
一、集群简介
Hadoop 集群包括两个集群:HDFS 集群、YARN 集群。两个集群逻辑上分离、通常物理上在一起;两个集群都是标准的主从架构集群。
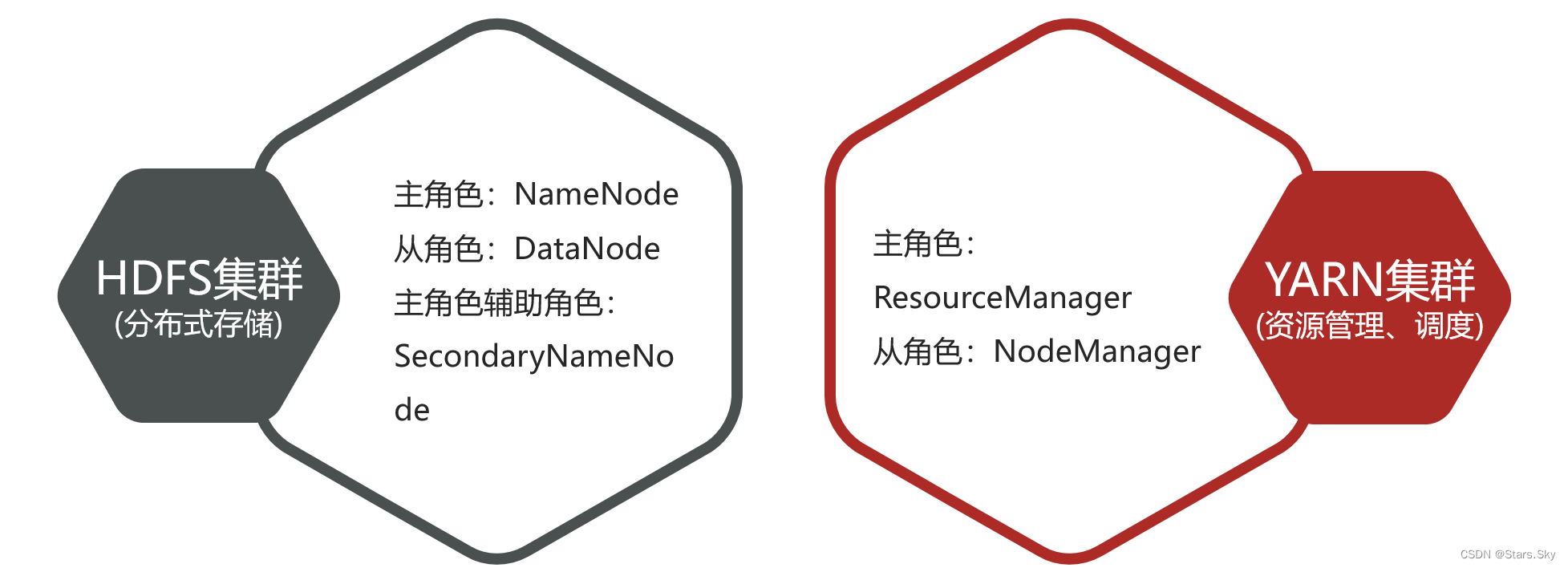
- 逻辑上分离
两个集群互相之间没有依赖、互不影响
- 物理上在一起
某些角色进程往往部署在同一台物理服务器上
- MapReduce 集群呢?
