


近期在写Spring项目的时候,需要通过注解的形式去替代之前直接将Bean存放在Spring容器这种方式,以此来简化对于Bean对象的操作,但是这样无法通过准确的Id去获取到相应的Bean对象了
测试观察
- 首先,如果要将指定的对象存放到Spring中,在Spring的配置文件中的扫描包路径一定不能错,这样我们在这个包中所包含的类前加上【五大类注解】,就可以将对象存储到Spring中的
<content:component-scanbase-package="com.spring.demo"></content:component-scan>
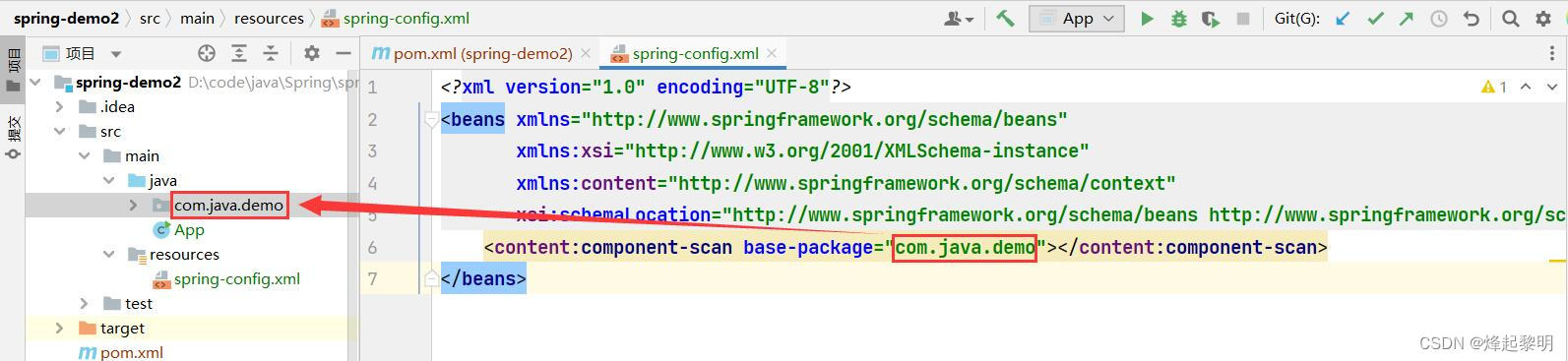
- 然后我便在这个包下写了个
UserController类,并且加上了【**@Controller**】注解,此时Spring在加载的时候就会存储改对象
@ControllerpublicclassUserController{publicvoidSayHello(){System.out.println("do SayHello()");}}
