
ik分词器的使用
- 一、下载并安装
- 1.1 已有作者编译后的包文件- 1.2 只有源代码的版本- 1.3 安装ik分词插件
- 二、ik分词器的模式
- 2.1 ik_smart演示- 2.2 ik_max_word演示- 2.3 standard演示
- 三、ik分词器在项目中的使用
- 四、ik配置文件
- 4.1 配置文件的说明- 4.2 自定义词库
- 五、参考链接
一、下载并安装
GitHub下载地址:Releases · infinilabs/analysis-ik · GitHub
1.1 已有作者编译后的包文件
选择与所需es版本相同的ik分词器,下载已经打包后的.zip文件
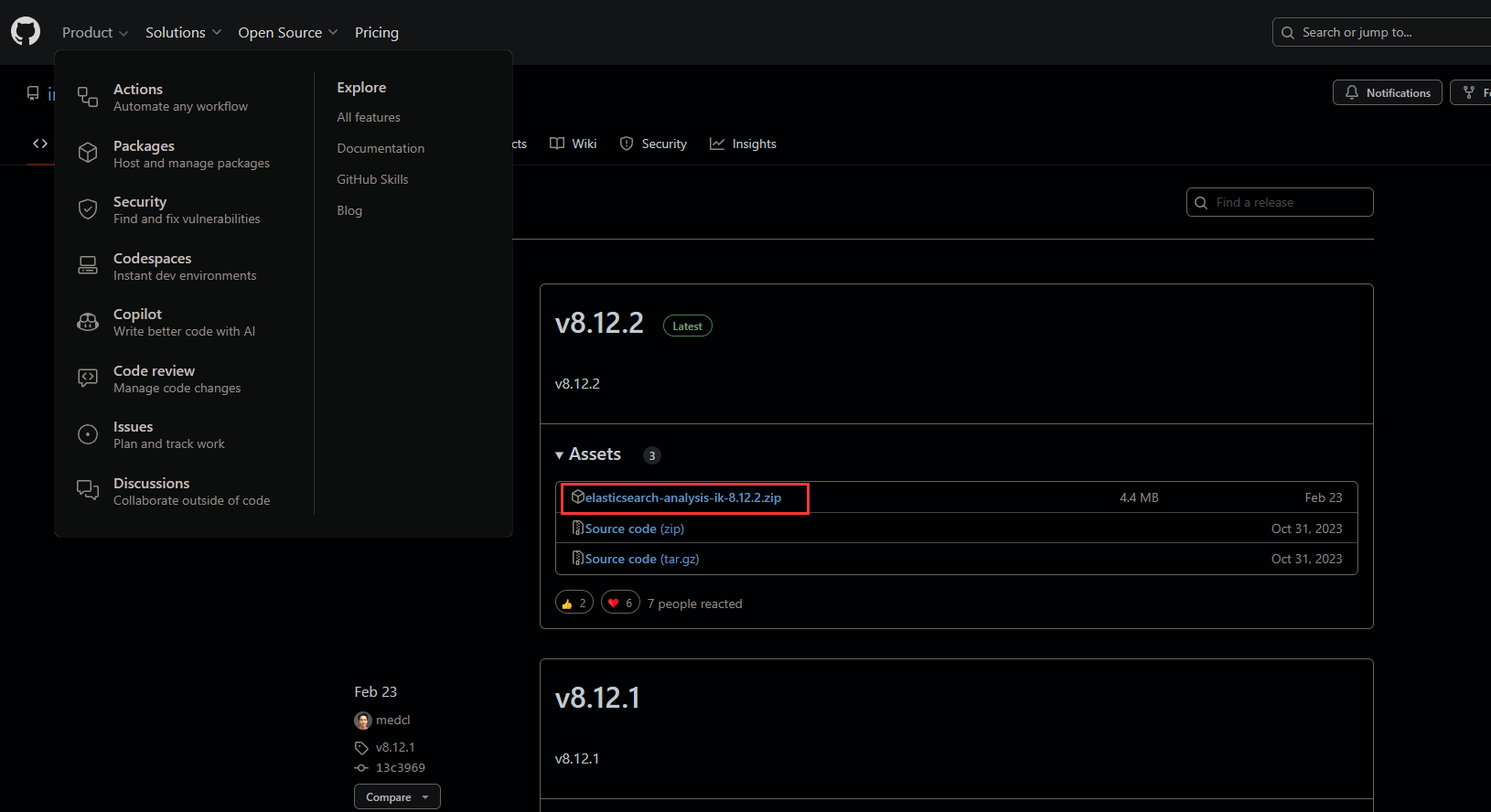
1.2 只有源代码的版本
首先下载源码解压后使用idea打开,修改es版本与分词器版本相同
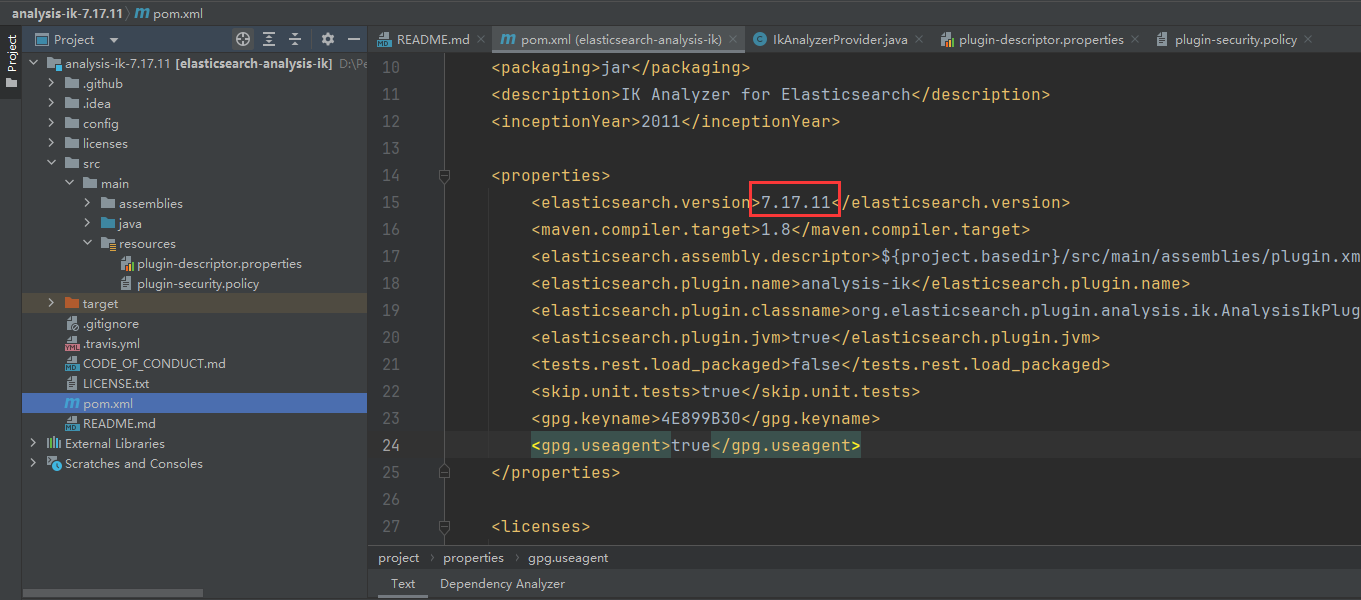
使用 mvn clean install 打包时报错:
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-compiler-plugin:3.5.1:compile (default-compile) on project elasticsearch-analysis-ik: Compilation failure
