
最近学习CNN,搭建CNN模型时看网上鱼龙混杂的博客走了不少歪路,决定自己来总结一下。
注意本教程未必对所有版本有效,请根据需要的版本适当调整。文章中配置的环境是Python 3.8.12 ,TensorFlow 2.3.0,Keras 2.4.3,构建自己的模型时TensorFlow是升级到了2.6.0。与文章中截图的中显示的版本可能略有不同,那是因为从我以前的笔记中截取的,请以文字为准
搭建环境
我们需要事先确定需要的Python、Keras以及TensorFlow版本。
以我为例,我想要构建自己的CNN模型,而且需要使用一些TensorFlow 2.3版本以后才支持的API,所以得安装比较新的版本,那么目前来说(2022.3.16)得需要Python 3.7以上的版本。
环境配置
Anaconda安装
方便起见,我们下载Anaconda用于环境搭建,Anaconda官网
点Download下载安装包即可。
下载完成打开安装程序
点击next
接受协议
为所有用户安装(为自己也行),这里会要管理员权限
选择安装位置
这个…英文能看懂吧,我就不翻译了,图省事我勾选了上方的配置系统变量,添加到我使用PyCharm所以也勾选了下方的,然后点Install安装即可。
创建Python环境
下一步我们来创建一个Python环境。这里使用GUI创建,如果熟悉的话命令行也可。
打开上一步安装的Anaconda Navigator
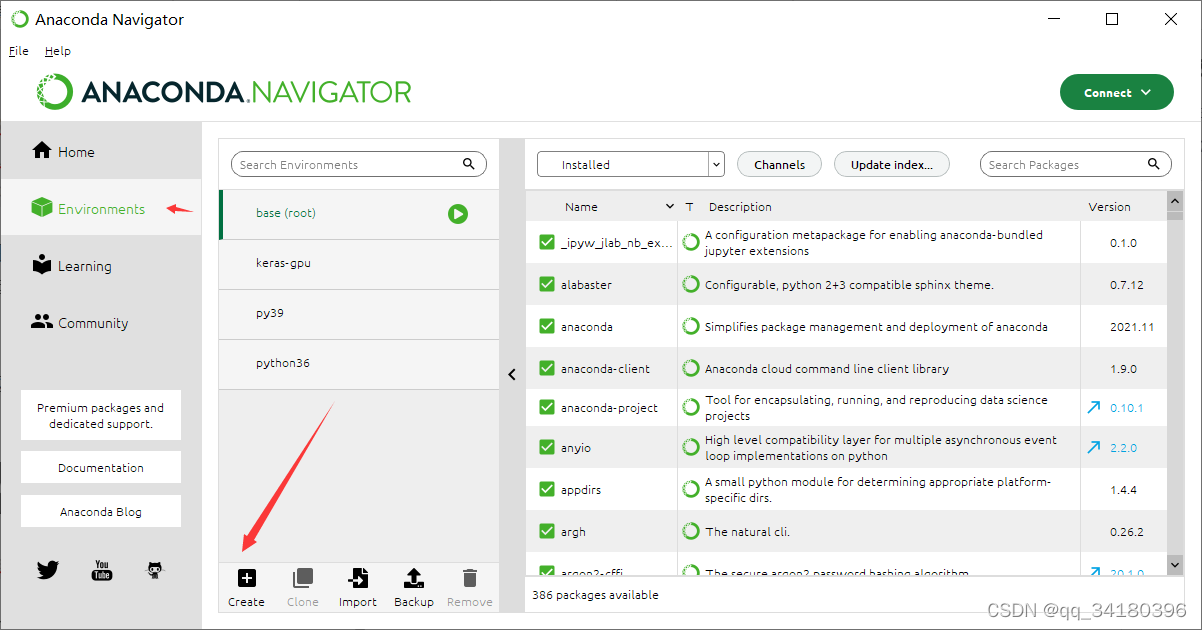
点击Environments里的create来创建环境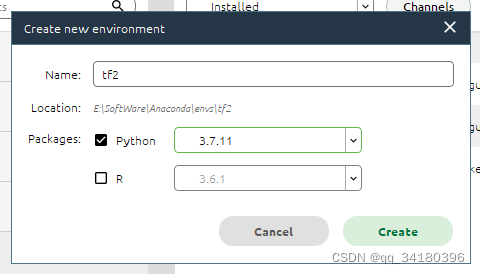
