
1.Hadoop集群搭建
(1)单机模式
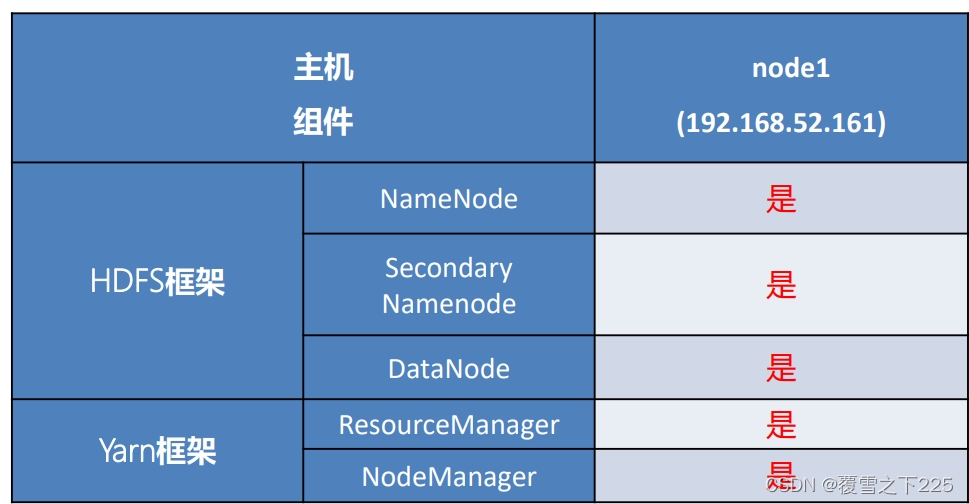
(2)集群模式
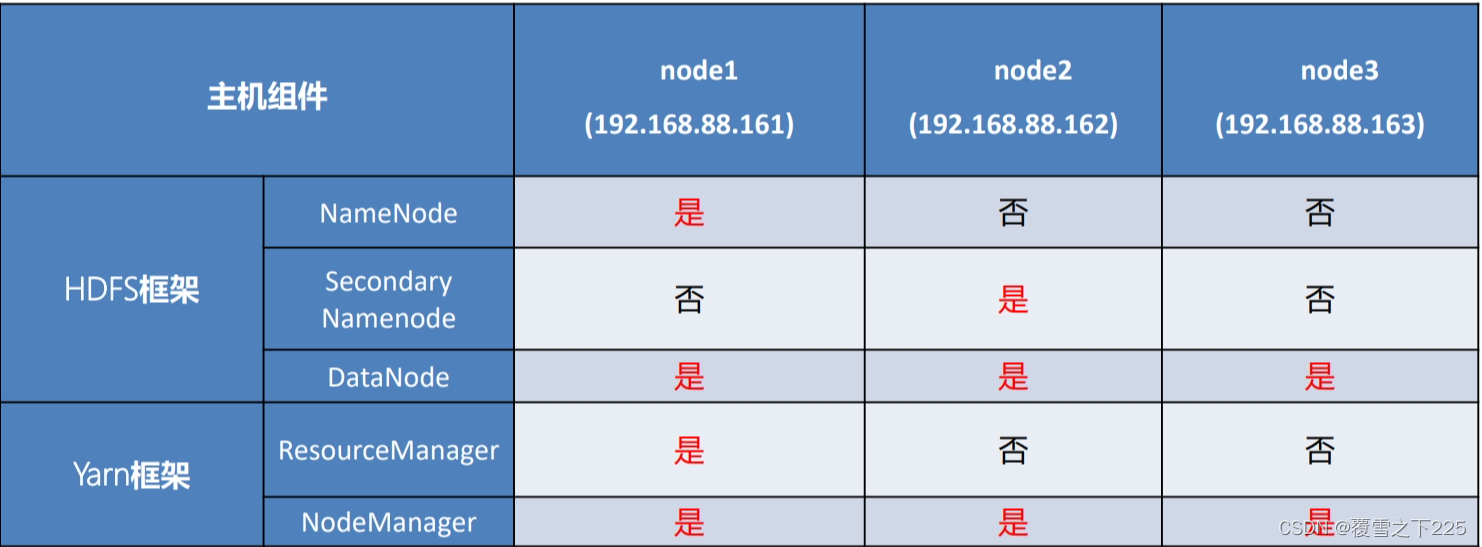
2.Hadoop集群使用
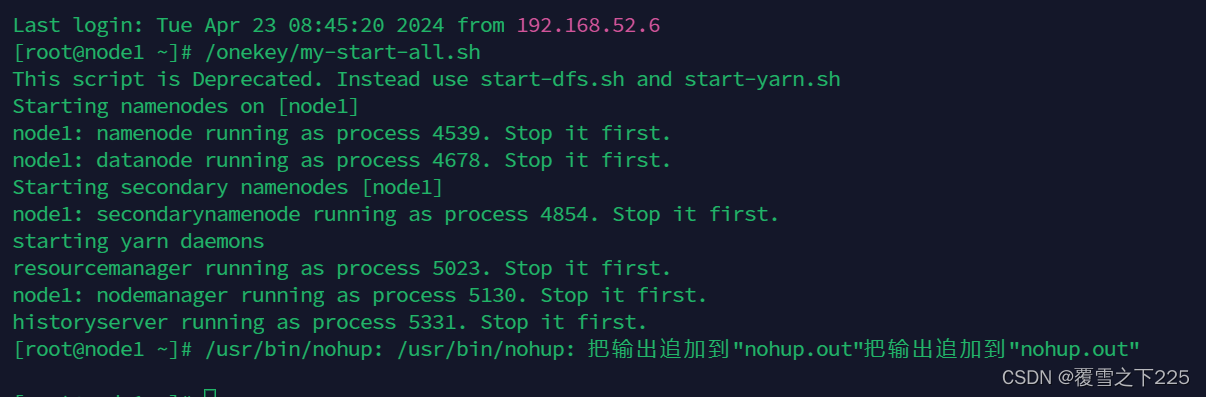
(1)一键启动大数据环境 /onekey/my-start-all.sh