MapReduce 是计算框架、代码层面的组件,没有集群之说
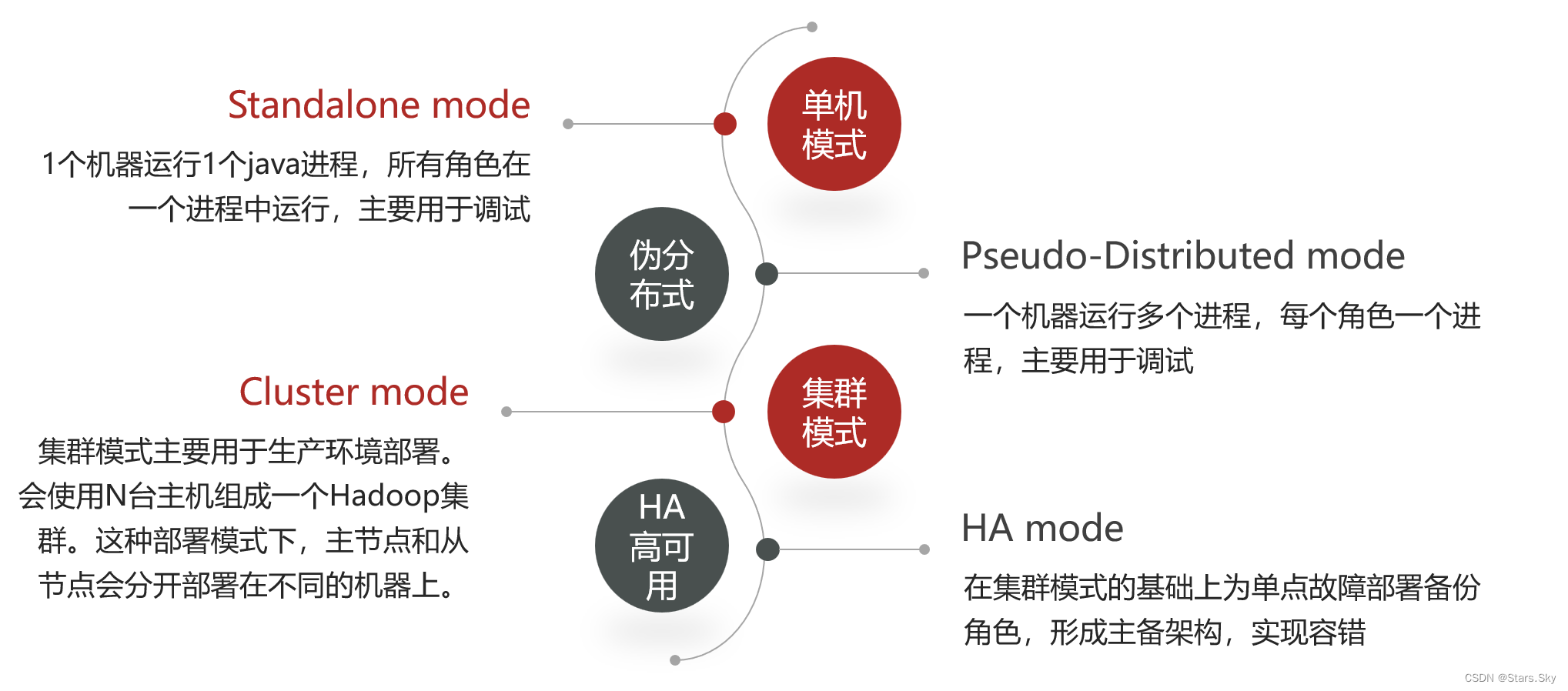
二、Hadoop 集群部署方式
三、集群安装
3.1 集群角色规划
集群模式主要用于生产环境部署,需要多台主机,并且这些主机之间可以相互访问。本次是在 Centos 7.6 搭建集群模式,以三台主机为例,以下是集群规划:
各节点 IP各节点名称运行角色各节点资源规划192.168.170.136hadoop01
NameNode、DataNode、ResourceManager、NodeManager
2 cpu / 4 G192.168.170.137hadoop02
SecondaryNamenode、DataNode 、NodeManager
2 cpu / 4 G192.168.170.138hadoop03DataNode 、NodeManager2 cpu / 4 G
3.2 服务器基础环境准备
3.2.1 环境初始化
给三台机器进行环境初始化,特别是需要做好 Hosts 映射:CentOS 7 初始化系统_centos7初始化_Stars.Sky的博客-CSDN博客
3.2.2 ssh 免密登录(在 hadoop01 上执行)
# 4 个 回车,生成公钥、私钥
[root@hadoop01 ~]# ssh-keygen
# 推送到各个节点
[root@hadoop01 ~]# ssh-copy-id root@hadoop01
[root@hadoop01 ~]# ssh-copy-id root@hadoop02
[root@hadoop01 ~]# ssh-copy-id root@hadoop03
3.2.3 各个节点上安装 JDK 1.8 环境
Linux 部署 JDK+MySQL+Tomcat 详细过程_一键部署jdk mysql tomcat_Stars.Sky的博客-CSDN博客
3.3 安装 Hadoop
hadoop 3.2.4 官方下载地址:Apache Downloads
# 创建统一工作目录(3 台机器)
[root@hadoop01 ~]# mkdir -p /bigdata/hadoop/server # 软件安装路径
[root@hadoop01 ~]# mkdir -p /bigdata/hadoop/data # 数据存储路径
[root@hadoop01 ~]# mkdir -p /bigdata/softwares # 安装包存放路径
# 上传、解压安装包(hadoop01)
[root@hadoop01 ~]# cd /bigdata/softwares/
[root@hadoop01 /bigdata/softwares]# ls
hadoop-3.2.4.tar.gz
[root@hadoop01 /bigdata/softwares]# tar -zxvf hadoop-3.2.4.tar.gz -C /bigdata/hadoop/server/
3.4 **Hadoop **安装包目录结构
[root@hadoop01 /bigdata/softwares]# cd /bigdata/hadoop/server/
[root@hadoop01 /bigdata/hadoop/server]# ls
hadoop-3.2.4
[root@hadoop01 /bigdata/hadoop/server]# cd hadoop-3.2.4/
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4]# ls
bin etc include lib libexec LICENSE.txt NOTICE.txt README.txt sbin share
