
在上篇演示使用了 Request 模块采集智联招聘网站 PC 端网页的招聘信息,结果遇到了比较隐蔽的反爬限制(当时还不清楚什么原因导致的),看来使用该模块这条路暂时走不通了,打算换用 Selenium 模块试试,并尝试寻找该网站反爬限制的具体原因。
一、环境准备
- Google 浏览器及 chromedriver.exe 驱动插件;
- 支持 Python 编程的编辑器(比如 PyCharm);
- pip 下载 selenium、BeautifulSoup、csv 等模块;
注意:谷歌浏览器的驱动插件的安装和验证,在爬虫入门做过介绍,此处不再说明了。
二、使用 Selenium 模块
当选取目标网页后,最重要的是进行网页结构的分析,从而定位出目标元素。上篇已经做过了具体的分析,这里不再重复叙述了,而是直接使用 selenium 模块实现数据采集,并尝试寻找之前存在的反爬原因。
主体方法的思路:
- 使用 selenium 模块的 webdriver 驱动库模拟打开浏览器;
- 发送 get 请求,访问智联招聘在杭州招聘 Python 职位的第一页地址(暂不使用多个窗口的切换);
- 智能等待 10s 后,获取第一页的网页源代码,并写入 txt 文件保存;
- 接着就是解析和定位网页元素了,这块的步骤和方式和以前一样,提取到目标数据后写入csv文件保存,最后退出并关闭浏览器。
测试爬取第一页,演示如下:
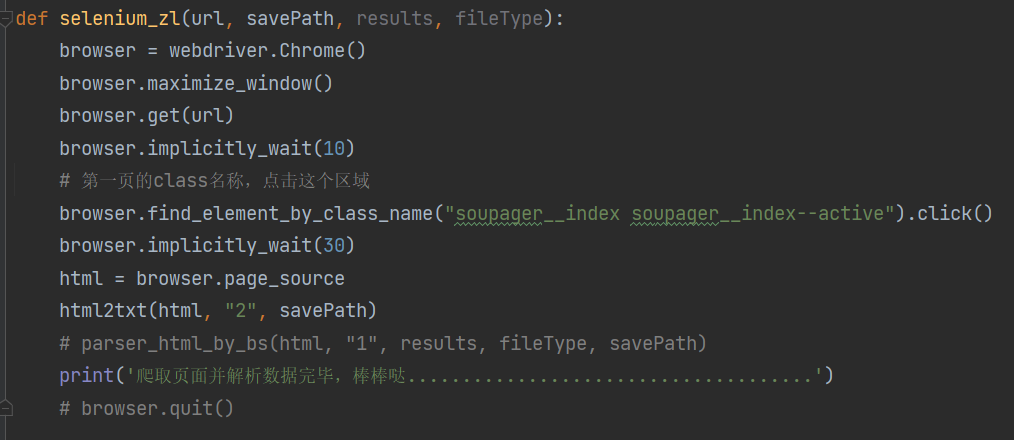
def selenium_zl(url, savePath, results, fileType):
browser = webdriver.Chrome()
browser.get(url) # https://sou.zhaopin.com/?jl=653&kw=Python
browser.implicitly_wait(10)
html = browser.page_source
html2txt(html, "1", savePath)
parser_html_by_bs(html, "1", results, fileType, savePath)
print('爬取页面并解析数据完毕,棒棒哒.....................................')