(2)一键关闭大数据环境 /onekey/my-stop-all.sh
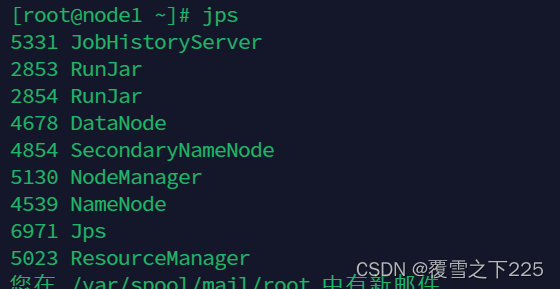
(3)查看进程 jps
(4)查看hdfs页面 2.x版本:50070 3.x版本:9870
(5)查看yarn页面 8088
(6)查看日志 19888
3.Hadoop集群使用
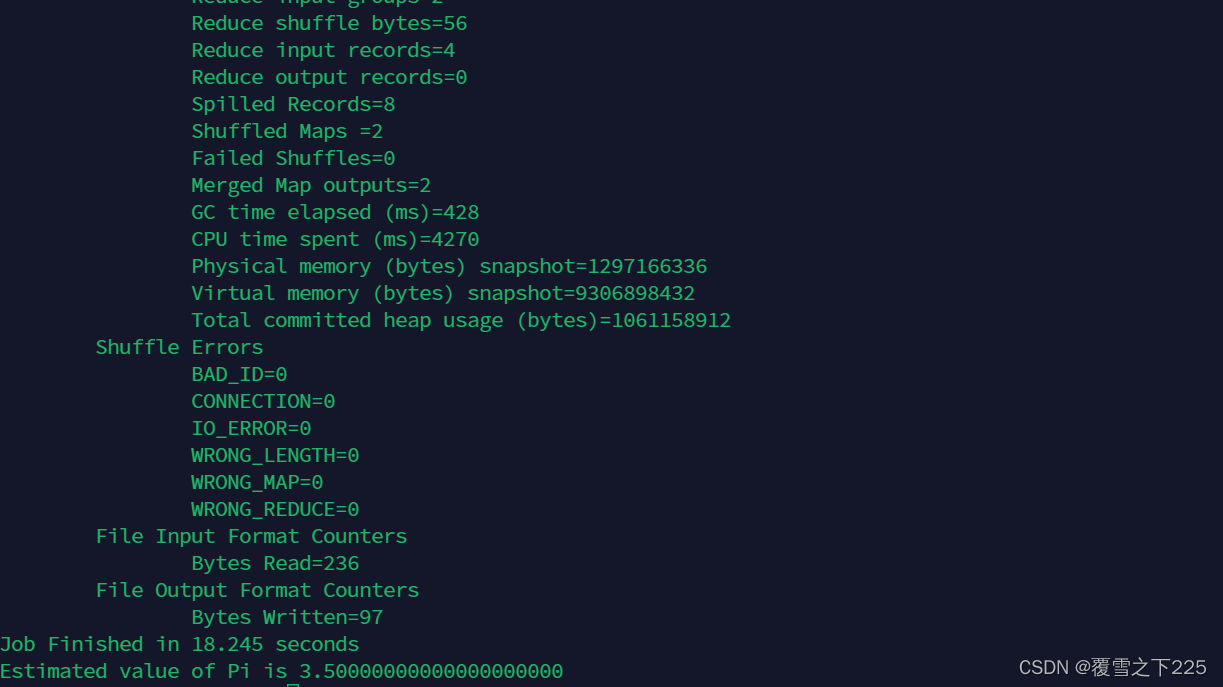
评估圆周率
