
系列文章目录
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
例如:第一章 Python 机器学习入门之pandas的使用
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
提示:以下是本篇文章正文内容,下面案例可供参考
一、卷积神经网络是什么
什么是卷积
对图像(不同的数据窗口数据)和滤波矩阵(一组固定的权重:因为每个神经元的多个权重固定,所以又可以看做一个恒定的滤波器filter)做内积(逐个元素相乘再求和)的操作就是所谓的『卷积』操作,也是卷积神经网络的名字来源。
非严格意义上来讲,下图中红框框起来的部分便可以理解为一个滤波器,即带着一组固定权重的神经元。多个滤波器叠加便成了卷积层。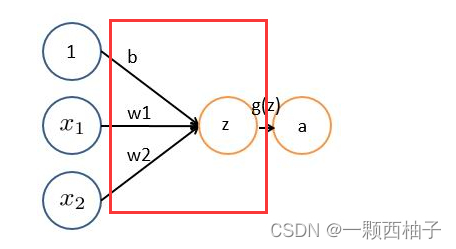
整体结果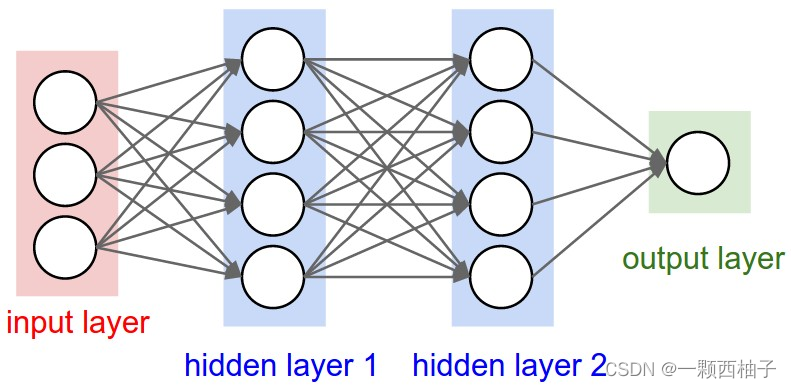
卷积神经网络是一种带有卷积结构的深度神经网络,卷积结构可以减少深层网络占用的内存量,其三个关键的操作,其一是局部感受野,其二是权值共享,其三是pooling层,有效的减少了网络的参数个数,缓解了模型的过拟合问题。。
网络结构
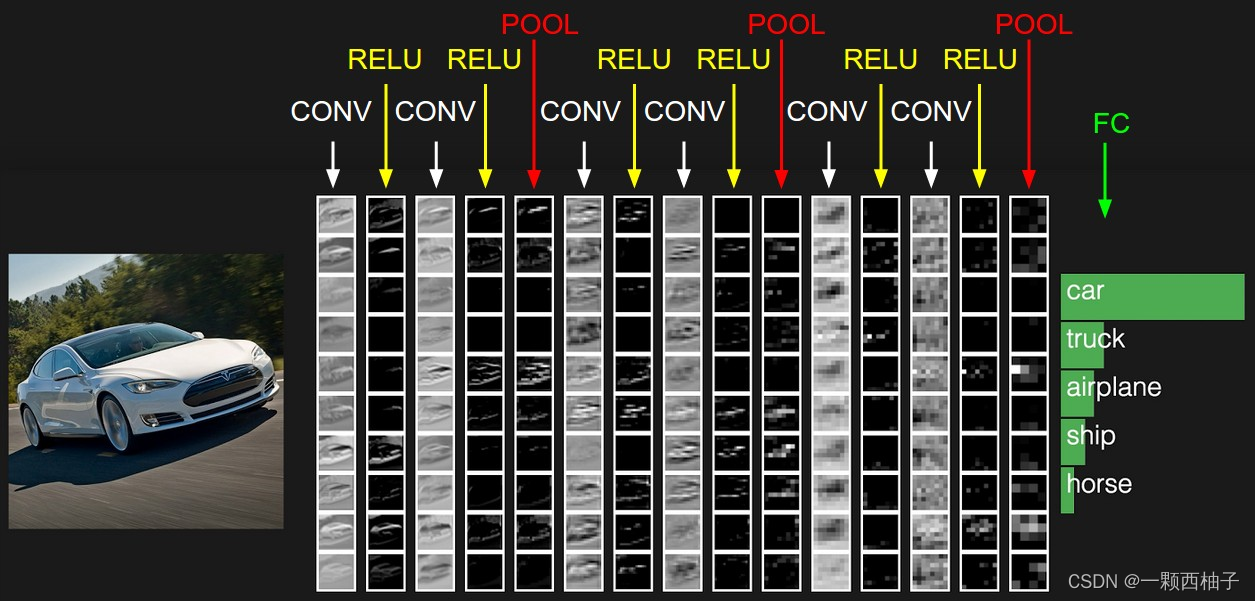
上图中CNN要做的事情是:给定一张图片,是车还是马未知,是什么车也未知,现在需要模型判断这张图片里具体是一个什么东西,总之输出一个结果:如果是车 那是什么车
- 最左边是数据输入层
对数据做一些处理,比如去均值(把输入数据各个维度都中心化为0,避免数据过多偏差,影响训练效果)、归一化(把所有的数据都归一到同样的范围)、PCA/白化等等。CNN只对训练集做“去均值”这一步。
- 中间是
CONV:卷积计算层,线性乘积 求和。
RELU:激励层,上文2.2节中有提到:ReLU是激活函数的一种。
POOL:池化层,简言之,即取区域平均或最大。
- 最右边是
FC:全连接层
这几个部分中,卷积计算层是CNN的核心,下文将重点阐述。
二、动图理解
卷积计算过程
在CNN中,滤波器filter(带着一组固定权重的神经元)对局部输入数据进行卷积计算。每计算完一个数据窗口内的局部数据后,数据窗口不断平移滑动,直到计算完所有数据。这个过程中,有这么几个参数:
a. 深度depth:神经元个数,决定输出的depth厚度。同时代表滤波器个数。
b. 步长stride:决定滑动多少步可以到边缘。
c. 填充值zero-padding:在外围边缘补充若干圈0,方便从初始位置以步长为单位可以刚好滑倒末尾位置,通俗地讲就是为了总长能被步长整除。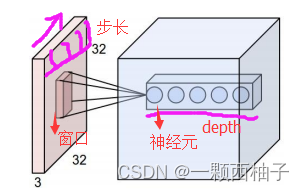
