
一、环境配置
1.1 配置hadoop和java的环境变量
1.下载hadoop和jdk

2.在系统变量里配置HADOOP_HOME和JAVA_HOME,并配置PATH。

3.在cmd中输入以下代码查看是否配置成功
hadoop version
java -version

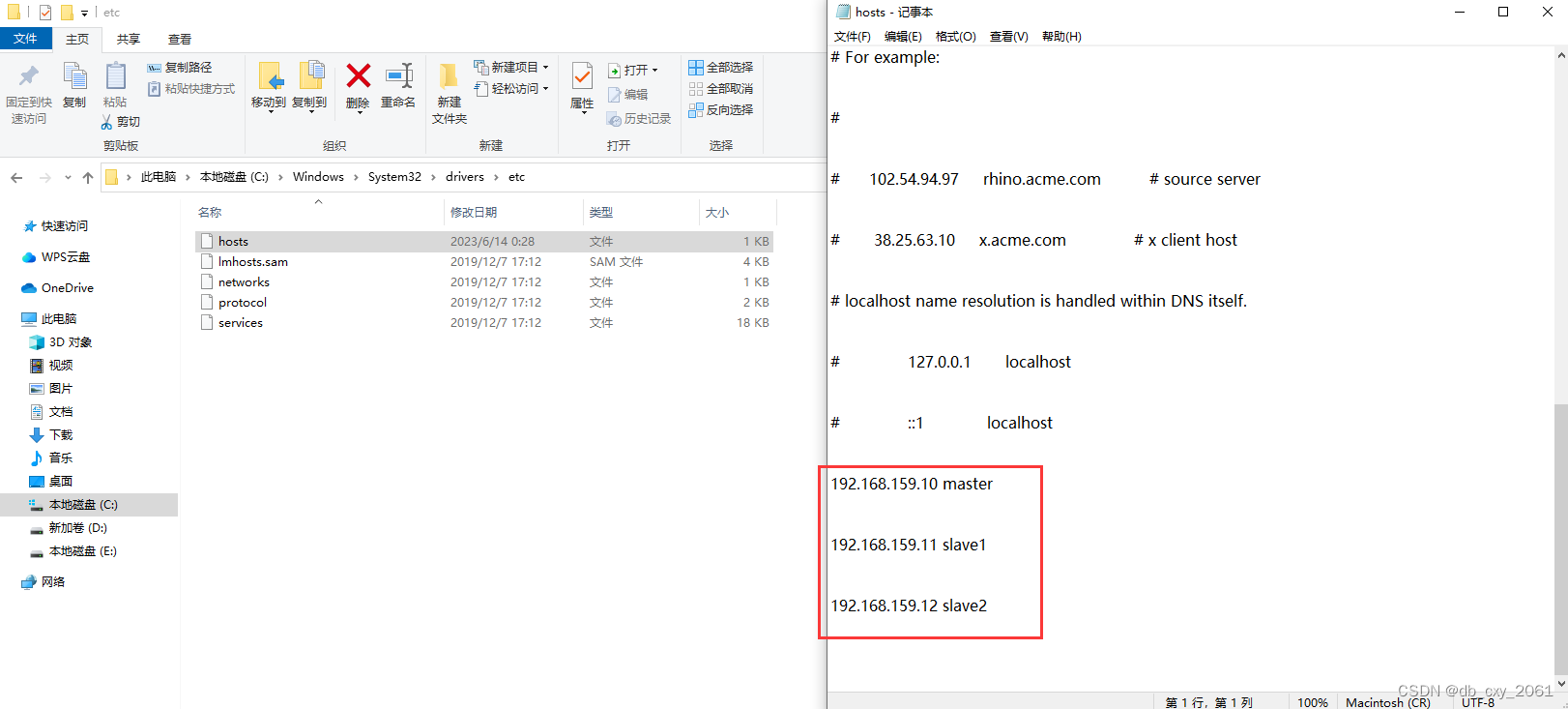
1.2 修改本地host文件
Windows本地是不知道我们在虚拟机中的ip和hostname的,我们需要手动修改windows系统本地文件,这样在写代码的时候windows能识别出我们虚拟机的host。
在 C:\Windows\System32\drivers\etc 中修改hosts文件,将虚拟机的hostname和ip写在文件底部
二、编写JAVA代码
2.1 导入hadoop_lib包
首先要下载hadoop_lib包,然后在IDEA里面导入这个包。

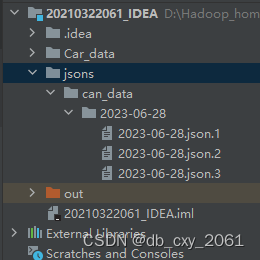
2.2 读取本地文件
本次要上传的文件如下
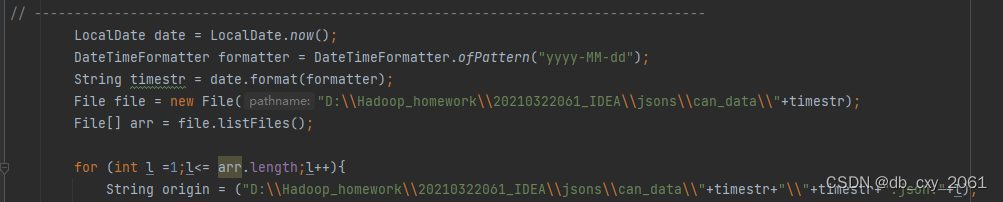
要一次性上传完这些文件,需要循环读取文件名字,代码如下
2.3 使用copyBytes方法将本地文件传入hdfs
IOUtils.copyBytes()方法:
IOUtils.copyBytes(in, out, 4096, false)
--in:是FSDataInputStream类的对象,是有关读取文件的类,也就是所谓“输入流”
--out:是FSDataOutputStream类的对象,是有关文件写入的类,也就是“输出流”
--4096表示用来拷贝的buffer大小(buffer是缓冲区)--缓冲区大小
--// true - 是否关闭数据流,如果是false,就在finally里关掉
先创建hdfs存储路径作为输出流,然后把本地文件存储路径作为输入流,利用copyBytes方法将本地文件上传到hdfs输出流的路径就大功告成了!! 代码如下↓

三、在hdfs中查看是否上传成功
输入以下代码查看hdfs里是否存在我们上传的文件
hdfs dfs -ls -R /can_data
hdfs中存在文件,上传成功!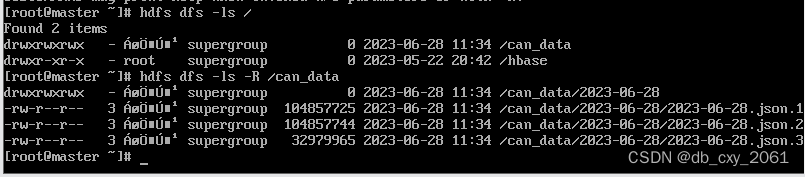
总结
本次利用java代码将本地文件上传到hdfs中,是hadoop中基础的操作之一。熟练并灵活地使用java,可以让大数据学生们很好地提升自己的能力,对大数据的理解也会更深刻。
本文转载自: https://blog.csdn.net/yanzhenjinghong/article/details/131432469
版权归原作者 db_cxy_2061 所有, 如有侵权,请联系我们删除。
版权归原作者 db_cxy_2061 所有, 如有侵权,请联系我们删除。