(1)cd /export/server/hadoop-2.7.5/share/hadoop/mapreduce
(2)hadoop jar hadoop-mapreduce-examples-2.7.5.jar pi x y
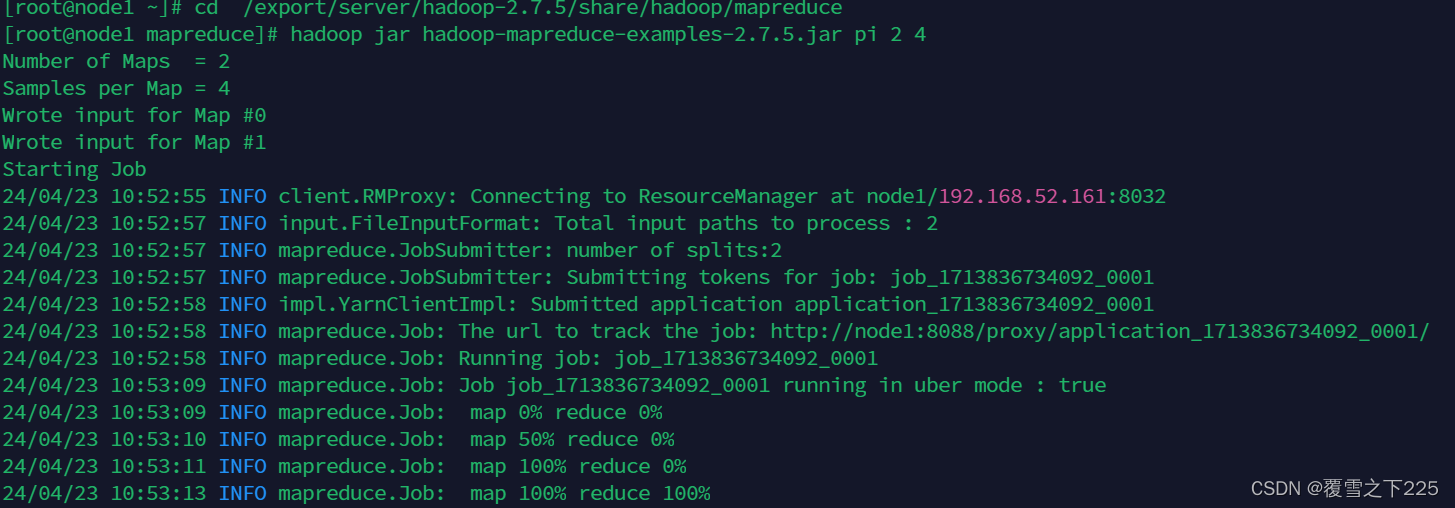
第一个参数pi:表示MapReduce程序执行圆周率计算;
第二个参数x:用于指定map阶段运行的任务次数,并发度
第三个参数!y:用于指定每个map任务取样的个数!
