
设置服务器的主机名称
[root@localhosth~]# ostnamectl set-hostname master
[root@localhosth~]# hostname
绑定主机名与 IP 地址
[root@master ~]# vi /etc/hosts
192.168.130.10 master
****关闭防火墙 ****
[root@master ~]# systemctl stop firewalld
关闭防火墙后要查看防火墙的状态,确认一下。
[root@master ~]# systemctl status firewalld
[root@master ~]# systemctl disable firewalld
下载 JDK 安装包
卸载自带 OpenJDK
[root@master ~]# rpm -qa | grep java
[root@master ~]# rpm -e --nodeps +包
****安装 JDK ****
[root@master ~]# tar -zxvf /opt/software/jdk-8u152-linux
x64.tar.gz -C /opt
[root@master ~]# ll /opt
设置 JAVA 环境变量
[root@master ~]# vi /etc/profile
JAVA_HOME 指向 JAVA 安装目录
export JAVA_HOME=/opt/jdk1.8.0_152
执行 source 使设置生效:
[root@master ~]# source /etc/profile
检查 JAVA 是否可用。
[root@master ~]# echo $JAVA_HOME
****安装 Hadoop 软件 ****
解压tar -zxvf /opt/software/hadoop-2.7.1.tar.gz -C /opt
mv /usr/local/src/hadoop-2.7.1 /usr/local/src/hadoop
在文件末尾添加以下配置信息
[root@master ~]# vi /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_281-amd64
export HADOOP_HOME=/sur/local/hadoop-3.1.4
export HADOOP_CONF_DIR=/usr/local/hadoop-3.1.4/etc/hadoop
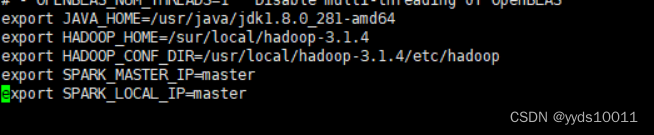
export SPARK_MASTER_IP=master
export SPARK_LOCAL_IP=master
使用 命令vi hadoop-env.sh mapred-env.sh yarn-env.sh 在这三个文件末尾添加如下所示内容:
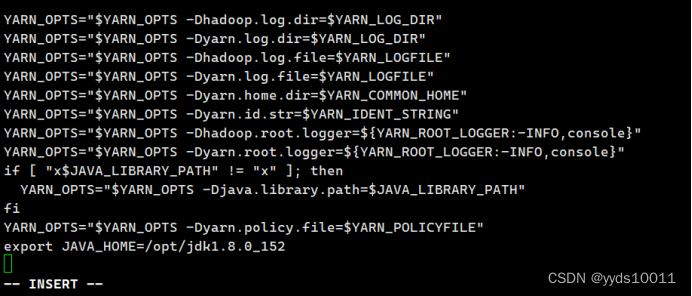
export JAVA_HOME=/opt/jdk0.8.0_152
[root@master hadoop]# vi hadoop-env.sh


[root@master hadoop]# vi mapred-env.sh


[root@master hadoop]# vi yarn-env.sh
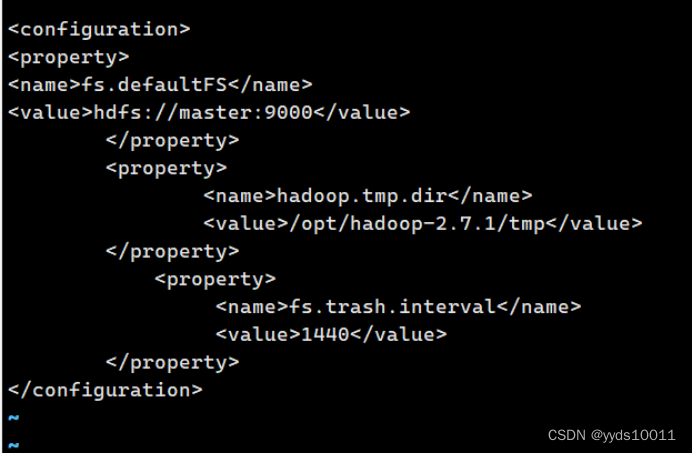
配置 core-site.xml.
[root@master hadoop]# vi core-site.xml
<configuration> <property><name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.7.1/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
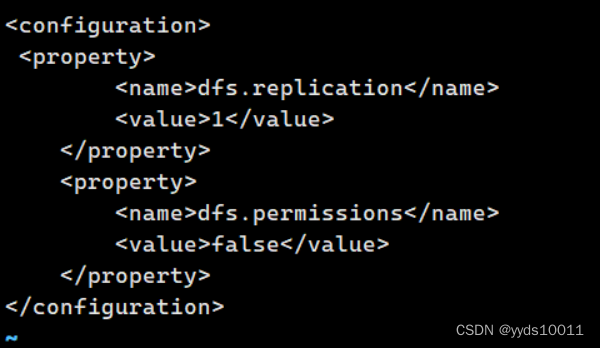
配置 hdfs-site.xml
[root@master hadoop]# vi hdfs-site.xml
<configuration> <property> <name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
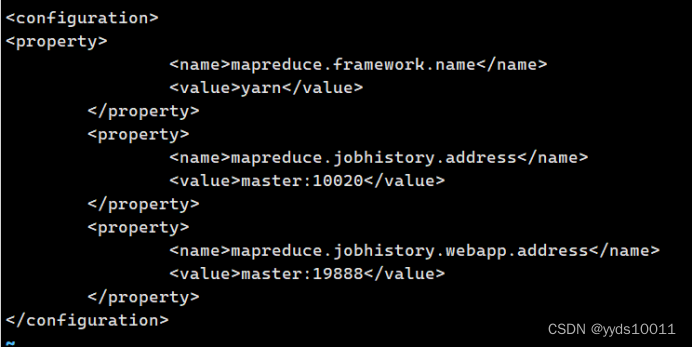
将 mapred-site.xml.template 复制一份为 mapred-site.xml,再配置 mapred-site.xml
[root@master hadoop]# cp mapred-queues.xml.template mapred-site.xml
[root@master hadoop]# vi mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
配置本机 ssh 免密登录
[root@master hadoop]# yum install openssh-server

