
1.软件准备
- Vmware workstation pro16
- centos7镜像文件
- Java8-linux
- 网盘地址:链接:https://pan.baidu.com/s/15Gjxes4PC3zOZPX6JPkncQ 提取码:5277
2.安装centos7虚拟机
- 点击文件新建虚拟机
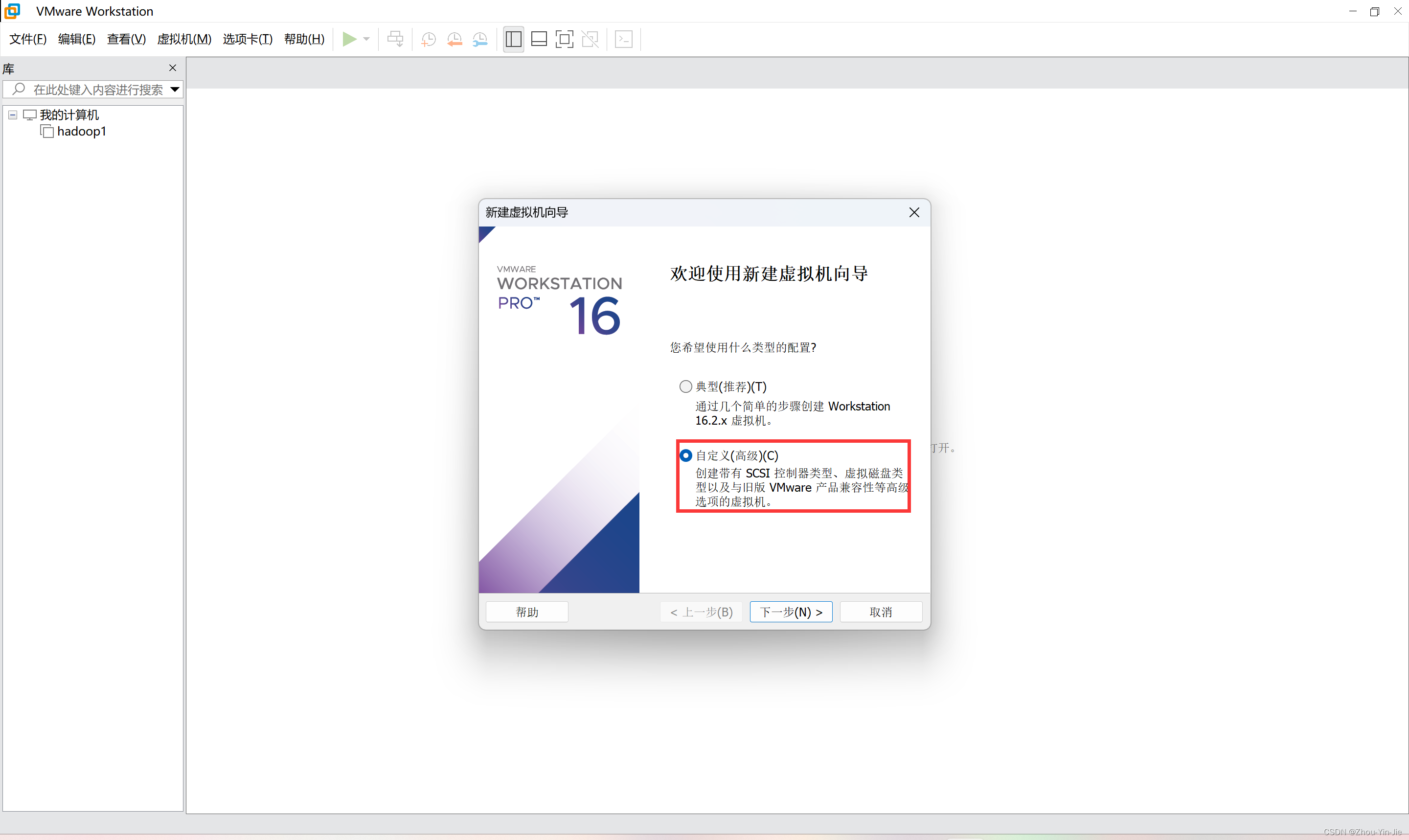
- 选择自定义高级安装,点击下一步
- 点击下一步
- 选择稍后安装操作系统,点击下一步
- 选择linux操作系统,centos764位
- 填写虚拟机的名称、修改虚拟机存放的目录
- 根据自己的电脑配置,选择处理机的数量以及每个核的数量
- 选择虚拟机的内存
- 选择网络连接位NAT模式
- 一直点击下一步到为虚拟机分配硬盘空间
- 一直点击下一步直至完成。
- 点击编辑虚拟机设置,点击CD\DVD,选择IOS镜像文件,这个镜像文件就是centos7的镜像文件。
- 打开虚拟机
- 选择install centos
- 来到欢迎界面,左边滑倒最底下,选择中文
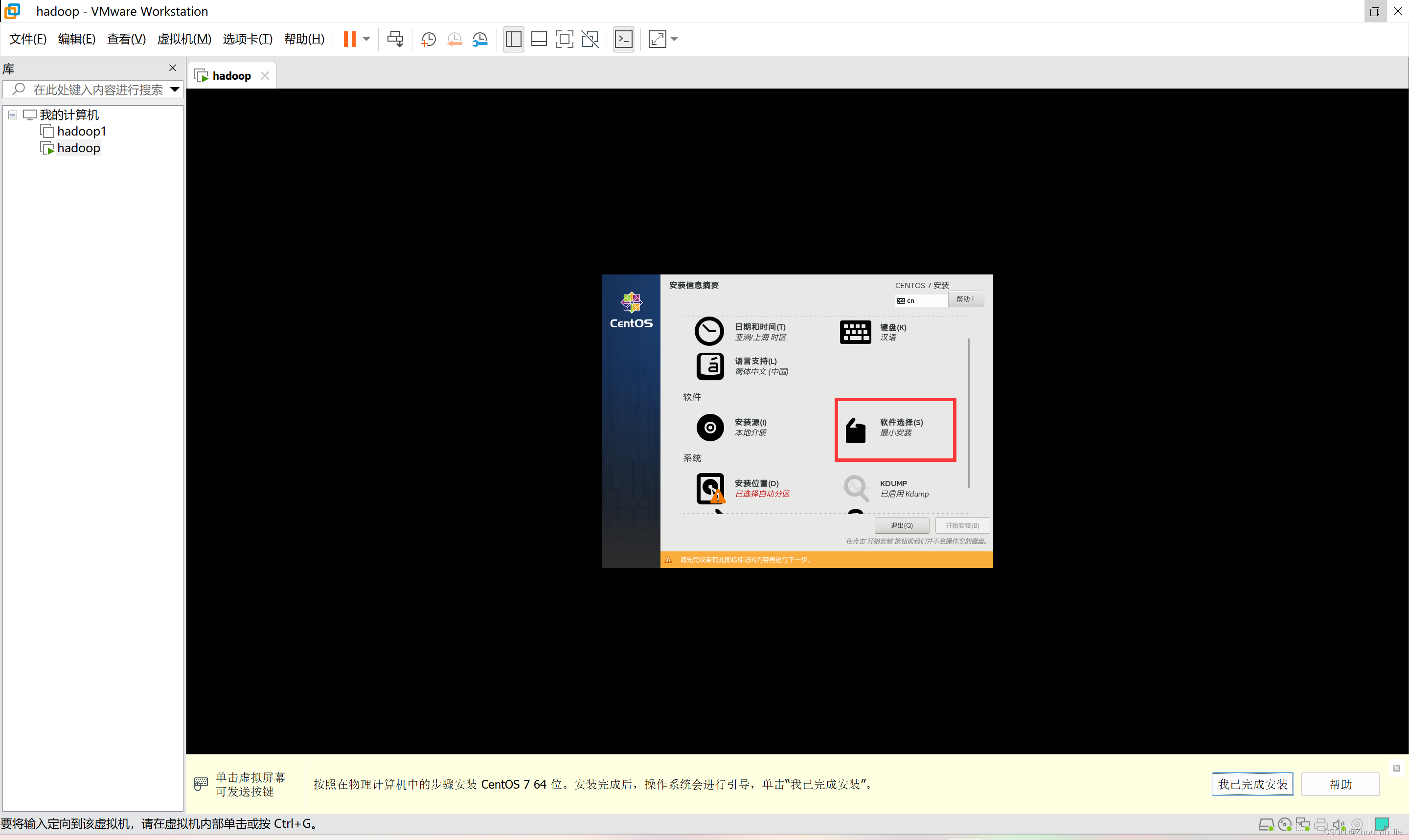
