
团队在日常工作中,一般情况下使用的消息队列是腾讯云 CKafka。CKafka 提供了高可靠的开箱即用消息队列能力,让我们在日常能够放心使用,减少花在运维上的投入。不过即便如此,我们还是需要学习 Kafka 的一些基本概念和功能,从而在实际应用中嗯能够充分高效、高质量地利用 Kafka 的能力。
业务基本概念
本小节主要说明的是在软件业务层面,我们使用 Kafka 中会接触到的概念
消息 Message
对于一个消息队列系统,最基础的自然是 “消息”。在 Kafka 中,“消息” 就是
Message
,是在 Kafka 中数据传输的基本单位。多个消息会被分批次写入 Kafka 中。这同一批次的消息,就称为一组消息。
生产者和消费者
生产者和消费者的概念就很好理解了:产生消息的服务就称为 “生产者”
Producer
,也称为 “发布者”
Publisher
或
Writer
。
而需要获取消息的服务就称为 “消费者”
Consumer
,也称为 “订阅者”
SubScriber
或
Reader
。
主题 Topic 和 分区 Partition
在 Kafka 中,所有的消息并不是还有一条队列。Kafka 的消息通过
Topic
进行分类。而一个 Topic 可以被区分为多个 “分区”
Partitions
。
这里需要注意的是,在 同一个 partition 内部,消息的顺序是能够保证的。也就是说:如果消息A到达 partition 的时间早于消息B,那么消费者在获取消息的时候,必然是先获得消息A之后,才能够获取到消息B。
但是,如果在多个 partitions 之间,消息的顺序就无法保证了。比如当消费者监听多个 partitions 时的话,消息A和消息B被读取出来的时间无法保证。
那这么一来,partition 有什么用呢?实际上 Partition 是用来做负载均衡的。当 comsumer 将消息发到一个 topic 上时,Kafka 默认会将消息尽量均衡地分发到多个 partitions 上。作为消费者监听 topic 时,需要配置监听哪些 partitions。一个 consumer 可以监听多个 partitions,comsumer 和 partition(s) 的对应关系也称为 “所有权关系”
偏移量 Offset
Offset
是一个递增的整数值,由 Kafka 自动递增后自动写入每一个 partition 中。在同一个 partition 中,一个 offset 值唯一对应着一条 message。此外,由于 offset 是递增的,因此也可以用来区分多个 message 之间的顺序。Consumer 的重启动作并不影响 offset 的值,因为这是 Kafka 来进行维护的数值。
Broker 和 集群
一个独立的 Kafka server 就称为一个
broker
。一个或多个 broker 可以组成一个 “集群”
broker cluster
。Kafka 虽然是一个分布式的消息队列系统,但是在集群中,Kafka 依然是准中心化的系统架构。也就是说每一个集群中依然是有一台主 broker,称为
controller
。
每一个 cluster 会自动选举一个
cluster controller
出来,controller 需要负责以下操作:
- 管理 cluster
- 将 partition 分配给 broker 和监控 broker。
在 cluster 中,一个 partition 会从属于一个 broker,这个 broker 也会称作该 partition 的
leader
。同时该 partition 也可以分配给多个 broker,进行 分区复制——如果其中一个 broker 失效了,那么其余的 broker 可以尽快接管 leader 的位置。如果是使用云原生的 Kafka,我们一般就不需要太担心这个问题。
安装/运维基本概念
Kafka 部署架构
如果是运维自己安装 Kafka 的话,需要提前安装的软件是
Java
和
Zookeeper
。我当时就非常疑惑怎么多了一个
Zookeeper
?实际上 Kafka 是使用 Zookeeper 来保存 cluster 中的元数据和消费者信息。这里体现出了 Java 强大和完善的生态圈,各种方案都能够找到已有的轮子。
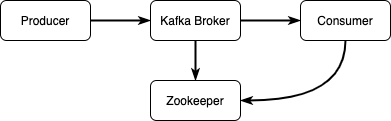
Zookeeper 也支持集群部署。Zookeeper 集群称为 “群组”
Ensemble
。因为 ensemble 也是使用了选举机制,因此每个 ensemble 中有奇数个节点,不建议超过7个。如果我们使用了云原生的 Kafka,就不需要过多关心这个细节啦。
Topic 参数
部署好了 broker 和 Zookeeper 之后,我们就可以创建 topics 了。创建 topic 时有一些参数需要进行配置。主要的有以下几项需要特别留意:
num.partitions: 新 topic 默认的分区数。在后续运维中,partition 的数量只会增加,不会减少。在腾讯云 CKafka 中,这对应着 “分区数” 配置log.retension.ms: 按照时间决定 topic 中的数据可以保存多久。这对应 CKafka 界面中的 “retension.ms” 参数log.retension.bytes: 按照存储空间决定 topic 中的数据可以保存多少。该参数在 CKafka 中不支持log.segment.bytes: 表示按照存储空间决定日志片段文件的大小。该参数在 CKafka 中不支持log.segment.ms: 表示按照时长决定日志片段大小。对应 CKafka 界面中的 “segment.ms” 参数。不是必要参数
如何选择 Partitions 的数量?