 3.5 **编辑 **Hadoop 配置文件
3.5 **编辑 **Hadoop 配置文件
3.5.1 hadoop-env.sh
文件中设置的是 Hadoop 运行时需要的环境变量。JAVA_HOME 是必须设置的,即使我们当前的系统中设置了 JAVA_HOME,它也是不认识的,因为 Hadoop 即使是在本机上执行,它也是把当前的执行环境当成远程服务器。
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# pwd
/bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop
# 在文件最后面直接添加下面内容
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# vim hadoop-env.sh
# 配置 JAVA_HOME
export JAVA_HOME=/usr/java/jdk1.8.0_381
# 设置用户以执行对应角色 shell 命令
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
3.5.2 core-site.xml
hadoop 的核心配置文件,有默认的配置项 core-default.xml。core-default.xml 与 core-site.xml 的功能是一样的,如果在 core-site.xml 里没有配置的属性,则会自动会获取 core-default.xml 里的相同属性的值。
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# vim core-site.xml
<configuration>
<!-- 默认文件系统的名称。通过 URI 中 schema 区分不同文件系统。-->
<!-- file:///本地文件系统 hdfs:// hadoop分布式文件系统 gfs://。-->
<!-- hdfs 文件系统访问地址:http://nn_host:8020。-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:8020</value>
</property>
<!-- hadoop 本地数据存储目录 format 时自动生成 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/bigdata/hadoop/data/tmp</value>
</property>
<!-- 在 Web UI 访问 HDFS 使用的用户名。-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
3.5.3 hdfs-site.xml
HDFS 的核心配置文件,主要配置 HDFS 相关参数,有默认的配置项 hdfs-default.xml。hdfs-default.xml 与 hdfs-site.xml 的功能是一样的,如果在 hdfs-site.xml 里没有配置的属性,则会自动会获取 hdfs-default.xml 里的相同属性的值。
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# vim hdfs-site.xml
<configuration>
<!-- 设定 SNN 运行主机和端口 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop02:9868</value>
</property>
</configuration>