- 点击完成,来到信息安装摘要界面,点击软件选择。默认是最小安装,为了方便我们学习,需要点进去选择一些配置。
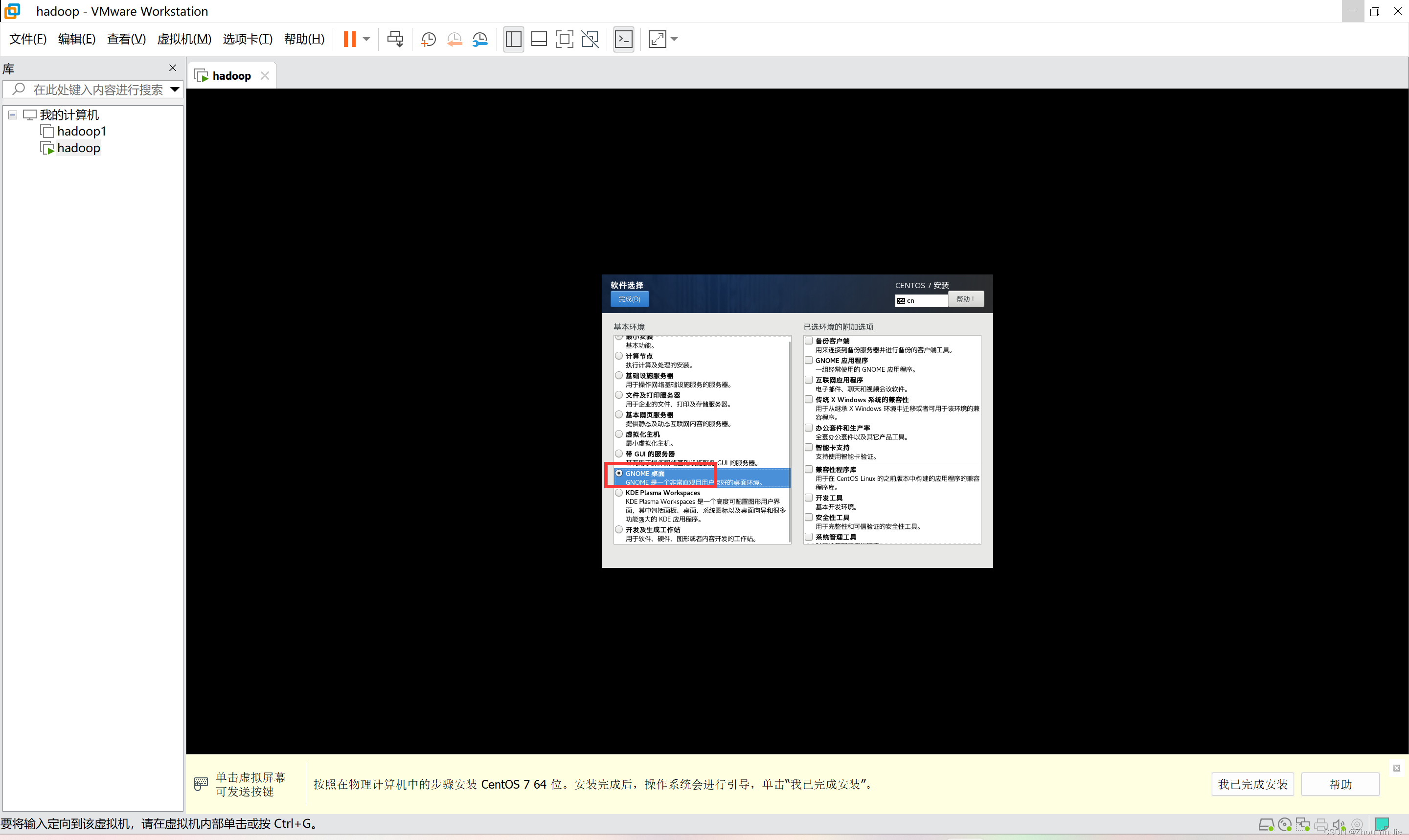
- 选择一个桌面环境,点击完成
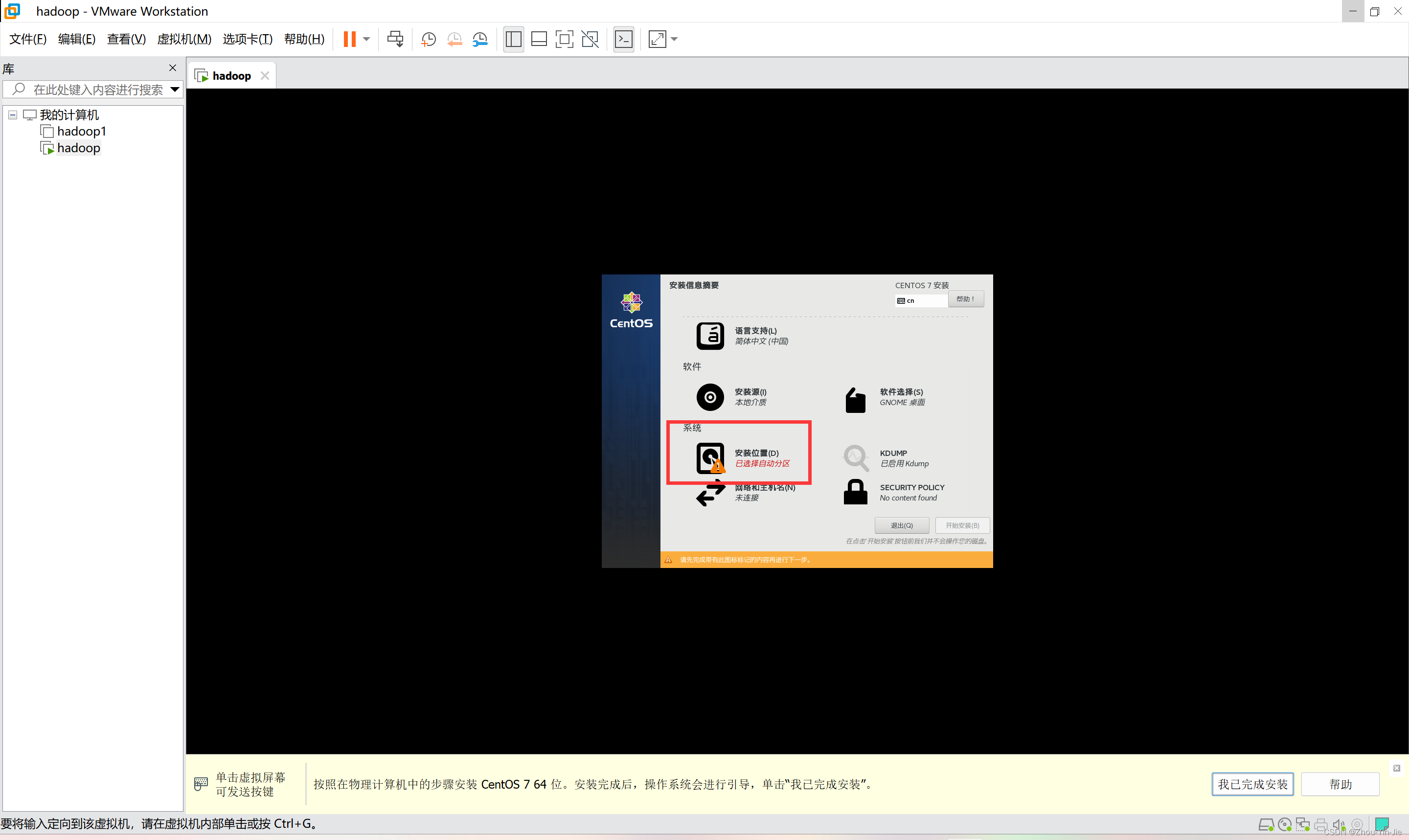
- 点击安装位置,自定义分区(可直接使用默认分区)
- 点击我要分区,然后点击完成。
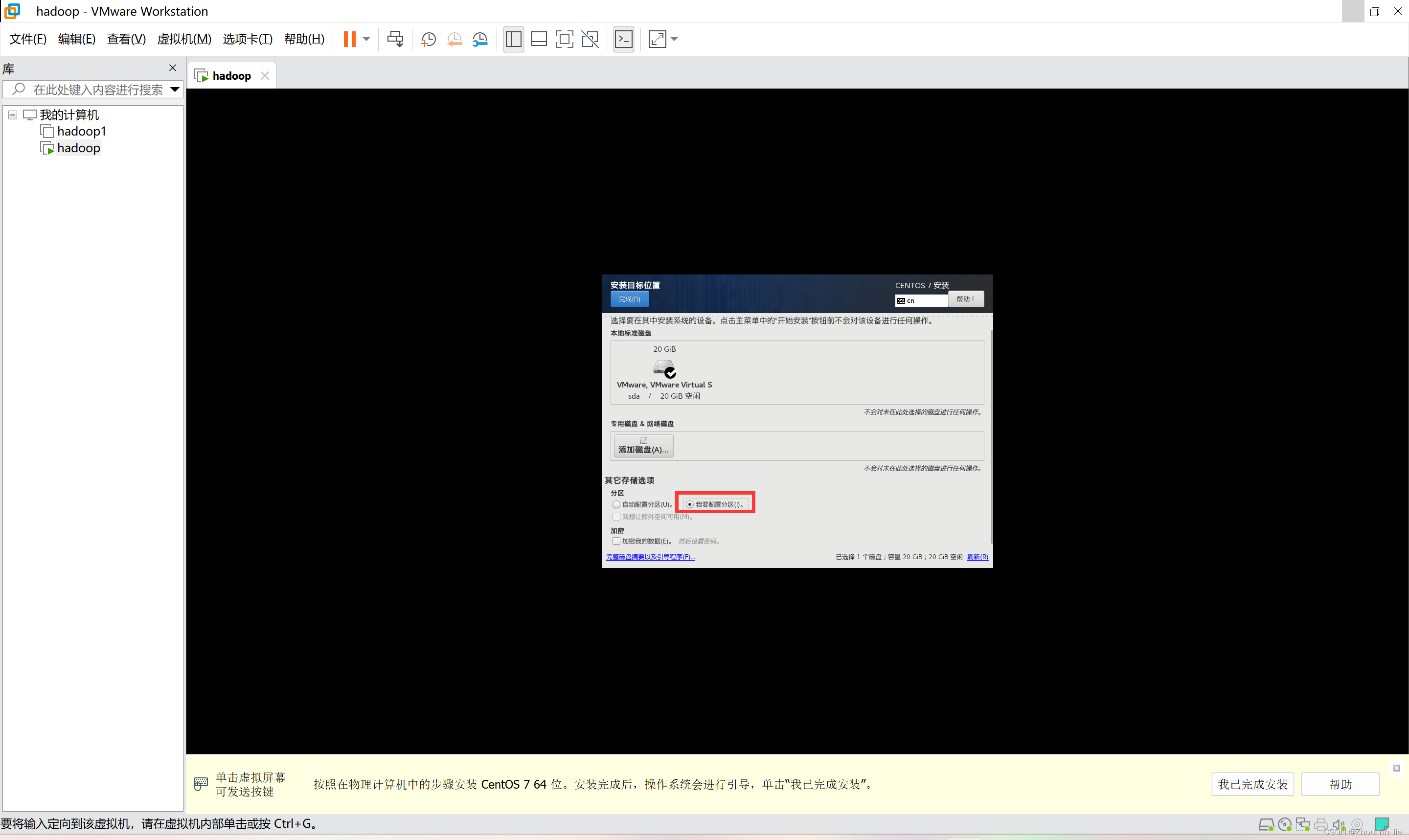
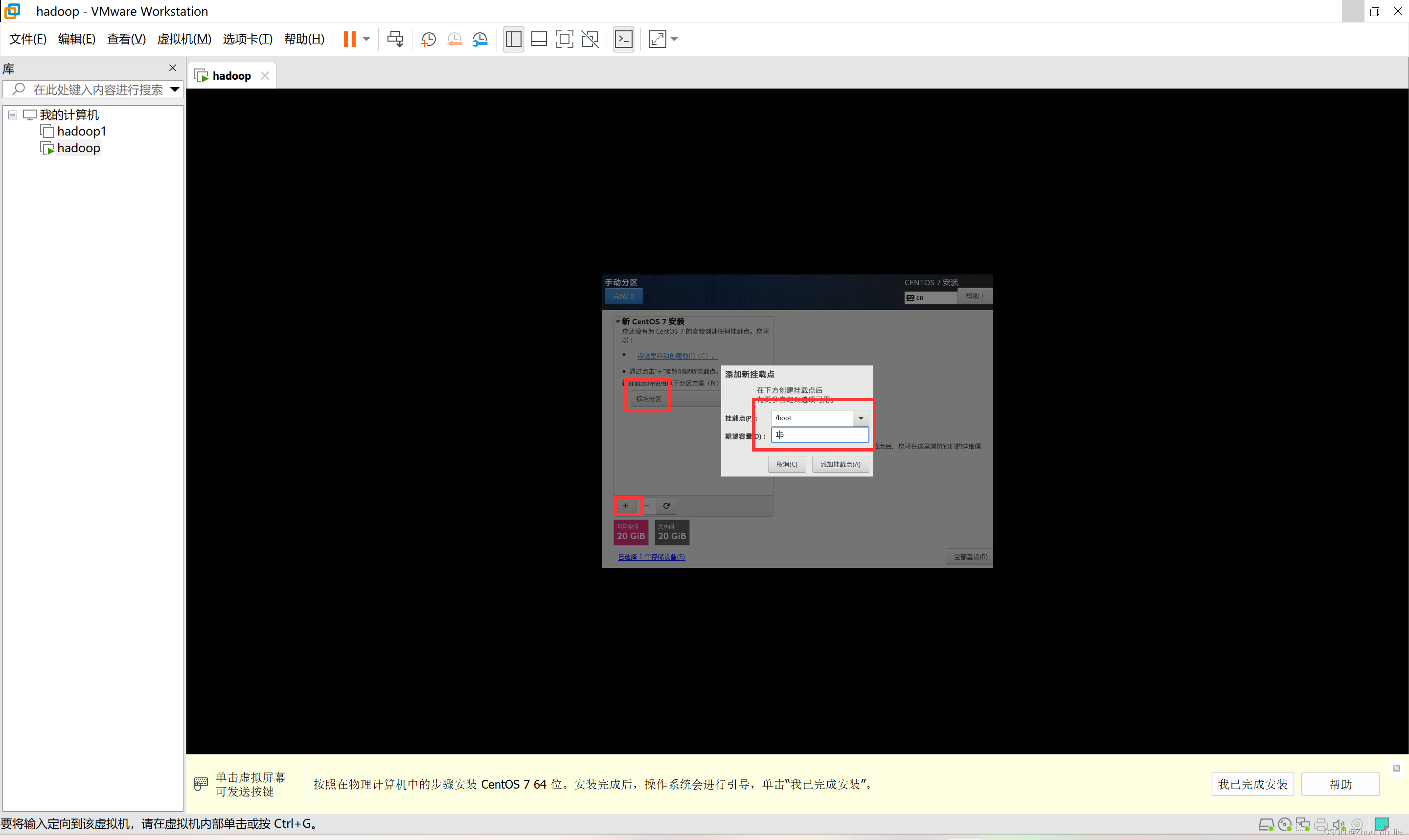
- 选择标准分区,添加挂载点/boot 分配1G空间
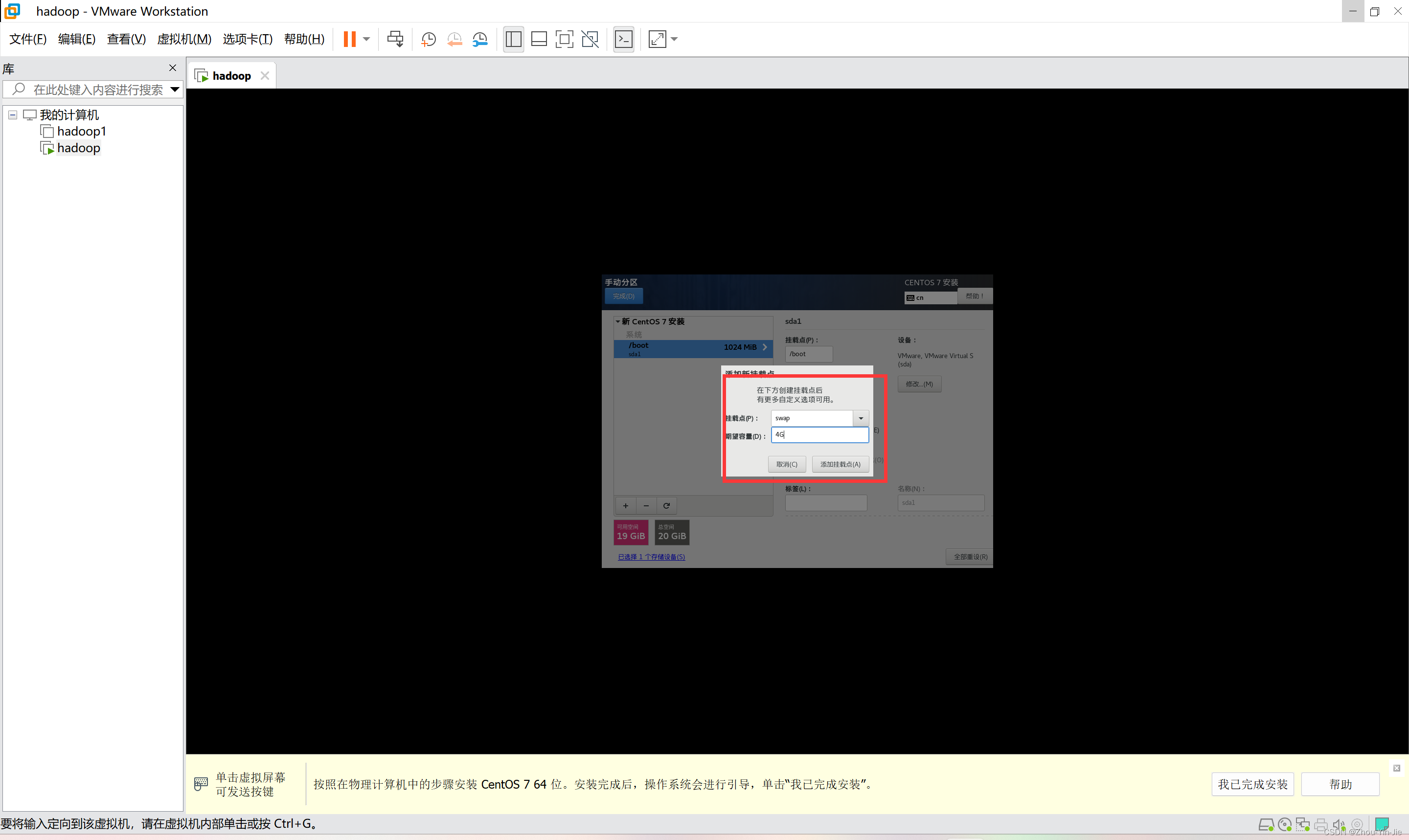
- 添加挂载点 swap 分配4G空间
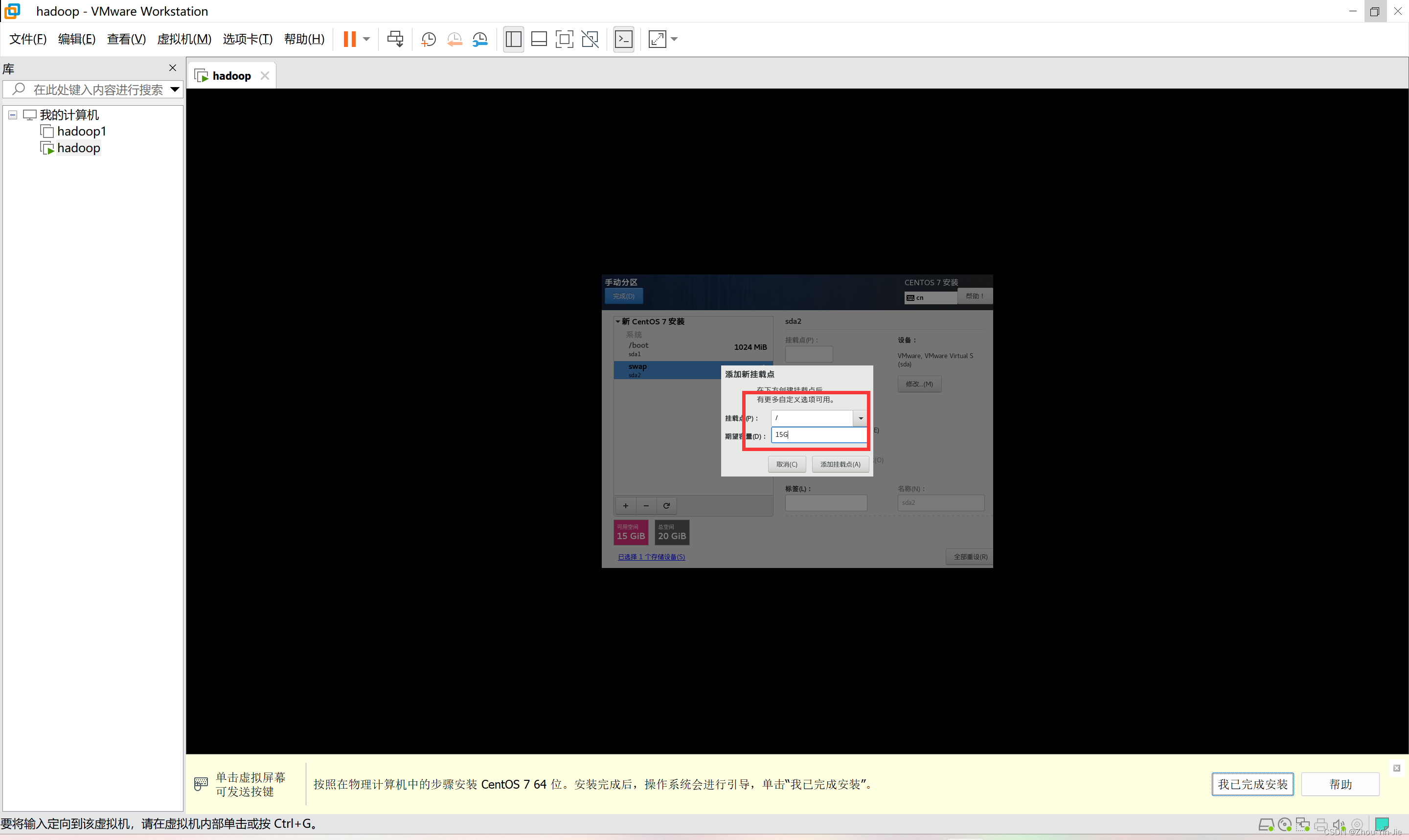
- 添加挂载点,分配剩下的空间,点击完成
- 点击主机名,设置一个方便识别的主机名,点击完成。
- 点击开始安装
- 在安装的过程中,设置root用户的密码,可根据自己的需求添加普通用户。
- 等待安装完成
3.配置静态ip