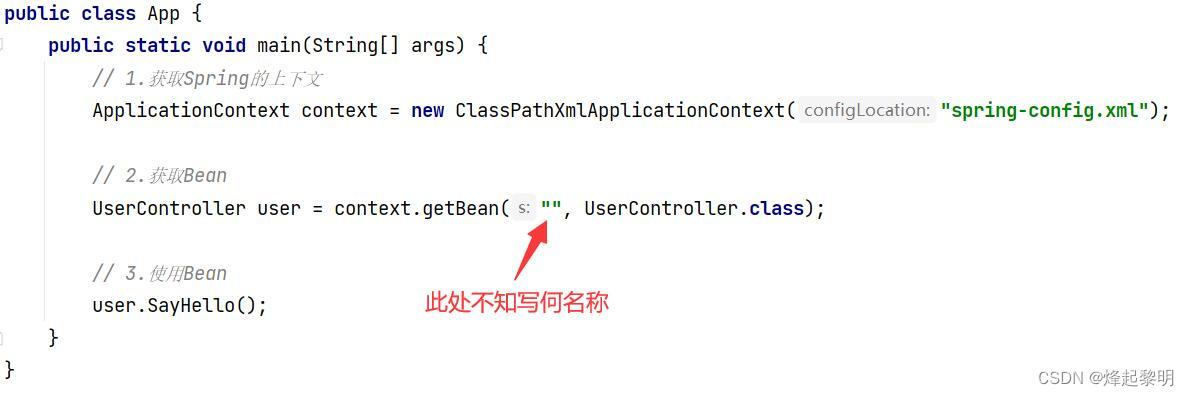
- 此时看到,我在App类中去获取到了这个Bean对象,而且使用的是【名称 + 类名】的形式,这种形式就可以防止Spring中存储多个Bean对象而造成的冲突问题
- 但是呢,我就卡在了这里,不知道该去写什么名称?因为根本没有在Spring中写明Id值
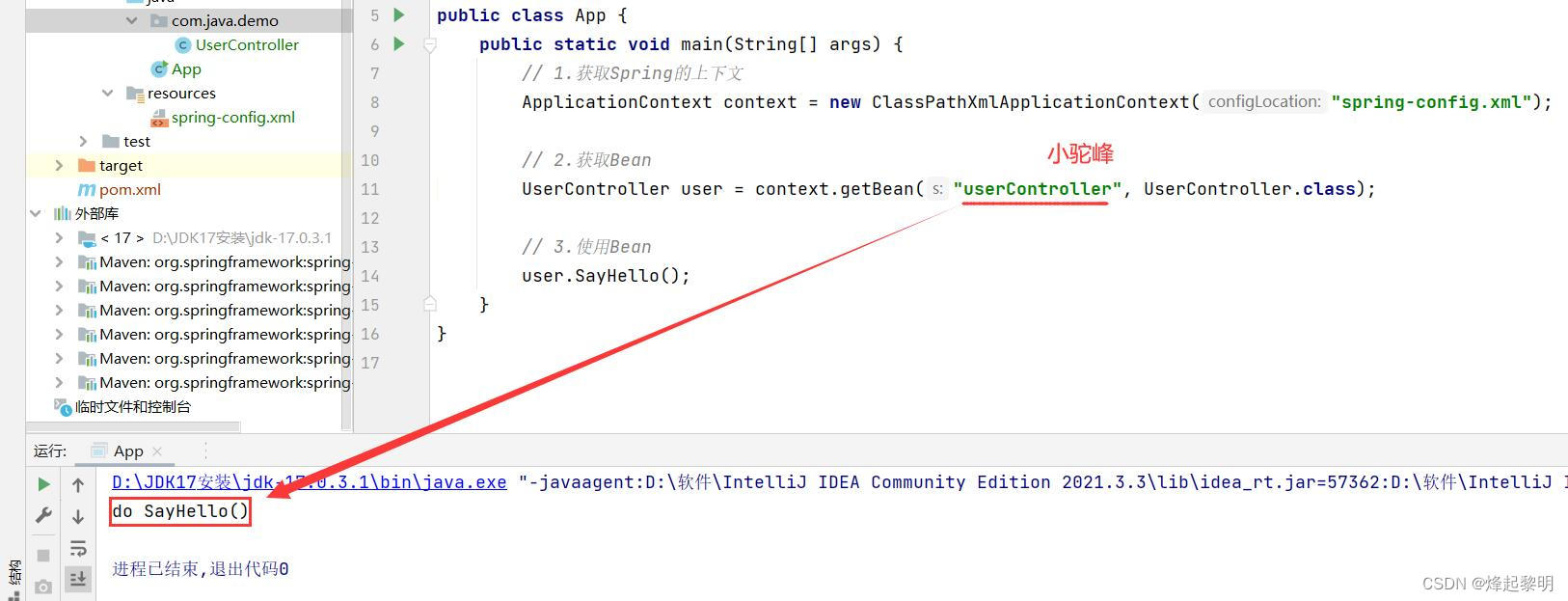
- 首先我想到的是这个名称会不会就是类名呢?但是在我进行尝试之后却发现并不是这样,编译器报出了异常说
No bean named 'UserController' available

- 然后我又想到了Java的命名规范是【小驼峰】,一般去通过这个类实例化对象的时候都是将首字母进行一个小写,其余不变,于是当我使用这个名称进行传递的时候,程序运行就没有问题了
那我首先猜测它的命名就是这样规定的,但是有没有特例呢?