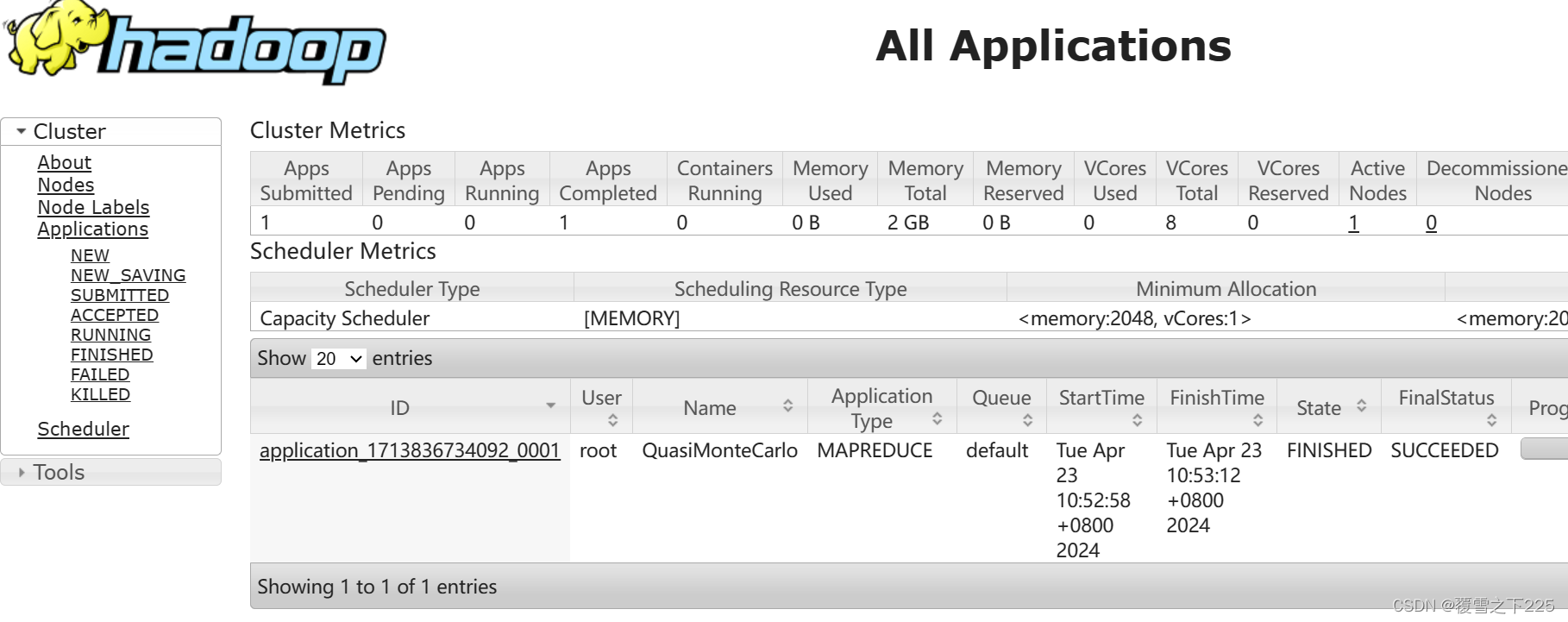
(3)查看yarn页面
3.hadoop的shell命令
Hadoop提供了文件系统的shell命令使用格式如下: hadoop fs <args>或者 hdfs dfs <args>
(1)ls命令
格式: hadoop fs -ls URI
作用:类似于Linux的ls命令,显示文件列表 hadoop fs -ls / #显示文件列表 hadoop fs –ls -R / #递归显示文件列表
(2) mkdir命令
格式 : hadoop fs –mkdir [-p] <paths>
作用 : 以中的URI作为参数,创建目录。使用-p参数可以递归创建目录
应用: hadoop fs -mkdir /dir1 hadoop fs -mkdir -p /aaa/bbb/ccc
(3) mv命令
格式 : hadoop fs -mv
作用: 将hdfs上的文件从原路径src移动到目标路径dst,该命令不能夸文件系统
应用: hadoop fs -mv /dir1/1.txt /dir2
(4) rm命令
格式: hadoop fs -rm [-r] [-skipTrash] URI [URI 。。。] 作用: 删除参数指定的文件和目录,参数可以有多个,删除目录需要加-r参数 如果指定-skipTrash选项,那么在回收站可用的情况下,该选项将跳过回收站而直接删除文件; 否则,在回收站可用时,在HDFS Shell 中执行此命令,会将文件暂时放到回收站中。
应用: hadoop fs -rm /initial-setup-ks.cfg #删除文件 hadoop fs -rm -r /dir2 #删除目录
(5) cp命令
格式: hadoop fs -cp
作用: 将文件拷贝到目标路径中
应用: hadoop fs -cp /dir1/1.txt /dir2
(6)cat命令
格式: hadoop fs -cat
作用: 将参数所指示的文件内容输出到控制台
应用: hadoop fs -cat /dir1/1.txt
(7) put命令
格式 : hadoop fs -put ...