为环境起个名字,并选择相应Python版本。我这里叫tf2,选的是python 3.7.11版本。
再次点击create后稍作等待,待其安装完成。
安装完成后打开终端(open terminal)
键入
python -V
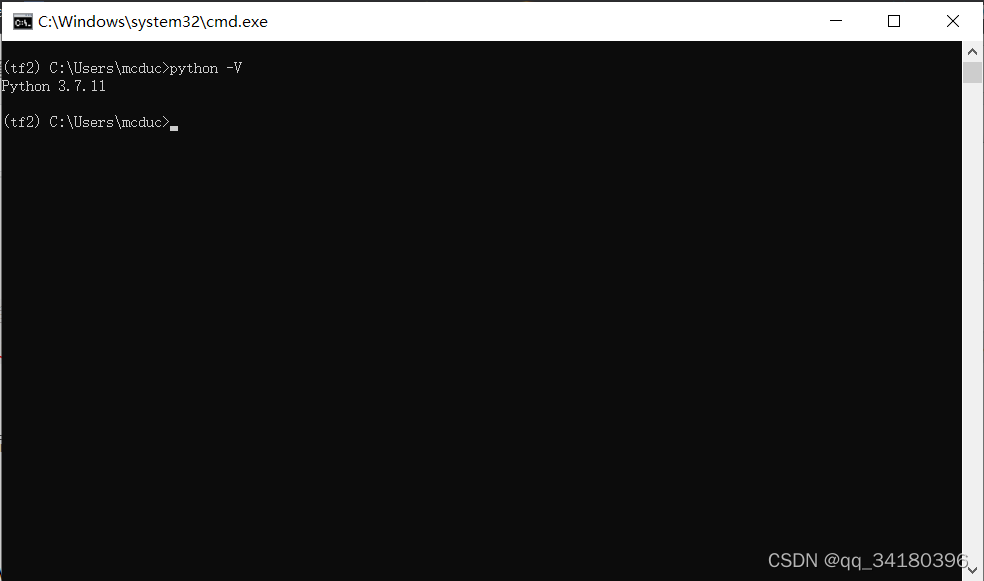
说明已经成功安装了python 3.9.7,需要该环境的时候使用
conda activate tf2#环境名
激活环境即可。
安装TensorFlow和Keras
依旧是在Anaconda Navigator中操作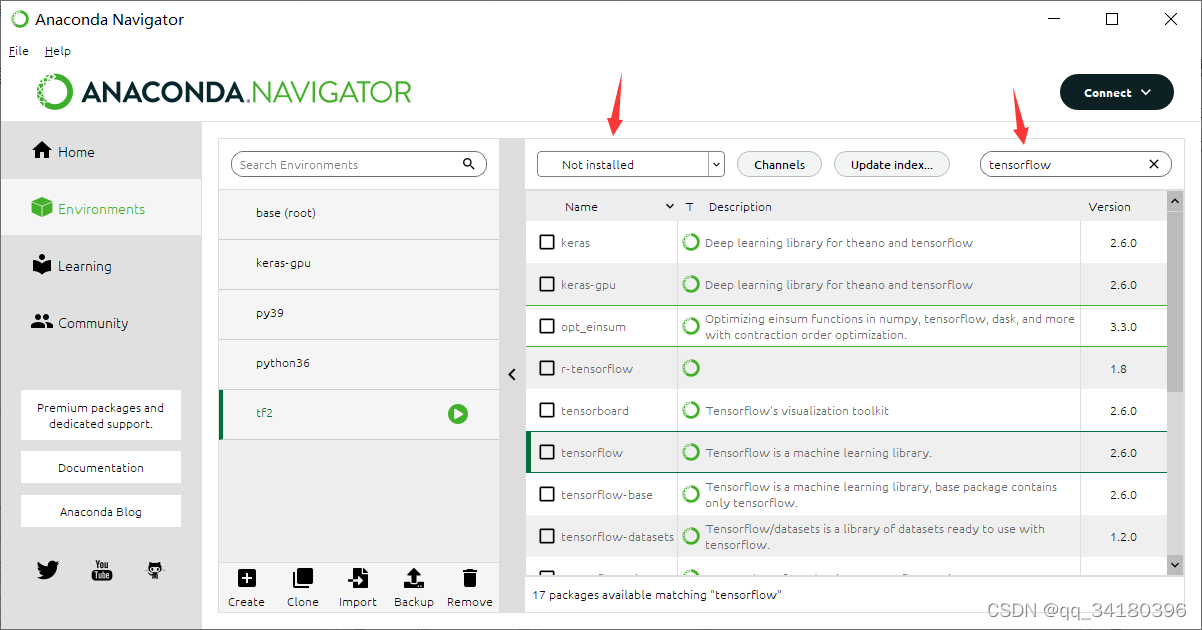
选择Not installed栏,搜索tensorflow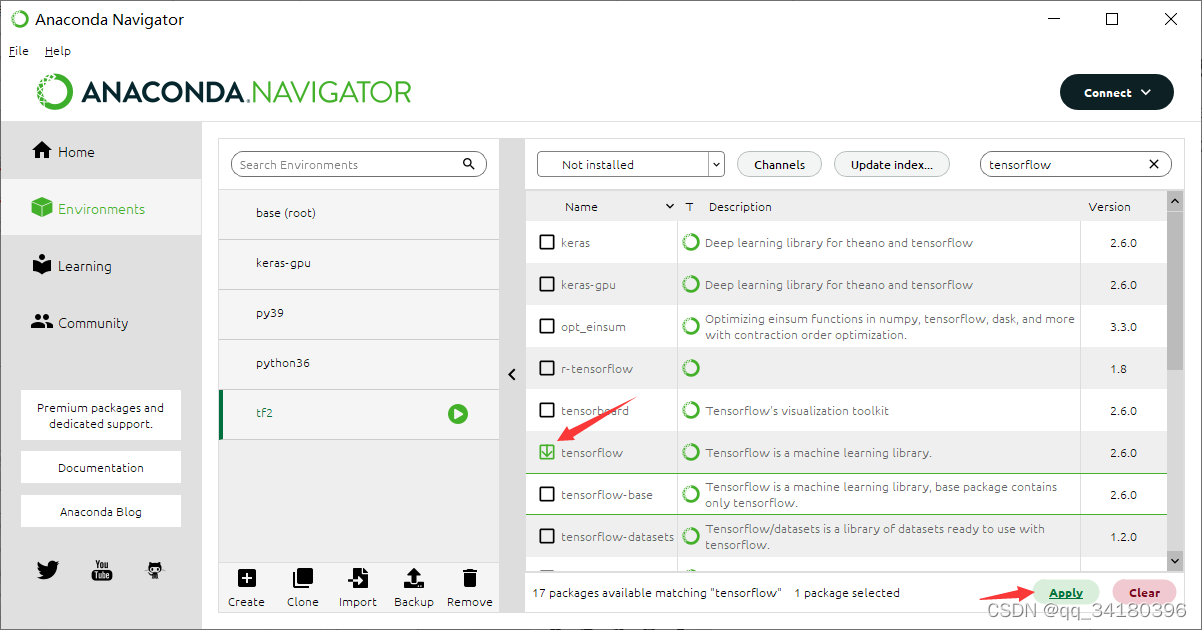
勾选tensorflow然后点击apply
等待搜索依赖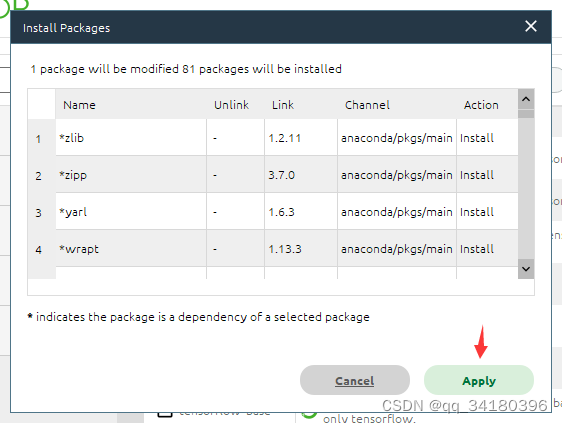
再次点击apply,他会开始安装所有相关依赖以及tensorflow本体
安装完成后打开终端(上文提到的打开方式)
如图表明已经激活名为“tf2”的环境,接下来键入
python
import tensorflow as tf
print(tf.__version__)
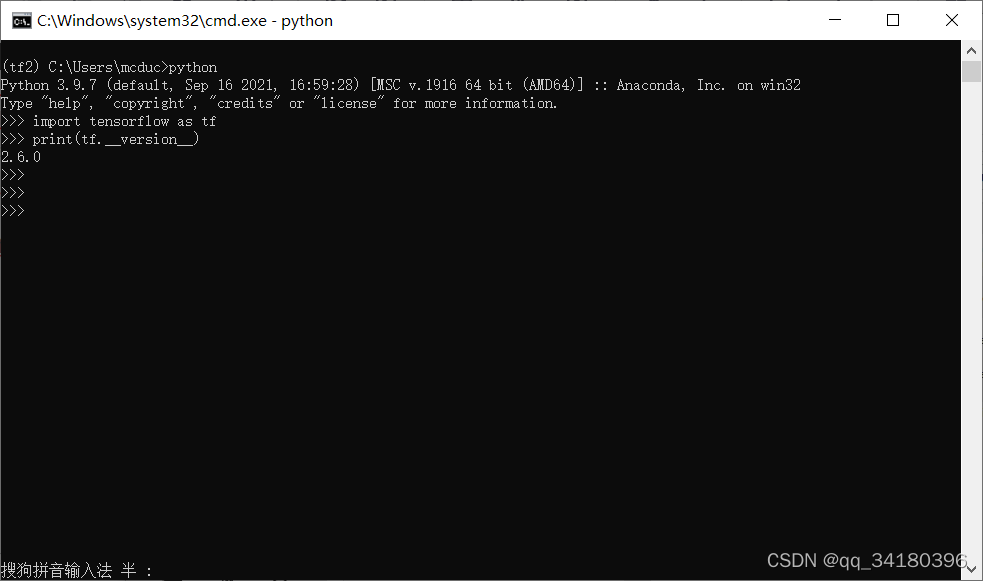
看到对应安装的版本号,说明安装成功了。接下来再安装keras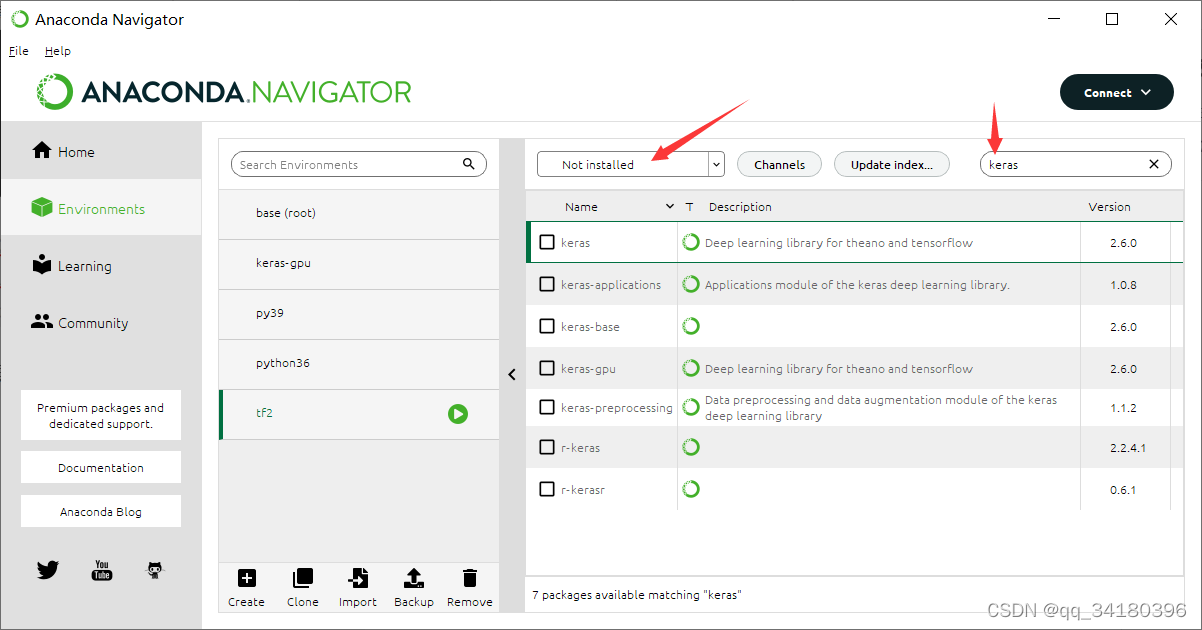
