
⭐️前面的话⭐️
本篇文章主要介绍数据库约束,数据表的聚合查询,多表查询,合并查询,难点基本上都集中在多表查询部分,大家要耐心地去看去练习哦。
📒博客主页:未见花闻的博客主页
🎉欢迎关注🔎点赞👍收藏⭐️留言📝
📌本文由未见花闻原创,CSDN首发!
📆首发时间:🌴2022年3月19日🌴
✉️坚持和努力一定能换来诗与远方!
💭参考书籍:📚《MySQL必知必会》,📚《高性能MySQL》
💬参考在线编程网站:🌐牛客网🌐力扣
博主的码云gitee,平常博主写的程序代码都在里面。
博主的github,平常博主写的程序代码都在里面。
🍭作者水平很有限,如果发现错误,一定要及时告知作者哦!感谢感谢!
📌导航小助手📌
温馨提示: 全文共2.9万字,阅读可能需要较长时间。
🌱1.数据库的约束
🌾1.1数据库常用约束
- NOT NULL - 指示某列不能存储 NULL 值。
- UNIQUE - 保证某列的每行必须有唯一的值。
- DEFAULT - 规定没有给列赋值时的默认值。
- PRIMARY KEY - NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
- FOREIGN KEY - 保证一个表中的数据匹配另一个表中的值的参照完整性。
- CHECK - 保证列中的值符合指定的条件。对于MySQL数据库,对CHECK子句进行分析,但是忽略CHECK子句。
🌾1.2NOT NULL约束
该约束使用对象为列,创建数据表的时候使用,可以约束列的值不能为
null
。
语法:
createtable 表名 (变量 数据类型 notnull,...);
栗子:
-- 对id使用not null约束
mysql>createtable student (id intnotnull, name varchar(20));
Query OK,0rows affected (0.01 sec)--id值不能为null ,id默认值为null,所以插入数据时必须对id赋值
mysql>desc student;+-------+-------------+------+-----+---------+-------+| Field |Type|Null|Key|Default| Extra |+-------+-------------+------+-----+---------+-------+| id |int(11)|NO||NULL||| name |varchar(20)| YES ||NULL||+-------+-------------+------+-----+---------+-------+2rowsinset(0.00 sec)-- 不为null的id,没问题
mysql>insertinto student values(1,"张三");
Query OK,1row affected (0.00 sec)-- 为null的id插入失败
mysql>insertinto student values(nul1,"李四");
ERROR 1054(42S22): Unknown column'nul1'in'field list'-- 插入时不给id列赋值,插入失败
mysql>insertinto student (name)values("李四");
ERROR 1364(HY000): Field 'id' doesn't have a defaultvalue
该约束可以同时对多个使用。
-- 如果存在一个表则删除
mysql>droptableifexists student;
Query OK,0rows affected (0.01 sec)-- 对id和name都进行 not null 约束
mysql>createtable student (id intnotnull, name varchar(20)notnull);
Query OK,0rows affected (0.01 sec)-- 查看表结构
mysql>desc student;+-------+-------------+------+-----+---------+-------+| Field |Type|Null|Key|Default| Extra |+-------+-------------+------+-----+---------+-------+| id |int(11)|NO||NULL||| name |varchar(20)|NO||NULL||+-------+-------------+------+-----+---------+-------+2rowsinset(0.00 sec)
🌾1.3UNIQUE约束
该约束使用的对象为列,创建数据表的时候使用,可以约束该列的值不能重复。
语法:
createtable 表名 (变量 数据类型 unique,...);
栗子:
-- 删除原有的student表
mysql>droptableifexists student;
Query OK,0rows affected (0.01 sec)-- 创建student表,并对id和name使用unique约束
mysql>createtable student (id intunique, name varchar(20)unique);
Query OK,0rows affected (0.02 sec)-- 查看表结构
mysql>desc student;+-------+-------------+------+-----+---------+-------+| Field |Type|Null|Key|Default| Extra |+-------+-------------+------+-----+---------+-------+| id |int(11)| YES | UNI |NULL||| name |varchar(20)| YES | UNI |NULL||+-------+-------------+------+-----+---------+-------+2rowsinset(0.00 sec)-- 插入不重复数据
mysql>insertinto student values(1,"张三");
Query OK,1row affected (0.00 sec)-- 插入id或name重复的数据,均失败
mysql>insertinto student values(1,"张三");
ERROR 1062(23000): Duplicate entry '1'forkey'id'
mysql>insertinto student values(2,"张三");
ERROR 1062(23000): Duplicate entry '张三'forkey'name'
mysql>insertinto student values(1,"李四");
ERROR 1062(23000): Duplicate entry '1'forkey'id'
🌾1.4DEFAULT约定默认值
与上面约束使用方法一样,创建表时可使
default 默认值
来给某列设置默认值。
语法:
createtable 表名 (变量 数据类型 default 默认值,...);
栗子:
mysql>droptableifexists student;
Query OK,0rows affected (0.01 sec)
mysql>createtable student (id int, name varchar(20)default"匿名");
Query OK,0rows affected (0.01 sec)
mysql>desc student;+-------+-------------+------+-----+---------+-------+| Field |Type|Null|Key|Default| Extra |+-------+-------------+------+-----+---------+-------+| id |int(11)| YES ||NULL||| name |varchar(20)| YES || 匿名 ||+-------+-------------+------+-----+---------+-------+2rowsinset(0.00 sec)
mysql>insertinto student (id)values(1);
Query OK,1row affected (0.00 sec)
mysql>select*from student;+------+--------+| id | name |+------+--------+|1| 匿名 |+------+--------+1rowinset(0.00 sec)
🌾1.5 PRIMARY KEY约束
该约束叫做主键约束,相当于
not null
和
unique
同时使用的效果,它能约束该列的值不能与其他列相同且不能为
null
,相当于一个身份证标识。
语法:
createtable 表名 (变量 数据类型 primarykey,...);
栗子:
mysql>droptableifexists student;
Query OK,0rows affected (0.01 sec)
mysql>createtable student (id intprimarykey, name varchar(50));
Query OK,0rows affected (0.01 sec)
mysql>desc student;+-------+-------------+------+-----+---------+-------+| Field |Type|Null|Key|Default| Extra |+-------+-------------+------+-----+---------+-------+| id |int(11)|NO| PRI |NULL||| name |varchar(50)| YES ||NULL||+-------+-------------+------+-----+---------+-------+2rowsinset(0.00 sec)
mysql>insertinto student values(1,"张三");
Query OK,1row affected (0.00 sec)
mysql>insertinto student values(2,"李四");
Query OK,1row affected (0.00 sec)
mysql>insertinto student values(2,"王五");
ERROR 1062(23000): Duplicate entry '2'forkey'PRIMARY'
mysql>select*from student;+----+--------+| id | name |+----+--------+|1| 张三 ||2| 李四 |+----+--------+2rowsinset(0.00 sec)
MySQL还支持自增主键,就是使用自增主键约束后,可以不用给这个列赋值,在插入记录时,它会自动从1开始自增(未初始值时),如果前一次插入时给定了一个值,则后续插入会基于该值自增。
语法:
createtable 表名 (变量 数据类型 primarykeyauto_increment,...);