- 此时我又去定义了一个类,将其类名取成了两个大写字母开头的,看看这样子的命名是否还会以【小驼峰】的形式去进行转换
@ControllerpublicclassSController{publicvoidSayHello(){System.out.println("do SayHello()");}}
- 但是当我在看运行结果的时候,却发现这样小驼峰的形式似乎行不通了
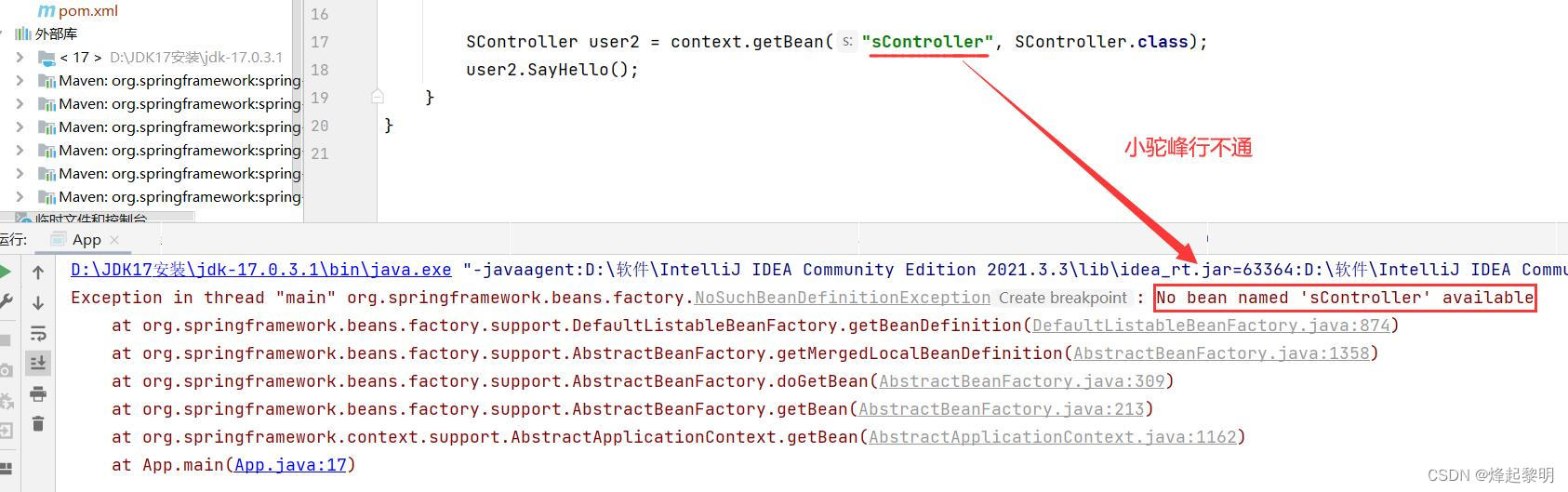
- 但是当我在将名称改回【类名】的时候,却发现又可以运行了,这是为什么呢?里面的转换规则又是怎样的?这需要我再去研究一番🔍

原理探究
通过上面的测试可以看出,Spring对于这个Bean对象的命名转换是存在一定规则的,因为【在Spring中,约定大于俗成】
- 接下去我就通过查看Spring源码的方式带读者来探究一下到底这个Spring内部对于这个Bean的命名转换规则是怎样的,虽然Spring框架的代码都是开源的,但是要精准地找到对应想要的代码逻辑可不简单,需要层层深入地进行探访
- 首先第一步,我们可以按两下【shift】键,便会跳出IDEA的搜索框,在这个里面你可以去搜寻当前项目中所有的类、接口,以查看它们的内部实现。然后我便发现了一个类叫做
AnnotationBeanNameGenerator,翻译一下即为【注释Bean名称生成器】,那我猜测命名规范的代码逻辑可能就在这个类中
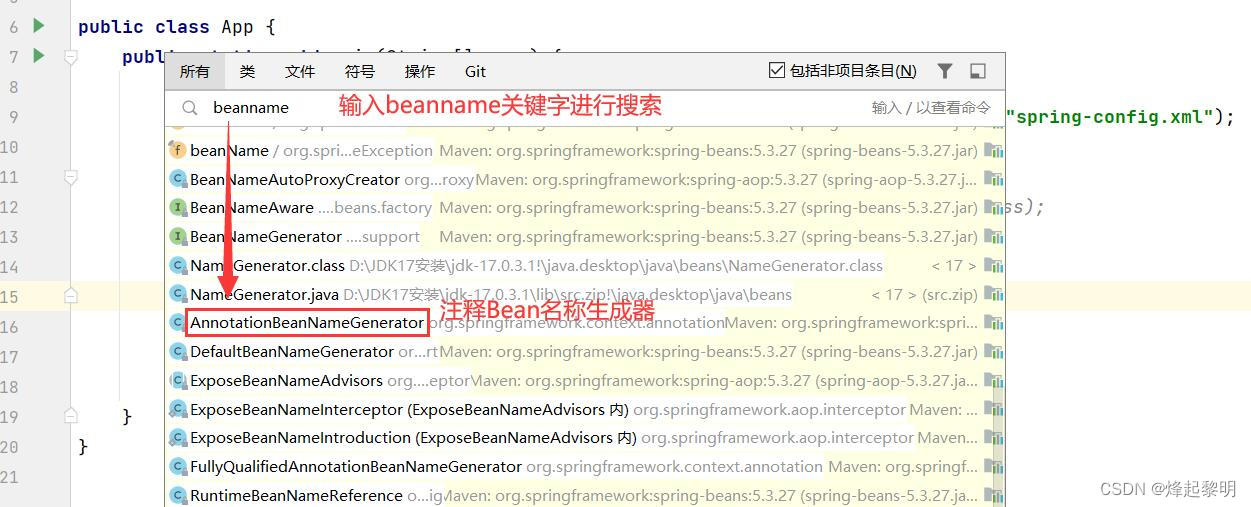
- 当我们进入到这个类后,就可以去寻找其对应的方法了,那个方法是和
