
filter查询
query,根据你的查询条件,去计算文档的匹配度得到一个分数,并且根据分数进行排序,不会做缓存的。
filter,根据你的查询条件去查询文档,不去计算分数,而且filter会对经常被过滤的数据进行缓存。
# filter查询
POST /sms-logs-index/sms-logs-type/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"corpName": "盒马鲜生"
}
},
{
"range": {
"fee": {
"lte": 4
}
}
}
]
}
}
}
// Java实现filter操作
@Test
public void filter() throws IOException {
//1. SearchRequest
SearchRequest request = new SearchRequest(index);
request.types(type);
//2. 查询条件
SearchSourceBuilder builder = new SearchSourceBuilder();
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
boolQuery.filter(QueryBuilders.termQuery("corpName","盒马鲜生"));
boolQuery.filter(QueryBuilders.rangeQuery("fee").lte(5));
builder.query(boolQuery);
request.source(builder);
//3. 执行查询
SearchResponse resp = client.search(request, RequestOptions.DEFAULT);
//4. 输出结果
for (SearchHit hit : resp.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}
高亮查询
高亮查询就是你用户输入的关键字,以一定的特殊样式展示给用户,让用户知道为什么这个结果被检索出来。
高亮展示的数据,本身就是文档中的一个Field,单独将Field以highlight的形式返回给你。
ES提供了一个highlight属性,和query同级别的。
- fragment_size:指定高亮数据展示多少个字符回来。
- pre_tags:指定前缀标签,举个栗子< font color="red" >
- post_tags:指定后缀标签,举个栗子< /font >
- fields:指定哪几个Field以高亮形式返回
**RESTful实现 **
# highlight查询 POST /sms-logs-index/sms-logs-type/_search { "query": { "match": { "smsContent": "盒马" } }, "highlight": { "fields": { "smsContent": {} }, "pre_tags": "<font color='red'>", "post_tags": "</font>", "fragment_size": 10 } }
/ Java实现高亮查询
@Test
public void highLightQuery() throws IOException {
//1. SearchRequest
SearchRequest request = new SearchRequest(index);
request.types(type);
//2. 指定查询条件(高亮)
SearchSourceBuilder builder = new SearchSourceBuilder();
//2.1 指定查询条件
builder.query(QueryBuilders.matchQuery("smsContent","盒马"));
//2.2 指定高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("smsContent",10)
.preTags("<font color='red'>")
.postTags("</font>");
builder.highlighter(highlightBuilder);
request.source(builder);
//3. 执行查询
SearchResponse resp = client.search(request, RequestOptions.DEFAULT);
//4. 获取高亮数据,输出
for (SearchHit hit : resp.getHits().getHits()) {
System.out.println(hit.getHighlightFields().get("smsContent"));
}
}

聚合查询
ES的聚合查询和MySQL的聚合查询类似,ES的聚合查询相比MySQL要强大的多,ES提供的统计数据的方式多种多样。
**下图名字可以随便起 **
# ES聚合查询的RESTful语法
POST /index/type/_search
{
"aggs": {
"名字(agg)": {
"agg_type": {
"属性": "值"
}
}
}
}
去重计数查询
去重计数,即Cardinality,第一步先将返回的文档中的一个指定的field进行去重,统计一共有多少条
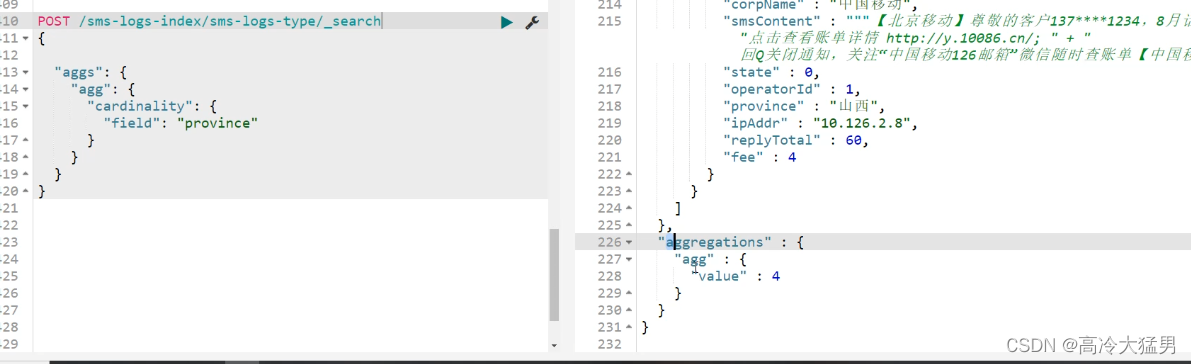
# 去重计数查询 北京 上海 武汉 山西
POST /sms-logs-index/sms-logs-type/_search
{
"aggs": {
"agg": {
"cardinality": {
"field": "province"
}
}
}
}
// Java代码实现去重计数查询
@Test
public void cardinality() throws IOException {
//1. 创建SearchRequest
SearchRequest request = new SearchRequest(index);
request.types(type);
//2. 指定使用的聚合查询方式
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.aggregation(AggregationBuilders.cardinality("agg").field("province"));
request.source(builder);
//3. 执行查询
