

😊你好,我是小航,一个正在变秃、变强的文艺倾年。
🔔本文讲解实战ElasticSearch搜索匹配,欢迎大家多多关注!
🔔一起卷起来叭!目录
前言:
某天某月某日,当我在逛珍爱网的时候,突然想到了自己还木有女朋友,甚至忽略了我是一个男性!哦当然这不是重点,重点是它没有匹配到我理想的另一半,于是我决定,自己写一个搜索匹配,寻找自己理想的另一半。
一、设计数据库
SQL设计如下:
字典表设计:(用户所处的城市、兴趣…)
CREATETABLE`data_dict`(`id`bigintNOTNULLAUTO_INCREMENTCOMMENT'主键ID',`node_name`varchar(50)NOTNULLCOMMENT'节点名称',`parent_id`bigintNOTNULLDEFAULT'0'COMMENT'父ID',`type`intNOTNULLCOMMENT'类型:0-城市;1-兴趣',`node_level`intNOTNULLCOMMENT'节点层级',`show_status`intNOTNULLCOMMENT'是否显示:1-显示;0-不显示',`sort`intNOTNULLCOMMENT'排序',PRIMARYKEY(`id`))ENGINE=InnoDBDEFAULTCHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
二、初始化项目
项目结构:
如何初始化项目这里不再赘述,请看往期实战教程
三、功能实现
1.父子节点:
修改DataDictEntity表:
- 增加逻辑删除注解
- 增加child属性
packagecom.example.demo.entity;importcom.baomidou.mybatisplus.annotation.TableField;importcom.baomidou.mybatisplus.annotation.TableId;importcom.baomidou.mybatisplus.annotation.TableLogic;importcom.baomidou.mybatisplus.annotation.TableName;importjava.io.Serializable;importjava.util.Date;importjava.util.List;importcom.fasterxml.jackson.annotation.JsonInclude;importlombok.Data;/**
*
*
* @author Liu
* @email [email protected]
* @date 2022-10-06 20:48:15
*/@Data@TableName("data_dict")publicclassDataDictEntityimplementsSerializable{privatestaticfinallong serialVersionUID =1L;/**
* 主键ID
*/@TableIdprivateLong id;/**
* 节点名称
*/privateString nodeName;/**
* 父ID
*/privateLong parentId;/**
* 类型:0-城市;1-兴趣
*/privateInteger type;/**
* 节点层级
*/privateInteger nodeLevel;/**
* 是否显示:1-显示;0-不显示
*/@TableLogic(value ="1", delval ="0")privateInteger showStatus;/**
* 排序
*/privateInteger sort;@JsonInclude(JsonInclude.Include.NON_EMPTY)// 属性为空不参与序列化,这里方便前端处理@TableField(exist =false)// 数据库表中不存在该字段privateList<DataDictEntity> children;}
逻辑删除的配置也可以通过配置文件配置:
mybatis-plus:mapper-locations: classpath:/mapper/*.xmlglobal-config:db-config:id-type: auto # 主键自增logic-delete-value:1logic-not-delete-value:0
接下来我们编写接口:
控制层
ApiController:
@RestControllerpublicclassApiController{@AutowiredDataDictService dataDictService;@GetMapping("/list/tree")publicResult<List<DataDictEntity>>listWithTree(){List<DataDictEntity> entities = dataDictService.listWithTree();returnnewResult<List<DataDictEntity>>().ok(entities);}}
业务层
DataDictServiceImpl:
/**
* 树形查询
*/@OverridepublicList<DataDictEntity>listWithTree(){// 1.查出所有分类(数据库只查询一次,内存进行修改)List<DataDictEntity> entities = baseMapper.selectList(null);// 2.组装分类return entities.stream().filter(node -> node.getParentId()==0)// 先过滤得到所有一级分类.peek((nodeEntity)->{