3.5.4 mapred-site.xml
MapReduce 的核心配置文件,Hadoop 默认只有个模板文件 mapred-site.xml.template,需要使用该文件复制出来一份 mapred-site.xml 文件。
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# vim mapred-site.xml
<configuration>
<!-- mr 程序默认运行方式。yarn 集群模式 local 本地模式-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- jobhistory 服务配置 注意 19888 是 web ui 访问端口 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value>
</property>
<!-- MR App Master 环境变量。-->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- MR MapTask 环境变量。-->
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- MR ReduceTask 环境变量。-->
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
3.5.5 yarn-site.xml
YARN 的核心配置文件,在该文件中的 <configuration> 标签中添加以下配置。
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# vim yarn-site.xml
<!-- yarn 集群主角色 RM 运行机器。-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<!-- NodeManager 上运行的附属服务。需配置成 mapreduce_shuffle,才可运行 MR 程序。-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 每个容器请求的最小内存资源(以MB为单位)。-->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<!-- 每个容器请求的最大内存资源(以MB为单位)。-->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<!-- 容器虚拟内存与物理内存之间的比率。-->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
</property>
<!-- 开启 yarn 日志聚集功能,收集每个容器的日志集中存储在一个地方 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置为一天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop01:19888/jobhistory/logs</value>
</property>
3.5.6 workers
workers 文件里面记录的是集群主机名。一般有以下两种作用:
配合一键启动脚本如 start-dfs.sh、stop-yarn.sh 用来进行集群启动。这时候 slaves 文件里面的主机标记的就是从节点角色所在的机器。
可以配合 hdfs-site.xml 里面 dfs.hosts 属性形成一种白名单机制。
