
一开始获得一个名为tar的文件到Kali中用 tar –xvf 文件名 的命令解压
解压后我们获得一张图片

我们将图片放到16进制编辑器里看一下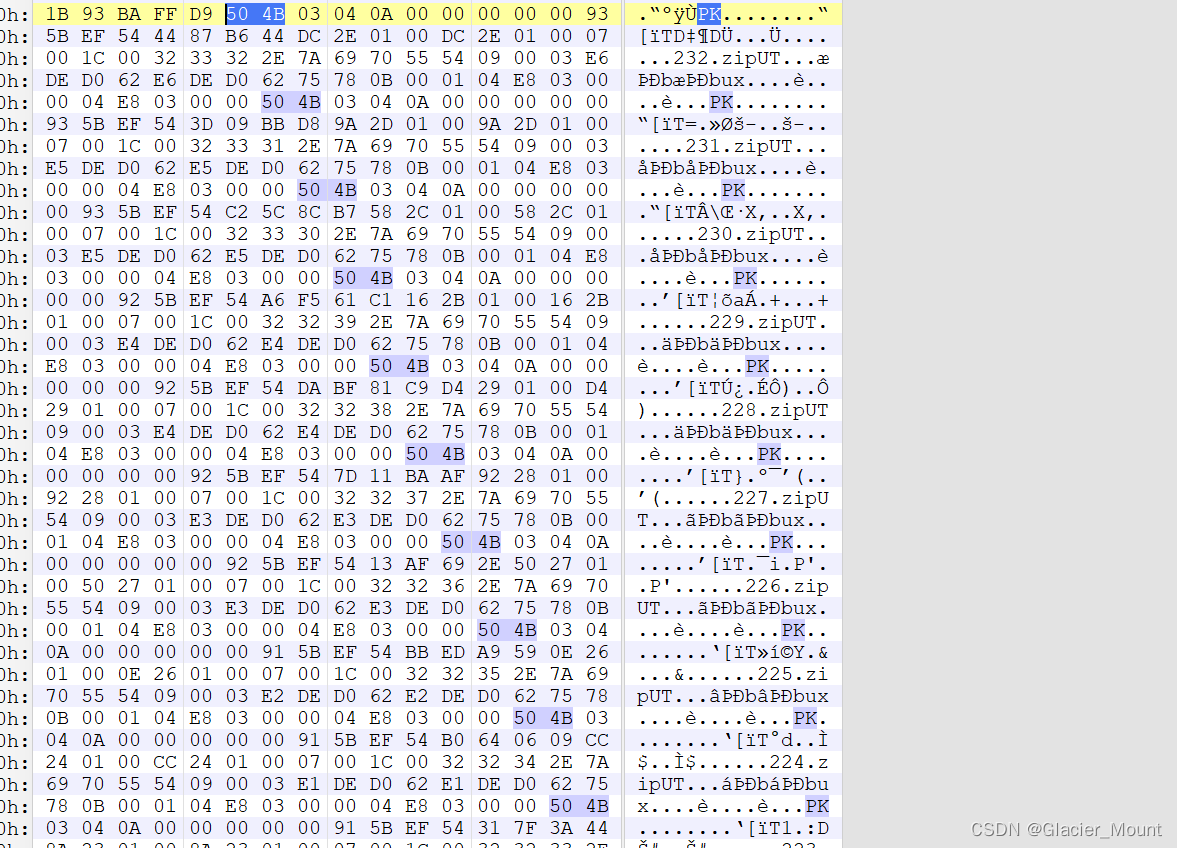
我们发现一大堆zip文件头,我们将图片后缀改为zip试一下。