示例过程: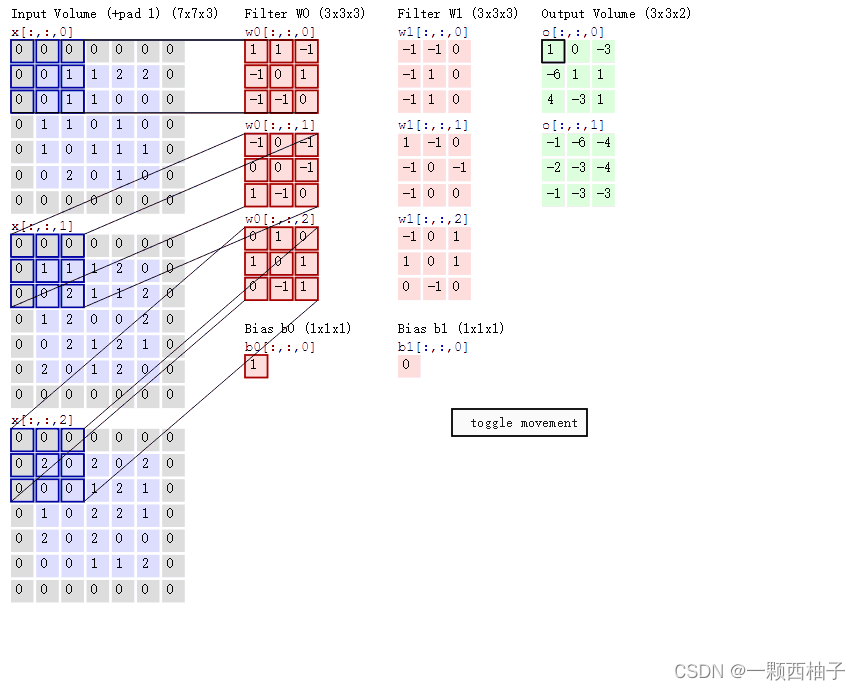
激活函数
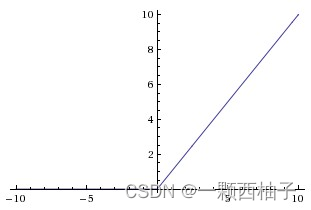
实际梯度下降中,sigmoid容易饱和、造成终止梯度传递,因为反向传播时求导可能为0,且没有0中心化。咋办呢,可以尝试另外一个激活函数:ReLU,其图形表示如下
ReLU的优点是收敛快,求梯度简单。
池化层
作用减小数据大小,有平均池化和最大赤化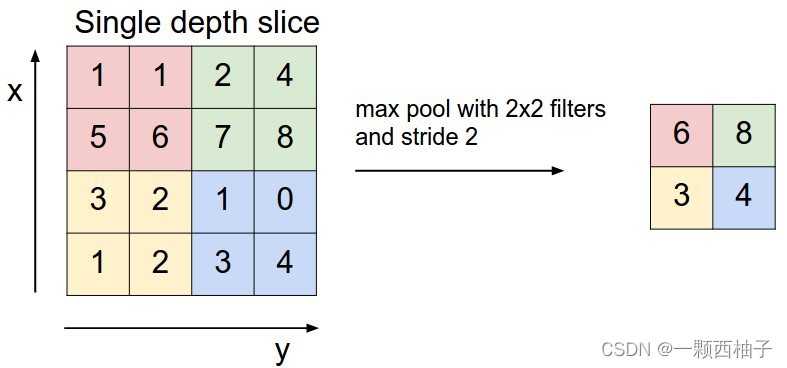
上图所展示的是取区域最大,即上图左边部分中 左上角2x2的矩阵中6最大,右上角2x2的矩阵中8最大,左下角2x2的矩阵中3最大,右下角2x2的矩阵中4最大,所以得到上图右边部分的结果:6 8 3 4。很简单不是?
全连接层
采用softmax全连接,得到的激活值即卷积神经网络提取到的图片特征。
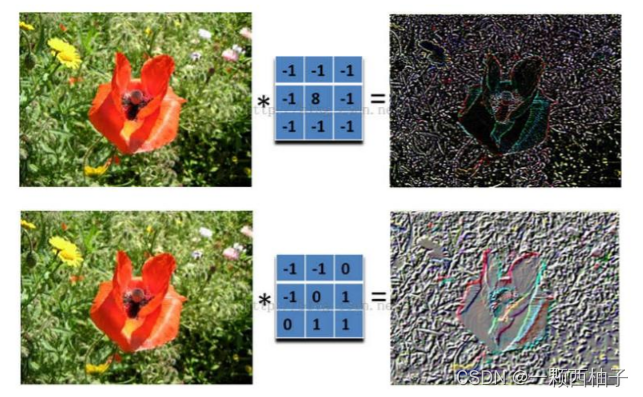
不同的卷积核会得到不同的效果
在下图对应的计算过程中,输入是一定区域大小(width*height)的数据,和滤波器filter(带着一组固定权重的神经元)做内积后等到新的二维数据。
具体来说,左边是图像输入,中间部分就是滤波器filter(带着一组固定权重的神经元),不同的滤波器filter会得到不同的输出数据,比如颜色深浅、轮廓。相当于如果想提取图像的不同特征,则用不同的滤波器filter,提取想要的关于图像的特定信息:颜色深浅或轮廓。
如下图所示
三、手写数字数据集代码
数据集查看
数据集分析
使用keras.datasets库的mnist.py文件中的load_data方法加载数据
import tensorflow as tf
mnist=tf.keras.datasets.mnist
#导入mnist数据集,确保网络畅通(X_train, Y_train),(X_test, Y_test)= mnist.load_data()#shape属性获取数据形状print(X_train.shape,Y_train.shape,X_test.shape,Y_test.shape)
结果
训练集共有60000个样本,测试集共有10000个样本,每个图片样本的像素大小是2828的单通道灰度图(单通道图每个像素点只能有有一个值表示颜色,每个像素取值范围是[0-255])。X_train(储存样本数量,样本像素行,样本像素列);Y_trainn 。对此X_train是60000张2828的数据,尺寸是600002828,Y_train是对应的数字,尺寸是60000*1,X_test和Y_test同理。在本报告后文将Y_train以及Y_test称为数字标准答案。