BeanName有关联的,首先点击右侧的【结构】我们便可以看到这个类中到底有哪些方法,那一看我们就可以观察到有generateBeanName()这个方法,点到对应的方法后再进行观察,便发现其最后返回时又去调用了一个方法,于是我继续按住Ctrl键点进去

- 点进去发现里面又是一个方法,一些复杂的逻辑其实就是以这样一种嵌套的形式进行的,各个类、接口之间的方法调来调去

- 然后看到这是下面的这个方法
buildDefaultBeanName()生成默认Bean名称
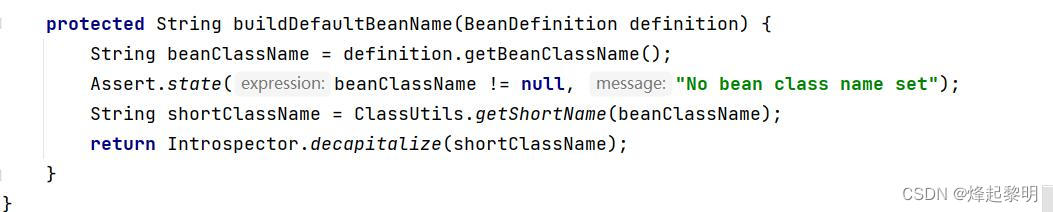
- 最后的话我们看到它在return的时候似乎又通过一个类名去调用了一个方法,然后传入了这个ClassName,那我继续点进去后就发现我似乎已经不处于Spring框架的源码中了,而是来到了JDK中
publicstaticStringdecapitalize(String name){if(name ==null|| name.length()==0){return name;}if(name.length()>1&&Character.isUpperCase(name.charAt(1))&&Character.isUpperCase(name.charAt(0))){return name;}char[] chars = name.toCharArray();
chars[0]=Character.toLowerCase(chars[0]);returnnewString(chars);}
- 我们可以点击右上角的这个按钮【选择打开的文件】去找到这个类所对应的位置