dfs.hosts 指定一个文件,其中包含允许连接到 NameNode 的主机列表。必须指定文件的完整路径名,那么所有在 workers 中的主机才可以加入的集群中。如果值为空,则允许所有主机。
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# vim workers
hadoop01
hadoop02
hadoop03
3.6 分发同步安装包
在 hadoop01 机器上将 Hadoop 安装包 scp 同步到其他机器:
[root@hadoop01 /bigdata/hadoop]# cd /bigdata/hadoop/server/
[root@hadoop01 /bigdata/hadoop/server]# scp -r hadoop-3.2.4 root@hadoop02:/bigdata/hadoop/server/
[root@hadoop01 /bigdata/hadoop/server]# scp -r hadoop-3.2.4 root@hadoop03:/bigdata/hadoop/server/
3.7 **配置 ****Hadoop **环境变量
在三台机器上配置 Hadoop 环境变量:
[root@hadoop01 /bigdata/hadoop/server]# vim /etc/profile
# hadoop
export HADOOP_HOME=/bigdata/hadoop/server/hadoop-3.2.4/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 重新加载环境变量
[root@hadoop01 /bigdata/hadoop/server]# source /etc/profile
# 验证环境变量是否生效
[root@hadoop01 /bigdata/hadoop/server]# hadoop
3.8 NameNode format****(格式化操作)
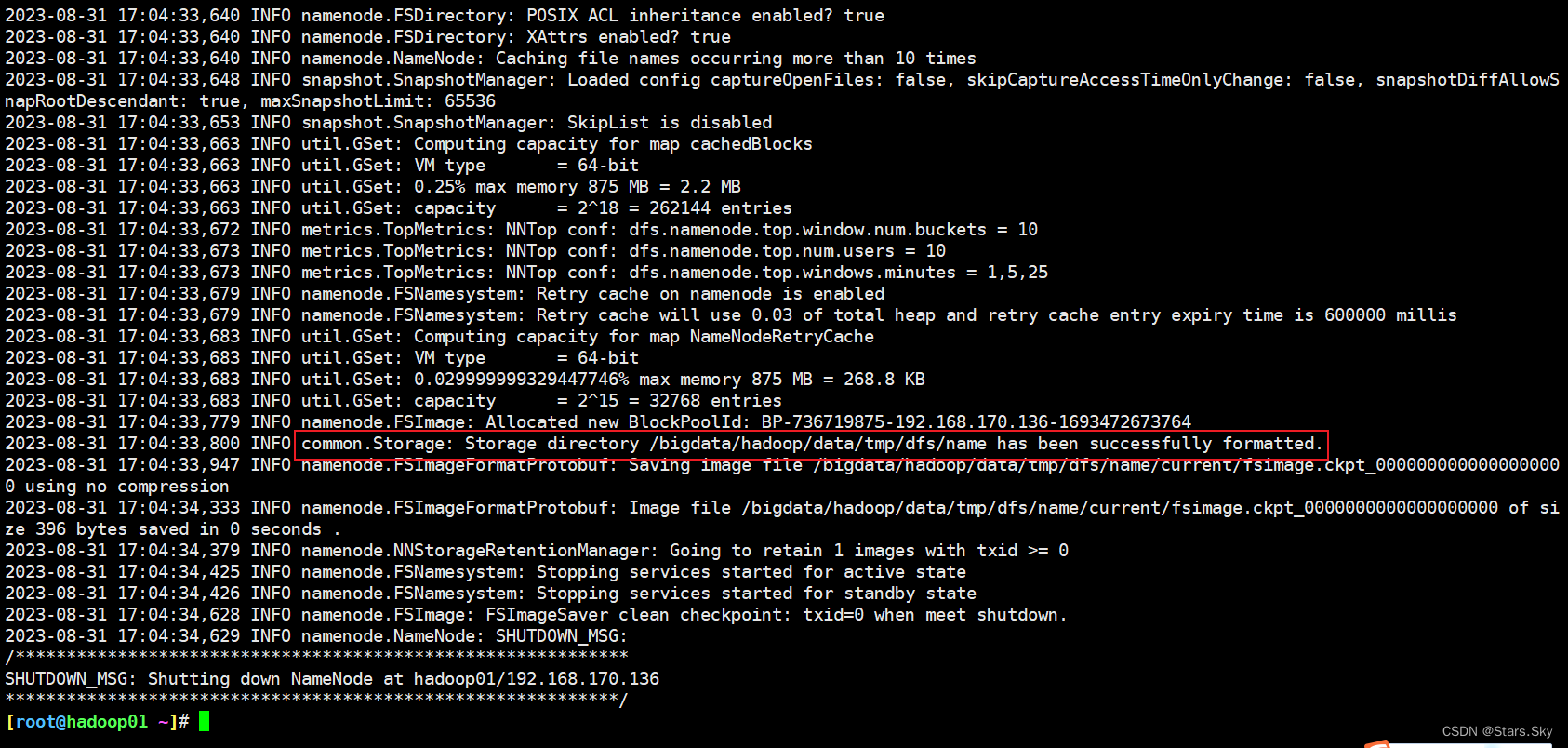
首次启动 HDFS 时,必须对其进行格式化操作。format 本质上是初始化工作,进行 HDFS 清理和准备工作。
# 仅在 hadoop01 上执行
[root@hadoop01 ~]# hdfs namenode -format
[root@hadoop01 ~]# ll /bigdata/hadoop/data/tmp/dfs/name/current/
总用量 16
-rw-r--r-- 1 root root 396 8月 31 17:04 fsimage_0000000000000000000
-rw-r--r-- 1 root root 62 8月 31 17:04 fsimage_0000000000000000000.md5
-rw-r--r-- 1 root root 2 8月 31 17:04 seen_txid
-rw-r--r-- 1 root root 218 8月 31 17:04 VERSION
fsimage_0000000000000000000:这是文件系统镜像(File System Image),包含了HDFS的整个文件系统结构(如目录和文件元数据)的一个快照。fsimage_0000000000000000000.md5:这是与fsimage文件对应的MD5校验和,用于验证文件完整性。seen_txid:这个文件保存了NameNode最后一次启动后见到(即处理过)的最大事务ID。VERSION:这个文件包含了与NameNode相关的各种版本和配置信息,比如Hadoop的版本号,布局版本等。
