
基本使用方法
echarts-wordcloud是基于echarts的一个词云库,是我常用的一个组件,业务上用的多一点,但是这个库在echarts的官网文档里面没有说明,git上的说明也很少,有些配置需要自己摸索,下面都是我的血泪总结。官方github地址
依赖
首先要安装echarts包,这是基础包,然后还需要额外引入词云的包,对应的版本可自行选择,我这不是最新的
“echarts-wordcloud”: “^2.0.0”
“echarts”: “^5.1.2”
项目中使用:
import*as echarts from'echarts'import'echarts-wordcloud'
echarts-wordcloud 的基本配置项
首先基本使用:
// 这里和echarts的使用一样,先拿到容器元素const chart = echarts.init(document.getElementById('tlrealtimewordcloud'))// 这里是官方给出的一些基本的配置项,我做一些说明
chart.setOption({...
series:[{
type:'wordCloud',// shape这个属性虽然可配置,但是在词的数量不太多的时候,效果不明显,它会趋向于画一个椭圆
shape:'circle',// 这个功能还没用过
keepAspect:false,// 这个是可以自定义背景图片的,词云会按照图片的形状排布,所以有形状限制的时候,最好用背景图来实现,而且,这个背景图一定要放base64的,不然词云画不出来
maskImage: maskImage,// 下面就是位置的配置
left:'center',
top:'center',
width:'70%',
height:'80%',
right:null,
bottom:null,// 词的大小,最小12px,最大60px,可以在这个范围调整词的大小
sizeRange:[12,60],// 每个词旋转的角度范围和旋转的步进
rotationRange:[-90,90],
rotationStep:45,// 词间距,数值越小,间距越小,这里间距太小的话,会出现大词把小词套住的情况,比如一个大的口字,中间会有比较大的空隙,这时候他会把一些很小的字放在口字里面,这样的话,鼠标就无法选中里面的那个小字,这里可以用函数根据词云的数量动态返回间距
gridSize:8,// 允许词太大的时候,超出画布的范围
drawOutOfBound:false,// 布局的时候是否有动画
layoutAnimation:true,// 这是全局的文字样式,相对应的还可以对每个词设置字体样式
textStyle:{
fontFamily:'sans-serif',
fontWeight:'bold',// 颜色可以用一个函数来返回字符串,这里是随机色color:function(){// Random colorreturn'rgb('+[
Math.round(Math.random()*160),
Math.round(Math.random()*160),
Math.round(Math.random()*160)].join(',')+')';}},
emphasis:{
focus:'self',
textStyle:{
textShadowBlur:10,
textShadowColor:'#333'}},// 数据必须是一个数组,数组是对象,对象必须有name和value属性
data:[{
name:'Farrah Abraham',
value:366,// 这里就是对每个字体的样式进行设置
textStyle:{}}]}]});
优化项
shape
shape也可以是一个函数,比如希望是矩形的时候(来自官方githup问答区)
shape:functionshapeSquare(theta){return Math.min(1/ Math.abs(Math.cos(theta)),1/ Math.abs(Math.sin(theta)))},
gridSize
可以用一个函数根据词云的数量动态确定词间距
color
颜色可以在外面统一配置,也可以像下文那样给每个词都配置一下,这里推荐一组好看的配色
['#86D4FF','#FF8F6C','#2CF263','#9FA8F7','#1274FF','#E6613D','#FFC629','#FFAB2E','#F78289','#FF6C96','#45BFD4','#4E31FF','#31FBFB','#86D4FF','#BF8AFD','#FFF500','#DE58FF','#72ED7C','#0BEEB8','#931CFF','#3D25F2','#F995C8','#FBE9B4','#FF4AB6']
效果是这样的
权重问题
组件会严格按照value值的大小分配权重,权重就体现在字体大小上。所以如果数据本身分布不均匀的时候,视觉效果看起来不够好,比如一个数为10000,其他的数为100-10,那么只能体现出两种权重了,即10000和其他。但是这样往往会导致视觉上,权重的分层不够明显,所以我们这个时候需要给数据分配权重,也就是改变每个词的fontSize.