browser.quit()
txt 文件内容分析:
当拿到了网页源代码,就可以开始验证保存的 html 网页是不是采集到了第一页数据,我随便搜索了"合码控股"关键字,在 txt 文件里竟然不存在啊,如下:

快要怀疑人生了?!看来和选择的模块是没有多大关系啊。
山重水复,柳暗花明:
重新理了一下思路,我把解析网页和退出浏览器的代码暂时注释掉,然后增加浏览器的点击代码,此时仿佛看到了一些不一样的东西,代码如下:
此时,模拟浏览器没有退出,可以看到第一页的页面内容,如下:
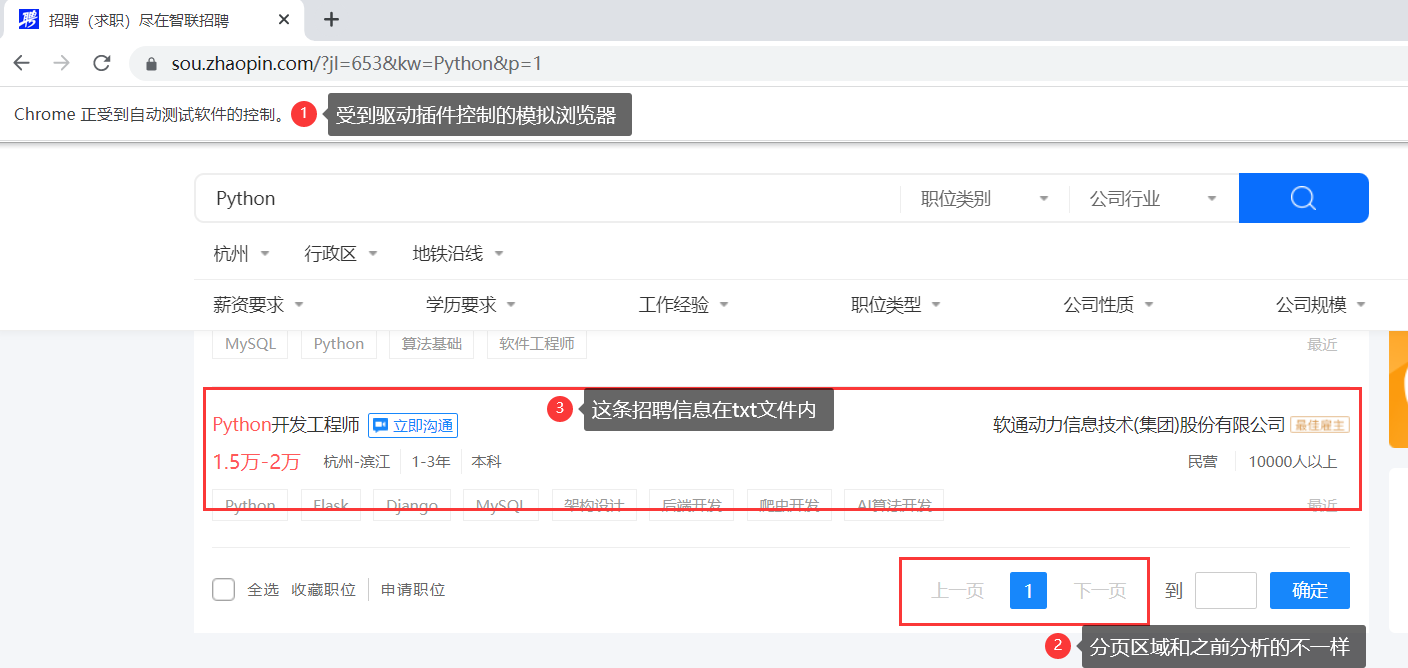
到这里,似乎知道为什么了?原来是被 Session 访问限制啊,将模拟浏览器的页面翻到最前面,就明白了,如下所示:

这真是太折腾人了,现在反思一下,在之前分析的时候,我已经在浏览器里已经做过手动登录了,为什么使用爬虫代码的时候还要登录呢?!看来不能想当然啊,这下明白了怎么回事之后,就可以针对性的绕过。
道高一尺,魔高一丈:
如果被 Session 访问限制的话,在发起请求之前,创建 Session 会话登陆就行了。然而,事情并没那么简单啊,智联招聘的 PC 端网页只允许手机号 + 短信验证码的方式进行登录!!!顿时感到很无语,这又极大的增加爬取方的爬取难度,哎,心真累!
经过一番研究和测试,目前大致有两种可行的解决方案:
- 一是,想办法将手机上的验证码转发到某个第三方平台,然后,自动化爬虫代码再去该平台的服务器上去请求获取。
- 二是,先进行手动登录网站,通过抓取已登录状态的 cookie,在自动化爬虫代码里使用该 cookie 模拟登录。
第一种方案,难度较大,需要有不少的知识储备才行。比如,需要了解监听手机短信的收发机制和熟悉 Flask 框架的使用,或者干脆使用打码平台,或者自己实现深度学习算法等不同的方式。考虑到安全性,以及实现起来比较复杂,哈哈哈,顿时被劝退了,目前自己的知识体系和储备还不足,后面再进行深入研究吧。
第二种方案,难度稍低,但需要熟悉 HTTP 通讯方面的一些知识。这种方式简单可行,建议使用,因此,打算在下篇将重点说明如何绕过短信验证码实现登录的。
三、小结
至此,困扰已久的问题原因终于找到了,原来还是网站的反扒限制啊!特此记录一下。
接下来将继续研究该问题的解决方法,并实现之前的目标,下篇将总结和梳理,就这样。
版权归原作者 谁是谁的小确幸 所有, 如有侵权,请联系我们删除。