3.9 **Hadoop **集群启动关闭
3.9.1 手动逐个进程启停
每台机器上每次手动启动关闭一个角色进程。
- HDFS 集群
hdfs --daemon start namenode|datanode|secondarynamenode
hdfs --daemon stop namenode|datanode|secondarynamenode
- YARN 集群
yarn --daemon start resourcemanager|nodemanager
yarn --daemon stop resourcemanager|nodemanager
3.9.2 **shell **脚本一键启停
在 hadoop01 上,使用软件自带的 shell 脚本一键启动。前提:配置好机器之间的 SSH 免密登录和 workers 文件。
HDFS 集群
start-dfs.sh
stop-dfs.sh
YARN 集群
start-yarn.sh
stop-yarn.sh
Hadoop 集群
start-all.sh
stop-all.sh
[root@hadoop01 ~]# start-all.sh
Starting namenodes on [hadoop01]
上一次登录:五 9月 1 14:24:35 CST 2023pts/0 上
Starting datanodes
上一次登录:五 9月 1 14:25:14 CST 2023pts/0 上
Starting secondary namenodes [hadoop02]
上一次登录:五 9月 1 14:25:17 CST 2023pts/0 上
Starting resourcemanager
上一次登录:五 9月 1 14:25:23 CST 2023pts/0 上
Starting nodemanagers
上一次登录:五 9月 1 14:25:30 CST 2023pts/0 上
3.9.3 **Hadoop **集群启动日志
# 启动完毕之后可以使用 jps 命令查看进程是否启动成功
[root@hadoop01 ~]# jps
22337 NodeManager
21798 DataNode
22203 ResourceManager
22669 Jps
21662 NameNode
[root@hadoop02 ~]# jps
21114 NodeManager
21005 DataNode
21213 Jps
[root@hadoop03 ~]# jps
21010 DataNode
21219 Jps
21119 NodeManager
# Hadoop 启动日志
[root@hadoop01 ~]# ll /bigdata/hadoop/server/hadoop-3.2.4/logs/
总用量 184
-rw-r--r-- 1 root root 36069 8月 31 17:54 hadoop-root-datanode-hadoop01.log
-rw-r--r-- 1 root root 692 8月 31 17:54 hadoop-root-datanode-hadoop01.out
-rw-r--r-- 1 root root 43819 8月 31 17:54 hadoop-root-namenode-hadoop01.log
-rw-r--r-- 1 root root 692 8月 31 17:54 hadoop-root-namenode-hadoop01.out
-rw-r--r-- 1 root root 40045 8月 31 17:55 hadoop-root-nodemanager-hadoop01.log