栗子:
mysql>droptableifexists student;
Query OK,0rows affected (0.01 sec)
mysql>createtable student (id intprimarykeyauto_increment, name varchar(20));
Query OK,0rows affected (0.02 sec)
mysql>desc student;+-------+-------------+------+-----+---------+----------------+| Field |Type|Null|Key|Default| Extra |+-------+-------------+------+-----+---------+----------------+| id |int(11)|NO| PRI |NULL|auto_increment|| name |varchar(20)| YES ||NULL||+-------+-------------+------+-----+---------+----------------+2rowsinset(0.00 sec)
mysql>insertinto student values(null,"张三"),(null,"李四"),(null,"王五");
Query OK,3rows affected (0.00 sec)
Records: 3 Duplicates: 0Warnings: 0
mysql>select*from student;+----+--------+| id | name |+----+--------+|1| 张三 ||2| 李四 ||3| 王五 |+----+--------+3rowsinset(0.00 sec)
mysql>insertinto student values(10,"黑大帅"),(null,"灰太狼"),(null,"小灰灰");
Query OK,3rows affected (0.00 sec)
Records: 3 Duplicates: 0Warnings: 0
mysql>select*from student;+----+-----------+| id | name |+----+-----------+|1| 张三 ||2| 李四 ||3| 王五 ||10| 黑大帅 ||11| 灰太狼 ||12| 小灰灰 |+----+-----------+6rowsinset(0.00 sec)
🌾1.6 FOREIGN KEY约束
该约束称为外键约束,是针对与两张表的情况下使用的,比如有一张学生表里面有学号,姓名,班级号,还有一张表是班级表,里面有班级号和班级名,该学生表里面的学生所在班级都能在班级表里面找到,这个时候就需要对学生表做一个外键约束,就能使学生表与班级表联系起来。我们发现学生表是依赖与班级表的,称学生表为子表,班级表为父表。
语法:
--父表已经创建createtable 表名 (变量 数据类型....,foreignkey(子表中的一个变量)references 父表名(父表中的一个变量));
栗子:
-- 创建class表作为student的父表
mysql>createtable class (classId intprimarykeyauto_increment, className varchar(50));
Query OK,0rows affected (0.02 sec)
mysql>desc class;+-----------+-------------+------+-----+---------+----------------+| Field |Type|Null|Key|Default| Extra |+-----------+-------------+------+-----+---------+----------------+| classId |int(11)|NO| PRI |NULL|auto_increment|| className |varchar(50)| YES ||NULL||+-----------+-------------+------+-----+---------+----------------+2rowsinset(0.00 sec)
mysql>insertinto class values(null,"计算机1班"),(null,"软工1班"),(null,"英语1班"),(null,"中文1班"),(null,"机械1班"),(null,"食工1班"),(null,"化学1班"),(null,"电子1班"),(null,"材料1班");
Query OK,9rows affected (0.00 sec)
Records: 9 Duplicates: 0Warnings: 0
mysql>select*from class;+---------+---------------+| classId | className |+---------+---------------+|1| 计算机1班 ||2| 软工1班 ||3| 英语1班 ||4| 中文1班 ||5| 机械1班 ||6| 食工1班 ||7| 化学1班 ||8| 电子1班 ||9| 材料1班 |+---------+---------------+9rowsinset(0.00 sec)-- 添加外键约束创建子表student
mysql>droptableifexists student;
Query OK,0rows affected (0.01 sec)
mysql>createtable student (id intprimarykeyauto_increment, name varchar(20), classId int,foreignkey(classId)references class(classId));
Query OK,0rows affected (0.02 sec)
mysql>desc student;+---------+-------------+------+-----+---------+----------------+| Field |Type|Null|Key|Default| Extra |+---------+-------------+------+-----+---------+----------------+| id |int(11)|NO| PRI |NULL|auto_increment|| name |varchar(20)| YES ||NULL||| classId |int(11)| YES | MUL |NULL||+---------+-------------+------+-----+---------+----------------+3rowsinset(0.00 sec)-- 添加学生
mysql>insertinto student (name, classId)values("喜羊羊",1),("美羊羊",4),("沸羊羊",5),("暖羊羊",3),("懒羊羊",6),("慢羊羊",9),("灰太狼",8),("小灰灰",7),("黑大帅",8);
Query OK,9rows affected (0.01 sec)
Records: 9 Duplicates: 0Warnings: 0
mysql>select*from student;+----+-----------+---------+| id | name | classId |+----+-----------+---------+|1| 喜羊羊 |1||2| 美羊羊 |4||3| 沸羊羊 |5||4| 暖羊羊 |3||5| 懒羊羊 |6||6| 慢羊羊 |9||7| 灰太狼 |8||8| 小灰灰 |7||9| 黑大帅 |8|+----+-----------+---------+9rowsinset(0.00 sec)-- 添加班级表中不存在的班级会插入失败
mysql>insertinto student (name, classId)values("光头强",20);
ERROR 1452(23000): Cannot addorupdate a child row: a foreignkeyconstraint fails (`test`.`student`,CONSTRAINT`student_ibfk_1`FOREIGNKEY(`classId`)REFERENCES`class`(`classId`))
使用外键约束的数据表,依赖于其他一个表,这个被依赖的表称为父表,被约束的表被称为子表,当在子表插入记录时,必须在父表中存在某一对应关系才能插入。
除了插入记录,修改子表中的记录也有可能失败,就如上面的学生表和班级表,如果将黑大帅的班级id修改为10,但是这个id在班级表是不存在的,所以会发生修改失败的情况。
mysql>update student set classId =10where name ="黑大帅";
ERROR 1452(23000): Cannot addorupdate a child row: a foreignkeyconstraint fails (`test`.`student`,CONSTRAINT`student_ibfk_1`FOREIGNKEY(`classId`)REFERENCES`class`(`classId`))
同样,外键约束不仅约束子表,父表也是受约束的,当你试图将班级表中的id修改或删除,且在学生表中存在班级为此id的学生,那么你会操作失败。
mysql>update class set classId =10where classId =1;
ERROR 1451(23000): Cannot deleteorupdate a parent row: a foreignkeyconstraint fails (`test`.`student`,CONSTRAINT`student_ibfk_1`FOREIGNKEY(`classId`)REFERENCES`class`(`classId`))
当然如果你试图删除或修改父表中的一个id所对应的记录,只要学生表中不存在班级为此id的学生,就可以删除。比如学生表中没有软工1班(对应id为2)的学生,那么这个记录在班级表可以修改或者删除。
mysql>deletefrom class where classId=2;
Query OK,1row affected (0.00 sec)
外键约束的工作原理:
在子表插入新的记录时,会根据对应的值先在父表查询,查询到了目标值之后才能完成子表的插入操作。
对于父表的查询操作,被依赖的这一列必须要要有索引(索引能加快查询效率),如果使用
primary key
或者
unique
约束该列,则该列会自动创建索引。所以上面的学生表与班级表的例子,虽然我们没有主动对父表中的
classId
列创建索引,但是该列被主键约束,自动创建了索引。
🌱2.数据表的设计
🌾2.1一对一
以教务系统为例,学生表有学号姓名班级等属性,教务系统上的用户表有账号密码等属性,每一个学生有且仅有一个教务系统的账号,并且教务系统上的一个账号仅对应一个学生,像这种关系就是一对一的关系。
那么如何在数据库表示这种一对一的关系呢?