[ERROR] /D:/PersonalProjects/analysis-ik-7.17.11/analysis-ik-7.17.11/src/main/java/org/elasticsearch/index/analysis/IkAnalyzerProvider.java:[13,9] 无法将类 org.elasticsearch.index.analysis.AbstractIndexAnalyzerProvider<T>中的构造器
AbstractIndexAnalyzerProvider应用到给定类型;
[ERROR] 需要: org.elasticsearch.index.IndexSettings,java.lang.String,org.elasticsearch.common.settings.Settings
[ERROR] 找到: java.lang.String,org.elasticsearch.common.settings.Settings
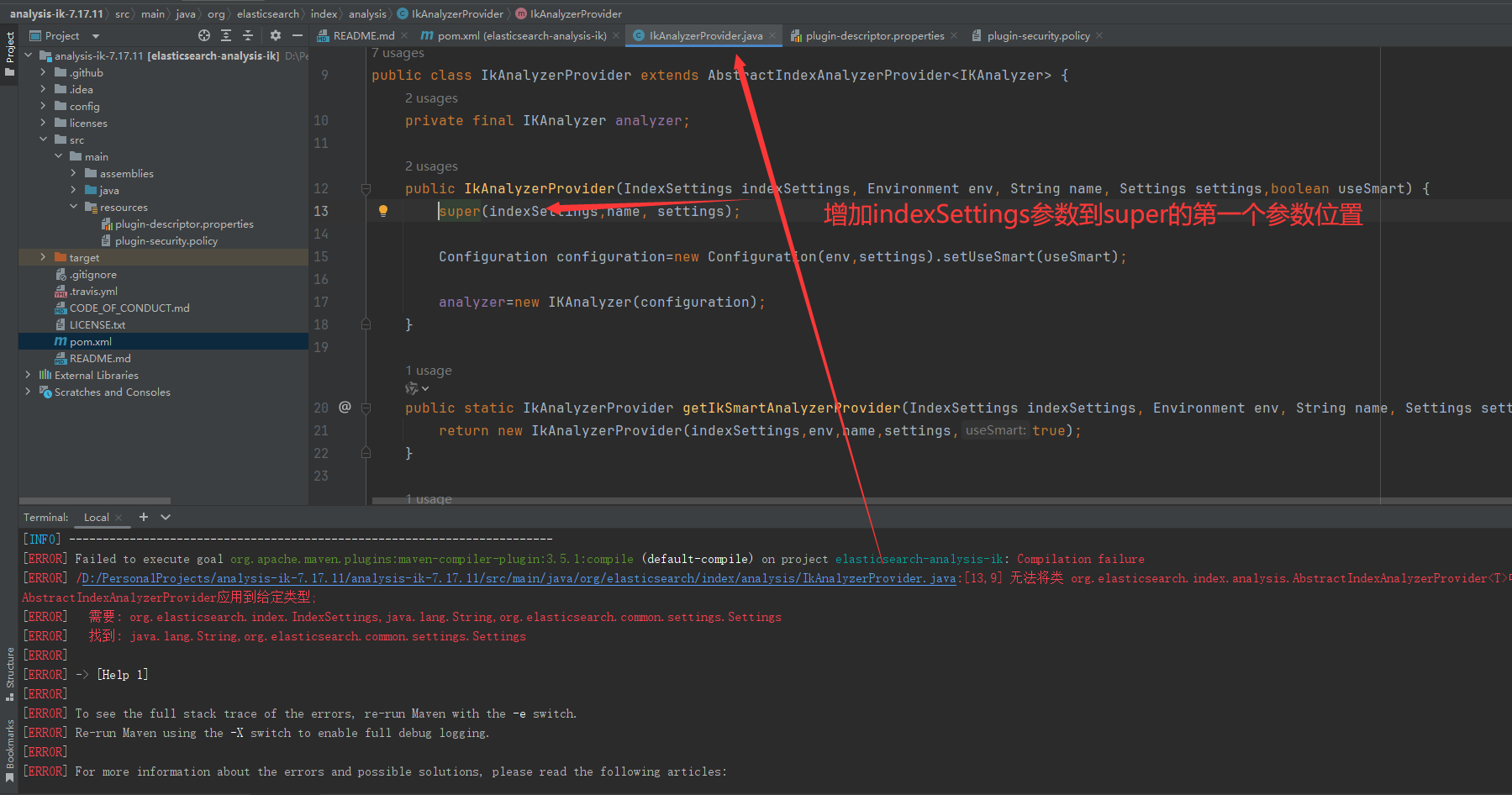
修改代码报错部分:增加indexSetting参数到super入参的第一个位置
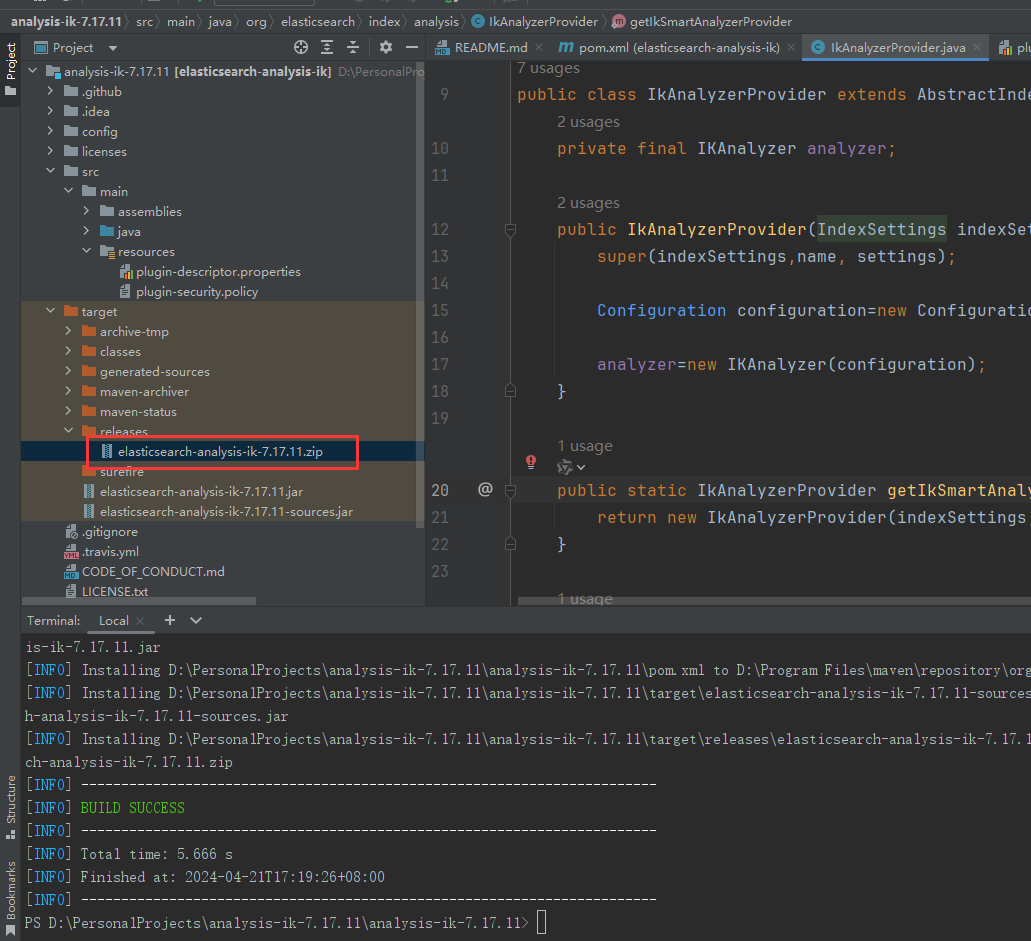
使用mvn clean install进行打包,注意我们所需的是/target/release目录下的.zip压缩包
1.3 安装ik分词插件
