
Flink内部数据精准一次消费
Barrier对齐
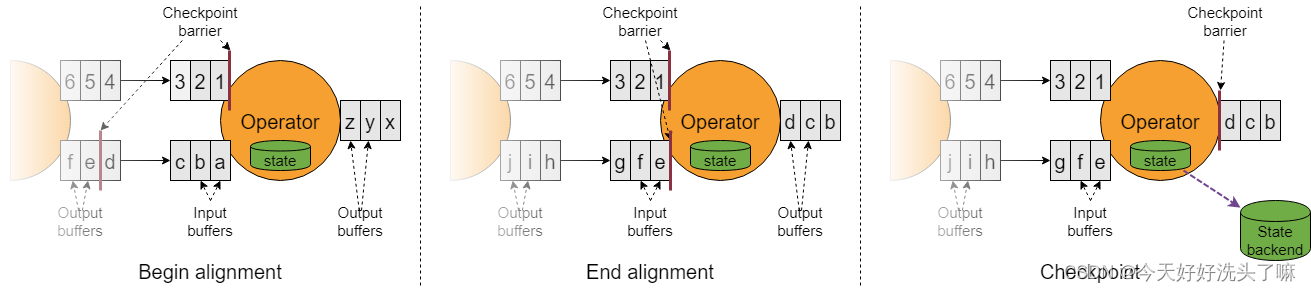
- 流程 当一个算子上游有两条或多条输入时,在进行Checkpoint时可能会出现两条流中数据流速不一样,导致多条流同一批次的Barrier到达下游算子的时间不一致, 此时快的Barrier到达下游算子后,此Barrier之后到达的数据将会放到缓冲区,不会进行处理。等到其他流慢的Barrier到达后,此算子才进行checkpoint,然后把状态保存到状态后端。这就是Barrier的对齐机制。
- 优缺点 1)优点:①状态后端保存数据少。 2)缺点:①延迟性高(快的Barrier到达后会阻塞此条流的数据处理)②当作业出现反压时,会加剧作业的反压(当出现反压时,数据本身就处理不过来,此时某条流的数据又阻塞了所以就会加剧反压。)③整体chenkpoint时间变长(因为反压会导致数据流速变慢,导致Barrier流的也慢,所以就会使得整体chenkpoint时间变长)。
- 优化 在Flink1.11后引入了Unaligned Checkpoint的特性,使得当Barrier不对齐的时候也可以实现数据的精准一次消费。
Barrier不对齐(Unaligned Checkpoint)
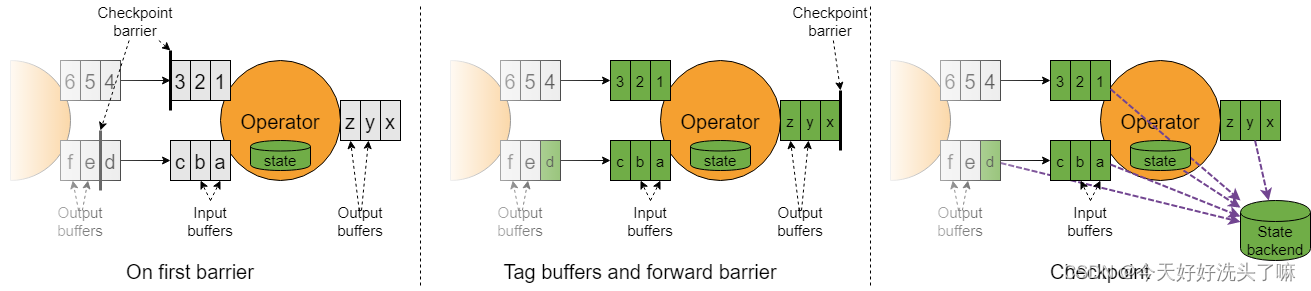
- 流程 当流速快的Barrier到达下游算子的input buffer后,此时会把这个Barrier插队到此下游算子的output buffer最前面,然后把这个Barrier发生给之后的算子,同时对自身进行快照,这时的快照内容就是当时的状态以及当时所有input buffer和output buffer以及流速慢的Barrier(这个流速慢的Barrier应该是当进行快照时就被移除了,并不会流下去)之前的数据都会保存到状态后端当中。当之后恢复到此次checkpoint的时候,不对齐的数据会重新恢复到各个流中,虽然会重新进行计算,但是此时的状态也是未计算之前的状态。
- 优缺点 1)优点:①加快checkpoint的进行②当作业出现反压时不会造成反压加剧。 2)缺点:①状态后端保存数据多②进行状态恢复的时比较慢。
Flink内部数据至少一次消费
Barrier不对齐
- 流程 这个不对齐和上边的精准一次消费不对齐机制是不一样的。当流速快的Barrier流到下游算子当中,此时不理会此Barrier,正常进行后续数据的计算。当流速慢的Barrier到来的时候,此时进行快照。此时进行快照时,会把流速慢的那条流中相同Barrier后的数据也进行计算一部分,然后把计算完的状态保存到状态后端,之后进行状态恢复时,会把Barrier之后的数据进行重复,而此时状态的结果是包含一部分Barrier之后的数据的 ,此时就会造成数据的重复消费问题。
- 优缺点 1)优点:①不会阻塞数据,延迟低。 2)缺点:①造成数据的重复消费问题。
本文转载自: https://blog.csdn.net/qq_42009405/article/details/122850469
版权归原作者 今天好好洗头了嘛 所有, 如有侵权,请联系我们删除。
版权归原作者 今天好好洗头了嘛 所有, 如有侵权,请联系我们删除。