方案1:把学生表与用户表放在一个表中一一对应。
方案2:学生表中增加一列,存放学生在教务系统上的账号,在教务系统用户表增加一列,存放学生的学号。
🌾2.2一对多
还是以教务系统为例,如学生与班级之间的关系就是一个一对多的关系,一个学生原则上只能在一个班级中,一个班级考研英语容纳多名学生。
那么如何在数据库表示这种一对多的关系呢?
方案1:在班级表中增加一列,存放一个班里面所有学生的学号。但是MySQL不支持这种方案,因为SQL中没有类似于数组的类型。
方案2:在一个学生表中增加一列,存放学生所在的班级。
🌾2.3多对多
还是以教务系统为例,如学生与课程之间的关系就是一个典型的多对多的关系,一个学生可以学习多门课程,一门课程中有多名学生学习。
那么如何在数据库表示这种多对多的关系呢?
只有一种方案:建立一个关联表,来关联学生表和课程表,这个关联表中有两列,一列用来存放学生学号,另一列存放课程编号,这样两表可以通过这一个关联表来实现多对多的一个关系。
🌱3.数据表的查询操作(进阶)
🌾3.1将一个表中的数据插入到另一个表
SQL支持将表A的数据插入到表B,但是前提的满足插入的时候需满足列与列之间的数据类型以及顺序要相同。
语法:
insertinto B select 对应与表B的列集合 from A;
栗子:
mysql>createtable A (id int, name varchar(20));
Query OK,0rows affected (0.02 sec)
mysql>insertinto A values(1,"张三疯"),(2,"夏洛特"),(3,"熊大"),(4,"刻晴"),(5,"急先锋");
Query OK,5rows affected (0.01 sec)
Records: 5 Duplicates: 0Warnings: 0
mysql>select*from A;+------+-----------+| id | name |+------+-----------+|1| 张三疯 ||2| 夏洛特 ||3| 熊大 ||4| 刻晴 ||5| 急先锋 |+------+-----------+5rowsinset(0.00 sec)
mysql>createtable B (id int, name varchar(20));
Query OK,0rows affected (0.02 sec)-- A与B表数据类型顺序对应,不需调整
mysql>insertinto B select*from A;
Query OK,5rows affected (0.01 sec)
Records: 5 Duplicates: 0Warnings: 0
mysql>select*from B;+------+-----------+| id | name |+------+-----------+|1| 张三疯 ||2| 夏洛特 ||3| 熊大 ||4| 刻晴 ||5| 急先锋 |+------+-----------+5rowsinset(0.00 sec)-- A与C表数据类型顺序不对应,需要调整
mysql>createtable C (name varchar(20), id int);
Query OK,0rows affected (0.01 sec)
mysql>insertinto C select name, id from A;
Query OK,5rows affected (0.00 sec)
Records: 5 Duplicates: 0Warnings: 0
mysql>select*from C;+-----------+------+| name | id |+-----------+------+| 张三疯 |1|| 夏洛特 |2|| 熊大 |3|| 刻晴 |4|| 急先锋 |5|+-----------+------+5rowsinset(0.00 sec)
将一个表A数据拷贝到另外一个表B本质是先查询表A的数据,查询出来的数据需要与表B对应,表A中查询结果为一临时表,然后再将这个临时表插入到表B。
🌾3.2聚合查询
🌼3.2.1聚合查询函数
函数说明count(列名或表达式)返回查询到的数据的个数sum(列名或表达式)返回查询到的数据的和avg(列名或表达式)返回查询到的数据的平均值max(列名或表达式)返回查询到的数据的最大值min(列名或表达式)返回查询到的数据的最小值
对于上面的聚合函数可以在列名(表达式)前加入一个关键字
distinct
可以实现对查询到的数据去重后,再进行计算。
我们来对什么的聚合函数做一些演示,首先我们来创建一个表:
createtable exam_score(id int, name varchar(50), chinese double(4,1), math double(4,1),english double(4,1), computer double(4,1));insertinto exam_score values(1,'美羊羊',99.5,90.5,98,82),->(2,'懒羊羊',58.5,32.5,44,66.5),->(3,'喜羊羊',92,98,88,100),->(4,'沸羊羊',78,72,74.5,81),->(5,'暖羊羊',90,91,98,76),->(6,'灰太狼',33,91,32,98.5),->(7,'小灰灰',81,82,78,88),->(8,'神秘人',null,null,null,null);
表格数据如下:
+------+-----------+---------+------+---------+----------+| id | name | chinese | math | english | computer |+------+-----------+---------+------+---------+----------+|1| 美羊羊 |99.5|90.5|98.0|82.0||2| 懒羊羊 |58.5|32.5|44.0|66.5||3| 喜羊羊 |92.0|98.0|92.0|100.0||4| 沸羊羊 |78.0|72.0|74.5|81.0||5| 暖羊羊 |90.0|91.0|98.0|76.0||6| 灰太狼 |33.0|91.0|32.0|98.5||7| 小灰灰 |81.0|82.0|78.0|88.0||8| 神秘人 |NULL|NULL|NULL|NULL|+------+-----------+---------+------+---------+----------+
首先我们来使用count函数,计算这个数据表有多少行,统计数据表行数可以对
*
的查询结果计数。
-- 一共8行
mysql>selectcount(*)from exam_score;+----------+|count(*)|+----------+|8|+----------+1rowinset(0.00 sec)-- 当然也可以对输出的表名改名
mysql>selectcount(*)as"全表行数"from exam_score;+--------------+| 全表行数 |+--------------+|8|+--------------+1rowinset(0.00 sec)
还有一个疑问,count函数能不能对
null
计数?我们来计算一下语文成绩的个数。
mysql>selectcount(chinese)as"语文成绩个数"from exam_score;+--------------------+| 语文成绩个数 |+--------------------+|7|+--------------------+1rowinset(0.00 sec)
所以说
null
值count函数不会计算,其实包括其他的聚合函数也不会计算
null
。
例如sum函数,对语文成绩进行求和。
-- 包含null结果
mysql>selectsum(chinese)as"语文成绩总分"from exam_score;+--------------------+| 语文成绩总分 |+--------------------+|532.0|+--------------------+1rowinset(0.00 sec)-- 删除null的记录
mysql>deletefrom exam_score where name="神秘人";
Query OK,1row affected (0.01 sec)
mysql>selectsum(chinese)as"语文成绩总分"from exam_score;+--------------------+| 语文成绩总分 |+--------------------+|532.0|+--------------------+
