
在人类的语言中,单词的顺序和它们在句子中的位置是非常重要的。如果单词被重新排序后整个句子的意思就会改变,甚至可能变得毫无意义。
Transformers不像LSTM具有处理序列排序的内置机制,它将序列中的每个单词视为彼此独立。所以使用位置编码来保留有关句子中单词顺序的信息。
什么是位置编码?
位置编码(Positional encoding)可以告诉Transformers模型一个实体/单词在序列中的位置或位置,这样就为每个位置分配一个唯一的表示。虽然最简单的方法是使用索引值来表示位置,但这对于长序列来说,索引值会变得很大,这样就会产生很多的问题。
位置编码将每个位置/索引都映射到一个向量。所以位置编码层的输出是一个矩阵,其中矩阵中的每一行是序列中的编码字与其位置信息的和。
如下图所示为仅对位置信息进行编码的矩阵示例。
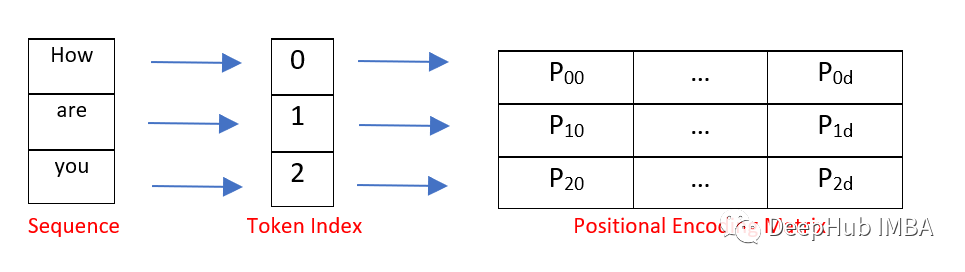
Transformers 中的位置编码层
假设我们有一个长度为 L 的输入序列,并且我们需要对象在该序列中的位置。位置编码由不同频率的正弦和余弦函数给出:
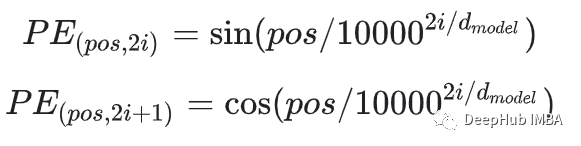
d:输出嵌入空间的维度
pos:输入序列中的单词位置,0≤pos≤L/2
i:用于映射到列索引 其中0≤i<d/2,并且I 的单个值还会映射到正弦和余弦函数
在上面的表达式中,我们可以看到偶数位置对使用正弦函数,奇数位置使用 余弦函数。
从头编写位置编码矩阵
下面是一小段使用NumPy实现位置编码的Python代码。代码经过简化,便于理解位置编码。
def getPositionEncoding(seq_len,dim,n=10000):
PE = np.zeros(shape=(seq_len,dim))
for pos in range(seq_len):
for i in range(int(dim/2)):
denominator = np.power(n, 2*i/dim)
PE[pos,2*i] = np.sin(pos/denominator)
PE[pos,2*i+1] = np.cos(pos/denominator)
return PE
PE = getPositionEncoding(seq_len=4, dim=4, n=100)
print(PE)
为了更好的理解位置彪马,我们可以对其进行可视化,让我们在更大的值上可视化位置矩阵。我们将从matplotlib库中使用Python的matshow()方法。比如设置n=10,000,得到:
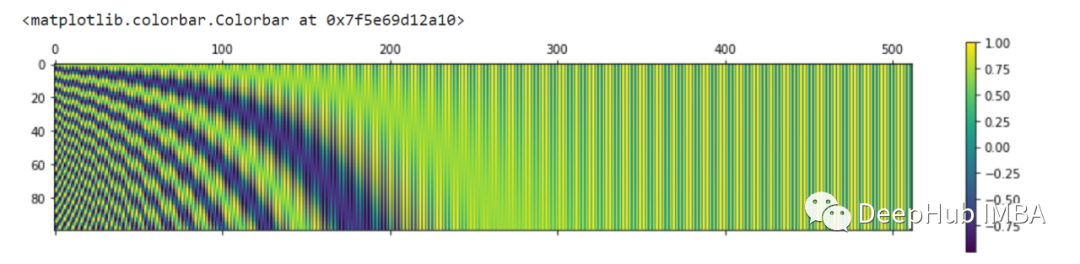
因此,位置编码层将单词嵌入与序列中每个标记的位置编码矩阵相加,作为下一层的输入。这里需要注意的是位置编码矩阵的维数应该与词嵌入的维数相同。
在 Keras 中编写自己的位置编码层
首先,让我们编写导入所有必需库。
import tensorflow as tf
from tensorflow import convert_to_tensor, string
from tensorflow.keras.layers import TextVectorization, Embedding, Layer
from tensorflow.data import Dataset
import numpy as np
以下代码使用 Tokenizer 对象将每个文本转换为整数序列(每个整数是字典中标记的索引)。
output_sequence_length = 4
vocab_size = 10
sentences = ["How are you doing", "I am doing good"]
tokenizer = Tokenizer()
tokenizer.fit_on_texts(sentences)
tokenzied_sent = tokenizer.texts_to_sequences(sentences)
print("Vectorized words: ", tokenzied_sent)
实现transformer 模型时,必须编写自己的位置编码层。这个 Keras 示例展示了如何编写 Embedding 层子类:
class PositionEmbeddingLayer(Layer):
def __init__(self, sequence_length, vocab_size, output_dim, **kwargs):
super(PositionEmbeddingLayer, self).__init__(**kwargs)
self.word_embedding_layer = Embedding(
input_dim=vocab_size, output_dim=output_dim
)
self.position_embedding_layer = Embedding(
input_dim=sequence_length, output_dim=output_dim
)
def call(self, inputs):
position_indices = tf.range(tf.shape(inputs)[-1])
embedded_words = self.word_embedding_layer(inputs)
embedded_indices = self.position_embedding_layer(position_indices)
return embedded_words + embedded_indices
这样我们的位置嵌入就完成了
作者:Srinidhi Karjol