
1.新建虚拟机
给虚拟机命名,选择存放路径
接着指定磁盘大小,因为我们不止搭建单机模式还要搭建伪分布模式,这里我们选择80G
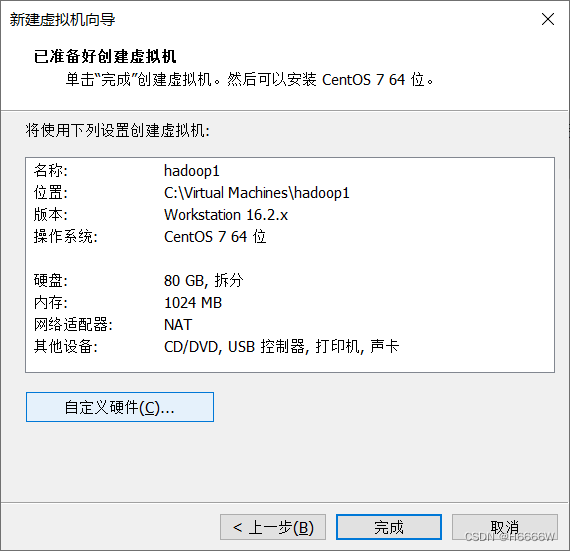
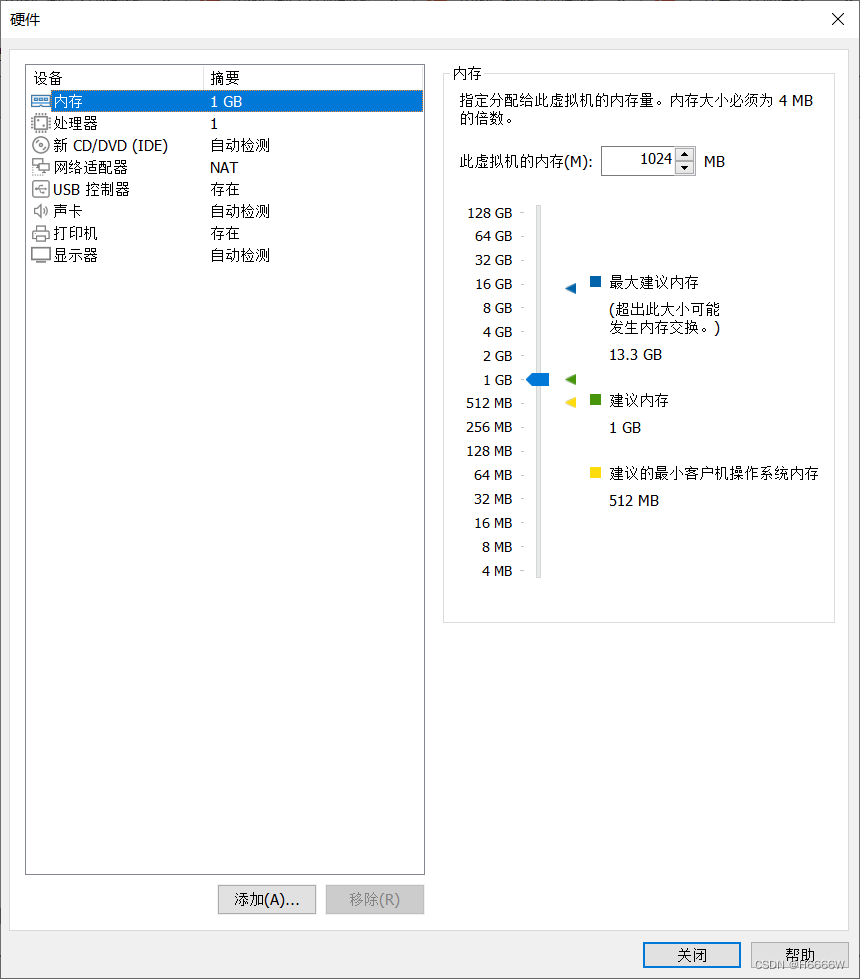
这里会看到创建虚拟机完成,我们点击自定义硬件,选择合适的内存,处理器,还有映像文件,这里我们用不到声卡和打印机可以给他移除
根据自己电脑配置选择合适的,这里我们选择完之后是这样的
然后我们开启虚拟机
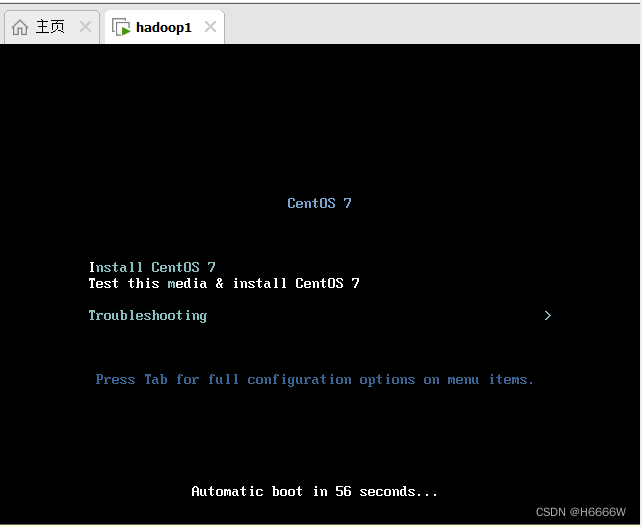
选择第一个centos7,鼠标点进去按↑,回车
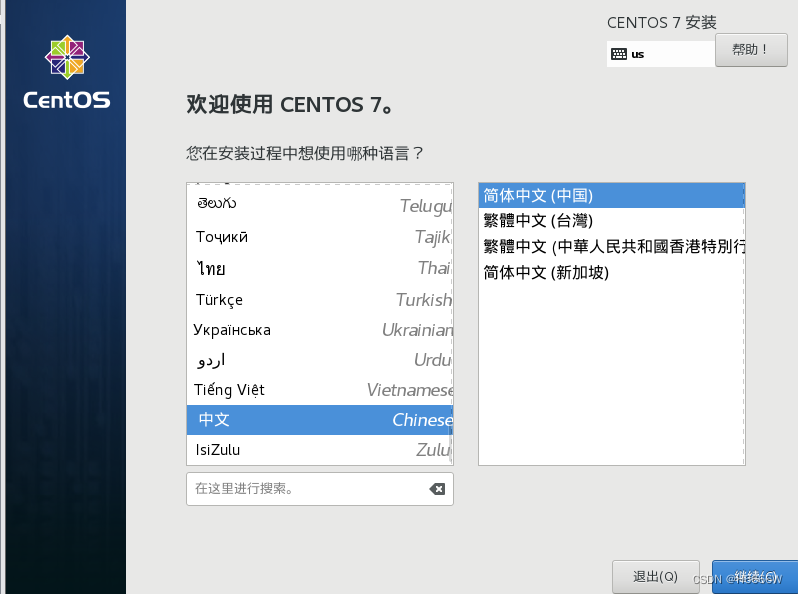
语言选择中文,根据自己
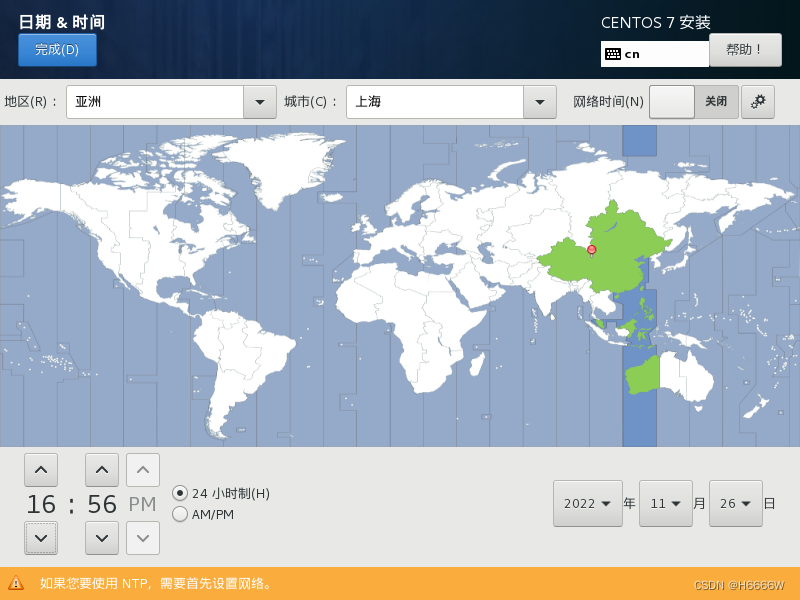