然后我们得到一个压缩包
通过不断解压我们发现压缩包是一个套着一个的并且数字是依次递减的。
解压套娃的压缩包有三种方法。
1 分析16进制文件找到最后一个文件的文件头和文件未。
2 利用文件每次都递减1的规律跑脚本。
3 自己手动一个个点吧。(emmmm我是菜鸡,自己一个个点过去的。)
我们用方法一来看一下
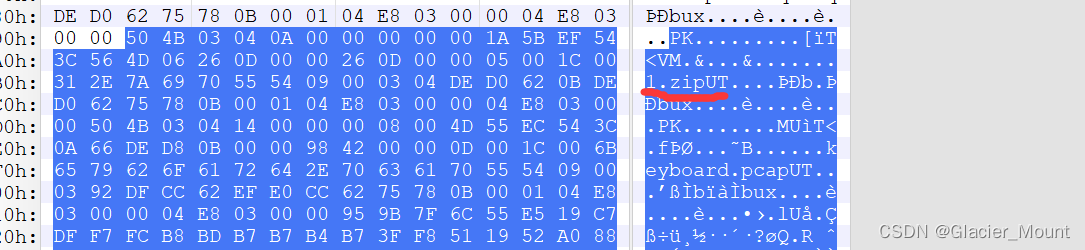
我们定位到1.zip的头504B0304然后我们再往后找第一个尾504B0506
这样首尾环合形成一个zip文件。
我们创建一个16进制文本保存一下。

打开压缩包我们发现是一个经过加密的pcap文件。
我们把压缩包放到16进制编译器里看一下。
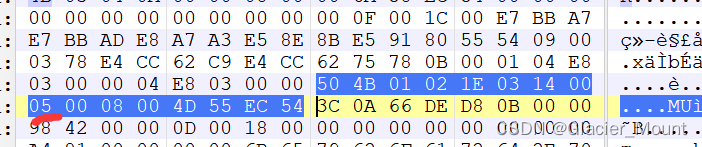
把504B的文件头全找出来发现是伪加密,只要将05改成00就好。
之后我们用Wireshake打开keyboard.pacp

根据观察我们可以发现这是一个键盘流量。
键盘数据包的数据长度为8个字节,击键信息集中在第3个字节,每次击键都会产生一个数据包。
我们通过过滤将键盘的数据包提取出来。
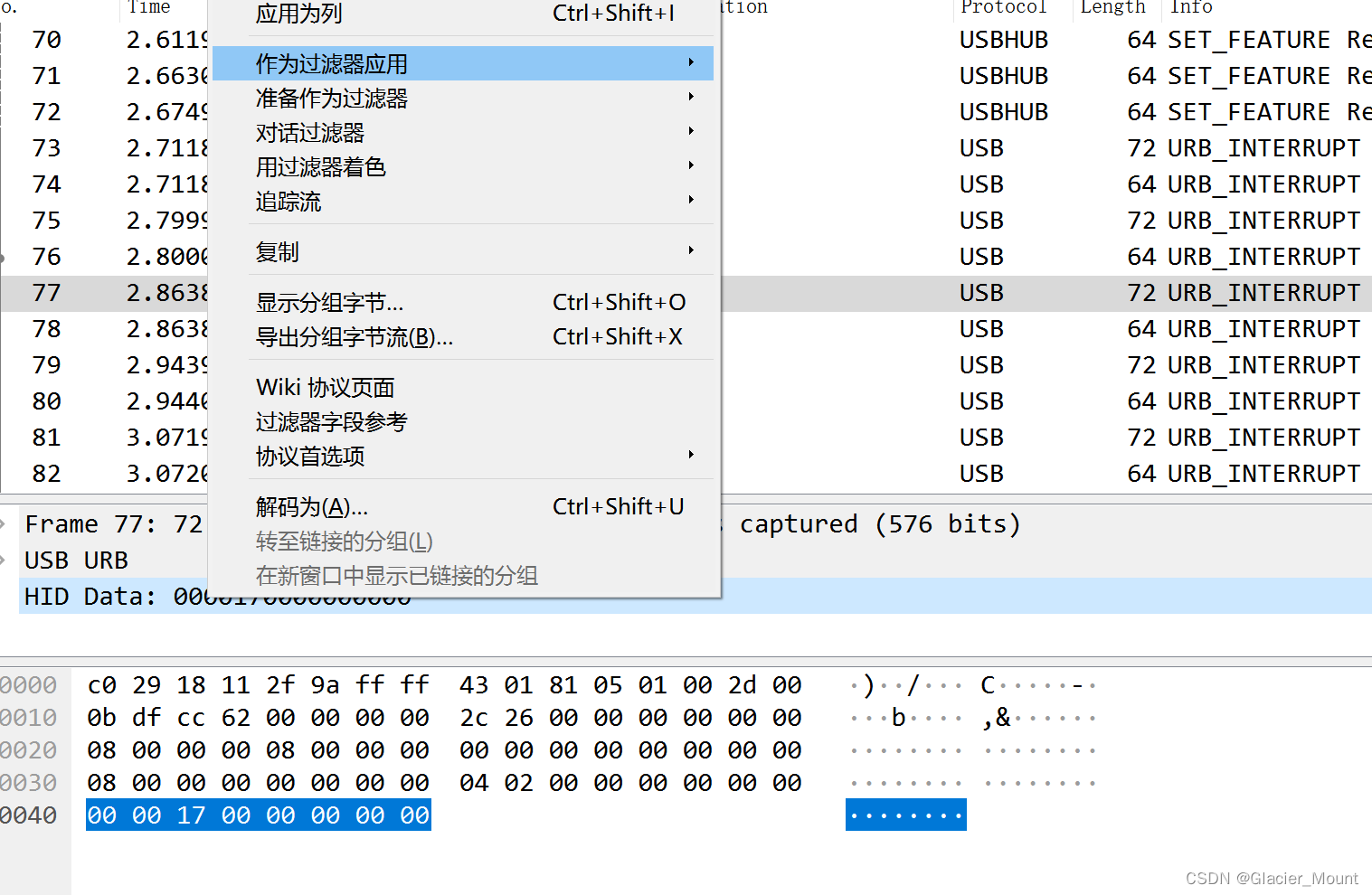
之后最简单的方法就是使用王一航大佬的代码直接将结果跑出来。(在GitHub中搜
UsbKeyboardDataHacker可以找到。)