作用 : 将单个的源文件或者多个源文件srcs从本地文件系统上传到目标文件系统中。
应用: hadoop fs -put /root/1.txt /dir1 #上传文件 hadoop fs –put /root/dir2 / #上传目录
4.Hive体验
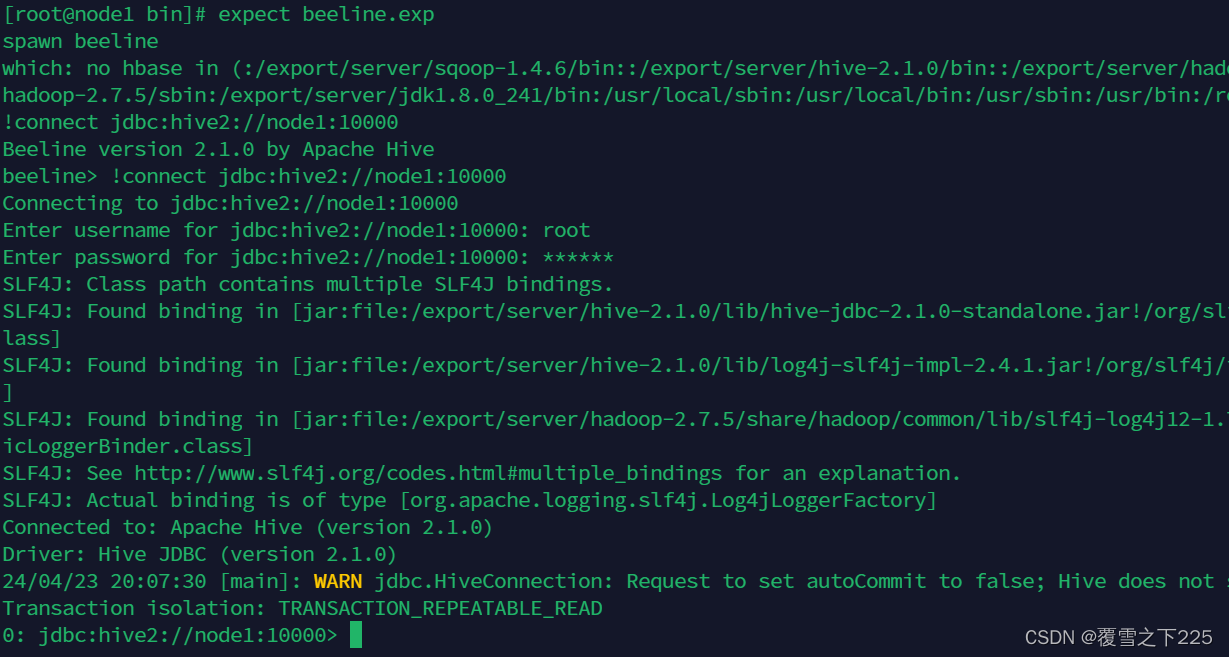