配置下时间,点击左上角完成
点击配置分区,关闭kdump
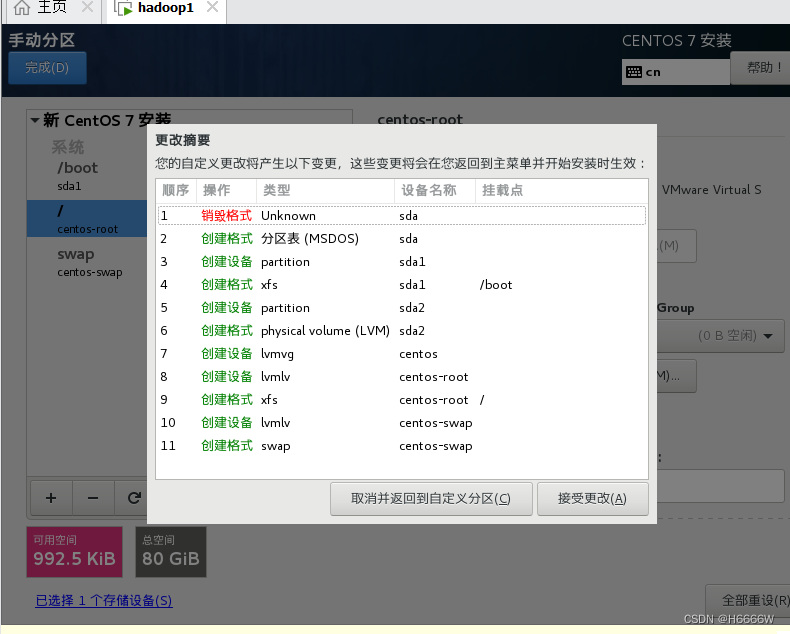
设置下root用户的密码等待安装
安装完之后点击重启,然后
网络文件编辑
/etc/sysconfig/network-scripts/ifcfg-ens33
配置下网络ip
虚拟机的网络ip是在左上角的编辑下虚拟机网络编辑器
编辑完之后我们重启一下网络服务并测试一下ping百度

2.连接访问工具
我用的是mobaxterm
输入root用户密码就可以进来了
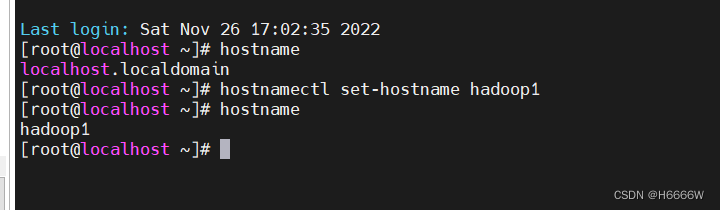
修改主机名
配置ip映射vi /etc/hosts

查看防火箱状态并且关闭
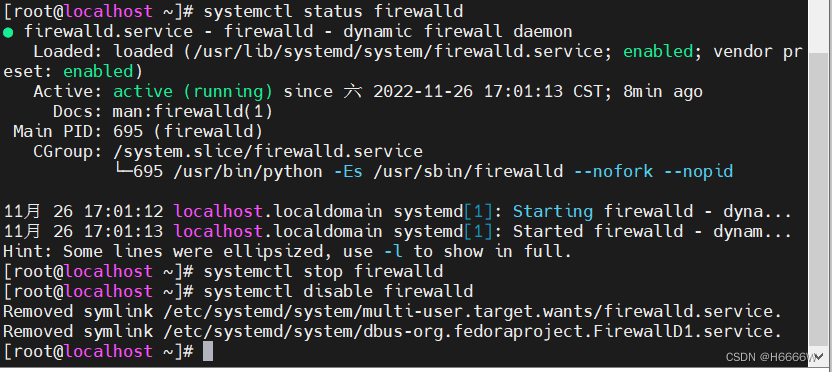
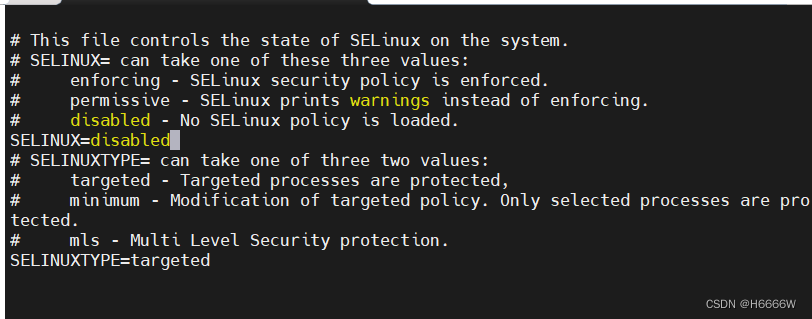
