
大家好,小编来为大家解答以下问题,python拉取git提交的代码,pycharm上如何拉git代码,现在让我们一起来看看吧!

Source code download: 本文相关源码
基于Python实现自动拉取Git分支源码自动解析并执行SQL语句
by:授客 QQ:1033553122
1.代码用途
开发过程中,研发人员会提交SQL更新脚本到Git源码库,然后测试负责去拉取这些SQL脚本,并手动在测试环境或其它环境的数据库中执行这些脚本,很麻烦,本代码的用途就是为了替代手工执行的操作
2.测试环境
Win7 64位
Python 3.3.2
git-credential-winstore.exe
下载地址:
https://pan.baidu.com/s/1hsehGjU
mysql-connector-python-2.1.4-py3.3-winx64.msi
Git-2.13.1.2-64-bit.exe
TortoiseGit-1.8.14.0-64bit.msi
atlassian-bitbucket-5.1.1-x64.exe
3.设计思路
大致思路如下:
->> 1-1 如果是首次运行程序,创建基线文件和基线变量,递归遍历本地目标目录下的SQL文件,然后根据待执行SQL文件所属数据库(例中为ddtm|ddtmk)和操作类型(例中为更新|回滚),分别记录到不同的基线文件,同时也记录到对应的基线变量中
->> 1-2 如果非首次运行程序,从基线文件读取已执行过的文件到对应的基线变量
->> 2 切换到本地目标分支
->> 3 PULL Git远程分支merge到本地目标分支
->> 4 递归遍历本地目标目录下的SQL文件,然后根据待执行SQL文件所属数据库和操作类型,分别记录到不同非基线变量
->> 5 对比基线变量和非基线变量,过滤得出待执行的SQL脚本文件,根据所属数据库和操作类型,分别存入不同变量
->> 6 按操作顺序执行这些变量中的SQL脚本(先执行更新,再执行回滚,再执行更新)
6.1 针对每个变量,排序好SQL文件(例中为按文件名),接着按排序后的顺序,解析每个SQL文件
6.1.1针对每个SQL文件,先解析得到单个文件中所有待执行SQL语句,并按文件中SQL语句编写顺序存储,然后执行每条SQL语句,根据执行结果分别记录结果到不同的文件
6.1.2 等待单个SQL文件中的SQL都执行完成,更新该文件信息至对应的基线文件
4.使用方法
- 安装好相关软件,特别是git-credential-winstore.exe
安装好该软件后,手动执行一次Git PULL操作,目的在于存储凭据,以便后续执行Git相关操作时,免输入密码操作
2)配置程序用数据库
编辑配置文件conf/dbconfig.conf
[DDTM]
host = 192.168.1.100
port = 3306
user = testacc
passwd = test1234
db = ddtm
charset = utf8
[DDTMK]
host = 192.168.1.100
port = 3306
user = testacc
passwd = test1234
db = ddtmk
charset = utf8
3)配置需要遍历的目标目录(SQL文件所在目录)
编辑配置文件conf/dirpath_init.conf
[INITCONF]
dir_path = E:\Git\ddt-core-ws\ddt-db\db\V6.8
4)git初始化配置
编辑配置文件conf/git_init.conf
[INITCONF]
git_remote_hostname = origin
remote_branchs_to_pull = ['master']
local_branch = master
path_to_local_branch = E:/Git/ddt-core-ws
说明:
git_remote_hostname: 远程主机名称
remote_branchs_to_pull: 需要拉取的远程分支,格式为列表形式,形如['master', 'feature/V1.1']
local_branch:需要切到至的本地目标分支,要求必须已在本地经创建该分支
path_to_local_branch:本地分支源码所在路径,依葫芦画瓢 ,注意用 /分隔
5)执行程序
推荐写成批处理,然后用windows定时任务跑,如下
cd /d D:\auto_exec_sql
python main.py
start D:\auto_exec_sql\filerecord\file_for_failure.txt
说明:
start D:\auto_exec_sql\filerecord\file_for_failure.txt
该命令用于执行完毕后自动打开存放执行SQL失败的文件,方便查看
每条sql语句执行结果包含以下几个方面
执行的sql
执行时间
所在的文件(全路径)
操作的数据库
执行失败的原因
注意:
<1> 每次允许程序,执行成功、失败的记录都会分别追加到file_for_failure.txt,file_for_success.txt,为了方便查看执行结果,建议适时清空file_for_failure.txt内容。(为何不以’w’方式打开呢?如果是定时任务跑,中途某次运行结果忘记查看了,那岂不是会因为覆盖,无法查询那次的执行结果?)
<2> 正常情况下,每次运行完成后,无更新的情况下,每个已执行过的文件都不会在下次运行中被执行,需要人工查看失败原因,并手工补充执行操作
<3> 如果想目标目录下的文件都被重新执行一次,则程序运行之前,手动放置四个空文件到filerecord目录下

5.源码下载地址
6.说明
本程序非通用程序,仅提供思路,针对不同项目,需要做适当的修改,方可用
程序使用限制如下
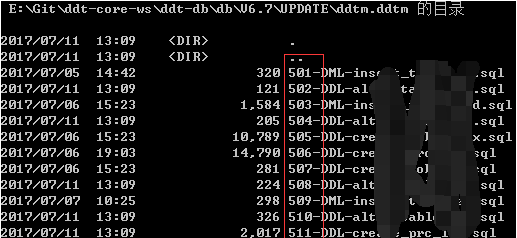
<1> 固定的目录组织结构,存放SQL文件的上级目录,及上级目录的父目录结构及名称,必须和以下一模一样,否则必须修改程序

<2> 脚本文件命名,必须数字打头,代表文件新增顺序,同时也代表其SQL语句执行顺序,如果目标目录包含了多个带
<1>结构的文档目录,那么要求每个SQL脚本的编号唯一,或者按名称升序排序能代表文件执行顺序
<3> 统一SQL脚本文件编码,暂时不支持不同编码的文件同时存在,目前定性为UTF-8-SIG(UTF-8无BOM格式编码)
<4> 不支持创建mysql存储过程,事件等,这类以DELIMITER
//开头,以DELIMITER
;结尾的SQL语句
<5> 存储过程,事件等除外,其它普通SQL,每条SQL语句之间必须以 ; 分号分隔
<6> 程序根据文件名称&文件最后修改时间组合值是否变化来判断文件是否被更新,是则会被执行
源码下载
程序重构:
自动感知新分支并自动拉去,自动切换到新目录进行脚本执行,支持不改代码,动态增加数据库
版权归原作者 2301_81895949 所有, 如有侵权,请联系我们删除。