安装 ssh 客户端。命令: yum install openssh-client
[root@master hadoop]# yum install openssh-client
NameNode格式化
执行如下命令,格式化 NameNode
[root@master ~]# su – hadoop
[hadoop@master ~]# cd /opt/hadoop/
[hadoop@master hadoop]$ bin/hdfs namenode –format
执行如下命令,启动 NameNode:
[hadoop@master hadoop]$ hadoop-daemon.sh start namenode
[hadoop@master hadoop]$ jps
启动 SecondaryNameNode
[hadoop@master hadoop]$ hadoop-daemon.sh start secondarynamenode
[hadoop@master hadoop]$ jps
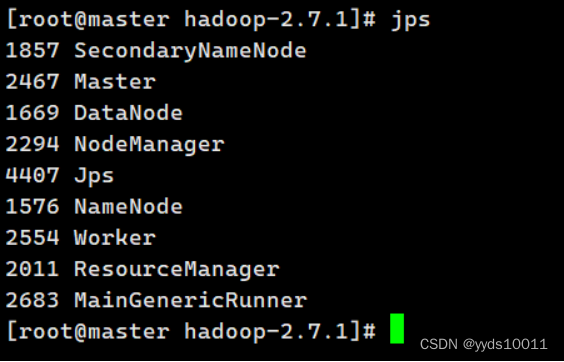
使用浏览器查看节点状态
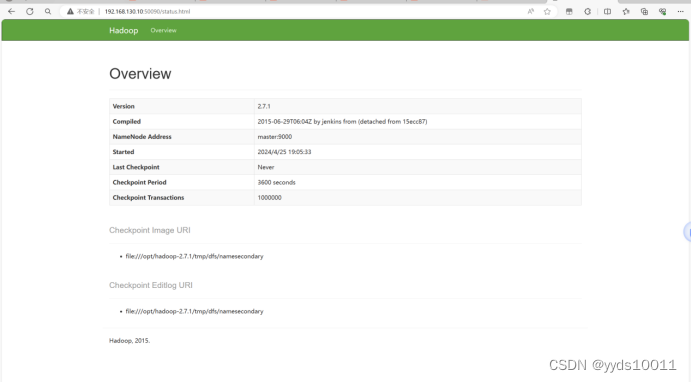
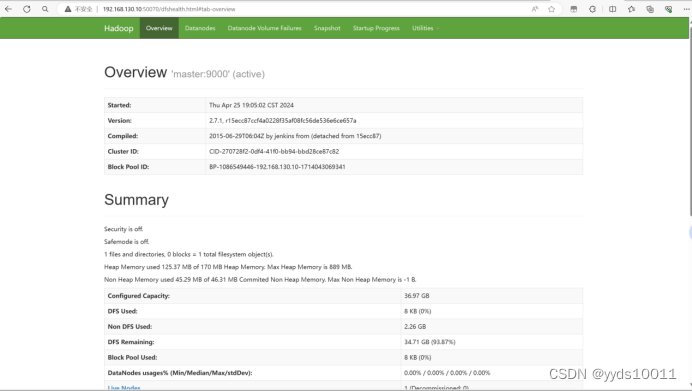
(一).搭建spark
1.解压spark包
tar -axf spark-2.0.0-bin-hadoop2.7.gz -C /opt/


