
简介与概述
因此,本文的重点是在不是使用BN来构建图像识别的卷积残差神经网络。但是如果没有BN,这些网络通常无法很好地运行或无法扩展到更大的批处理大小,但是本篇论文构建的网络可以使用大的批次进行伦联,并且比以前的最新方法(例如LambdaNets)更有效 。训练时间与准确率如下图表显示,对于在ImageNet上进行的相同的top-1准确性评分,NFnet比EffNet-B7快8.7倍。此模型是没有任何其他培训数据的最新技术,也是新的最新迁移学习。NFnets目前在全球排行榜上排名第二,仅次于使用半监督预训练和额外数据的方法。

BN有什么问题?
如果一个数据通过网络进行传播,它在经过各个层时将经历各种转换,但是,如果以错误的方式构建网络,这种传播就变得错上加错。在机器学习中,将数据集中在平均值周围,并将其缩放为单位变量是一个很好的做法,但当你在层中前进时,特别是如果你有像ReLU这样的激活层,它们只提取信号的正部分。因此随着时间的流逝,更深一层之间的中间表示可能会非常偏斜并且没有居中。如果您的数据具有良好的条件数(即,以均值为中心,不太偏斜等),则当前机器学习中的方法会更好地工作。

BN有3个显著的缺点。首先,它是一个非常昂贵的计算,这会导致内存开销。你需要计算平均值,缩放需要将它们存储在内存中用于反向传播算法。这增加了在某些网络中评估梯度所需的时间。
其次,它在模型训练和在推理时引入了一个差异的行为。因为在推理时你不想要这种批依赖,二十希望能够适配一个数据点,并且这两种操做的结果应该是相同的。
第三,BN打破了小批量训练实例之间的独立性。这意味着,现在批处理中哪些其他示例很重要。
这有两个主要后果。首先,批大小将影响批规范化。如果你有一个小批量,平均值将是一个非常有噪声的近似,然而,如果你有一个大批量,平均值将是一个很好的近似。我们知道对于一些应用来说大批量的训练是有利的,他们稳定了培训,减少了培训时间等。
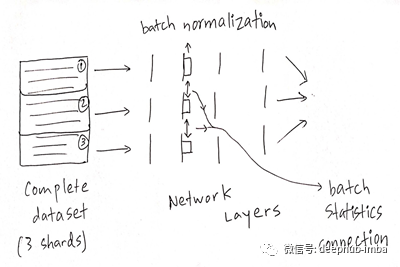
其次,分布式训练变得非常麻烦,因为例如,如果你的数据并行性,也就是说,你有这批数据批处理分为三个不同的部分,这三个部分向前传播到所有的神经网络用于3个不同的机器上的训练。如果在所有3个网络中都有一个BN层,那么您在技术上要做的就是将信号转发到BN层,然后您必须在BN层之间传递批处理统计信息,因为否则 在整个批次中没有平均值和方差。这使网络可以“欺骗”某些损失函数。
论文贡献
作者提出了自适应梯度裁剪(AGC),该方法基于梯度范数与参数范数的单位比例来裁剪梯度,他们证明了AGC允许我们训练具有更大批处理量和更强大数据增强功能的无规范化网络。
作者设计了一个称为NFNet的无规范化ResNet系列,该系列在ImageNet上针对各种训练等待时间设置了最好的验证精度。NFNet-F1模型达到与EfficientNet-B7相似的精度,同时训练速度提高了8.7倍,最大的模型在没有额外数据的情况下,设定了一个全新的高度(86.5% top-1精度)。
作者还提到,在对3亿张带有标签的大型私有数据集进行预训练后,对ImageNet进行微调时,NFNet与批归一化网络相比,其验证准确率要高得多。最佳模型经过微调后可达到89.2%的top-1
自适应梯度裁剪(AGC)
梯度裁剪通常用于语言建模以稳定训练,最近的工作表明,与梯度下降相比,它允许有更大的学习率的训练。梯度裁剪通常是通过约束梯度的模来实现的。具体来说,对于梯度向量G =∂L/∂θ,其中L表示损失,θ表示包含所有模型参数的向量,标准裁剪算法在更新θ之前对梯度进行裁剪:
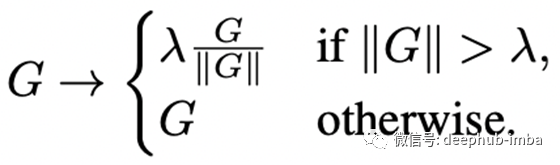
在训练过程中,优化器为了达到全局最小值而进行巨大的跳跃并不是一件很好的事情,所以梯度剪切只是说,无论何时任何参数的梯度非常大,我们都会剪切该梯度。如果梯度是好的,我们肯定会再次看到它,但如果梯度是坏的,我们想要限制它的影响。问题在于它对限幅参数λ非常敏感,原因是它不具有自适应性。
AGC所做的是,它可以缩放渐变,不仅可以将渐变缩放到其自己的范数,还可以将渐变裁剪为比率(渐变的大小/渐变所作用的权重是多少)。乍一看可能会有些困惑,详细请看论文第4页,以更清晰地理解AGC。
剪切阈值λ是必须调整的标量超参数。根据经验,作者发现,虽然这种削波算法使他们能够以比以前更高的批次大小进行训练,但是训练稳定性对削波阈值的选择极为敏感,在改变模型深度、批大小或学习速率时需要细粒度调整。作者通过选择与梯度范数成反比的自适应学习速率来忽略梯度的比例。
注意,最优剪切参数λ可能取决于优化器的选择,学习率和批大小。根据经验作者发现对于大批量生产λ应该更小。
自适应梯度裁剪(AGC)的消融
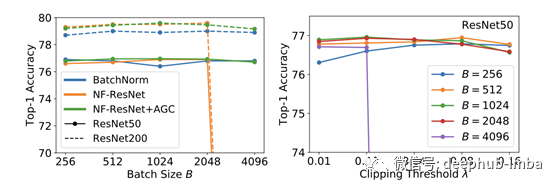
例如,如果你比较图1中的批规范网络(NF-ResNet和NF-ResNet + AGC),你可以看到在一定的批大小(2048)之后,非AGC会简单地崩溃,而AGC会占上风。这似乎是大批量生产的隐藏问题。作者抱怨说λ的剪切阈值是非常挑剔的。在图2中,你可以看到λ对批大小有一个至关重要的依赖,另外上图显示在小批次大小下,可以在相当大的阈值上进行剪切。对于大批量,必须将阈值保持在非常低的水平,因为如果将阈值修剪得更高则会崩溃。
最后本篇论文的地址:
https://arxiv.org/pdf/2102.06171.pdf High-Performance Large-Scale Image Recognition Without Normalization, 11 Feb 2021.
作者:Nakshatra Singh
deephub翻译组