nodeEntity.setChildren(getChildrens(nodeEntity, entities));// 递归得到一级分类的子部门}).sorted(Comparator.comparingInt(node ->(node.getSort()==null?0: node.getSort()))).collect(Collectors.toList());}/**
* 递归查询子节点
*/privateList<DataDictEntity>getChildrens(DataDictEntity root,List<DataDictEntity> all){return all.stream().filter(node -> root.getId().equals(node.getParentId()))// 找到root的子部门.peek(dept ->{
dept.setChildren(getChildrens(dept, all));// 设置为子部门}).sorted(Comparator.comparingInt(node ->(node.getSort()==null?0: node.getSort()))).collect(Collectors.toList());}
具体逻辑已经写到注释上面了
我们新增几个测试数据:
INSERTINTO`data_dict`VALUES(1,'1',0,0,1,1,2);INSERTINTO`data_dict`VALUES(2,'1-1',1,0,2,1,1);INSERTINTO`data_dict`VALUES(3,'1-1-1',2,0,3,1,1);INSERTINTO`data_dict`VALUES(4,'2',0,0,1,1,1);INSERTINTO`data_dict`VALUES(5,'3',0,0,1,0,1);
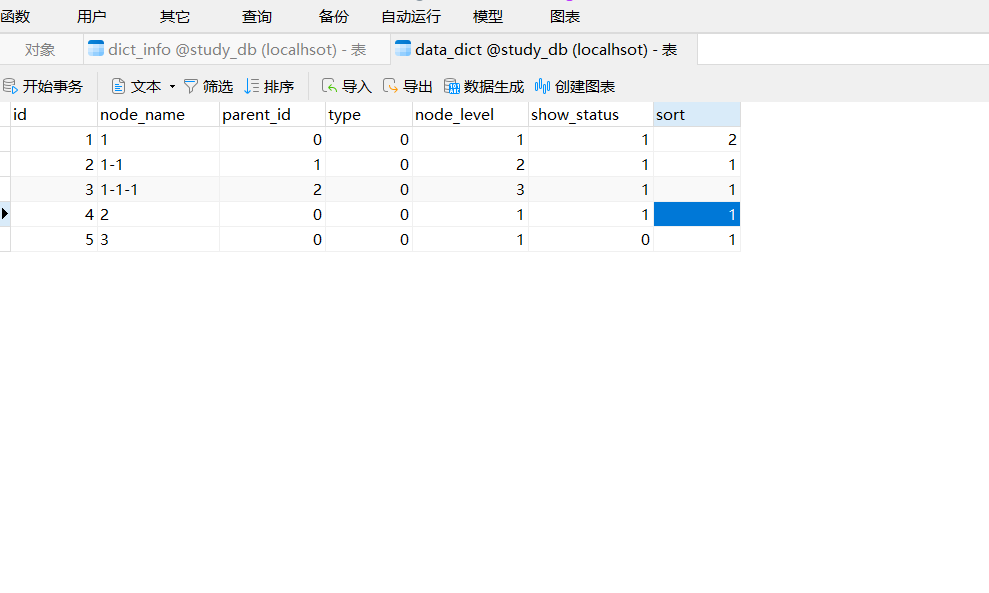
打开测试工具Apifox测试:
发送Get请求:
http://localhost:8080/list/tree
返回结果:
{"code":0,"msg":"success","data":[{"id":4,"nodeName":"2","parentId":0,"type":0,"nodeLevel":1,"showStatus":1,"sort":1},{"id":1,"nodeName":"1","parentId":0,"type":0,"nodeLevel":1,"showStatus":1,"sort":2,"children":[{"id":2,"nodeName":"1-1","parentId":1,"type":0,"nodeLevel":2,"showStatus":1,"sort":1,"children":[{"id":3,"nodeName":"1-1-1","parentId":2,"type":0,"nodeLevel":3,"showStatus":1,"sort":1}]}]}]}
如果树形节点数据不经常变动,且不是很重要的数据,我们可以考虑把数据缓存起来,加快查询速度
之前Redis详细的缓存实战请看这里:对接外部API + 性能调优
由于这里是一般场景,缓存数量不是很大,没必要使用第三方缓存,使用Spring Cache足够了:
1.开启Cache
@SpringBootApplication@EnableCachingpublicclassDemoApplication{publicstaticvoidmain(String[] args){SpringApplication.run(DemoApplication.class, args);}}
2.添加Cacheable 注解
/**
* 树形查询
* value:缓存名
* key:显示的指定key Spring官方更推荐,SpEL:Spring Expression Language,Spring 表达式语言
* sync = true 解决缓存击穿
*/@Cacheable(value ={"data_dict"}, key ="#root.method.name", sync =true)@OverridepublicList<DataDictEntity>listWithTree(){// 1.查出所有分类(数据库只查询一次,内存进行修改)List<DataDictEntity> entities = baseMapper.selectList(null);
log.info("查询了数据库!");// 2.组装分类return entities.stream().filter(node -> node.getParentId()==0)// 先过滤得到所有一级分类.peek((nodeEntity)->{
nodeEntity.setChildren(getChildrens(nodeEntity, entities));// 递归得到一级分类的子部门}).sorted(Comparator.comparingInt(node ->(node.getSort()==null?0: node.getSort()))).collect(Collectors.toList());}
我们打开Api文档测试:
调用两次方法后发现:
查询了数据库!