将下载或者编译后的.zip文件解压到es的安装目录下的plugins目录下,并重命名为ik
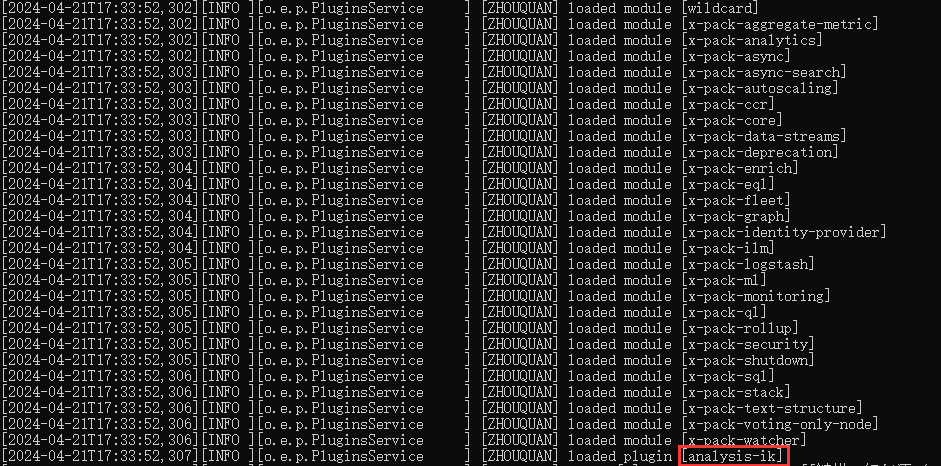
然后启动es,查看日志可发现已经加载的ik分词器
二、ik分词器的模式
IK分词器提供了两种主要的分词模式:
- 细粒度分词模式(ik_max_word):- 在这种模式下,IK分词器会尽可能地按照词典中的词语进行最大长度匹配,将文本切分成连续的词语序列。- 这种模式适用于对文本进行细致的切分,会尽可能地将句子切分为最小的词语单元,能够获得更加精确的分词结果。
- 智能分词模式(ik_smart):- 在智能切分模式下,IK分词器会结合词典匹配和机器学习算法,根据文本的上下文信息进行分词,保留词语的完整性。- 这种模式能够更好地处理一些特殊情况,如未登录词和新词等,提高了分词的准确性和适用性。
2.1 ik_smart演示
POST _analyze
{"analyzer":"ik_smart","text":"中国篮球队"}
{"tokens":[{"token":"中国","start_offset":0,"end_offset":2,"type":"CN_WORD","position":0},{"token":"篮球队","start_offset":2,"end_offset":5,"type":"CN_WORD","position":1}]}
2.2 ik_max_word演示