-rw-r--r-- 1 root root 2264 8月 31 17:55 hadoop-root-nodemanager-hadoop01.out
-rw-r--r-- 1 root root 47741 8月 31 17:55 hadoop-root-resourcemanager-hadoop01.log
-rw-r--r-- 1 root root 2280 8月 31 17:54 hadoop-root-resourcemanager-hadoop01.out
-rw-r--r-- 1 root root 0 8月 31 17:04 SecurityAuth-root.audit
drwxr-xr-x 2 root root 6 8月 31 17:54 userlogs
3.10 *Hadoop***Web UI **页面
3.10.1 配置 windows 域名映射
- 以管理员身份打开 C:\Windows\System32\drivers\etc 目录下的 hosts 文件
- 在文件最后添加以下映射域名和 ip 映射关系

****3.10.2 访问 HDFS ****集群 UI 页面
其中 namenode_host 是 namenode 运行所在机器的主机名或者 ip。
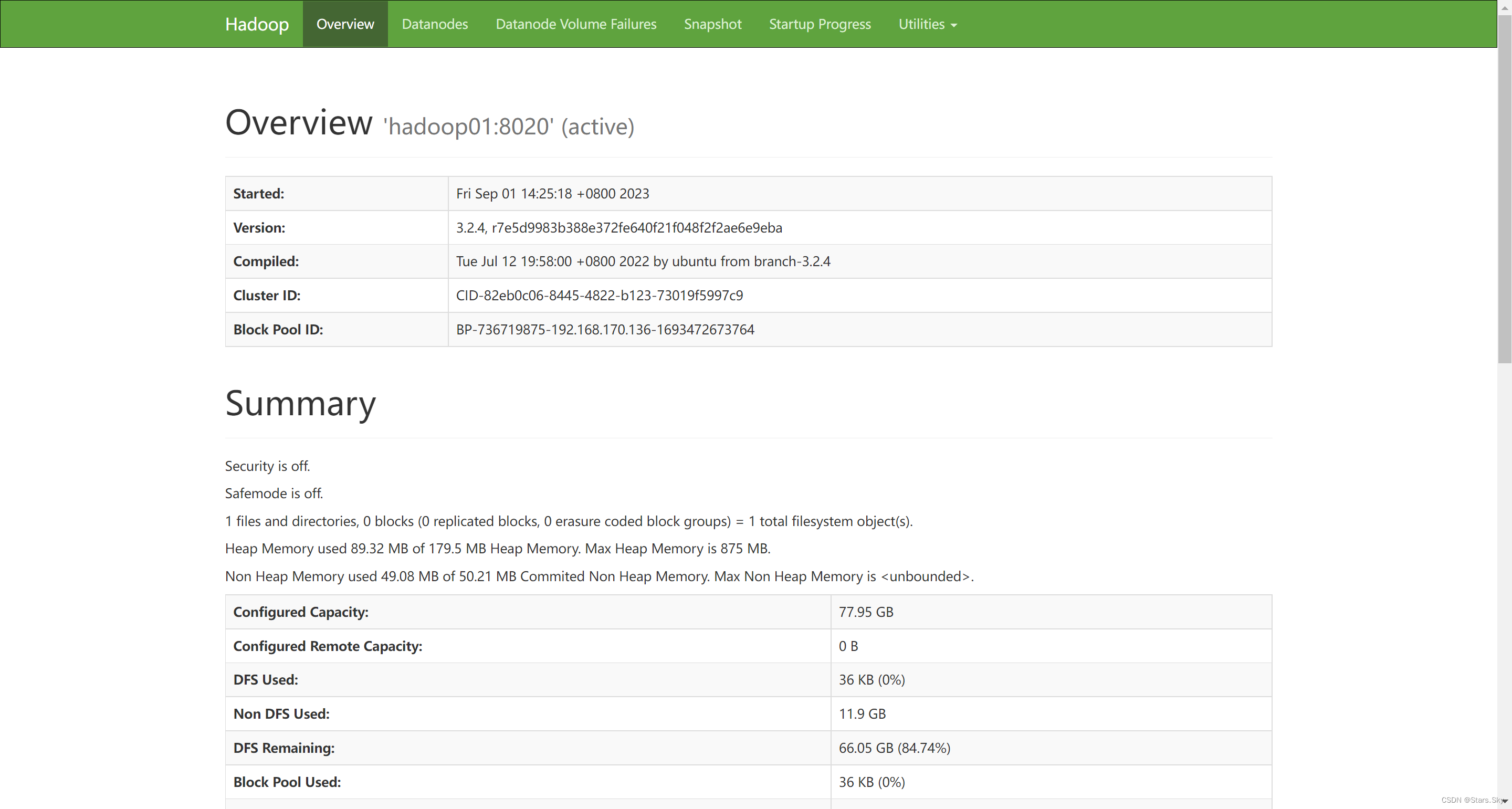
HDFS 文件系统 Web 页面浏览:

****3.10.3 访问 YARN ****集群 UI 页面
地址:http://resourcemanager_host:8088
其中 resourcemanager_host 是 resourcemanager 运行所在机器的主机名或者 ip。
3.10.4 访问 JobHistory 服务 UI 页面
# 启动 JobHistory 服务
[root@hadoop01 ~]# mapred --daemon start historyserver
地址:http://historyserver_host:19888/jobhistory
其中 historyserver_host 是 historyserver 运行所在机器的主机名或者 ip。

四、**Hadoop **初体验
4.1 **HDFS **初体验
4.1.1 shell 命令操作
[root@hadoop01 ~]# hadoop fs -mkdir /test1
[root@hadoop01 ~]# hadoop fs -put jdk-8u381-linux-x64.tar.gz /test1
[root@hadoop01 ~]# hadoop fs -ls /
Found 1 items
drwxr-xr-x - root supergroup 0 2023-09-01 14:43 /test1
4.1.2 Web UI 页面操作
 4.2 MapReduce+YARN****初体验
4.2 MapReduce+YARN****初体验
4.2.1 执行 Hadoop 官方自带的 MapReduce 案例
评估圆周率 π 的值:
[root@hadoop01 ~]# cd /bigdata/hadoop/server/hadoop-3.2.4/share/hadoop/mapreduce/
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/share/hadoop/mapreduce]# hadoop jar hadoop-mapreduce-examples-3.2.4.jar pi 2 4


下一篇文章:HDFS HA 高可用集群搭建详细图文教程_Stars.Sky的博客-CSDN博客
版权归原作者 Stars.Sky 所有, 如有侵权,请联系我们删除。