选择Not installed栏,搜索keras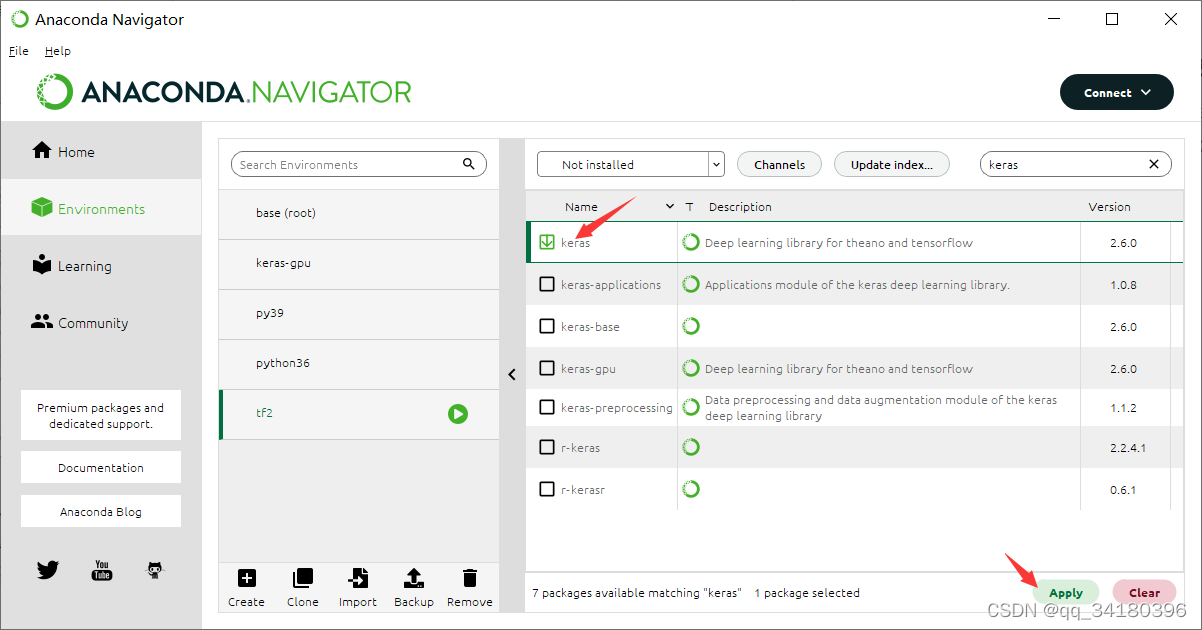
勾选keras然后点apply,接下来同前文提到tensorflow安装流程一样,弹出串口点击apply安装,待安装完成,终端键入
python
import keras
print(keras.__version__)
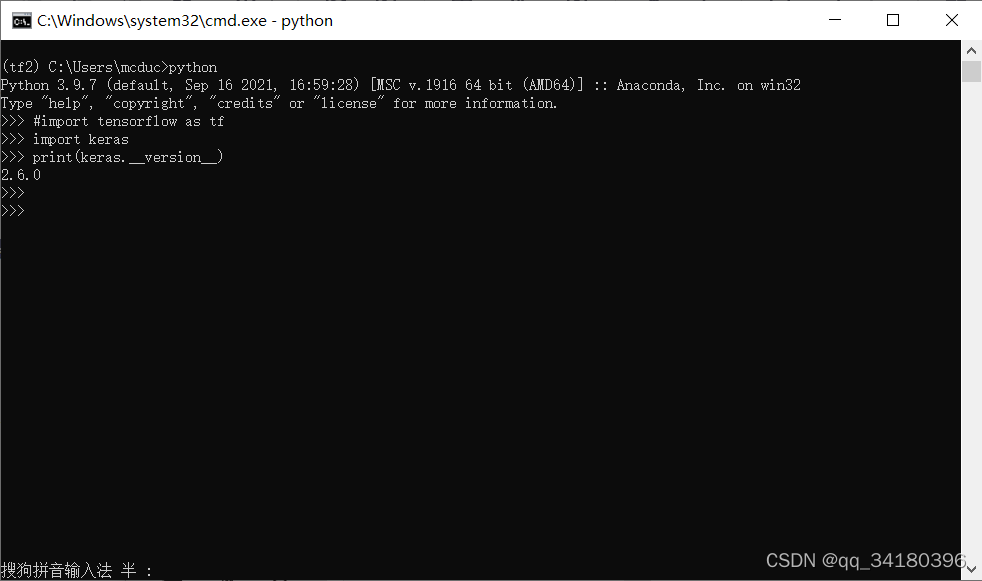
显示keras版本号,安装完成
安装其他依赖
为了可视化训练结果,我们需要matplotlib库,另外安装ipython和jupyter。
类似于上文安装的过程,我们在Anaconda Navigator搜索安装即可,在此不多赘述。
安装问题汇总
Anaconda安装依赖无法满足
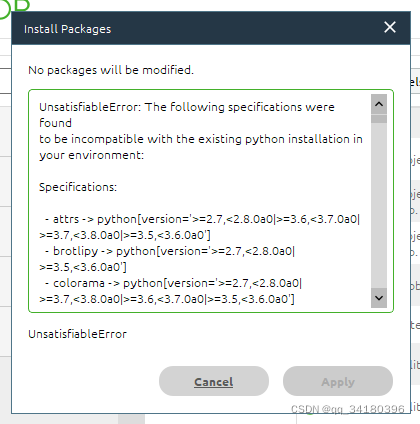
根据文字说明可以发现是一些依赖项版本无法符合的原因,一般是一般是Python版本过高造成的,固然tensorflow和keras支持Python 3.7-3.10版本,但其他库可能不支持高版本Python,所以解决方法之一便是降版本,安装更低版本的Python,不过降版本Anaconda上可安装的tensorflow版本也会降,如有需要得手动安装高版本tensorflow,相应的依赖项版本可能也有变动,比较麻烦;方法之二就是手动安装依赖项,适合有经验的人。
实操构建CNN模型
其实Keras和TensorFlow官网都有实例代码及其讲解,也可以自己去看看。
跑一个例程