POST _analyze
{"analyzer":"ik_max_word","text":"中国篮球队"}
{"tokens":[{"token":"中国篮球","start_offset":0,"end_offset":4,"type":"CN_WORD","position":0},{"token":"中国","start_offset":0,"end_offset":2,"type":"CN_WORD","position":1},{"token":"篮球队","start_offset":2,"end_offset":5,"type":"CN_WORD","position":2},{"token":"篮球","start_offset":2,"end_offset":4,"type":"CN_WORD","position":3},{"token":"球队","start_offset":3,"end_offset":5,"type":"CN_WORD","position":4}]}
2.3 standard演示
POST _analyze
{"analyzer":"standard","text":"中国篮球队"}
{"tokens":[{"token":"中","start_offset":0,"end_offset":1,"type":"<IDEOGRAPHIC>","position":0},{"token":"国","start_offset":1,"end_offset":2,"type":"<IDEOGRAPHIC>","position":1},{"token":"篮","start_offset":2,"end_offset":3,"type":"<IDEOGRAPHIC>","position":2},{"token":"球","start_offset":3,"end_offset":4,"type":"<IDEOGRAPHIC>","position":3},{"token":"队","start_offset":4,"end_offset":5,"type":"<IDEOGRAPHIC>","position":4}]}
三、ik分词器在项目中的使用
常规的最常用的使用方式就是,数据插入存储时用 ik_max_word模式分词,而检索时,用ik_smart模式分词,即:索引时最大化的将文章内容分词,搜索时更精确的搜索到想要的结果。
建立映射示例如下:在数据被索引时我们设置"analyzer": “ik_max_word”,在检索时指定"search_analyzer": “ik_smart”
{"properties":{"id":{"type":"long"},"title":{"type":"text","analyzer":"ik_max_word","search_analyzer":"ik_smart","fields":{"keyword":{"type