(1)进入hive shell环境
expect beeline.exp
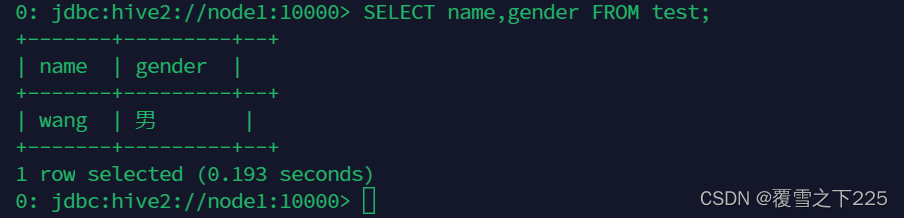
(2)创建表 CREATE TABLE test(id INT,name STRING,gender STRING);
(3)插入数据 INSERT INTO test VALUES(1,'wang','男');
(4)查询数据 SELET name,gender FROM test;
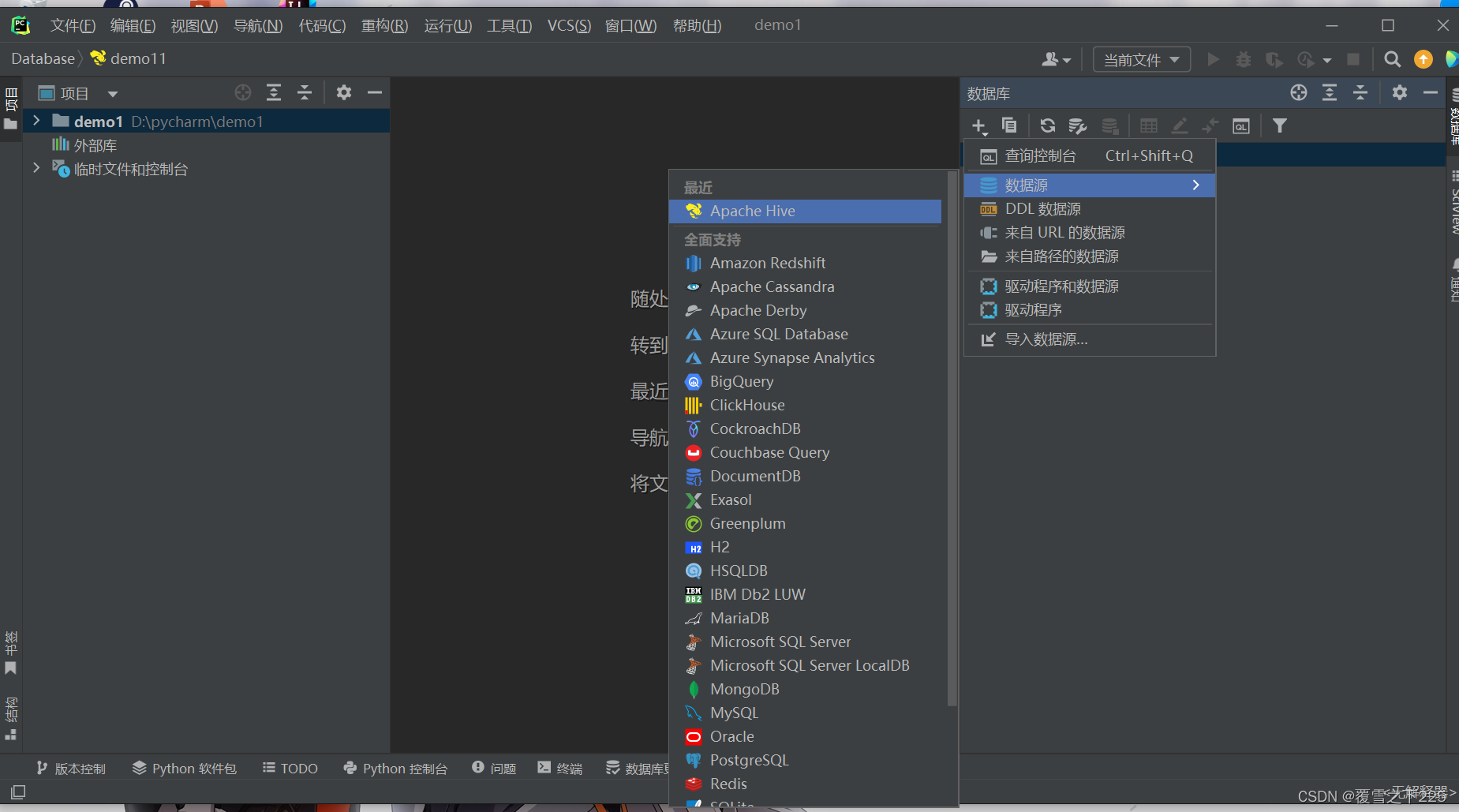
