
文章目录
1. 概述
在创建表时,可以使用
row format ...
指定分隔符形式。比如:
createtable external student (
name string,
age int);row format delimited fieldsterminatedby','
但是,根据原始数据分隔符的复杂程度,需要指定不同的分隔形式。比如:
- 情况一:分隔符为单字节

- 分隔符为多字节

- 字段中包含了分隔符
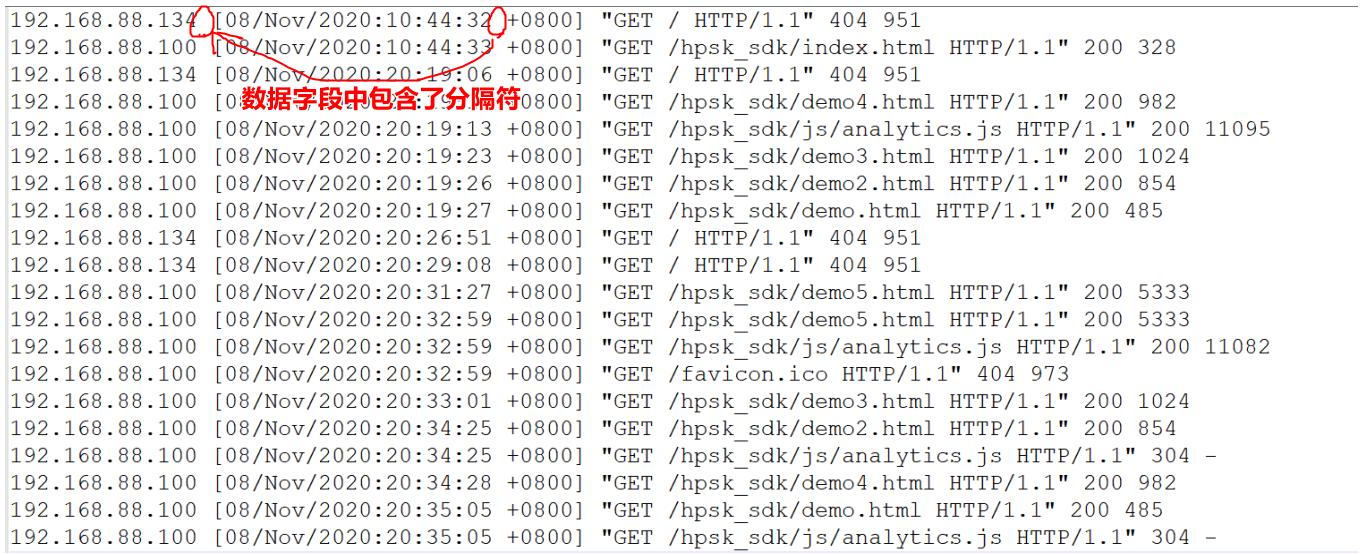
2. 单字节分隔符
方法:使用delimited关键字
加上
delimited
关键字,即使用
row format delimited
:用于处理单分隔符问题
fields terminated by ',':每个列之间用,分割collection items terminated by '-':集合之间的元素用-分割map keys terminated by ':':键值对之间用:分割lines terminated by '\n':每一行数据按\n分割
createtable external student (
name string,
age int);row format delimited
fieldsterminatedby','
collection items terminatedby'-'
map keysterminatedby':'linesterminatedby'\n';
3. 其它复杂情况
方式一:写MR程序进行字符替换转为单字节分隔符问题(不推荐)
不推荐,因此不详细介绍,具体可见:https://www.bilibili.com/video/BV1L5411u7ae?p=112&vd_source=5534adbd427e3b01c725714cd93961af
缺点:
- 写完替换分隔符的MR程序后,要导成jar包,再上传到hive。跑完替换分隔符的MR程序后,再去跑创建表的MR程序。故需要跑两个MR程序。
- 改变了原始数据
方式二:自定义InputFormat转为单字节分隔符问题(不推荐)
不推荐,因此不详细介绍,具体可见:https://www.bilibili.com/video/BV1L5411u7ae?p=114&vd_source=5534adbd427e3b01c725714cd93961af
缺点:
- 在导入数据时进行分隔符的替换。虽然只用跑一个创建表的MR程序。但是也要导jar包,很麻烦。
方式三:使用serde关键字 (推荐)
除了使用最多的LazySimpleSerDe,Hive该内置了很多SerDe类;
官网地址:https://cwiki.apache.org/confluence/display/Hive/SerDe
多种SerDe用于解析和加载不同类型的数据文件,常用的有ORCSerDe 、RegexSerDe、JsonSerDe等。
这里介绍的是:使用RegexSerDe来加载特殊数据的问题,使用正则匹配来加载数据。
那么这一块的难点在于 正则表达式 的构造。 比如:

createtable apachelog(
ip string,--IP地址
stime string,--时间
mothed string,--请求方式
url string,--请求地址
policy string,--请求协议
stat string,--请求状态
body string --字节大小)--指定使用RegexSerde加载数据row format serde 'org.apache.hadoop.hive.serde2.RegexSerDe'--指定正则表达式with serdeproperties ("input.regex"="([^ ]*) ([^}]*) ([^ ]*) ([^ ]*) ([^ ]*) ([0-9]*) ([^ ]*)")
stored as textfile ;
本文转载自: https://blog.csdn.net/qq_43546676/article/details/128313097
版权归原作者 ElegantCodingWH 所有, 如有侵权,请联系我们删除。
版权归原作者 ElegantCodingWH 所有, 如有侵权,请联系我们删除。