":"keyword"},"sort":{"type":"keyword","normalizer":"sort_normalizer"}}},"content":{"type":"text","analyzer":"ik_max_word","search_analyzer":"ik_smart"}}}
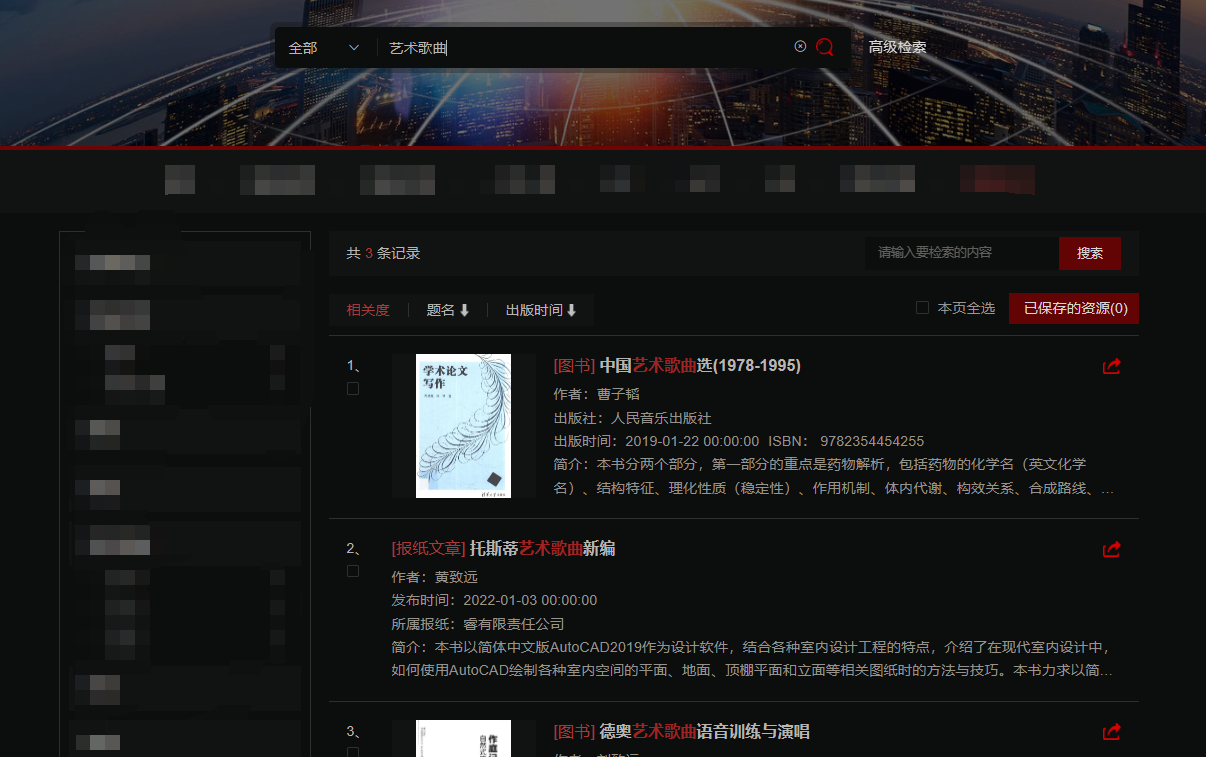
输入检索词
艺术歌曲
,由于在mapping中设置了 “search_analyzer”: “ik_smart”,因此默认使用最大分词,根据bm25算分后返回结果如下
四、ik配置文件
4.1 配置文件的说明
配置文件地址:\plugins\ik\config
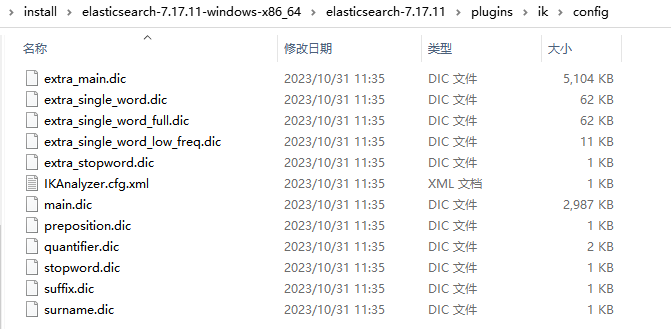
- IKAnalyzer.cfg.xml: 这是IK分词器的主要配置文件,用于配置分词器的一些参数和规则。例如,可以在这个文件中指定自定义词典、停用词表、分词模式等。
- ext.dic: 这是一个外部用户词典文件,用于存放用户自定义的词语。IK分词器在进行分词时会优先使用这个词典中的词语,可以用来补充分词器的默认词典,提高分词准确性。
- stopword.dic: 这是一个停用词表文件,用于存放需要在分词过程中忽略的常用词语。停用词通常是一些没有实际语义或者在特定场景中无关紧要的词语,如“的”、“是”、“在”等。