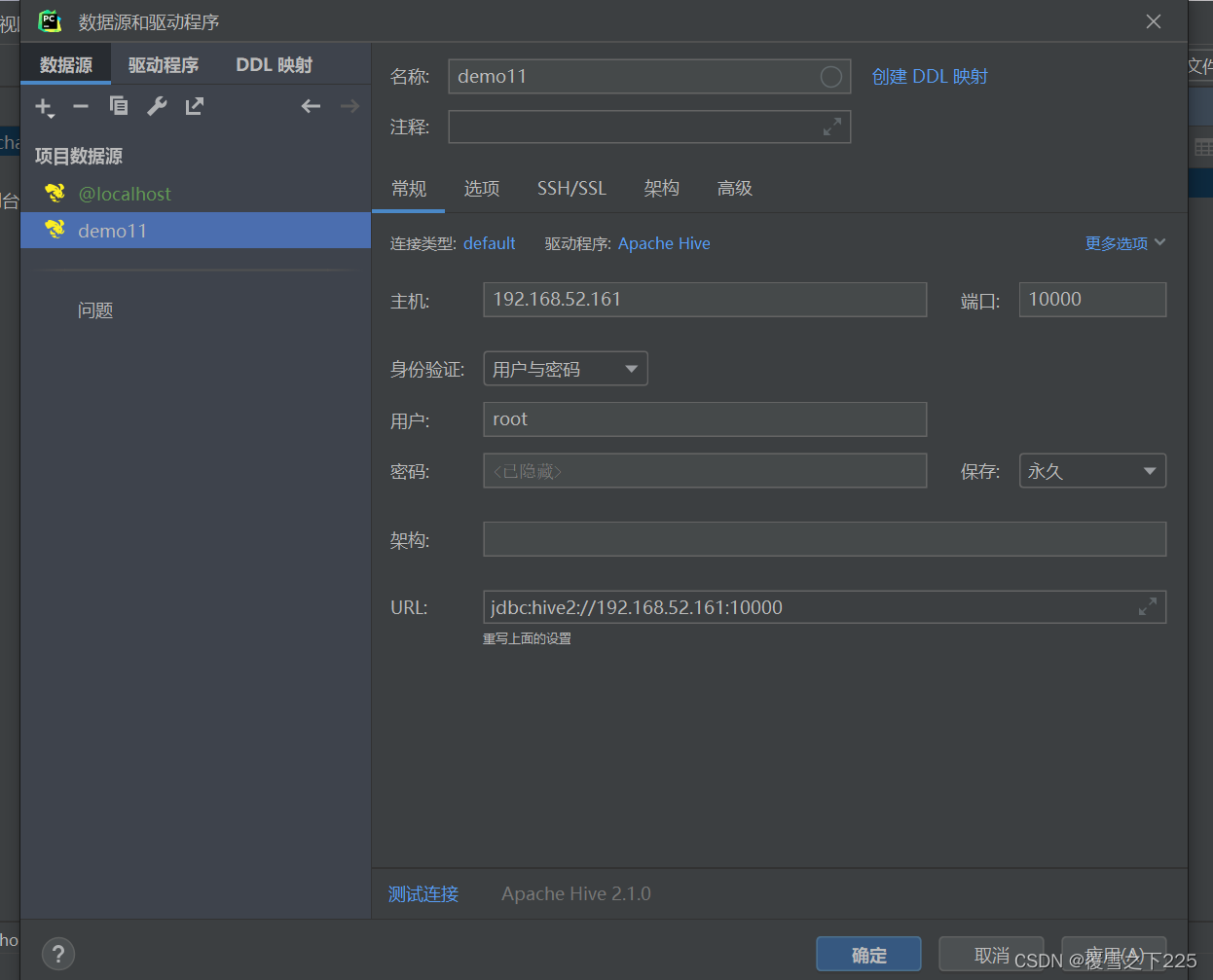
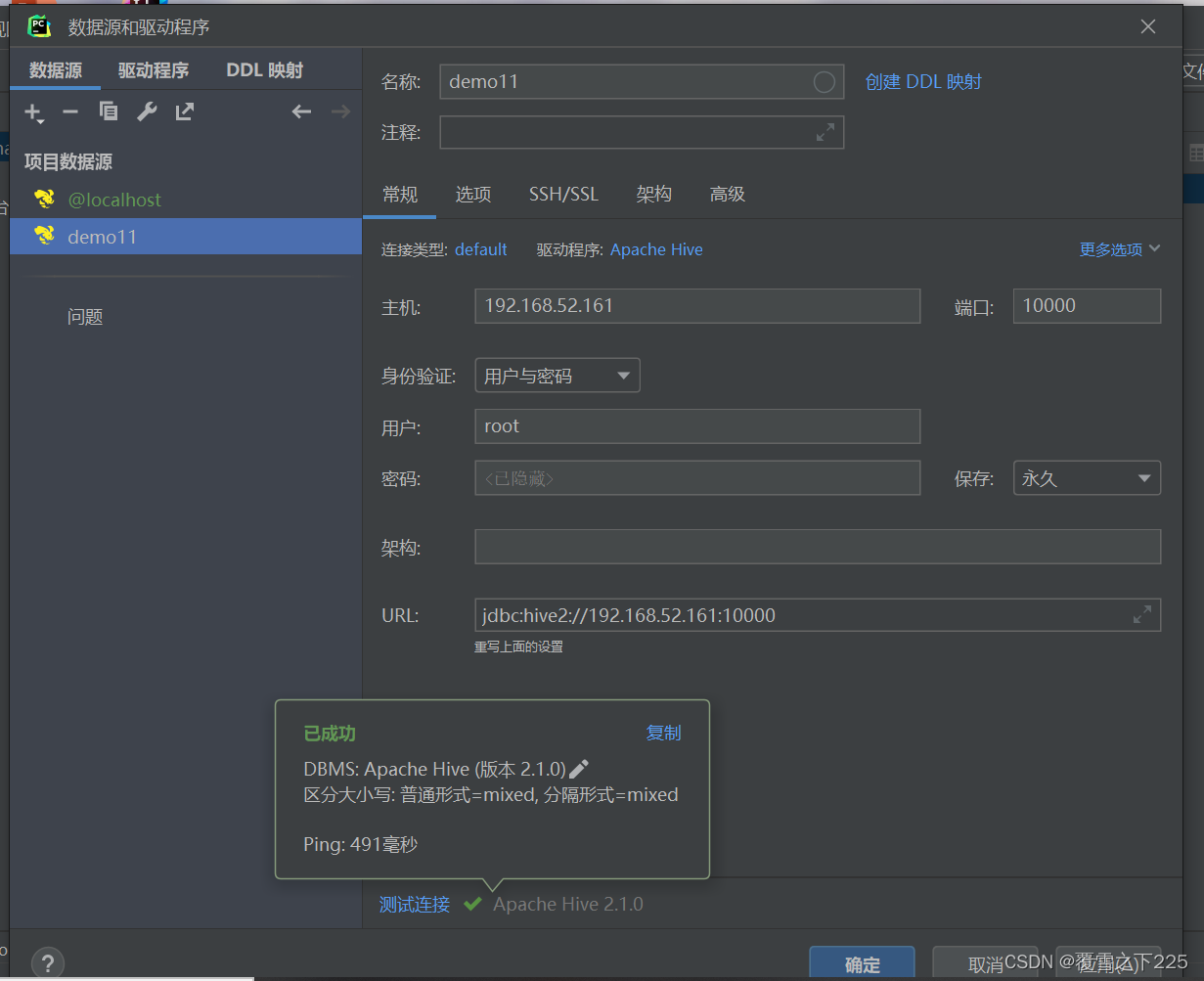
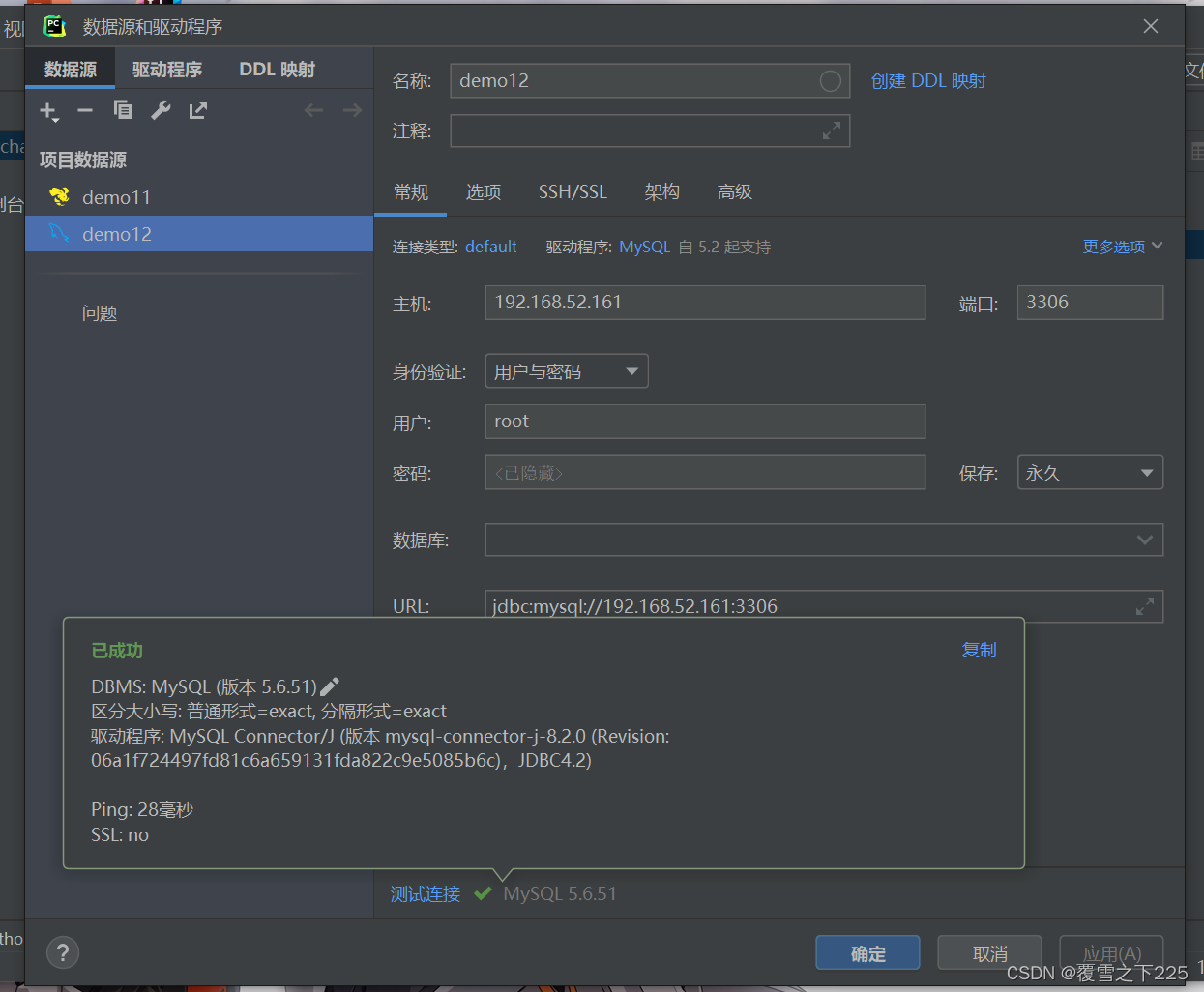
5.Hive链接客户端


版权归原作者 覆雪之下225 所有, 如有侵权,请联系我们删除。