SearchResponse resp = client.search(request, RequestOptions.DEFAULT);
//4. 获取返回结果
Cardinality agg = resp.getAggregations().get("agg");
long value = agg.getValue();
System.out.println(value);
}

范围统计
统计一定范围内出现的文档个数,比如,针对某一个Field的值在 0
100,100200,200~300之间文档出现的个数分别是多少。范围统计可以针对普通的数值,针对时间类型,针对ip类型都可以做相应的统计。
range,date_range,ip_range
数值统计
# 数值方式范围统计
POST /sms-logs-index/sms-logs-type/_search
{
"aggs": {
"agg": {
"range": {
"field": "fee",
"ranges": [
{
"to": 5
},
{
"from": 5, # from有包含当前值的意思
"to": 10
},
{
"from": 10
}
]
}
}
}
}
# 时间方式范围统计
POST /sms-logs-index/sms-logs-type/_search
{
"aggs": {
"agg": {
"date_range": {
"field": "createDate",
"format": "yyyy",
"ranges": [
{
"to": 2000
},
{
"from": 2000
}
]
}
}
}
}
# ip方式 范围统计
POST /sms-logs-index/sms-logs-type/_search
{
"aggs": {
"agg": {
"ip_range": {
"field": "ipAddr",
"ranges": [
{
"to": "10.126.2.9"
},
{
"from": "10.126.2.9"
}
]
}
}
}
}
from表示包含当前值得意思 上图表示0-5 ,5-10 (包含5不含10),10以上(包含10)
// Java实现数值 范围统计
@Test
public void range() throws IOException {
//1. 创建SearchRequest
SearchRequest request = new SearchRequest(index);
request.types(type);
//2. 指定使用的聚合查询方式
SearchSourceBuilder builder = new SearchSourceBuilder();
//---------------------------------------------
builder.aggregation(AggregationBuilders.range("agg").field("fee")
.addUnboundedTo(5)
.addRange(5,10)
.addUnboundedFrom(10));
//---------------------------------------------
request.source(builder);
//3. 执行查询
SearchResponse resp = client.search(request, RequestOptions.DEFAULT);
//4. 获取返回结果
Range agg = resp.getAggregations().get("agg");
for (Range.Bucket bucket : agg.getBuckets()) {
String key = bucket.getKeyAsString();
Object from = bucket.getFrom();
Object to = bucket.getTo();
long docCount = bucket.getDocCount();
System.out.println(String.format("key:%s,from:%s,to:%s,docCount:%s",key,from,to,docCount));
}
}
统计聚合查询
他可以帮你查询指定Field的最大值,最小值,平均值,平方和等
使用:extended_stats
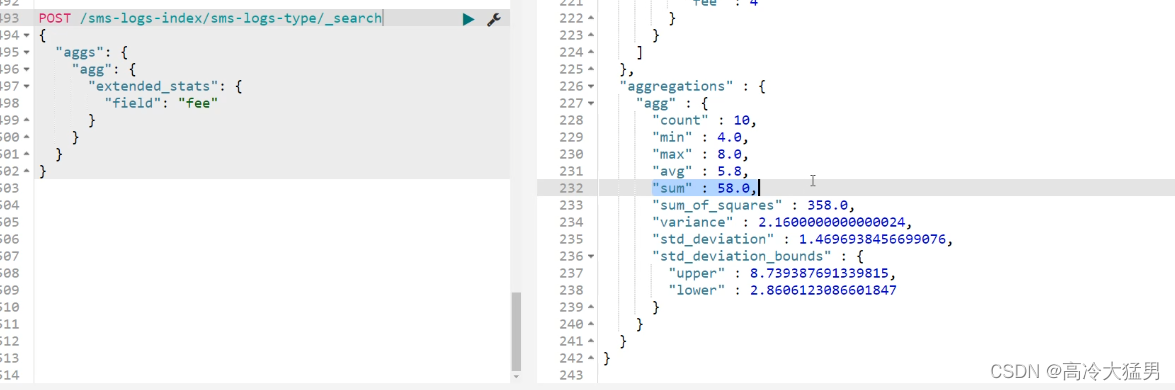
# 统计聚合查询
POST /sms-logs-index/sms-logs-type/_search
{
"aggs": {
"agg": {
"extended_stats": {
"field": "fee"
}
}
}
}
// Java实现统计聚合查询
@Test
public void extendedStats() throws IOException {
//1. 创建SearchRequest
SearchRequest request = new SearchRequest(index);
request.types(type);
//2. 指定使用的聚合查询方式
SearchSourceBuilder builder = new SearchSourceBuilder();
//---------------------------------------------
builder.aggregation(AggregationBuilders.extendedStats("agg").field("fee"));
//---------------------------------------------
request.source(builder);
//3. 执行查询
SearchResponse resp = client.search(request, RequestOptions.DEFAULT);
//4. 获取返回结果
ExtendedStats agg = resp.getAggregations().get("agg");
double max = agg.getMax();
double min = agg.getMin();
System.out.println("fee的最大值为:" + max + ",最小值为:" + min);
}
标签:
elasticsearch
大数据
本文转载自: https://blog.csdn.net/weixin_60934893/article/details/128047230
版权归原作者 高冷大猛男 所有, 如有侵权,请联系我们删除。
版权归原作者 高冷大猛男 所有, 如有侵权,请联系我们删除。