最后,聚合函数不能直接嵌套使用。
mysql>selectcount(count(math))from exam_score;
ERROR 1111(HY000): Invalid useofgroupfunction
聚合函数针对的是行与行之间的计算,之前的表达式求值是列与列之间的计算。
🌼3.2.2分组查询
我们可以通过
group by 列名
关键字对行进行分组,按照列的值,将值相同的分成一组。
分组查询语法:
select 列,...from 表名 (条件表达式)groupby 列名;
其中条件表达式是类似
where
,
limit
的语句,可以省略。
栗子:
我们来建一个不同职位的薪水表。
-- 建表
mysql>createtable emp (
id intprimarykeyauto_increment,
name varchar(20)notnull,
role varchar(20)notnull,
salary numeric(11,2));
Query OK,0rows affected (0.03 sec)-- 插入数据
mysql>insertinto emp (name, role, salary)values("幕后老板","董事长",666666.66),("诸葛亮","策划",12000),("柯南","策划",12800),("梅毛冰","策划",11000),("可莉","游戏角色",5000),("刻晴","游戏角色",5600),("胡桃","游戏角色",6666),("八重神子","游戏角色",4888),("枫原万叶","游戏角色",5200),("心海","游戏角色",6000),("打工人","开发工程师",20000),("苦逼加班人","开发工程师",20000),("996专业户","开发工程师",21000),("搬砖大师","开发工程师",20888);-- 查看数据
mysql>select*from emp;+----+-----------------+-----------------+-----------+| id | name | role | salary |+----+-----------------+-----------------+-----------+|1| 幕后老板 | 董事长 |666666.66||2| 诸葛亮 | 策划 |12000.00||3| 柯南 | 策划 |12800.00||4| 梅毛冰 | 策划 |11000.00||5| 可莉 | 游戏角色 |5000.00||6| 刻晴 | 游戏角色 |5600.00||7| 胡桃 | 游戏角色 |6666.00||8| 八重神子 | 游戏角色 |4888.00||9| 枫原万叶 | 游戏角色 |5200.00||10| 心海 | 游戏角色 |6000.00||11| 打工人 | 开发工程师 |20000.00||12| 苦逼加班人 | 开发工程师 |20000.00||13|996专业户 | 开发工程师 |21000.00||14| 搬砖大师 | 开发工程师 |20888.00|+----+-----------------+-----------------+-----------+14rowsinset(0.00 sec)
我们现在要查询每种岗位员工的薪水的平均值,最高值,最低值。
mysql>select role,avg(salary),max(salary),min(salary)from emp groupby role;+-----------------+---------------+-------------+-------------+| role |avg(salary)|max(salary)|min(salary)|+-----------------+---------------+-------------+-------------+| 开发工程师 |20472.000000|21000.00|20000.00|| 游戏角色 |5559.000000|6666.00|4888.00|| 策划 |11933.333333|12800.00|11000.00|| 董事长 |666666.660000|666666.66|666666.66|+-----------------+---------------+-------------+-------------+4rowsinset(0.00 sec)-- 可以为查询的临时表更名
mysql>select role,avg(salary)as"平均值",max(salary)as"最高薪资",min(salary)as"最低薪资"from emp groupby role;+-----------------+---------------+--------------+--------------+| role | 平均值 | 最高薪资 | 最低薪资 |+-----------------+---------------+--------------+--------------+| 开发工程师 |20472.000000|21000.00|20000.00|| 游戏角色 |5559.000000|6666.00|4888.00|| 策划 |11933.333333|12800.00|11000.00|| 董事长 |666666.660000|666666.66|666666.66|+-----------------+---------------+--------------+--------------+4rowsinset(0.00 sec)
如果数据中存在
null
,那么聚合函数
avg
,
max
,
min
不会纳入计算。
🌼3.2.3having
针对
group by
分组后的数据,需要对分组结果再进行条件过滤时,不能使用
where
条件语句进行过滤,只能使用
having
进行数据过滤。
语法格式与
where
差不多,只是
where
语句紧跟在表名后,而
having
跟在
group by
后。
语法:
-- having 用法select 聚合函数(或者列),...from 表名 groupby 列 having 条件;-- where 用法select 聚合函数(或者列),...from 表名 where 条件 groupby 列;
栗子:董事长的薪水太高了,算平均工资时不要把董事长的记录加进去(不是从服务器表中删除)
-- where筛选
mysql>select role,avg(salary)as"平均薪水"from emp where role !="董事长"groupby role;+-----------------+--------------+| role | 平均薪水 |+-----------------+--------------+| 开发工程师 |20472.000000|| 游戏角色 |5559.000000|| 策划 |11933.333333|+-----------------+--------------+3rowsinset(0.00 sec)-- having 筛选
mysql>select role,avg(salary)as"平均薪水"from emp groupby role having role !="董事长";+-----------------+--------------+| role | 平均薪水 |+-----------------+--------------+| 开发工程师 |20472.000000|| 游戏角色 |5559.000000|| 策划 |11933.333333|+-----------------+--------------+3rowsinset(0.00 sec)
🌾3.3联合(多表)查询
🌼3.3.1笛卡尔积
在数学中,两个集合
X
X
X和
Y
Y
Y的笛卡儿积(Cartesian product),又称直积,表示为
X
×
Y
X × Y
X×Y,是其第一个对象是X的成员而第二个对象是Y的一个成员的所有可能的有序对。
例如,设集合
A
=
a
,
b
A={a,b}
A=a,b,集合
B
=
0
,
1
,
2
B={0,1,2}
B=0,1,2,则两个集合的笛卡尔积为
(
a
,
0
)
,
(
a
,
1
)
,
(
a
,
2
)
,
(
b
,
0
)
,
(
b
,
1
)
,
(
b
,
2
)
{(a,0),(a,1),(a,2),(b,0),(b,1), (b,2)}