- 点击编辑,网络设置。记住这个子网ip等会需要使用。
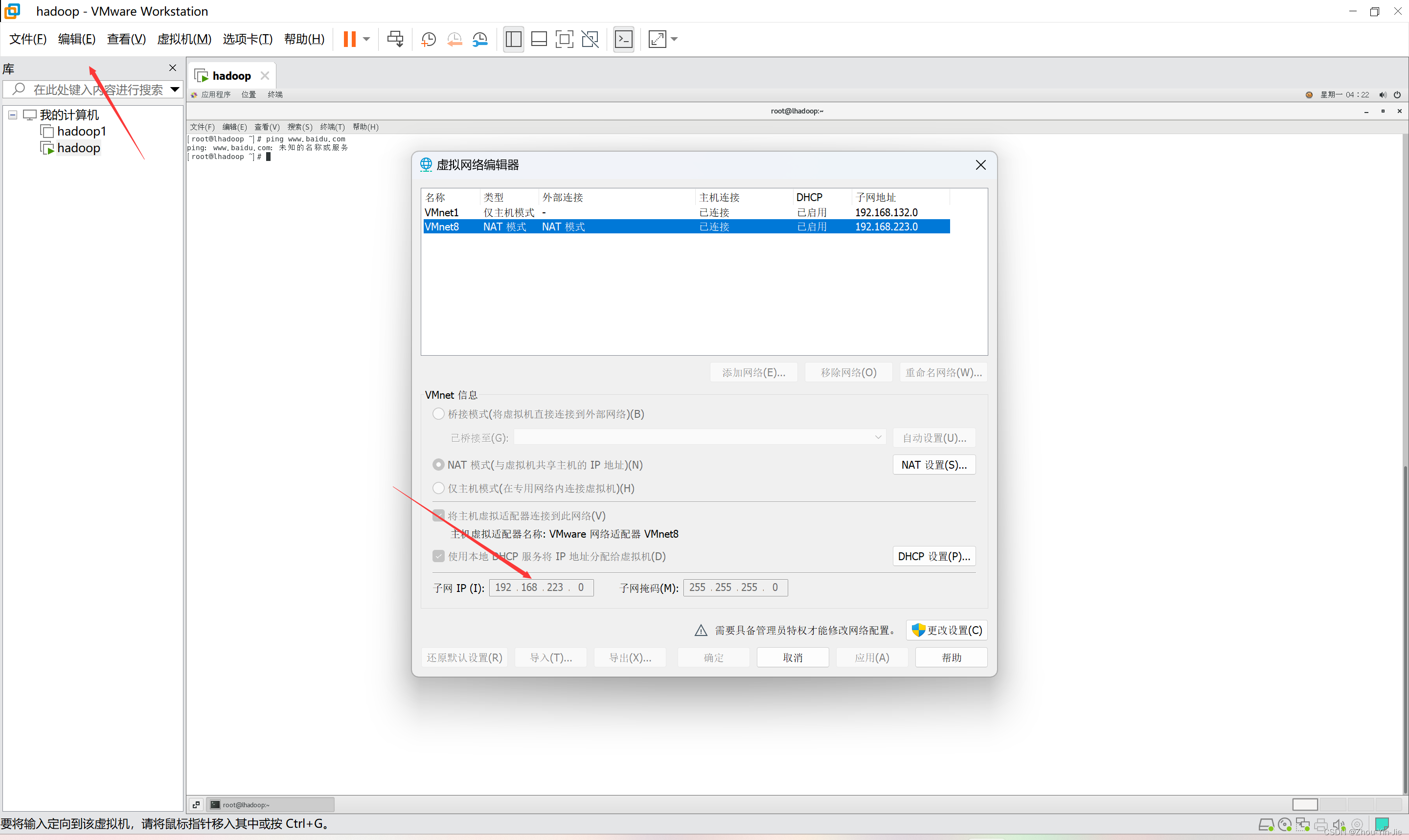
- 编辑网卡
vim /etc/sysconfig/network-scripts/ifcfg-ens33
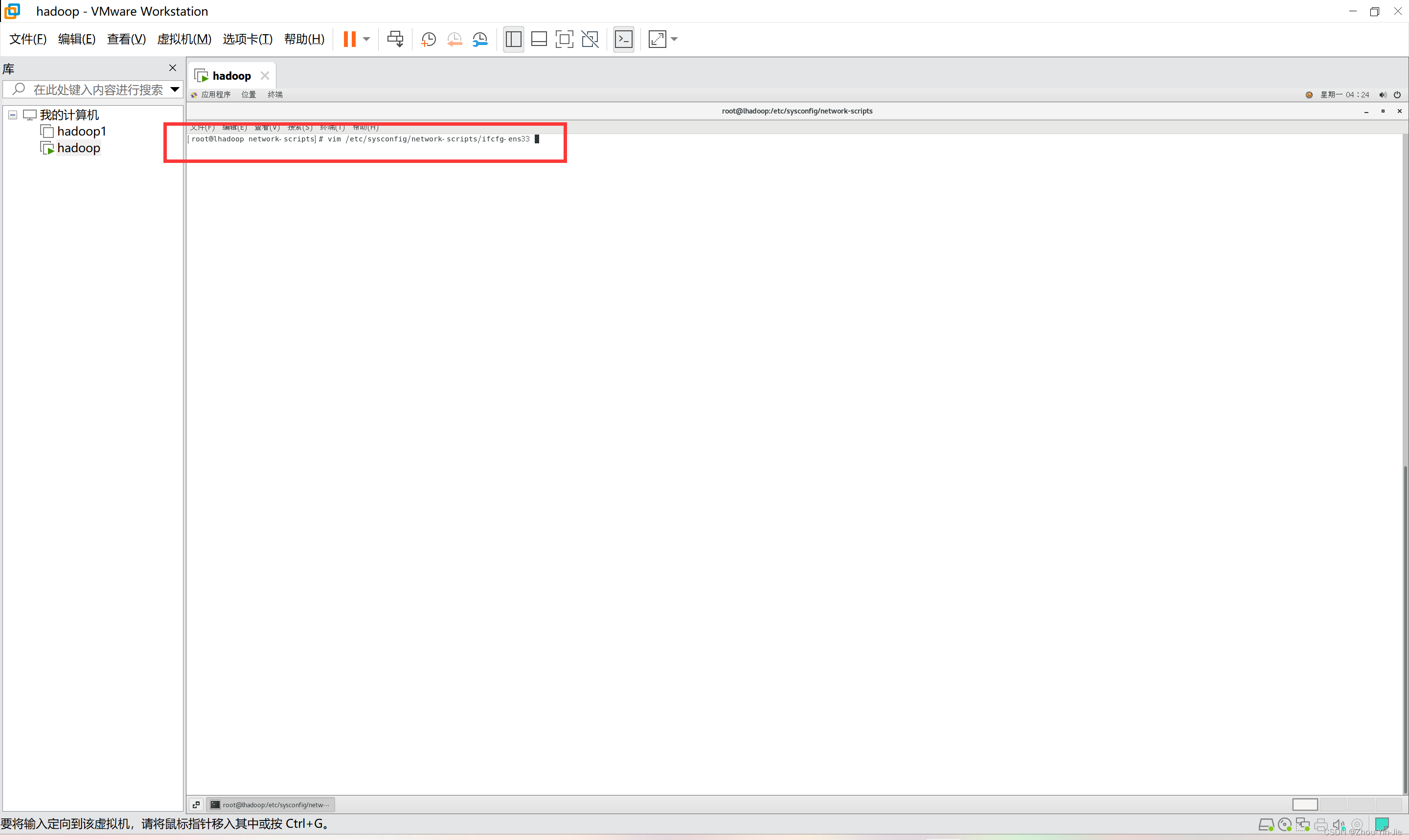
- 编辑文件 - 红框中是需要修改的内容- BOOTPROTO:改为静态模式,static- ONBOOT:开机自启,改为yes- IPADDR: 这个ip是自定义的静态ip, 需要在上面的那个网关下设置相应的IP地址。- GATEWAY:网关,就是上面的网关。- DNS1:DNS服务器,与网关地址一样即可。

- 执行网络重启命令或者重启虚拟机
systemctl retsart network
- 切换到超级管理员角色
su root
- 下载网络工具包
yum -y update
yum install -y net-tools
- 查看本机的IP
ifconfig
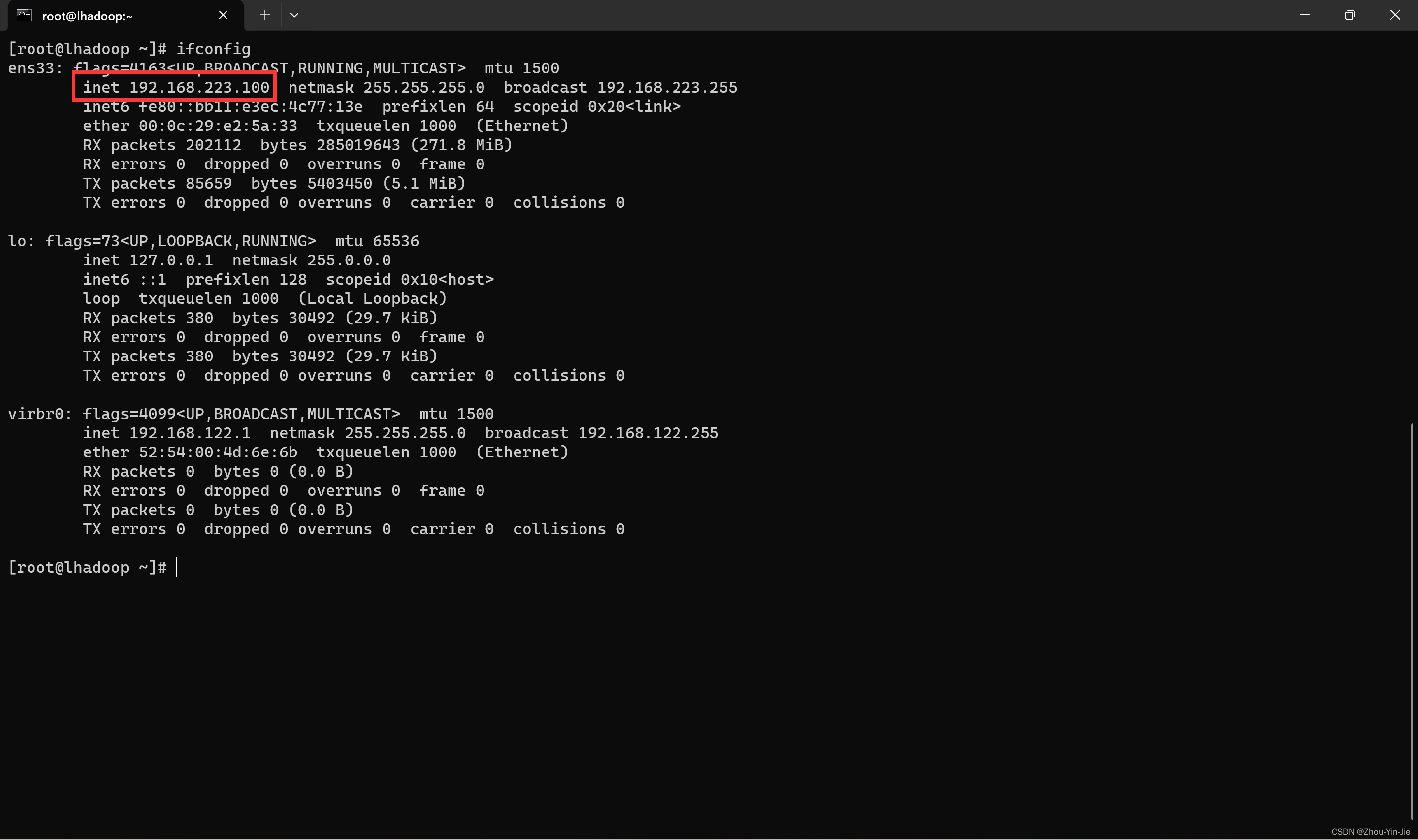
- 至此,静态IP已经设置完成。
- 关闭防火墙