前面提到,在同一个 partition 中,消息的顺序是能够得到保证的。因此对于一个小型的、对可靠性要求不高、但是对顺序性要求很高的系统而言,或许可以使用单 partition 的方案。
但是这个方案其实是非常危险的:
- 首先,单一 partition 就意味着 consumer 也只能有一个,否则会出现消息重复消费的问题。在一个生产项目中进行单点部署,这几乎是不可接受的
- 虽然在 Kafka 内部,单一 partition 内的消息顺序能够得到保证,但如果生产者未能得到保证的话,那么 kafka 内的消息顺序依然不是真实的。因此对于有强顺序要求的消息队列系统中,不建议使用时间顺序,而是采用逻辑顺序/逻辑时钟来区分消息的先后。
因此在实际生产环境中,我们应当适当地分配 partition 的数量。如果对顺序性有要求,那么不应该依赖 kafka 的顺序机制,而是使用额外的机制来保证。
Kafka 生产者
架构图
生产者向 Kafka broker 发送消息一般是用各语言的 SDK 来完成的。下面框图中是 SDK 完成的逻辑。首先 producer 在发送 message 之前,需要将 message 封装到
producer record
中,record 包含的必填信息是 topic 和 value(也就是 message 正文)信息。此外还可选 partition 和 key 信息,不过相对少用。Key 参数的作用后文会作说明。

当消息被写入 Kafka broker 之后,broker 会回调到 SDK 中,将消息最终落地的 partition 和 partition 中的 offset 信息返回给 SDK,并最终视需要返回给 Producer。
消息发送
Kafka 生产者有两种消息发送方式:同步 和 异步。
同步发送方式就是生产者发出的每一个消息,都需要按照上面的结构图的流程处理:消息发出后等待 Kafka broker 的结果响应之后再做进一步的处理。Kafka broker 返回的错误中包含了两种错误:
- 可重试错误: 当遇到这一类错误时,生产者可以直接重新尝试发送。比如网络错误、集群错误等等。
- 不可重试错误: 当遇到这一类错误时,生产者只能考虑告警、记录、修改软件逻辑等等。比如消息过大等等。
异步发送方式就是生产者通过 SDK 发送消息之后就直接返回;SDK 在后台处理消息的发送、响应处理,然后通过回调告知生产者以进行进一步的处理。
生产者参数
生产者启动之前也有一些参数可进行配置。读者可以在各语言的 SDK 中具体查找:
acks: 消息发送给 Kafka broker,由于实际上会有多个 broker,因此消息是需要复制多份的。该参数表示需要等待多少个 broker 的响应,才视为消息发送成功: - 0: 表示不需要等待 broker 响应- 1: 表示 leader 响应即可- all: 表示需要所有的 broker 响应buffer.memory: 生产者的缓冲区大小。单位是 message 的数量。当缓冲区满了之后,SDK 会根据maxblock.ms等待并阻塞一段时间之后再进行重试。如果缓冲区还是满了的状态,则会抛出异常或返回错误compression.type: 消息压缩格式,可选值为:snappy,gzip,lz4retries: 重试次数,重试间隔为retry.backoff.ms,默认是 100msbatch.size: 一个批次的数据大小,字节数。为了减少网络传输中的消耗,Kafka 生产者并不是一个消息就通过一次发送发出去,而是组成一个个批次进行发送。当一个批次的大小达到这个参数时,则会马上发出。linger.ms: 一个批次发送之前的缓冲时间。当批次的尺寸未达到batch.size的话,SDK 也不会一直按住 message 不发送,而是等待一段时间之后也会把内存中的批次发出client id: 自定义字符串,用于标识生产者max.id.flight.requests.per.connection: 这个参数指的是收到服务器响应之前,生产者可以发送的消息数。设置为 1 可以保证消息顺序,但是相应的效率就下降了request.timeout.ms: 生产者发送数据之后等待响应的时间
Key 的作用
在 producer record 中的
key
有两个用途:
- 作为消息的附加消息