python3 代码地址 键盘数据包
得到flag后我们把wwelcome中多的那个w去了就OK。
还有一种较为麻烦的方法是先用tshark将键盘的usbhid.data全保存到文本文件中去。

-r 是读取文件
-T 指出解析时输出的格式,常用的是text,也是默认格式.也可以是fields,指出显示某个域.
-e 就是具体显示出那个域
后面接的是保存的文件名与格式
0x04:"A", 0x05:"B", 0x06:"C", 0x07:"D", 0x08:"E", 0x09:"F", 0x0A:"G",
0x0B:"H", 0x0C:"I", 0x0D:"J", 0x0E:"K", 0x0F:"L", 0x10:"M", 0x11:"N",
0x12:"O", 0x13:"P", 0x14:"Q", 0x15:"R", 0x16:"S", 0x17:"T", 0x18:"U",
0x19:"V", 0x1A:"W", 0x1B:"X", 0x1C:"Y", 0x1D:"Z", 0x1E:"1", 0x1F:"2",
0x20:"3", 0x21:"4", 0x22:"5", 0x23:"6", 0x24:"7", 0x25:"8", 0x26:"9",
0x27:"0", 0x28:"\n", 0x2a:"[DEL]", 0X2B:" ", 0x2C:" ", 0x2D:"-", 0x2E:"=",
0x2F:"[", 0x30:"]", 0x31:"\", 0x32:"~", 0x33:";", 0x34:"'", 0x36:",", 0x37:"."
0x38:"/",0x39:"<CAP>"
注:当第一个字节为02或20时为shift键
当第三个字节为2a时为删除键(删除前一个字符)
当第三个字节为39时为大小写转换
通过第三字节与信息表的比对可以得出键盘敲击结果。
nepctf{welcome_to_nepctf_2nd}
版权归原作者 Glacier_Mount 所有, 如有侵权,请联系我们删除。