(a,0),(a,1),(a,2),(b,0),(b,1),(b,2)。
联合查询也称为多表查询,该查询基于笛卡尔积将多个表合并,再对这个合并表进行有效数据筛选。
笛卡尔积查询语法:
select 列,...from 表名1, 表名2;
栗子:假设我们有下面两张表,请把这两张表进行笛卡尔积。
-- 表1 stu 一共9个学生+----+-----------+---------+| id | name | classId |+----+-----------+---------+|1| 喜羊羊 |1||2| 美羊羊 |4||3| 沸羊羊 |5||4| 暖羊羊 |3||5| 懒羊羊 |6||6| 慢羊羊 |9||7| 灰太狼 |8||8| 小灰灰 |7||9| 黑大帅 |8|+----+-----------+---------+-- 表2 class 没有id为2的班级 一共8个班级+---------+---------------+| classId | className |+---------+---------------+|1| 计算机1班 ||3| 英语1班 ||4| 中文1班 ||5| 机械1班 ||6| 食工1班 ||7| 化学1班 ||8| 电子1班 ||9| 材料1班 |+---------+---------------+-- 笛卡尔积结果 一共 9x8=72 条记录
mysql>select*from stu, class;+----+-----------+---------+---------+---------------+| id | name | classId | classId | className |+----+-----------+---------+---------+---------------+|1| 喜羊羊 |1|1| 计算机1班 ||1| 喜羊羊 |1|3| 英语1班 ||1| 喜羊羊 |1|4| 中文1班 ||1| 喜羊羊 |1|5| 机械1班 ||1| 喜羊羊 |1|6| 食工1班 ||1| 喜羊羊 |1|7| 化学1班 ||1| 喜羊羊 |1|8| 电子1班 ||1| 喜羊羊 |1|9| 材料1班 ||2| 美羊羊 |4|1| 计算机1班 ||2| 美羊羊 |4|3| 英语1班 ||2| 美羊羊 |4|4| 中文1班 ||2| 美羊羊 |4|5| 机械1班 ||2| 美羊羊 |4|6| 食工1班 ||2| 美羊羊 |4|7| 化学1班 ||2| 美羊羊 |4|8| 电子1班 ||2| 美羊羊 |4|9| 材料1班 ||3| 沸羊羊 |5|1| 计算机1班 ||3| 沸羊羊 |5|3| 英语1班 ||3| 沸羊羊 |5|4| 中文1班 ||3| 沸羊羊 |5|5| 机械1班 ||3| 沸羊羊 |5|6| 食工1班 ||3| 沸羊羊 |5|7| 化学1班 ||3| 沸羊羊 |5|8| 电子1班 ||3| 沸羊羊 |5|9| 材料1班 ||4| 暖羊羊 |3|1| 计算机1班 ||4| 暖羊羊 |3|3| 英语1班 ||4| 暖羊羊 |3|4| 中文1班 ||4| 暖羊羊 |3|5| 机械1班 ||4| 暖羊羊 |3|6| 食工1班 ||4| 暖羊羊 |3|7| 化学1班 ||4| 暖羊羊 |3|8| 电子1班 ||4| 暖羊羊 |3|9| 材料1班 ||5| 懒羊羊 |6|1| 计算机1班 ||5| 懒羊羊 |6|3| 英语1班 ||5| 懒羊羊 |6|4| 中文1班 ||5| 懒羊羊 |6|5| 机械1班 ||5| 懒羊羊 |6|6| 食工1班 ||5| 懒羊羊 |6|7| 化学1班 ||5| 懒羊羊 |6|8| 电子1班 ||5| 懒羊羊 |6|9| 材料1班 ||6| 慢羊羊 |9|1| 计算机1班 ||6| 慢羊羊 |9|3| 英语1班 ||6| 慢羊羊 |9|4| 中文1班 ||6| 慢羊羊 |9|5| 机械1班 ||6| 慢羊羊 |9|6| 食工1班 ||6| 慢羊羊 |9|7| 化学1班 ||6| 慢羊羊 |9|8| 电子1班 ||6| 慢羊羊 |9|9| 材料1班 ||7| 灰太狼 |8|1| 计算机1班 ||7| 灰太狼 |8|3| 英语1班 ||7| 灰太狼 |8|4| 中文1班 ||7| 灰太狼 |8|5| 机械1班 ||7| 灰太狼 |8|6| 食工1班 ||7| 灰太狼 |8|7| 化学1班 ||7| 灰太狼 |8|8| 电子1班 ||7| 灰太狼 |8|9| 材料1班 ||8| 小灰灰 |7|1| 计算机1班 ||8| 小灰灰 |7|3| 英语1班 ||8| 小灰灰 |7|4| 中文1班 ||8| 小灰灰 |7|5| 机械1班 ||8| 小灰灰 |7|6| 食工1班 ||8| 小灰灰 |7|7| 化学1班 ||8| 小灰灰 |7|8| 电子1班 ||8| 小灰灰 |7|9| 材料1班 ||9| 黑大帅 |8|1| 计算机1班 ||9| 黑大帅 |8|3| 英语1班 ||9| 黑大帅 |8|4| 中文1班 ||9| 黑大帅 |8|5| 机械1班 ||9| 黑大帅 |8|6| 食工1班 ||9| 黑大帅 |8|7| 化学1班 ||9| 黑大帅 |8|8| 电子1班 ||9| 黑大帅 |8|9| 材料1班 |+----+-----------+---------+---------+---------------+72rowsinset(0.00 sec)
对n条记录的表A和m条记录的表B进行笛卡尔积,一共会产生
n*m
条记录,所以这个操作很危险,因为实际工作时的表数据量非常大,进行笛卡尔积产生的记录就会更大,因此工作中很少使用,由于多表查询是基于笛卡尔积,因此多表查询操作也是危险的。
得到两表的笛卡尔积后,有大量的记录都是无效的,需要进行筛选,对于上面的这一个栗子,两表的
classId
相等的数据是有效的,我们可以通过条件查询来筛选出有效的数据,但是这两张表中都有
classId
这一列,当进行表合并时,存在同名列的情况,我们可以使用
表名.列名
的形式访问对应表中的列。
-- 筛选有效数据
mysql>select id, name, className from stu, class where stu.classId=class.classId;+----+-----------+---------------+| id | name | className |+----+-----------+---------------+|1| 喜羊羊 | 计算机1班 ||4| 暖羊羊 | 英语1班 ||2| 美羊羊 | 中文1班 ||3| 沸羊羊 | 机械1班 ||5| 懒羊羊 | 食工1班 ||8| 小灰灰 | 化学1班 ||7| 灰太狼 | 电子1班 ||9| 黑大帅 | 电子1班 ||6| 慢羊羊 | 材料1班 |+----+-----------+---------------+
我们来创建几个表来模拟不同班级不同学生不同课程的学生成绩信息:
droptableifexists classes;droptableifexists student;droptableifexists course;droptableifexists score;createtable classes (id intprimarykeyauto_increment, name varchar(20),`desc`varchar(100));createtable student (id intprimarykeyauto_increment, sn varchar(20), name varchar(20), email varchar(20),