- quantifier.dic: 这是一个量词词典文件,用于存放中文中常见的量词,如“个”、“只”、“张”等。这些量词在分词过程中通常会被特别处理,以确保其正确分词。
- main.dic:ik原生内置的中文词库,总共有27万多条,只要是这些单词,都会被分在一起,都会按照这个里面的词语去分词
- preposition.dic: 介词
- surname.dic:中国的姓氏
4.2 自定义词库
每年都会出现新的流行语或者新的词语,但是自带的词库并未收录导致被分词。我们可以使用自定义词库来解决此问题。
示例:
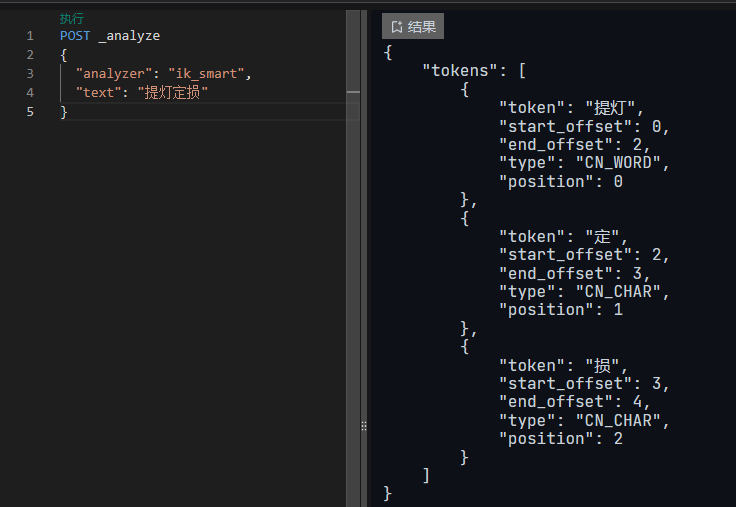
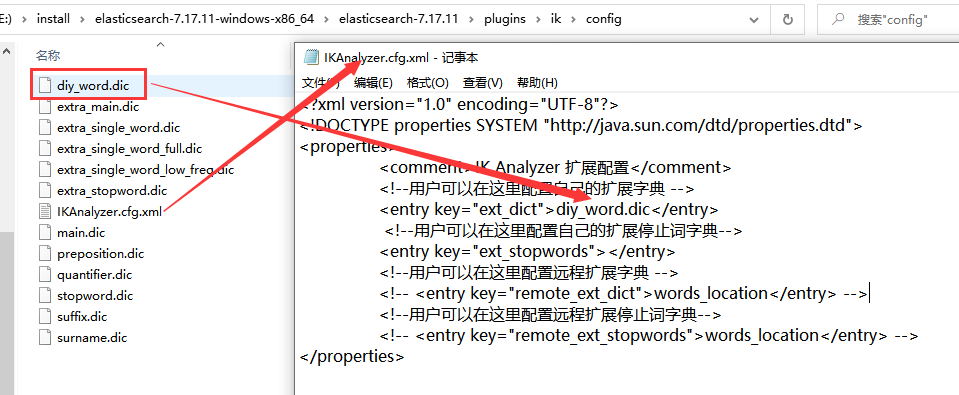
新增自定义词库 diy_word.dic,同时修改配置文件,指定自定义词库的名称。保存后重启es
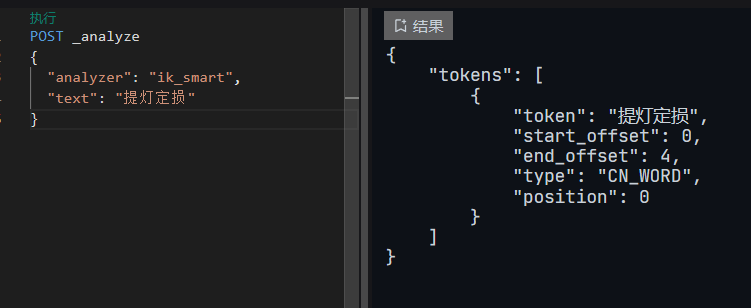
检索效果如下:
五、参考链接
[1] ElasticSearch7.3学习(十五)----中文分词器(IK Analyzer)及自定义词库_eleasticsearch ikanalyzer已经内置了词库是干什么用-CSDN博客
[2] ElasticSearch(ES)、ik分词器、倒排索引相关介绍 - 一剑一叶一花 - 博客园 (cnblogs.com)
版权归原作者 徐州蔡徐坤 所有, 如有侵权,请联系我们删除。