
anchors
运行trains.py没有生成anchor原因
yolov5运行后有一行 autoanchor:
一些教程的生成图如下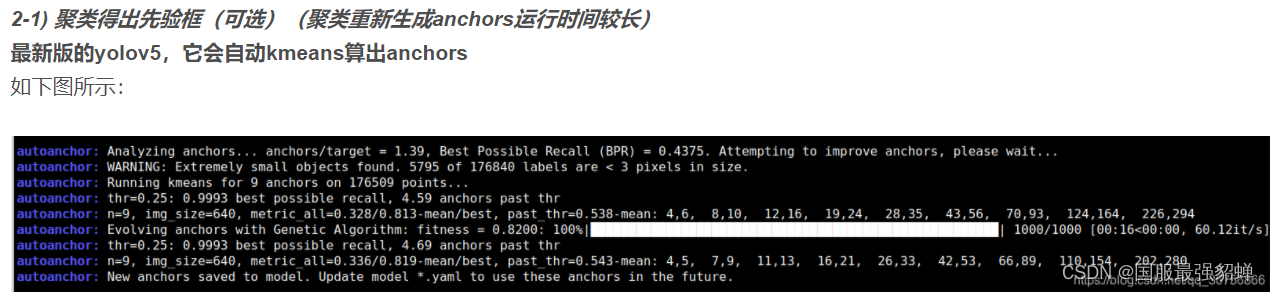
训练一开始会先计算
Best Possible Recall (BPR)
,当
BPR < 0.98
时,再在
kmean_anchors
函数中进行 k 均值 和 遗传算法 更新 anchors 。
但是我的数据集
BPR = 0.9997
,所以没有生成新的anchors。
默认的预设anchors很匹配我的训练数据,anchors就不会在更改,就使用预设的。
改了聚类的欧氏距离为iou,和去掉遗传算法,都没有预设的效果好。
yolov5s.yaml
anchor: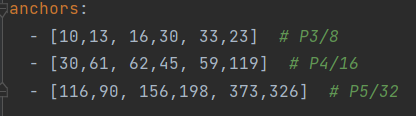
best.pt
的anchor查看一下和 s 一样
# #################查看模型 的 anchor #######################import torch
from models.experimental import attempt_load
model = attempt_load('runs/train/exp_xxxxxxxxxxxx/weights/best.pt', map_location=torch.device('cpu'))
m = model.module.model[-1]ifhasattr(model,'module')else model.model[-1]print(m.anchor_grid)
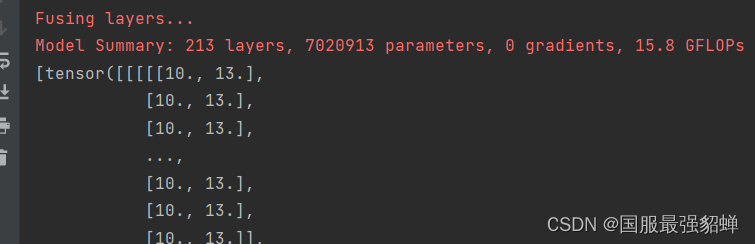
如果直接使用预设anchors:
训练时命令行添加
–noautoanchor
,表示不计算anchor,直接使用配置文件里的默认的anchor,不加该参数表示训练之前会自动计算。
程序
train.py
utils.autoanchor.py
当
BPR < 0.98
时,再在
kmean_anchors
函数中进行 k 均值 和 遗传算法 更新 anchors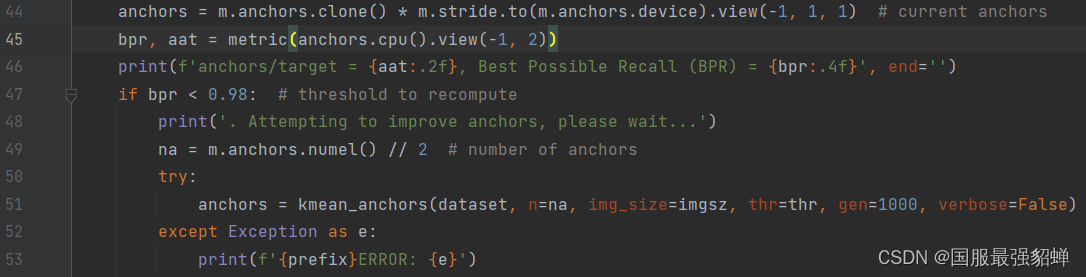
如果就要看它生成anchor的结果,可以把0.98改为0.9999

kmeans改动(距离、k-means++)
用 kmean_anchors 进行聚类。yolov5中用了kmeans和遗传算法。源代码
Kmeans calculation 欧氏距离聚类
和
遗传算法
。
作者默认使用的k-means方法是scipy包提供的,使用的是欧式距离。
博主改成了基于
1-IOU(bboxes, anchors)
距离的方法。
kmeans和kmeans++参考博客。k-means++算法,属于k-means算法的衍生,其主要解决的是k-means算法第一步,随机选择中心点的问题。
用聚类算法算出来的anchor并不一定比初始值即coco上的anchor要好,原因是目标检测大部分基于迁移学习,backbone网络的训练参数是基于coco上的anchor学习的,所以其实大部分情况用这个聚类效果并没有直接使用coco上的好!!而且聚类效果跟数据集的数量有很大关系,一两千张图片,聚类出来效果可能不会很好
autoanchor.py
# print(f'{prefix}Running kmeans for {n} anchors on {len(wh)} points...')# s = wh.std(0) # sigmas for whitening# k, dist = kmeans(wh / s, n, iter=30) # points, mean distance# assert len(k) == n, f'{prefix}ERROR: scipy.cluster.vq.kmeans requested {n} points but returned only {len(k)}'# k *= s
k = k_means(wh, n)
新建
yolo_kmeans.py
import numpy as np
# 这里IOU的概念更像是只是考虑anchor的长宽defwh_iou(wh1, wh2):# Returns the nxm IoU matrix. wh1 is nx2, wh2 is mx2
wh1 = wh1[:,None]# [N,1,2]
wh2 = wh2[None]# [1,M,2]
inter = np.minimum(wh1, wh2).prod(2)# [N,M]return inter /(wh1.prod(2)+ wh2.prod(2)- inter)# iou = inter / (area1 + area2 - inter)# k-means聚类,且评价指标采用IOUdefk_means(boxes, k, dist=np.median, use_iou=True, use_pp=False):"""