systemctl stop firewalld
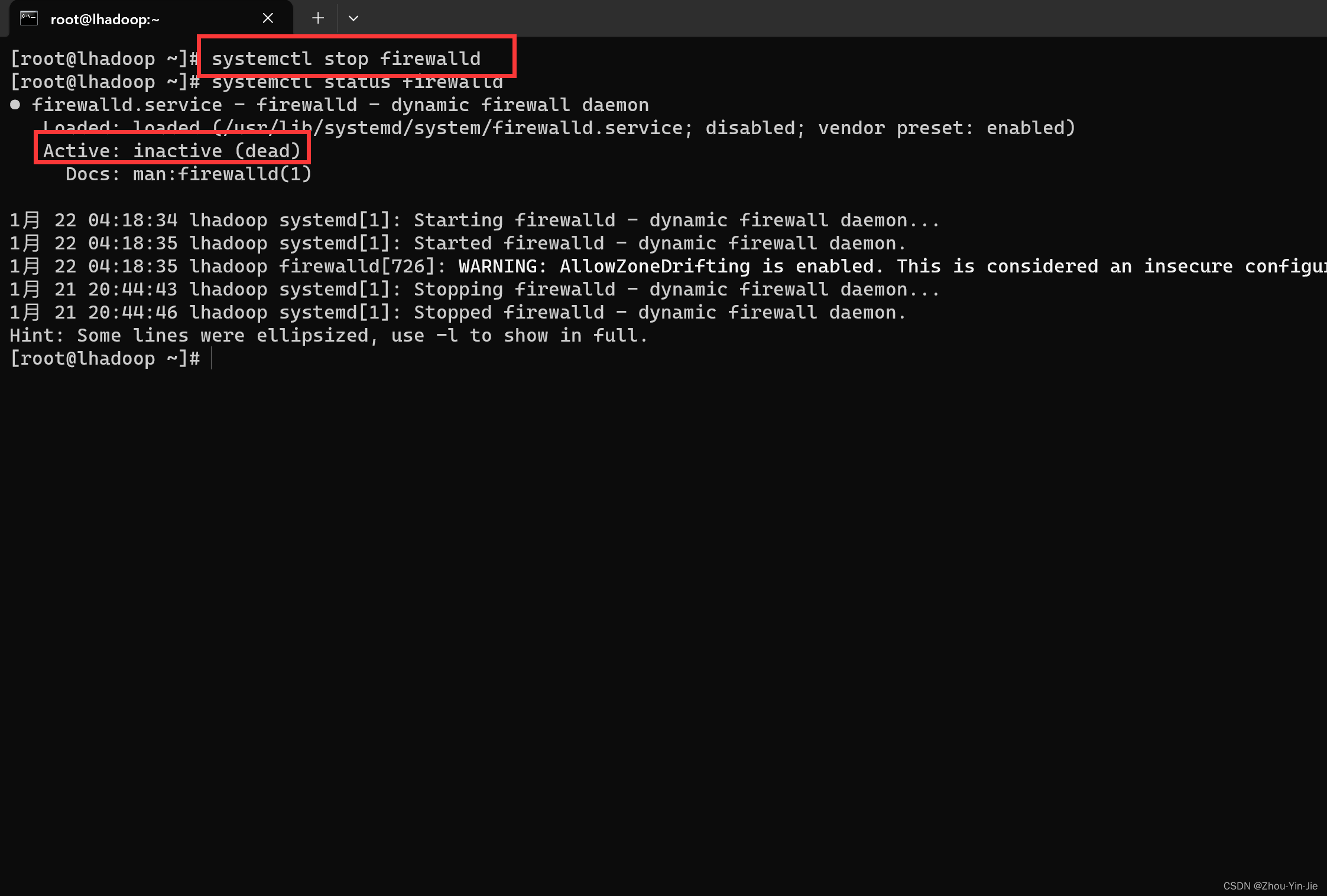
- 验证主机与虚拟机之间可不可以通信
主机:ping虚拟机ip
ping192.168.223.100
虚拟机:ping主机ip
ping 主机ip
4.安装JDK
- 利用文件传输软件将linux版的JAVA JDK传输到虚拟机中。

- 解压
tar-zxvf jdk-8u391-linux-x64.tar.gz
- 删除自带的JDK - 找出所有的java
rmp -qa|grepjava
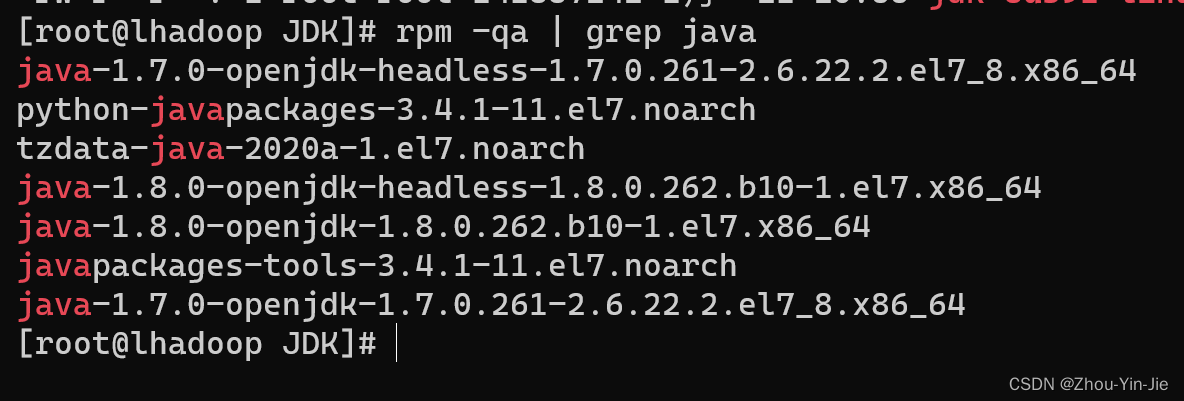
删除自带的即可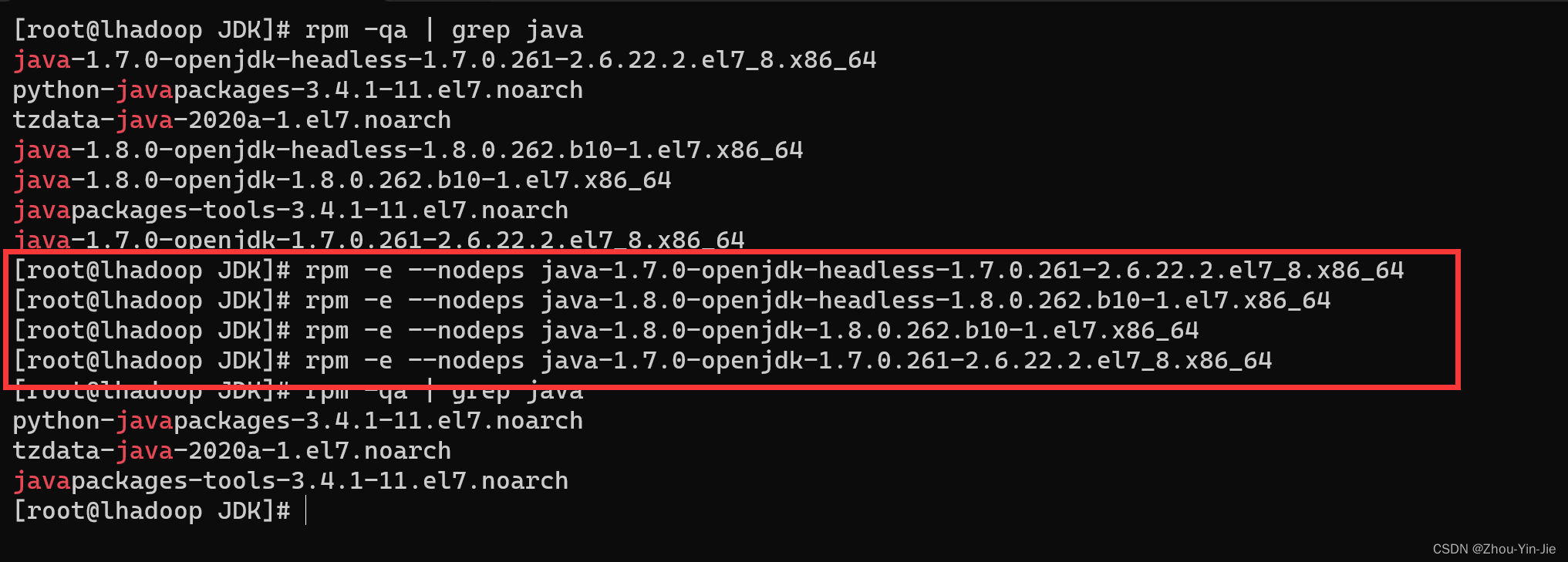 * 配置Java环境变量
* 配置Java环境变量
vim /etc/profile
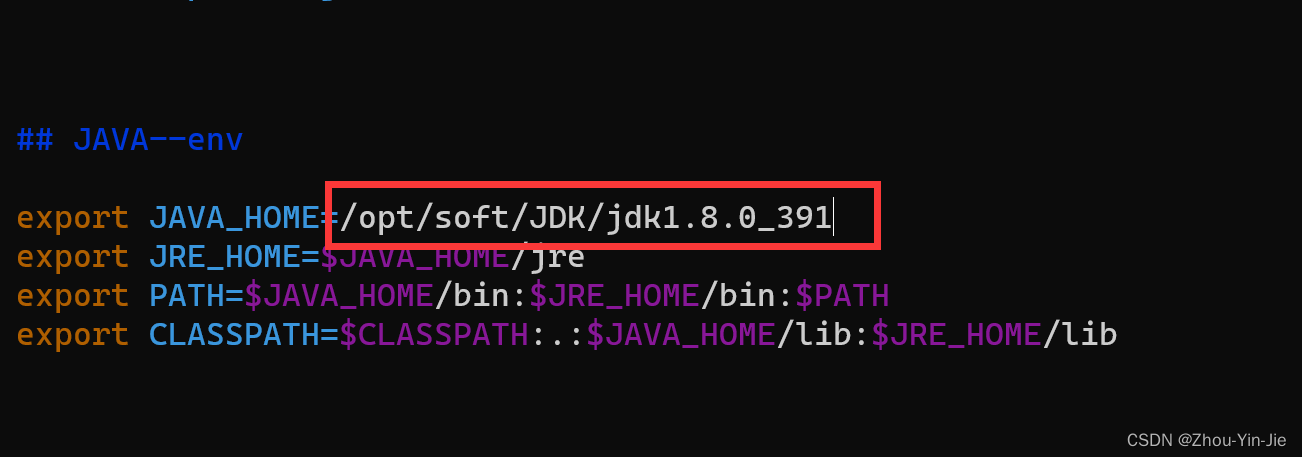
红框里面的需要填写自己JDK所在的地址
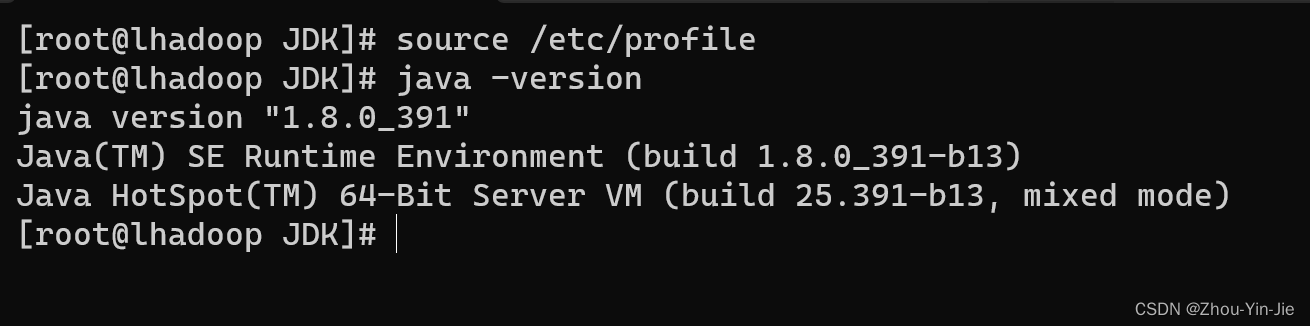
- 刷新配置文件并验证
source /etc/profile