单通道图: 俗称灰度图,每个像素点只能有有一个值表示颜色,它的像素值在0到255之间,0是黑色,255是白色,中间值是一些不同等级的灰色。. (也有3通道的灰度图,3通道灰度图只有一个通道有值,其他两个通道的值都是零)
数据集可视化
# 导入可视化的包import matplotlib.pyplot as plt
# 测试样本编号,取值范围[0-60000),此处随机采用406号样本
imgNum =406# cmap用于改变绘制风格,采用gray黑白
plt.imshow(X_train[imgNum],cmap='gray')#设置图像标题【此处我们打印出该图像对应的数字作为标题,方便查看】
plt.title(Y_train[imgNum])
plt.show()
结果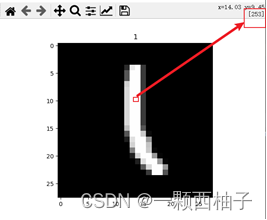
数据处理
# 图像的尺寸
img_rows, img_cols =28,28# 将图像像素转化为0-1的实数
X_train, X_test = X_train /255.0, X_test /255.0#转换数据维度[n,h,w,c]
X_train = X_train.reshape(X_train.shape[0], img_rows, img_cols,1)# print(X_train)
X_test = X_test.reshape(X_test.shape[0], img_rows, img_cols,1)
网络搭建
# 【Conv2D】# 构建卷积层。用于从输入的高维数组中提取特征。卷积层的每个过滤器就是一个特征映射,用于提取某一个特征,# 过滤器的数量决定了卷积层输出特征个数,或者输出深度。# 因此,图片等高维数据每经过一个卷积层,深度都会增加,并且等于过滤器的数量
model = tf.keras.models.Sequential([# 第一层卷积层
tf.keras.layers.Conv2D(filters=6, kernel_size=(3,3), padding='valid', activation=tf.nn.relu, input_shape=(28,28,1)),# 第一池化层
tf.keras.layers.AveragePooling2D(pool_size=(2,2), strides=(2,2), padding='same'),# 第二卷积层
tf.keras.layers.Conv2D(filters=16, kernel_size=(3,3), padding='valid', activation=tf.nn.relu),# 第二池化层