classes_id int);createtable course(id intprimarykeyauto_increment, name varchar(20));createtable score(score decimal(3,1), student_id int, course_id int);insertinto classes(name,`desc`)values('计算机系2020级1班','学习了计算机原理、C和Java语言、数据结构和算法'),('中文系2020级3班','学习了中国传统文学'),('自动化2020级5班','学习了机械自动化'),('数学系2020级2班','学习了数学分析'),('化学系2020级4班','学习了有机化学,无机化学,物理化学'),('生物系2020级6班','学习了生物学');insertinto student(sn, name, email, classes_id)values('2020001','喜羊羊','[email protected]',1),('2020002','美羊羊','[email protected]',1),('2020003','沸羊羊','[email protected]',1),('2020004','懒羊羊','[email protected]',2),('2020005','花羊羊',null,2),('2020006','慢羊羊','[email protected]',6),('2020007','小灰灰',null,2),('2020008','希儿','[email protected]',2),('2020009','布洛尼亚','[email protected]',3),('2020010','光头强','[email protected]',3),('2020011','黑大帅','[email protected]',3),('2020012','开心超人','[email protected]',4),('2020013','刻晴','[email protected]',4),('2020014','可莉','[email protected]',5),('2020015','万叶','[email protected]',5),('2020016','胡桃','[email protected]',6);insertinto course(name)values('Java'),('中国传统文化'),('计算机原理'),('汉语言文学'),('高等数学'),('英语'),('大学物理'),('有机化学'),('生物学'),('数学分析'),('无机化学'),('机械制图');insertinto score(score, student_id, course_id)values-- 喜羊羊(90.5,1,1),(98.5,1,3),(93,1,5),(88,1,6),-- 美羊羊(88,2,1),(78.5,2,3),(94.5,2,5),(98,2,6),-- 沸羊羊(63,3,1),(68,3,3),(79,3,5),-- 懒羊羊(67,4,2),(23,4,4),(72,4,6),-- 花羊羊(81,5,2),(90,5,6),-- 慢羊羊(87,6,7),(90,6,9),(89,6,5),-- 小灰灰(80,7,2),(92,7,6),-- 希儿(89,8,2),(78,8,6),-- 布洛尼亚(82,9,7),(98,9,12),-- 光头强(70,10,7),(81,10,12),-- 黑大帅(88,11,1),(90,11,5),(72,11,12),-- 开心超人(61,12,6),(87,12,10),-- 刻晴(90,13,2),(88,13,10),-- 可莉(58,14,5),(72,14,8),(78,14,11),-- 万叶(90,15,5),(82,15,8),(91,15,11),-- 胡桃(99,16,2),(73,16,5),(89,16,9);
一共有四张表,
classes
为班级表,
student
为学生表,
course
表为课程表,
score
为成绩表,其中学生与班级的关系是一对多,学生与课程之间的关系是多对多。
mysql>select*from classes;+----+-------------------------+-------------------------------------------------------------------+| id | name |desc|+----+-------------------------+-------------------------------------------------------------------+|1| 计算机系2020级1班 | 学习了计算机原理、C和Java语言、数据结构和算法 ||2| 中文系2020级3班 | 学习了中国传统文学 ||3| 自动化2020级5班 | 学习了机械自动化 ||4| 数学系2020级2班 | 学习了数学分析 ||5| 化学系2020级4班 | 学习了有机化学,无机化学,物理化学 ||6| 生物系2020级6班 | 学习了生物学 |+----+-------------------------+-------------------------------------------------------------------+6rowsinset(0.00 sec)
mysql>select*from student;+----+---------+--------------+-------------------+------------+| id | sn | name | email | classes_id |+----+---------+--------------+-------------------+------------+|1|2020001| 喜羊羊 | [email protected]|1||2|2020002| 美羊羊 | [email protected]|1||3|2020003| 沸羊羊 | [email protected]|1||4|2020004| 懒羊羊 | [email protected]|2||5|2020005| 花羊羊 |NULL|2||6|2020006| 慢羊羊 | [email protected]|6||7|2020007| 小灰灰 |NULL|2||8|2020008| 希儿 | [email protected]|2||9|2020009| 布洛尼亚 | [email protected]|3||10|2020010| 光头强 | [email protected]|3||11|2020011| 黑大帅 | [email protected]|3||12|2020012| 开心超人 | [email protected]|4||13|2020013| 刻晴 | [email protected]|4||14|2020014| 可莉 | [email protected]|5||15|2020015| 万叶 | [email protected]|5||16|2020016| 胡桃 | [email protected]|6|+----+---------+--------------+-------------------+------------+16rowsinset(0.00 sec)
mysql>select*from course;+----+--------------------+| id | name |+----+--------------------+|1| Java ||2| 中国传统文化 ||3| 计算机原理 ||4| 汉语言文学 ||5| 高等数学 ||6| 英语 ||7| 大学物理 ||8| 有机化学 ||9| 生物学 ||10| 数学分析 ||11| 无机化学 ||12| 机械制图 |+----+--------------------+12rowsinset(0.00 sec)
mysql>select*from score;+-------+------------+-----------+| score | student_id | course_id |+-------+------------+-----------+|90.5|1|1||98.5|1|3||93.0|1|5||88.0|1|6||88.0|2|1||78.5|2|3||94.5|2|5||98.0|2|6||63.0|3|1||68.0|3|3||79.0|3|5||67.0|4|2||23.0|4|4||72.0|4|6||81.0|5|2||90.0|5|6||87.0|6|7||90.0|6|9||89.0|6|5||80.0|7|2||92.0|7|6||89.0|8|2||78.0|8|6||82.0|9|7||98.0|9|12||70.0|10|7||81.0|10|12||88.0|11|1||90.0|11|5||72.0|11|12||61.0|12|6||87.0|12|10||90.0|13|2||88.0|13|10||58.0|14|5||72.0|14|8||78.0|14|11||90.0|15|5||82.0|15|8||91.0|15|11||99.0|16|2||73.0|16|5||89.0|16|9|+-------+------------+-----------+43rowsinset(0.00 sec)