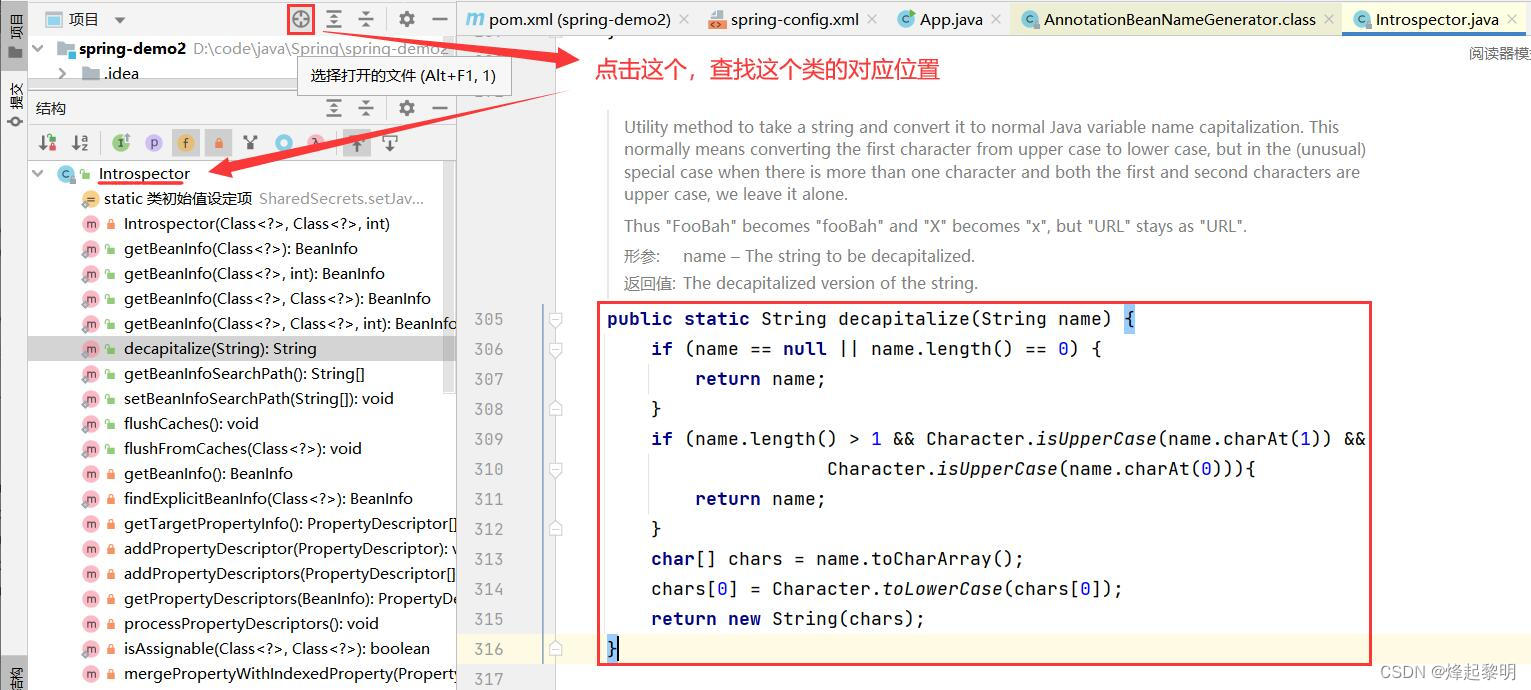
- 最后我这边顺腾摸瓜地去查找就看到这个类是
java.deskop包下的一个类,那么我们在查看Spring源码的时候最终还是来到了JDK下,这个可以说明一点:Bean的命名并不是乱取的,而是使用JDK的一个命名标准去进行命名的
然后我们就可以去看看JDK中对于命名的规范到底是怎样的💻
- 可以看到很明显的这里是有两种情况,若是首字母和第二个字母都是大写的话,那就返回原来的名称;第二种情况则是将字符串首先转换成了字符数组,然后再将第一位变成小写
- 那看到这里的话其实我已经是明白了,原来Spring对于Bean的这个命名规则是这样的

总结一下
最后的话我们来总结一下本次查看源码的收获吧🍚
通过查看Spring的源码我们进入到了JDK中,经过代码的阅读将Bean的命名转换总结了以下两点
- 默认情况:使用原类名首字母小写就能读取到Bean对象
- 特例:如果首字母和第二字母都是大写的情况下,那么Bean名称就是原类名
在学习Spring框架的过程中,初学者难免会遇到不理解的地方,因为Spring是一个IoC容器,会通过DI依赖注入的形式帮我们自动地去管理对象,所以内部的细节便不得而知,但我们可以通过【阅读源码】的方式来进行理解,去看看大佬是怎么思考的🤔
本文转载自: https://blog.csdn.net/Fire_Cloud_1/article/details/131024305
版权归原作者 烽起黎明 所有, 如有侵权,请联系我们删除。
版权归原作者 烽起黎明 所有, 如有侵权,请联系我们删除。