# 只出现了一次!
如果需要配置第三方缓存,需要引入依赖(spring-boot-starter-cache),然后在配置文件修改spring.cache.type:
<dependency>
第三方依赖
</dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-cache</artifactId></dependency>
这里就不再赘述了
2.搜索引擎:
准备工作:
(1)下载ealastic search(存储和检索)和kibana(可视化检索)
版本要统一
docker pull elasticsearch:7.4.2
docker pull kibana:7.4.2
(2)配置:
# 将docker里的目录挂载到linux的/mydata目录中
# 修改/mydata就可以改掉docker里的
mkdir -p /mydata/elasticsearch/config
mkdir -p /mydata/elasticsearch/data
# es可以被远程任何机器访问
echo "http.host: 0.0.0.0" >/mydata/elasticsearch/config/elasticsearch.yml
# 递归更改权限,es需要访问
chmod -R 777 /mydata/elasticsearch/
(3)启动Elastic search:
# 9200是用户交互端口 9300是集群心跳端口
# -e指定是单阶段运行
# -e指定占用的内存大小,生产时可以设置32G
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms64m -Xmx512m" \
-v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.4.2
# 设置开机启动elasticsearch
docker update elasticsearch --restart=always
(4)启动kibana:
# kibana指定了了ES交互端口9200 # 5600位kibana主页端口
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://192.168.56.10:9200 -p 5601:5601 -d kibana:7.4.2
# 设置开机启动kibana
docker update kibana --restart=always
(5)测试
查看elasticsearch版本信息:
http://192.168.56.10:9200
{
"name": "66718a266132",
"cluster_name": "elasticsearch",
"cluster_uuid": "xhDnsLynQ3WyRdYmQk5xhQ",
"version": {
"number": "7.4.2",
"build_flavor": "default",
"build_type": "docker",
"build_hash": "2f90bbf7b93631e52bafb59b3b049cb44ec25e96",
"build_date": "2019-10-28T20:40:44.881551Z",
"build_snapshot": false,
"lucene_version": "8.2.0",
"minimum_wire_compatibility_version": "6.8.0",
"minimum_index_compatibility_version": "6.0.0-beta1"
},
"tagline": "You Know, for Search"
}
显示elasticsearch 节点信息
http://192.168.56.10:9200/_cat/nodes
127.0.0.1 14 99 25 0.29 0.40 0.22 dilm * 66718a266132
66718a266132代表上面的结点
*代表是主节点
访问Kibana:
http://192.168.56.10:5601/app/kibana
为了增加ES的安全性,我们这里设置一下密码:
修改
elasticsearch.yml
文件(6.2或更早版本需要安装X-PACK, 新版本已包含在发行版中)
vim /mydata/elasticsearch/config/elasticsearch.yml
## 增加内容:
xpack.security.enabled: true
xpack.license.self_generated.type: basic
xpack.security.transport.ssl.enabled: true
重启ES服务:
docker restart elasticsearch
进入
elasticsearch
容器bin目录下
初始化密码
:
docker exec -it elasticsearch /bin/bash
/usr/share/elasticsearch/bin/elasticsearch-setup-passwords interactive
# 因为需要设置 elastic,apm_system,kibana,kibana_system,logstash_system,beats_system,remote_monitoring_user 这些用户的密码,故这个过程比较漫长,耐心设置;注意输入密码的时候看不到是正常的
这里我们将密码修改为:
123456
修改密码测试:
浏览器访问:http://192.168.56.10:9200
- 账号:elastic
- 密码:123456
exit # 退出之前的容器
# 进入kibana 容器内部
docker exec -it kibana /bin/bash
vi config/kibana.yml
# kinana.yml 末尾添加:
elasticsearch.username: "elastic"
elasticsearch.password: "123456"
# 重新启动kibana
exit
docker restart kibana
安装ik分词器:
由于所有的语言分词默认使用的都是“Standard Analyzer”,但是这些分词器针对于中文的分词,并不友好。为此需要安装中文的分词器。
查看自己的elasticsearch版本号:
访问:
http://192.168.56.10:9200
版本对应关系:
IK versionES versionmaster7.x -> master6.x6.x5.x5.x1.10.62.4.61.9.52.3.51.8.12.2.11.7.02.1.11.5.02.0.01.2.61.0.01.2.50.90.x1.1.30.20.x1.0.00.16.2 -> 0.19.0
ik分词器下载
之前我们已经将
elasticsearch
容器的
/usr/share/elasticsearch/plugins
目录,映射到宿主机的
/mydata/elasticsearch/plugins
目录下,所以我们直接下载
/elasticsearch-analysis-ik-7.4.2.zip
文件,然后
解压
到该文件夹下即可。安装完毕后,记得
重启elasticsearch容器
。
安装完成后,测试分词器:
打开 kibana-DevTool 控制台:
GET _analyze
{"analyzer":"ik_smart",
"text":"小航是中国人"}
输出结果:
{"tokens":[{"token":"小",
"start_offset":0,
"end_offset":1,
"type":"CN_CHAR",
"position":0},
{"token":"航",
"start_offset":1,
"end_offset":2,
"type":"CN_CHAR",
"position":1},
{"token":"是",
"start_offset":2,
"end_offset":3,
"type":"CN_CHAR",
"position":2},
{"token":"中国人",
"start_offset":3,
"end_offset":6,
"type":"CN_WORD",
"position":3}]}
小航
竟然没有被识别出来!!!