tf.keras.layers.AveragePooling2D(pool_size=(2,2), strides=(2,2), padding='same'),# 扁平化层,将多维数据转换为一维数据。
tf.keras.layers.Flatten(),# 全连接层
tf.keras.layers.Dense(units=120, activation=tf.nn.relu),# 全连接层
tf.keras.layers.Dense(units=84, activation=tf.nn.relu),# 输出层,全连接
tf.keras.layers.Dense(units=10, activation=tf.nn.softmax)])
model.summary()
优化器和编译器
# 优化器
adam_optimizer = tf.keras.optimizers.Adam(learning_rate)# 编译模型
model.compile(optimizer=adam_optimizer,
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=['accuracy'])
模型训练
# 模型开始训练时间
start_time = datetime.datetime.now()# 训练模型
num_epochs =10# 训练次数
batch_size =64# 批大小
learning_rate =0.001#学习率
model.fit(x=X_train, y=Y_train, batch_size=batch_size, epochs=num_epochs)# 模型结束训练,记录训练时间
end_time = datetime.datetime.now()
time_cost = end_time - start_time
查看预测结果
import random
# 进行预测
image_index = random.randint(1,100)# 选一张图片
pred = model.predict(X_test[image_index].reshape(1,28,28,1))print(pred.argmax())# 打印出预测值
plt.imshow(X_test[image_index].reshape(28,28), cmap='Greys')
plt.show()
准确率
print(model.evaluate(X_test, Y_test, verbose=2))
版权归原作者 一颗西柚子 所有, 如有侵权,请联系我们删除。