我们根据这几张表来说明如何进行多表查询,其中多表查询需要对多个表进行连接,连接的常用方式有内连接,左外连接,右外连接,全外连接(MySQL不支持),如果多表之间的数据均有对应,内外连接没有区别,如果多表之间的记录没有全部对应,内连接只会显示多表对应的数据集合,左外连接以左表为主,右外连接以右表连接为主。
多表查询的主要步骤为:
- 将多个表笛卡尔积。
- 筛选有效信息。
- 根据需求慢慢使查询结果达到预期。
🌼3.3.2内连接
格式语法:
select 字段 from 表1, 表2,...where 条件;select 字段 from 表1innerjoin 表2on 条件 ...;
其中
inner
可以省略。
内连接查询的数据记录如下图涂色部分: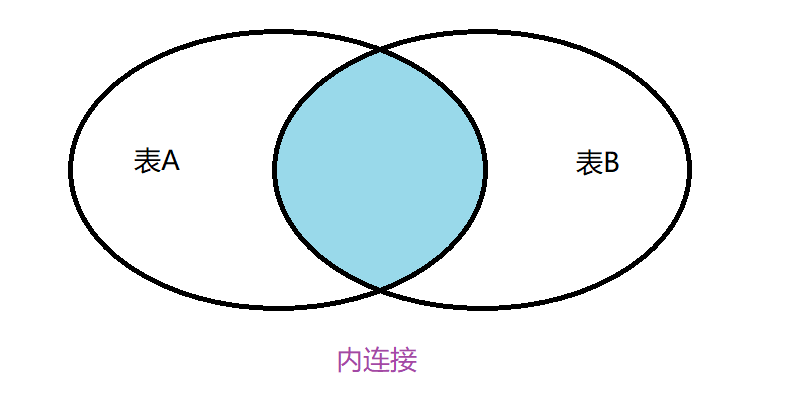
栗子:查询“喜羊羊”同学的成绩列表,无需显示科目。
首先要知道喜羊羊的成绩,那么必须得查询到喜羊羊的个人信息,除此之外,还得从分数表获取成绩,所以需要对学生表和分数表进行笛卡尔积。对上面所举例的学生表和成绩表进行笛卡尔积,一共会产生16*43条数据。
然后我们需要对这些数据进行筛选,首先学生姓名必须是喜羊羊,学生表中的学生id要与成绩表中学生id相同。
mysql>select*from student, score where student.name="喜羊羊"and student.id=score.student_id;+----+---------+-----------+-------------+------------+-------+------------+-----------+| id | sn | name | email | classes_id | score | student_id | course_id |+----+---------+-----------+-------------+------------+-------+------------+-----------+|1|2020001| 喜羊羊 | [email protected]|1|90.5|1|1||1|2020001| 喜羊羊 | [email protected]|1|98.5|1|3||1|2020001| 喜羊羊 | [email protected]|1|93.0|1|5||1|2020001| 喜羊羊 | [email protected]|1|88.0|1|6|+----+---------+-----------+-------------+------------+-------+------------+-----------+4rowsinset(0.00 sec)-- 只保留姓名,成绩,课程编号即可
mysql>select name, score, course_id from student, score where name="喜羊羊"and student.id=score.student_id;+-----------+-------+-----------+| name | score | course_id |+-----------+-------+-----------+| 喜羊羊 |90.5|1|| 喜羊羊 |98.5|3|| 喜羊羊 |93.0|5|| 喜羊羊 |88.0|6|+-----------+-------+-----------+4rowsinset(0.00 sec)
再来一个栗子:查询所有同学的总成绩和个人信息。首先肯定是需要对学生表和成绩表进行笛卡尔积并筛选出有效数据,得到这些数据后,我们需要查询每位同学的总分,每位同学的分数是分布在多行的,所以需要使用分组聚合查询,整体思路就是先得到所有同学的有效成绩,再利用聚合查询将每个同学的成绩汇总。至于分组,我们可以按照
id
分组也可以按照
name
分组进行聚合查询。
mysql>select name,sum(score)from student, score where id=student_id groupby id;+--------------+------------+| name |sum(score)|+--------------+------------+| 喜羊羊 |370.0|| 美羊羊 |359.0|| 沸羊羊 |210.0|| 懒羊羊 |162.0|| 花羊羊 |171.0|| 慢羊羊 |266.0|| 小灰灰 |172.0|| 希儿 |167.0|| 布洛尼亚 |180.0|| 光头强 |151.0|| 黑大帅 |250.0|| 开心超人 |148.0|| 刻晴 |178.0|| 可莉 |208.0|| 万叶 |263.0|| 胡桃 |261.0|+--------------+------------+16rowsinset(0.00 sec)
趁热打铁,继续加大难度,现在需要查询每位同学的成绩,个人信息以及需要将成绩具体对应到哪一门课程。这个问题,我们需要将学生表,分数表,课程表依次进行笛卡尔积运算并筛选出有效的信息。
mysql>select student.name as"姓名", course.name as"课程科目", score as"成绩"from student, score, course where student.id=score.student_id and score.course_id=course.id;+--------------+--------------------+--------+| 姓名 | 课程科目 | 成绩 |+--------------+--------------------+--------+| 喜羊羊 | Java |90.5|| 喜羊羊 | 计算机原理 |98.5|| 喜羊羊 | 高等数学 |93.0|| 喜羊羊 | 英语 |88.0|| 美羊羊 | Java |88.0|| 美羊羊 | 计算机原理 |78.5|| 美羊羊 | 高等数学 |94.5|| 美羊羊 | 英语 |98.0|| 沸羊羊 | Java |63.0|| 沸羊羊 | 计算机原理 |68.0|| 沸羊羊 | 高等数学 |79.0|| 懒羊羊 | 中国传统文化 |67.0|| 懒羊羊 | 汉语言文学 |23.0|| 懒羊羊 | 英语 |72.0|| 花羊羊 | 中国传统文化 |81.0|| 花羊羊 | 英语 |90.0|| 慢羊羊 | 大学物理 |87.0|| 慢羊羊 | 生物学 |90.0|| 慢羊羊 | 高等数学 |89.0|| 小灰灰 | 中国传统文化 |80.0|| 小灰灰 | 英语 |92.0|| 希儿 | 中国传统文化 |89.0|| 希儿 | 英语 |78.0|| 布洛尼亚 | 大学物理 |82.0|| 布洛尼亚 | 机械制图 |98.0|| 光头强 | 大学物理 |70.0|| 光头强 | 机械制图 |81.0|| 黑大帅 | Java |88.0|| 黑大帅 | 高等数学 |90.0|| 黑大帅 | 机械制图 |72.0|| 开心超人 | 英语 |61.0|| 开心超人 | 数学分析 |87.0|| 刻晴 | 中国传统文化 |90.0|| 刻晴 | 数学分析 |88.0|| 可莉 | 高等数学 |58.0|| 可莉 | 有机化学 |72.0|| 可莉 | 无机化学 |78.0|| 万叶 | 高等数学 |90.0|| 万叶 | 有机化学 |82.0|| 万叶 | 无机化学 |91.0|| 胡桃 | 中国传统文化 |99.0|| 胡桃 | 高等数学 |73.0|| 胡桃 | 生物学 |89.0|+--------------+--------------------+--------+43rowsinset(0.00 sec)
使用
join
语句也是可以的:
select
student.name as"姓名", course.name as"课程科目", score as"成绩"from
student join score on student.id=score.student_id join course on score.course_id=course.id;
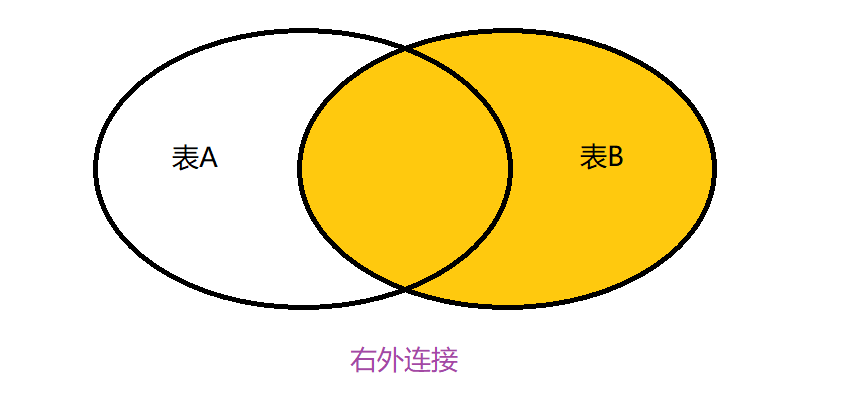
🌼3.3.3外连接
外连接分为左外连接,右外连接,全外连接(SQL不支持),其中左外连接是以左表为主,右外连接以右表为主。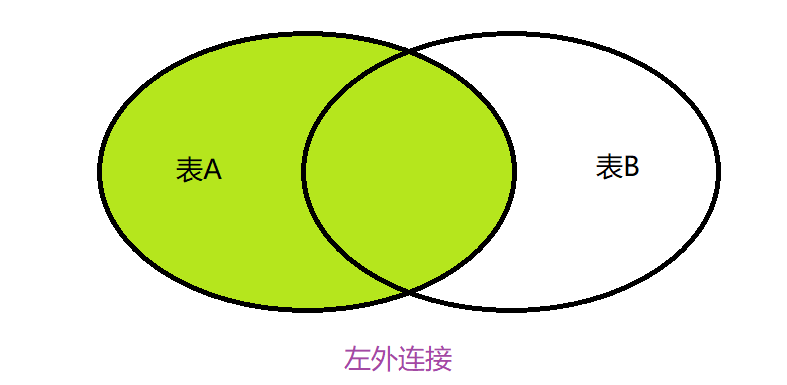
外连接是通过
join on
关键字来实现的,具体语法如下:
-- 左外连接select 字段 from 表A leftjoin 表B on 条件 ...;-- 右外连接select 字段 from 表A rightjoin 表B on 条件 ...;