跟着跑例程的操作主要是为了理解API的用法,这里用的是TensorFlow的新手指导例程,原网址
官方有较详尽的解释,有官方中文,新手建议跟着走一遍加深理解,我这里是简化版的,没有可视化部分,官方有可视化部分,需要安装matplotlib库。
# TensorFlow and tf.kerasimport tensorflow as tf
from tensorflow import keras
# Helper librariesimport numpy as np
# import matplotlib.pyplot as pltprint(tf.__version__)# 导入 Fashion MNIST 数据集
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels),(test_images, test_labels)= fashion_mnist.load_data()
class_names =['T-shirt/top','Trouser','Pullover','Dress','Coat','Sandal','Shirt','Sneaker','Bag','Ankle boot']# 预处理数据# 归一化
train_images = train_images /255.0
test_images = test_images /255.0# 构建模型# 设置层
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28,28)),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(10)])#编译模型
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])# 训练模型
model.fit(train_images, train_labels, epochs=10)# 评估准确率
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)print('\nTest accuracy:', test_acc)# 进行预测# 附加一个 softmax 层,将 logits 转换成更容易理解的概率。
probability_model = tf.keras.Sequential([model,
tf.keras.layers.Softmax()])# 抓取一个测试图像
img = test_images[1]# 添加图像到只有一个元素的batch
img =(np.expand_dims(img,0))
prediction = probability_model.predict(img)# 打印概率数组print(prediction)# 挑出概率最大的作为预测结果print(np.argmax(prediction))
构建自己的CNN模型
终于到了这一步了,哪个男孩不想拥有一套自己的CNN呢(雾)
我这里也是按图索骥,可以看看TensorFlow官方的教程
我取了智能车赛的图像作为训练数据集,实现对赛道元素的分类。数据量不多,但是赛道毕竟特征明显,我想应该够用了。