java-version
5.安装hadoop
- 上传hadoop到虚拟机
- 解压
tar-zxvf hadoop-2.10.2.tar.gz

- 进入Hadoop的配置文件

- 配置编辑hadoop-env.sh中java的位置- hadoop-env.sh
vim hadoop-env.sh

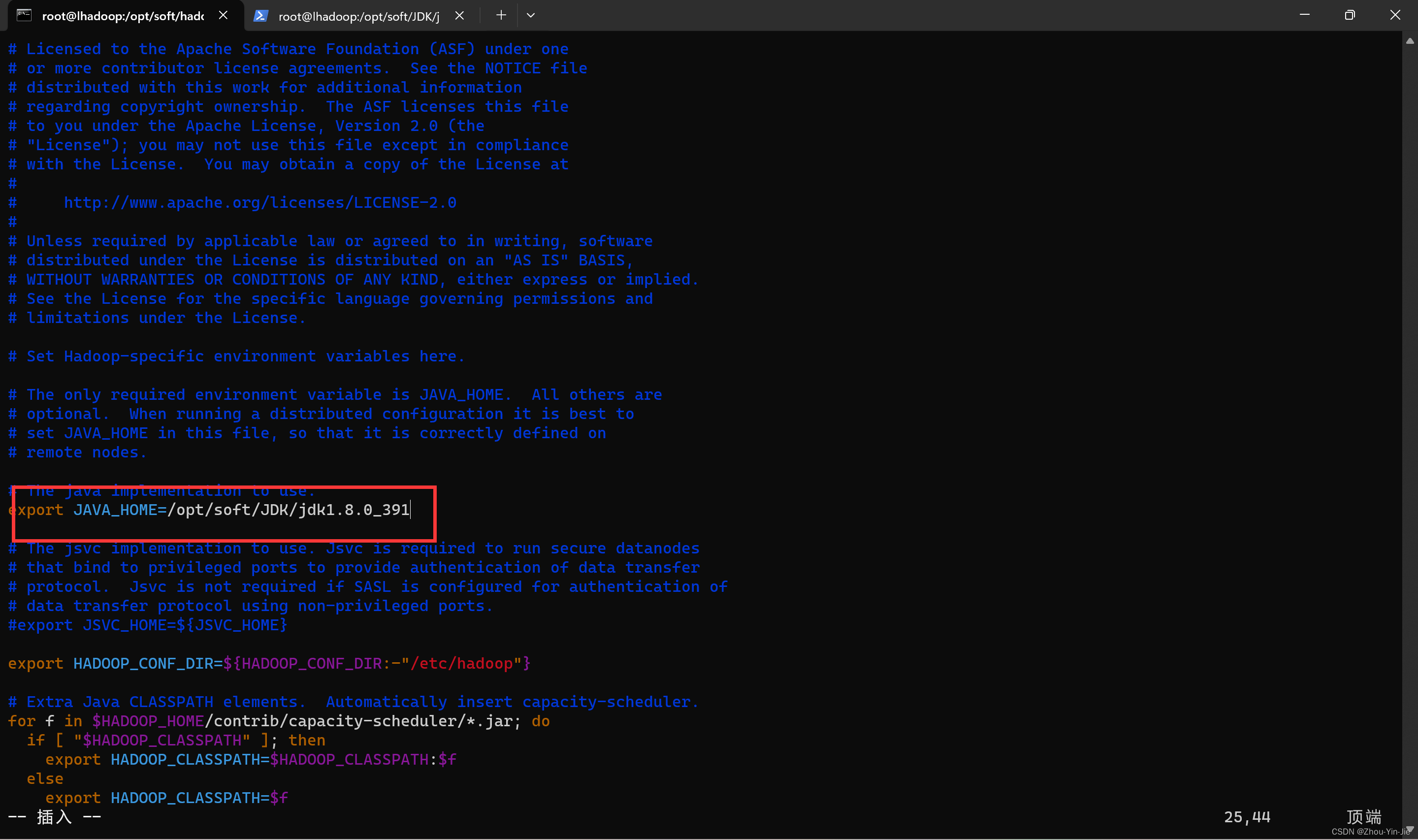
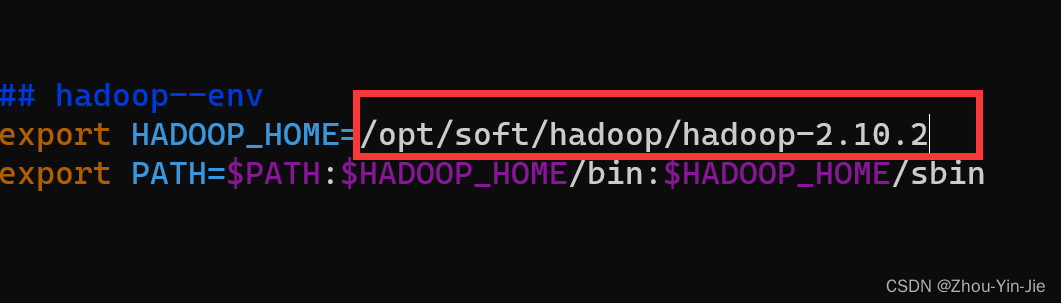
- 配置hadoop环境变量
vim /etc/profile
配置完成之后刷新环境变量配置
source /etc/profile
- 需要修改如下红框中的配置文件,注意mapred-site.xml.template 需要更名为mapred-site.xml

- core-site.xml
<configuration><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property><!-- 指定hadoop运行时产生文件的存储路径 --><property><name>hadoop.tmp.dir</name><!