配置环境变量。
vi /etc/profile
export JAVA_HOME=/opt/java-1.8.0-openjdk-1.8.0.322.b06-1.el7_9.x86_64/
export HAD00P_H0ME=/home/hj/hadoop-2.7.7/
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
2.编写spark-env.sh
cp spark-env.sh.template spark-env.sh
[root@master conf]# vi spark-env.sh
把下列路径加入最后
export JAVA_HOME=/usr/local/src/jdk1.8.0_152 #指定jdk位置如没有需下载
export HADOOP_HOME=/opt/hadoop #指定hadoop路径
export HADOOP_CONF_DIR=/opt/hadoop/etc/hadoop #指定hadoop路径
export SPARK_MASTER_IP=master
export SPARK_LOCAL_IP=master
启动spark集群
[root@master spark-2.0.0-bin-hadoop2.7]# cd sbin/
[root@master sbin]# ./start-all.sh

jps查看是否拥有worker
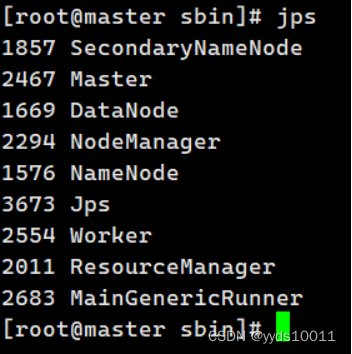
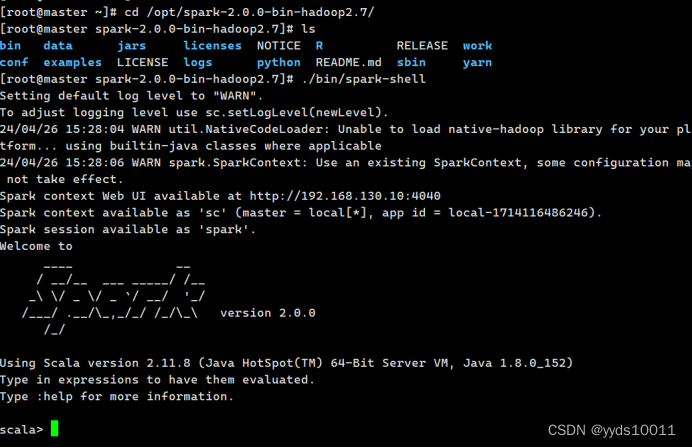
使用./bin/spark-shell 命令启动hadoop
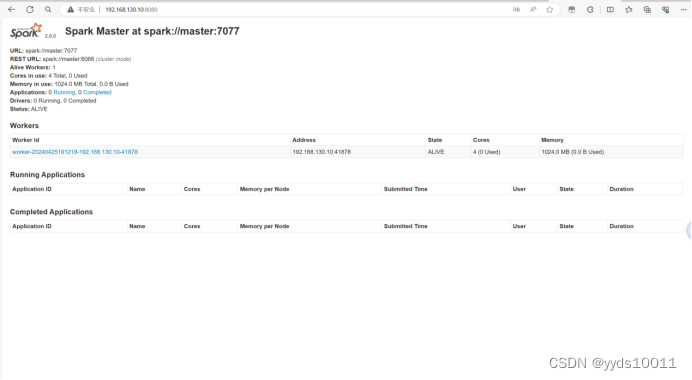
在浏览器输入ip地址+8080端口查看
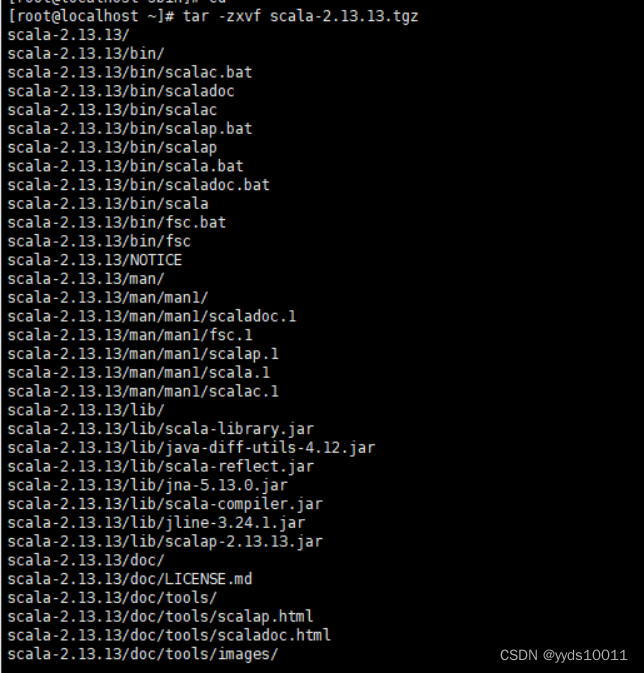
Scala部署安装步骤
[root@localhost ~]# tar -zxvf scala-2.13.13.tgz
编写/etc/profile在最下面添加如下路径
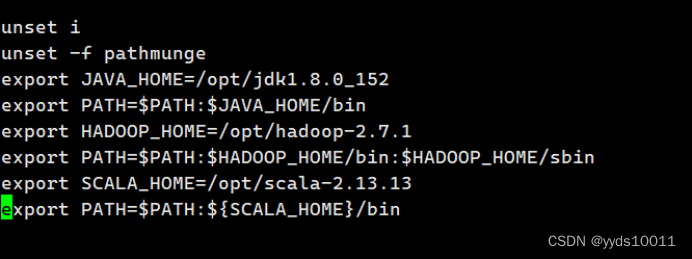
使用source /etc/profile来更新启用scala
最后在命令行输入scala即可

版权归原作者 yyds10011 所有, 如有侵权,请联系我们删除。