注意:我这里用的是TensorFlow版本是2.6.0。 前文安装的2.3.0版本是没有
image_dataset_from_directory
API的,从图片制作数据集稍麻烦。
准备工作
首先需要一些分好类的图像文件,分别位于对应类名的文件夹中
结构如下
track/
crossroad/
curve/
fork/
ramp/
roundabout/
straight/
编写程序
import os
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential
import tensorflow as tf
import matplotlib.pyplot as plt
# os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
directory="E:/dataset/track"# 目录位置,自己设
batch_size =32# batch大小
img_height =120# 图像高
img_width =188# 图像宽# 从文件目录构建训练数据集好测试数据集,两者4:1# 我的是灰度图,所以设置了彩色模式为灰度
train_ds = tf.keras.utils.image_dataset_from_directory(
directory,
color_mode="grayscale",
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
val_ds = tf.keras.utils.image_dataset_from_directory(
directory,
color_mode="grayscale",
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
class_names = train_ds.class_names
# 打印出分类名称print(class_names)# plt.figure(figsize=(10, 10))# for images, labels in train_ds.take(1):# for i in range(9):# ax = plt.subplot(3, 3, i + 1)# plt.imshow(images[i].numpy().astype("uint8"))# plt.title(class_names[labels[i]])# plt.axis("off")# 种类数
num_classes =len(class_names)
model = tf.keras.Sequential([
tf.keras.layers.Rescaling(1./255),# 3层卷积层,relu函数激活,每层后进行一次maxpooling池化
layers.Conv2D(16,3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32,3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64,3, padding='same', activation='relu'),
layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(120, activation='relu'),
tf.keras.layers.Dense(60, activation='relu'),
tf.keras.layers.Dense(num_classes)])
model.compile(
optimizer='adam',
loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
epochs =40
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
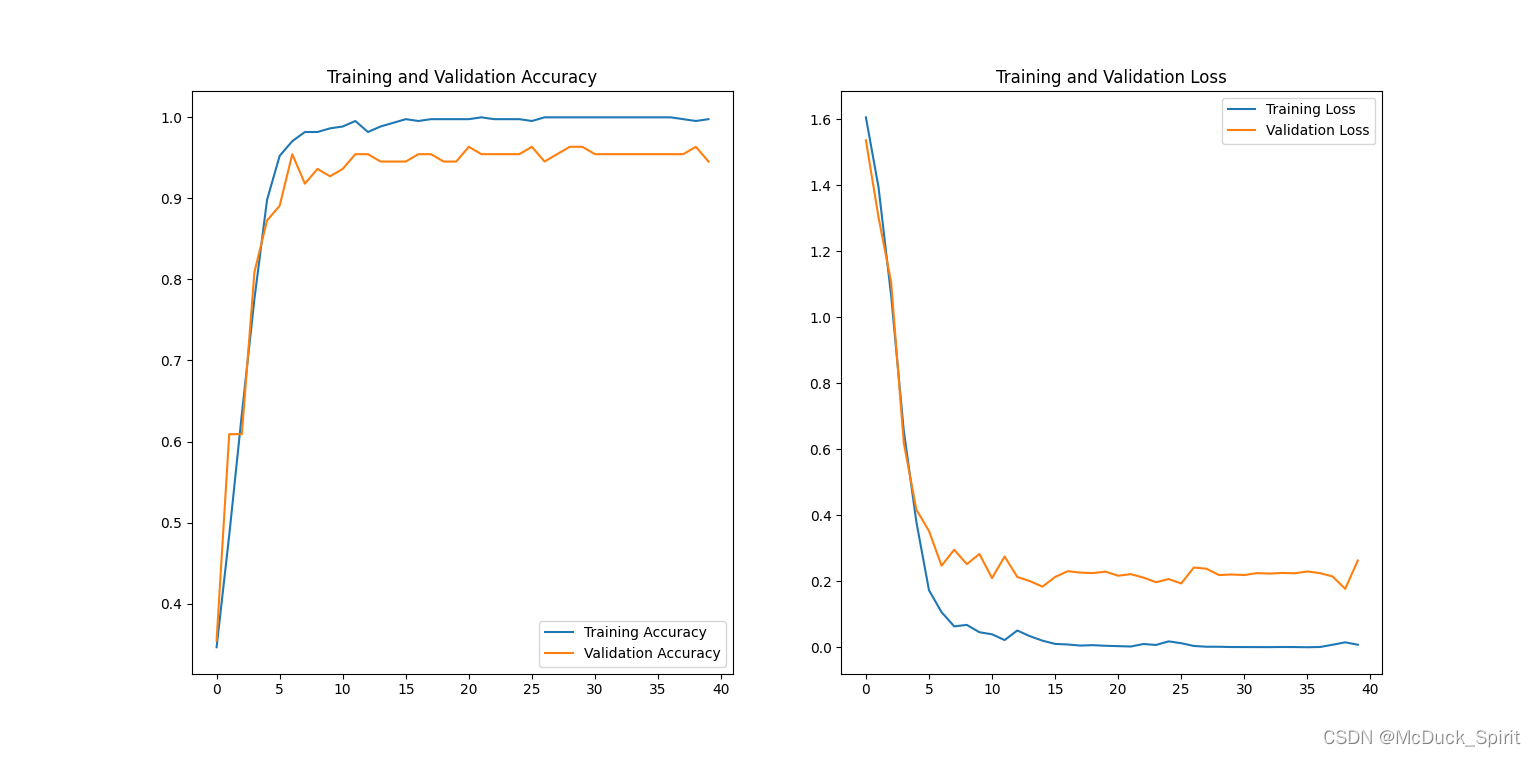
)# 可视化训练过程
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range =range(epochs)
plt.figure(figsize=(8,8))
plt.subplot(1,2,1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1,2,2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
效果
(作为示例程序模型没有细调)
本人也是CNN新手,文章可能还有不足,如有问题请在评论区指出,我会尽可能完善,愿共同学习共同进步;)
版权归原作者 McDuck_Spirit 所有, 如有侵权,请联系我们删除。