
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
提示:这里可以添加本文要记录的大概内容:
书接上回,传闻昔日数据导入有五大派别,一时之间数码武林局势动荡,可怜的码农处于水深火热之中。乱世出英雄,打着劫富济贫,替天行道大旗的六大帮派(数据导出)横空出世。
提示:以下是本篇文章正文内容,下面案例可供参考
一、数据导出是什么?
hive是一个依赖Hadoop集群的数据处理平台,我们不仅需要对数据进行筛选处理,更需要进行导出,供我们多次重复使用。
二、六大帮派
1.insert
insert有两种形式,加local上传到本地路径,不加local上传到集群
代码如下(示例):
insert加local
insert overwrite local directory '/root/export/data/student' select * from student;
insert不加local(并将数据格式化)
insert overwrite directory '/student' row format delimited fields terminated by ',' select * from student;
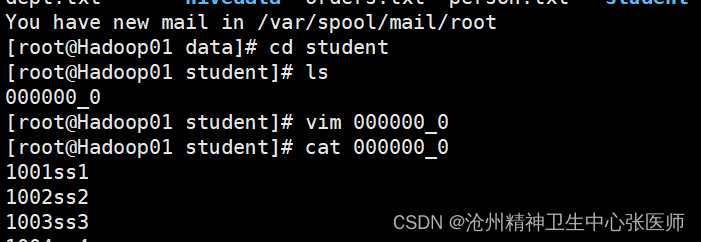
2.Hadoop命令导出到本地
代码如下(示例):
hadoop dfs -get /user/hive/warehouse/hive.db/student/student.txt /root/export/data/student/
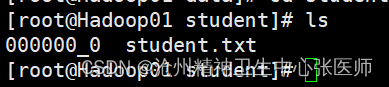
3.Hive shell命令导出
一个 > 是覆盖,两个>是追加
代码如下(示例):
bin/hive -e 'select * from hive.student'>>/root/export/data/student/student.txt
4.export导出到HDFS上
当该hdfs路径下有文件时或表存在,都不可导,与import连用。
代码如下(示例):
export table hive.student to '/user/hive/warehouse/hive.db/student';
5.Sqoop导出
将数据导出到window系统的mysql,并进行可视化操作
6.清除表中的数据(Truncate)——删库跑路
Truncate只能删除管理表,不能删除外部表的数据(但可以将外部表转为内部表哦,嘿嘿嘿)
只是删除内部表的hdfs数据,元数据还在
内部转为外部表
alter table student set tblproperties('EXTERNAL'='TRUE')一定大写
截断表
Truncate table student;
总结
六大派别与五大帮派共同统治着数码武林,侠义精神深入人心,hive语句妇孺皆知。街头小巷上谈论着他们的英雄事迹,再一次掀起了学习hive秘籍的狂潮。或许现在人们学习的已经不再是傍身之计,更多的是对天下武功,为快不灭的热爱。有人的地方就会就有江湖,大数据时代亦是如此。
本文转载自: https://blog.csdn.net/m0_64644104/article/details/130139281
版权归原作者 沧州精神卫生中心张医师 所有, 如有侵权,请联系我们删除。
版权归原作者 沧州精神卫生中心张医师 所有, 如有侵权,请联系我们删除。