我们来看下面的一个例子:
-- 建表A和Binsertinto A values(1,"张三"),(2,"李四"),(4,"王五");insertinto B values(1,98.5),(2,89.5),(3,82.0);-- A, B表数据+------+--------+| id | name |+------+--------+|1| 张三 ||2| 李四 ||4| 王五 |+------+--------++------+-------+| A_id | score |+------+-------+|1|98.50||2|89.50||3|82.00|+------+-------+
使用左外连接多表查询:
mysql>select*from A leftjoin B on A.id=B.A_id;+------+--------+------+-------+| id | name | A_id | score |+------+--------+------+-------+|1| 张三 |1|98.50||2| 李四 |2|89.50||4| 王五 |NULL|NULL|+------+--------+------+-------+3rowsinset(0.00 sec)
使用右外连接多表查询:
mysql>select*from A rightjoin B on A.id=B.A_id;+------+--------+------+-------+| id | name | A_id | score |+------+--------+------+-------+|1| 张三 |1|98.50||2| 李四 |2|89.50||NULL|NULL|3|82.00|+------+--------+------+-------+3rowsinset(0.00 sec)
使用内连接多表查询:
mysql>select*from A join B on A.id=B.A_id;+------+--------+------+-------+| id | name | A_id | score |+------+--------+------+-------+|1| 张三 |1|98.50||2| 李四 |2|89.50|+------+--------+------+-------+2rowsinset(0.00 sec)
🌼3.3.4自连接
自连接其实也是多表查询的一种,只不过原来是多张不同的表进行笛卡尔积,自连接是多张相同的表进行笛卡尔积,主要用于将行与行转换为列与列。
语法:
select 字段 from 表A, 表A,...where 条件;
栗子:根据3.3.1-3.3.2的成绩表,查找计算机组成原理成绩高于Java成绩的同学
id
,其中计算机组成原理课程
id
为
3
,Java课程
id
为
1
。
首先需要将两个成绩表笛卡尔积,由于两张相同的表存在列同名情况,需要使用
表名·.列名
来指定是哪一个表的列,对结果保留满足以下条件的数据:
- 两表学生id相同。
- 使左边的表保留课程id为
3的数据,右边的表保留课程id为1的数据。 - 上一步保证了左边的成绩是计算机原理,右边的成绩是Java,筛选计算机组成原理成绩大于Java成绩的同学id。
最后将学生id输出即可。
mysql>select*from score as s1, score as s2 where s1.student_id=s2.student_id and s1.course_id=3and s2.course_id=1and s1.score>s2.score;+-------+------------+-----------+-------+------------+-----------+| score | student_id | course_id | score | student_id | course_id |+-------+------------+-----------+-------+------------+-----------+|98.5|1|3|90.5|1|1||68.0|3|3|63.0|3|1|+-------+------------+-----------+-------+------------+-----------+2rowsinset(0.00 sec)-- 仅保留学生id
mysql>select s1.student_id from score as s1, score as s2 where s1.student_id=s2.student_id and s1.course_id=3and s2.course_id=1and s1.score>s2.score;+------------+| student_id |+------------+|1||3|+------------+2rowsinset(0.00 sec)
🌼3.3.5子查询
所谓子查询就是将查询语句嵌套,原来需要多部查询的操作转换为一步操作,但是嵌套层数多了,非常容易出错,因为人类的大脑并不擅长同时维护
多个变量
。
比如,查找花羊羊的同班同学,正常操作是先查询花羊羊所处班级,在根据班级查询花羊羊的同班同学。
-- 分步查询
mysql>select classes_id from student where name="花羊羊";+------------+| classes_id |+------------+|2|+------------+
mysql>select name from student where classes_id=2;+-----------+| name |+-----------+| 懒羊羊 || 花羊羊 || 小灰灰 || 希儿 |+-----------+-- 子查询
mysql>select name from student where classes_id=(select classes_id from student where name="花羊羊");+-----------+| name |+-----------+| 懒羊羊 || 花羊羊 || 小灰灰 || 希儿 |+-----------+
当嵌套的查询语句出现多条记录,可以搭配
[not]in
,
[not]exists
来使用·,就不多说了,因为子查询的方式比较反人类,工作中用的也不多。
🌼3.3.6合并查询
使用关键字
union
和
union all
能够取得两个结果集的并集,这两个合并查询关键字不同点就是带
all
的不会对结果去重,而不带
all
的会对结果去重,与
or
不相同的一点的是合并查询能够在多表进行查询得到并集,而
or
只能在单表中查询得到并集。
总的来说,合并查询能够查询不仅能够查询单表中两个结果的并集,也能查询多表中两个结果的并集,而
or
只能用于单表查询。
语法格式:
-- 去重合并查询select 字段 from 表A where 条件 unionselect 字段 from 表B where 条件;-- 不去重合并查询select 字段 from 表A where 条件 unionallselect 字段 from 表B where 条件;
表A与表B可以相同。
例如查询课程名为高等数学或者课程
id
大于等于
10
的课程名称。
-- 合并查询
mysql>select*from course where name="高等数学"unionselect*from course where id>=10;+----+--------------+| id | name |+----+--------------+|5| 高等数学 ||10| 数学分析 ||11| 无机化学 ||12| 机械制图 |+----+--------------+4rowsinset(0.00 sec)-- or
mysql>select*from course where name="高等数学"or id>=10;+----+--------------+| id | name |+----+--------------+|5| 高等数学 ||10| 数学分析 ||11| 无机化学 ||12| 机械制图 |+----+--------------+4rowsinset(0.00 sec)
到这里数据库的约束和数据表的一些稍微难一点的操作就全部介绍完毕了,最重要的还是实践,多写一些实例,多敲一些代码,这些知识完全是可以熟练掌握的。好了,内容就到这里了,下次见!
觉得文章写得不错的老铁们,点赞评论关注走一波!谢谢啦!
版权归原作者 未见花闻 所有, 如有侵权,请联系我们删除。