代码主要思路是:
- 数据量少于8个的时候,仅做了颜色的处理(业务需求,只有红黑两系颜色)
- 数据量大于8个的时候,二分法,把数据分成四部分,
- 对于第一梯队的数据来说,一般是最重要的,至少也有两个数据,我们只对这一部分的数据做权重处理,就可以有良好的视觉效果
- 最大的那个词,给一个最大的权重60,第二个和第三个,分别给55和40,剩下的就是(40-排名数)
- 如果还有需求的话,可以再细化一点,如果能上相关的聚类算法,那就更完美了 大体效果为:
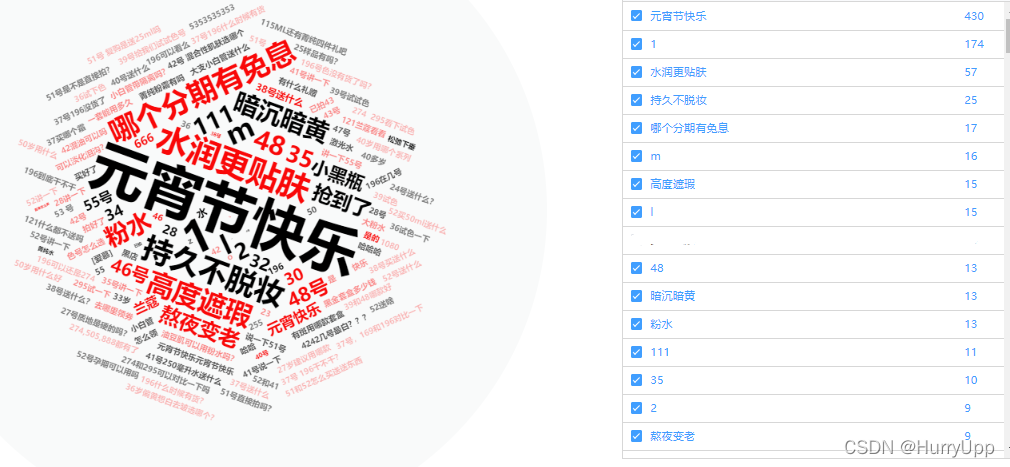 可以看见,排名靠前的都显示的比较好,直观而且有层次感
可以看见,排名靠前的都显示的比较好,直观而且有层次感
// 这里是我自己摸索的四分法,面对数据分配不均匀的时候还是挺有效果的const blackcolor =['#000000','#2a2a2a','#545454','#7e7e7e']const redcolor =['rgb(249,8,8)','rgba(249,8,8, 0.7)','rgba(249,8,8, 0.5)','rgba(249,8,8, 0.3)']constiterate=(arr, i, j, l)=>{if(l ===0){for(let k = i; k <= j; k++){if(k ===0){
arr[k].textStyle ={ color: blackcolor[l], fontSize:60}}elseif(k <3){if(k %2===0){
arr[k].textStyle ={ color: redcolor[l], fontSize:40}}else{
arr[k].textStyle ={ color: blackcolor[l], fontSize:55}}}else{if(k %2===0){
arr[k].textStyle ={ color: redcolor[l], fontSize:40- k }}else{
arr[k].textStyle ={ color: blackcolor[l], fontSize:40- k }}}}}else{for(let k = i; k <=j ; k++){if(k %2===0){
arr[k].textStyle ={ color: redcolor[l]}}else{
arr[k].textStyle ={ color: blackcolor[l]}}}}}constdealworddata=(data)=>{let len = data.length
if(len <=8){let i =0,j =0,k =0while(k<len){if( k %2===0){
data[k].textStyle ={ color: redcolor[i]}
i++}else{
data[k].textStyle ={ color: blackcolor[j]}
j++}
k++}}else{let mid = len >>1let leftmid = len >>1let rightmid =(len -1+ mid)>>1iterate(data,0, leftmid,0)iterate(data, leftmid, mid,1)iterate(data, mid, rightmid,2)iterate(data, rightmid, len-1,3)}}
背景图片
const maskImage =newImage()
maskImage.src = ‘’ // 这里是base64编码...
maskImage: maskImage
本文转载自: https://blog.csdn.net/HurryUpp/article/details/123064557
版权归原作者 HurryUpp 所有, 如有侵权,请联系我们删除。
版权归原作者 HurryUpp 所有, 如有侵权,请联系我们删除。