yolo k-means methods
Args:
boxes: 需要聚类的bboxes,bboxes为n*2包含w,h
k: 簇数(聚成几类)
dist: 更新簇坐标的方法(默认使用中位数,比均值效果略好)
use_iou:是否使用IOU做为计算
use_pp:是否是同k-means++算法
"""
box_number = boxes.shape[0]
last_nearest = np.zeros((box_number,))# 在所有的bboxes中随机挑选k个作为簇的中心ifnot use_pp:
clusters = boxes[np.random.choice(box_number, k, replace=False)]# k_means++计算初始值else:
clusters = calc_center(boxes, k)# print(clusters)whileTrue:# 计算每个bboxes离每个簇的距离 1-IOU(bboxes, anchors)if use_iou:
distances =1- wh_iou(boxes, clusters)else:
distances = calc_distance(boxes, clusters)# 计算每个bboxes距离最近的簇中心
current_nearest = np.argmin(distances, axis=1)# 每个簇中元素不在发生变化说明以及聚类完毕if(last_nearest == current_nearest).all():break# clusters won't changefor cluster inrange(k):# 根据每个簇中的bboxes重新计算簇中心
clusters[cluster]= dist(boxes[current_nearest == cluster], axis=0)
last_nearest = current_nearest
return clusters
# 计算单独一个点和一个中心的距离defsingle_distance(center, point):
center_x, center_y = center[0]/2, center[1]/2
point_x, point_y = point[0]/2, point[1]/2return np.sqrt((center_x - point_x)**2+(center_y - point_y)**2)# 计算中心点和其他点直接的距离defcalc_distance(boxes, clusters):"""
:param obs: 所有的观测点
:param clusters: 中心点
:return:每个点对应中心点的距离
"""
distances =[]for box in boxes:# center_x, center_y = x/2, y/2
distance =[]for center in clusters:# center_xc, cneter_yc = xc/2, yc/2
distance.append(single_distance(box, center))
distances.append(distance)return distances
# k_means++计算中心坐标defcalc_center(boxes, k):
box_number = boxes.shape[0]# 随机选取第一个中心点
first_index = np.random.choice(box_number, size=1)
clusters = boxes[first_index]# 计算每个样本距中心点的距离
dist_note = np.zeros(box_number)
dist_note += np.inf
for i inrange(k):# 如果已经找够了聚类中心,则退出if i +1== k:break# 计算当前中心点和其他点的距离for j inrange(box_number):
j_dist = single_distance(boxes[j], clusters[i])if j_dist < dist_note[j]:
dist_note[j]= j_dist
# 转换为概率
dist_p = dist_note / dist_note.sum()# 使用赌轮盘法选择下一个点
next_index = np.random.choice(box_number,1, p=dist_p)
next_center = boxes[next_index]
clusters = np.vstack([clusters, next_center])return clusters
还要多远才能进入你的心 还要多久才能和你接近
本文转载自: https://blog.csdn.net/zrg_hzr_1/article/details/121714910
版权归原作者 国服最强貂蝉 所有, 如有侵权,请联系我们删除。
版权归原作者 国服最强貂蝉 所有, 如有侵权,请联系我们删除。