永久关闭selinux
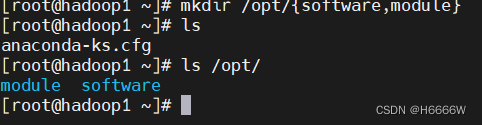
重启创建存放软件包和软件的目录
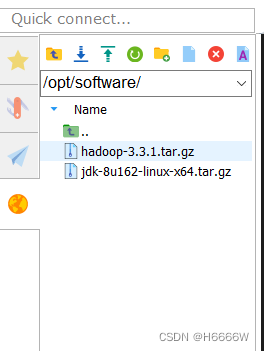
上传jdk和hadoop压缩包

解压到module目录
tar -zxvf /opt/software/hadoop-3.3.1.tar.gz -C /opt/module/
tar -zxvf /opt/software/jdk-8u162-linux-x64.tar.gz -C /opt/module/
解压完之后查看下

配置环境变量
vi /etc/profile
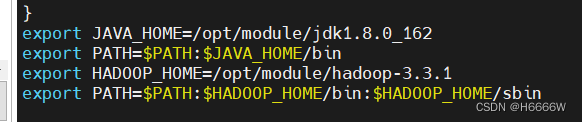
重新加载环境变量
source /etc/profile
测试
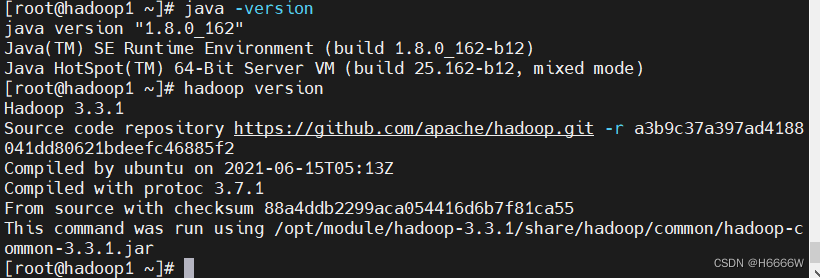
3.通过wordcount案例计算单词个数
切换到hadoop目录下并创建目录input/word.txt
编辑word.txt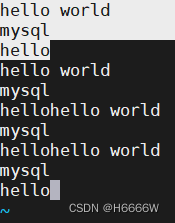
用Hadoop自带的计算框架计算单词个数

计算后查看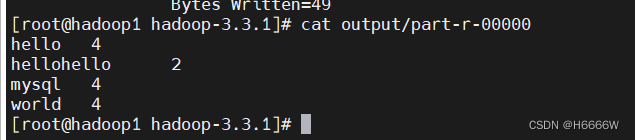
计算圆周率
hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar pi 10 10

本文转载自: https://blog.csdn.net/H6666W/article/details/128040745
版权归原作者 H6666W 所有, 如有侵权,请联系我们删除。
版权归原作者 H6666W 所有, 如有侵权,请联系我们删除。