-- 配置到hadoop目录下temp文件夹 --><value>file:/opt/soft/hadoop/hadoop-2.10.2/tmp</value></property></configuration>
- hdfs-site.xml
<configuration><property><name>dfs.namenode.http-address</name><value>192.168.223.100:9870</value></property><property><!--指定hdfs保存数据副本的数量,包括自己,默认为3--><!--伪分布式模式,此值必须为1--><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name><value>file:/opt/soft/hadoop/hadoop-2.10.2/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/opt/soft/hadoop/hadoop-2.10.2/dfs/data</value></property></configuration>
- mapred-site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property></configuration>
- yarn-site.xml
<configuration><!-- Site specific YARN configuration properties --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property></configuration>
- 验证启动
启动命令:过程中需要自己输入密码
start-all.sh
查看是否启动命令:
jps
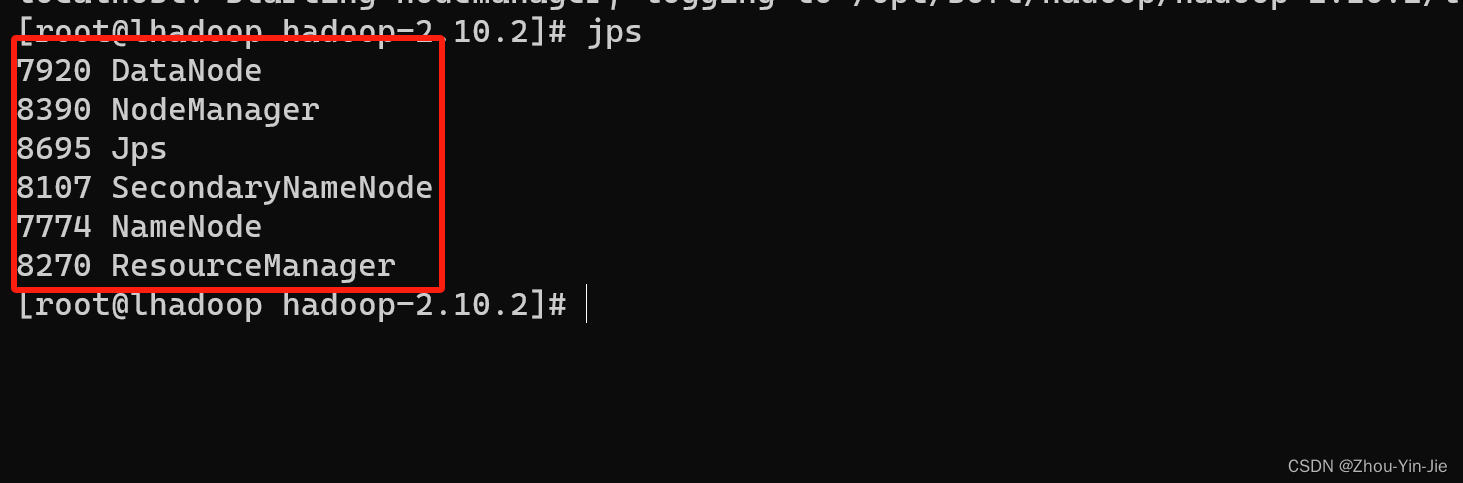
如何出现以上6个就表示单节点的hadoop启动成功。
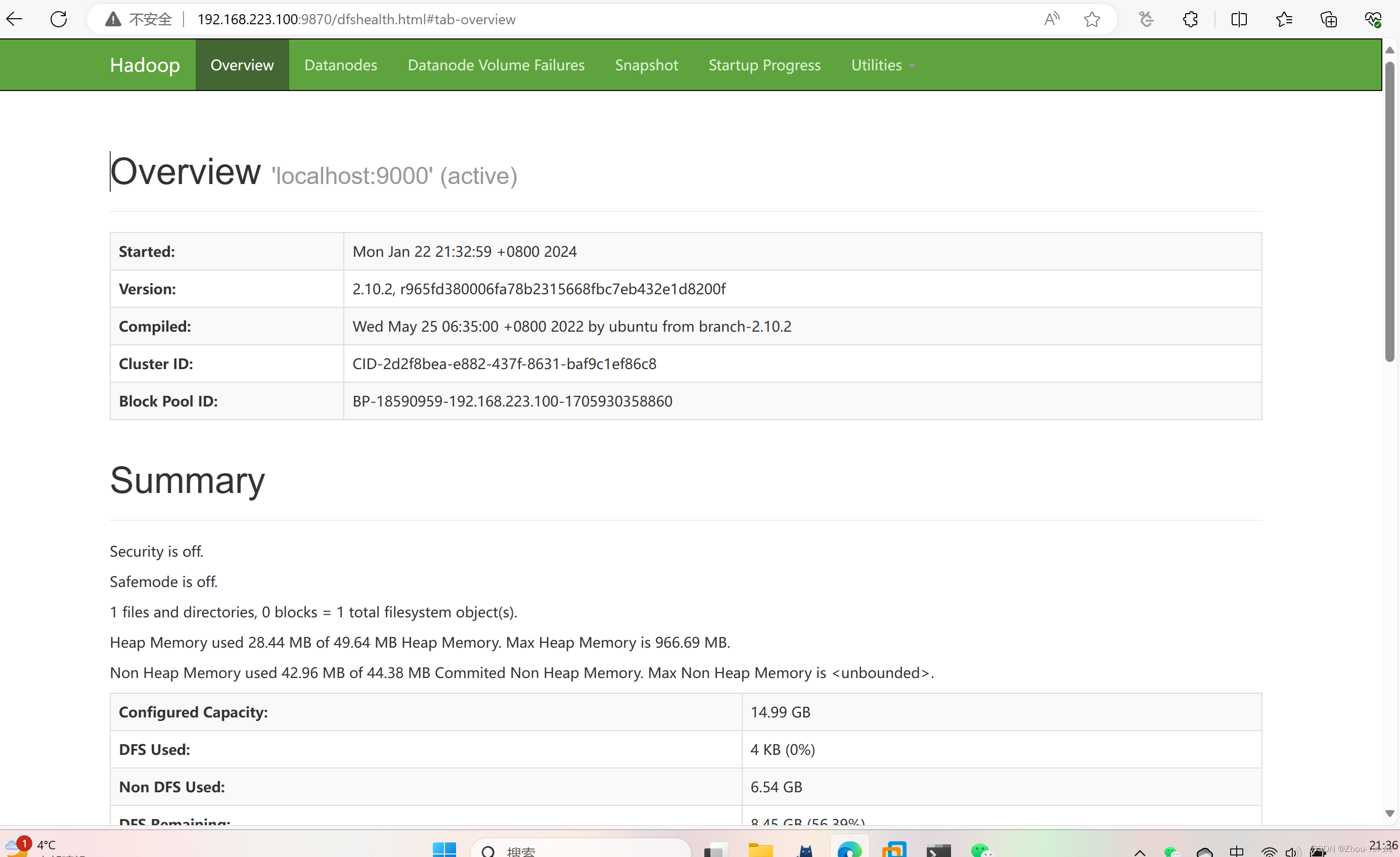
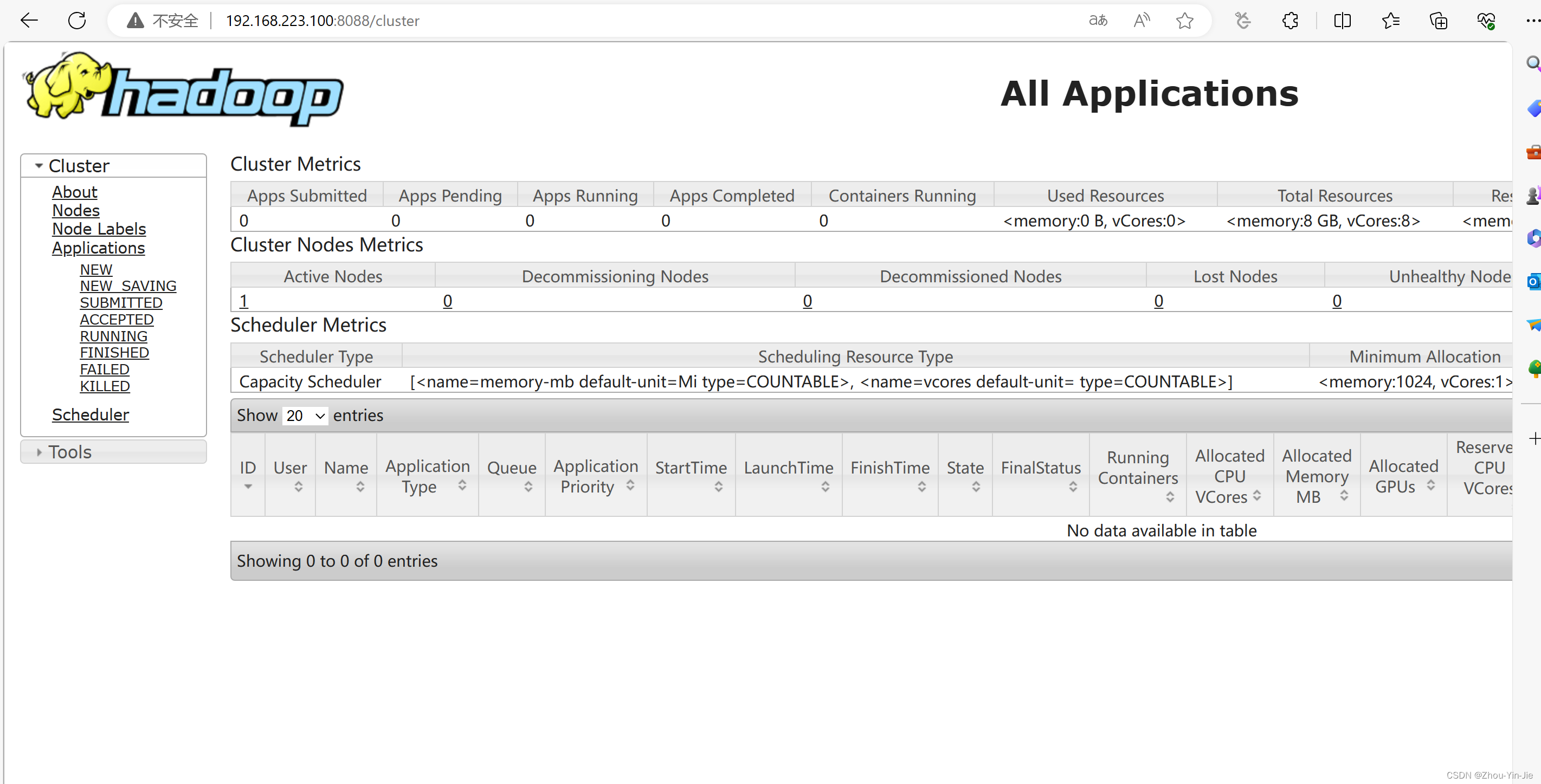
- 浏览器验证有两个端口:9870、8088
在地址栏输入IP+端口即可访问
192.168.223.100:9870
192.168.223.100:8088
TIP NameNode启动不成功
NameNode format每次都会新建一个新的namenodeld,而tmp/dfs/data包含了上次format下的id,NameNode format清空了namenode下的数据,但是没有清空datanode下的数据,导致启动失败。
- 执行以下命令解决问题
执行下面命令的时候。需要切换到hadoop的安装目录(包含bin的目录)。
# 1.先停掉hadoop
stop-all.sh
# 2.将tem目录删除掉,这个目录是上面配置文件中配置的目录,所以可能所在的位置和我不一样,只要删除即可。rm-rf temp
# 3.执行NameNode格式化命令
./bin/hdfs namenode -format# 4.启动hadoop
start-all.sh
本文转载自: https://blog.csdn.net/qq_57074721/article/details/135733135
版权归原作者 Zhou-Yin-Jie 所有, 如有侵权,请联系我们删除。
版权归原作者 Zhou-Yin-Jie 所有, 如有侵权,请联系我们删除。