- 可以用来决定写入到哪一个分区。默认分区器可以使拥有相同 key 的消息写入同一个分区。
- 如果 key == null,则默认采用轮询方式写入分区
- 如果 key 非空,则根据哈希结果决定分区
生产者也可以通过自定义分区器来实现业务的具体分区功能,具体参见各语言的 SDK
Kafka 消费者
一个 Kafka 的消费者是从属于其对应的 comsumer group 的,每一个 group 订阅一个 topic,每个 consumer 消费一部分的消息。整个 group 内部通过消费不同的 partition 实现负载均衡。每一个 group 都有一个
group.id
用于标识一个消费者群组,这在业务中就对应着一个消费者业务。
不要让消费者数量多于分区数量,否则会导致出现重复消费的问题。因此在 partition 选用时,宜多不宜省。更多的分区数量也能够更加合理地分配 consumer 之间的负载。
分区再均衡 Partitions Reoke / Rebalance
每个消费者可以对应一个或多个 partition;多个 consumer 组成一个 group,覆盖 topic 的全部 partitions。但是当 consumer 和 partitions 数量发生变化时,需要重新分配所有权关系。这个动作就称为
Rebalance
。至于是热切换还是冷切换,则由业务方决定。
消费者在调用
subscribe()
监听消息时,可以传入一个
ConsumerRebalanceListener
实例来监听事件。其中需要关注的事件有:
onPartitionsRevoked(): 这是再平衡开始之前的事件。注意此时消费者应停止消费,并且 commit 已完成但尚未 commit 的 offset 值onPartitionsAssigned(): 这是再平衡结束,也就是重新分配分区结束之后的时间。大部分情况下消费者也不需要特别处理什么,不过可以在这里进行一些消费过程的重启动作
Commit 和 Offset
前文提到,一个 message 能够与 kafka 中的一个 partition 中的一个 offset 值一一对应。对于消费者而言,partition-offset 对也可以用于标识当前 comsumer 已经获取到的消息的进度,也可以用于消费者在 kafka 中进行历史消息的寻址。
当对某个 message 消费完成后,消费者会将 offset 值提交到 kafka 中,从而让 Kafka 识别并保存某个 comsumer group 的消费进度。下一次 consumer 再请求事件时,默认会从该 offset 往后继续获取。Consummer 向 Kafka 更新 offset 的这一动作就称为 “提交”
commit
。
如果 consumer 发生崩溃,或者有新的 consumer 加入 group,就会触发 rebalance。完成 rebalancing 之后,每个 consumer 有可能会被分配到不同的分区。为了能够继续之前的工作,consumer 需要读取每一个分区最后一次提交的 offset,然后从指定的 offset 继续处理。这个操作,一般在 SDK 中就完成了。但是在上述切换过程中,由于分布式系统的分布式、异步特性,我们不可避免的还是可能遇到一些不一致的情况,具体表现为消息的重复处理和漏处理。所以我们在任何时候都不能简单依赖 Kafka 本身提供的消息队列机制,而是在各自的业务系统中也需要进行一定的防御式编程,避免错误处理出现。
一般而言,SDK 有下面几种 commit 方式:
- 自动提交:
enable.auto.commit为true时,API 定时、异步地进行 commit。因此,如果在触发了再均衡的时候还有部分数据未 commit,那么在再均衡之后在其他的消费者中就有可能发生重复消费 - 主动提交:
enable.auto.commit为false时,业务方需要主动调用相关 API 进行 commit。 - (主动的)异步提交: 其实就是主动提交的异步版,简单而言就是开一个后台异步 commit 的过程。
- 提交特定的 offset: 这种模式就是显式地 commit 具体 partition 的某个 offset 值。
邀您共同加入产品经理修炼之路:

版权归原作者 xiaoli8748_软件开发 所有, 如有侵权,请联系我们删除。