这可不行,得把“小航”当作一个词,所以我们搞个
“自定义词库”
:
安装Nginx:
//先创建一个存放nginx的文件夹
cd /mydata/
mkdir nginx
//下载安装nginx1.10,只是为了获取配置信息,进行配置映射,直接安装会先下载再安装
docker run -p 80:80 --name nginx -d nginx:1.10
//将容器里面的配置文件拷贝到当前目录
docker container cp nginx:/etc/nginx .
//查看mydata的nginx下面有没有文化,有则表示拷贝成功,则可以停止服务
docker stop nginx
dockerrm nginx
//为了防止后面安装新的nginx会出现的问题,进入mydata文件夹,再将之前复制的文件重新命名
mv nginx conf
//再创建nginx,将conf移动到nginx里面
mkdir nginx
mv conf nginx/
//再安装新的nginx
docker run -p 80:80 --name nginx \
-v /mydata/nginx/html:/usr/share/nginx/html \
-v /mydata/nginx/logs:/var/log/nginx \
-v /mydata/nginx/conf/:/etc//nginx \
-d nginx:1.10
//再在nginx的html下面创建一个文件夹
cd /mydata/nginx/html
mkdir es
cd es
//再创建一个fenci.txt,追加内容“小航”,并查看
echo'小航'>> ./fenci.txt
cat fenci.txt
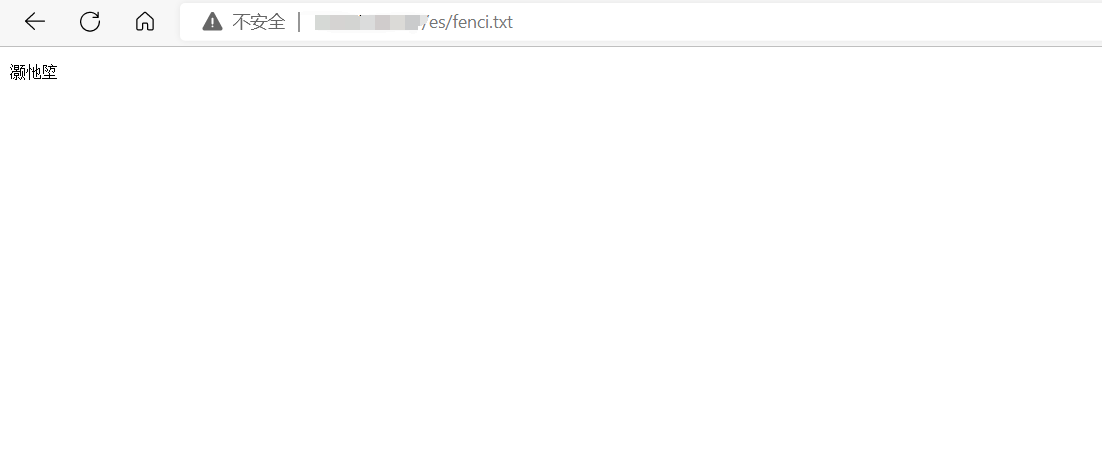
nginx启动后测试访问该文件:
http://192.168.56.10/es/fenci.txt
修改
/mydata/elasticsearch/plugins/elasticsearch-analysis-ik-7.4.2/config
中的
IKAnalyzer.cfg.xml
去掉注释,修改地址
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPEpropertiesSYSTEM"http://java.sun.com/dtd/properties.dtd"><properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 --><entrykey="ext_dict"></entry><!--用户可以在这里配置自己的扩展停止词字典--><entrykey="ext_stopwords"></entry><!--用户可以在这里配置远程扩展字典 --><entrykey="remote_ext_dict">http://192.168.56.10/es/fenci.txt</entry><!--用户可以在这里配置远程扩展停止词字典--><!-- <entry key="remote_ext_stopwords">words_location</entry> --></properties>
!!!重启es:
docker restart elasticsearch
再次测试:
GET _analyze
{"analyzer":"ik_smart",
"text":"小航是中国人"}
输出结果:
{
"tokens" : [
{
"token" : "小航",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "是",
"start_offset" : 2,
"end_offset" : 3,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "中国人",
"start_offset" : 3,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 2
}
]
}
Nice!
整合Elasticsearch
如果您对ES的基础操作不太了解,请先学习!后期有时间再出ES快速上手教程,本期只写准备环境和整合
Java操作es有两种方式:
1)9300: TCP
- spring-data-elasticsearch:transport-api.jar;
- springboot版本不同,ransport-api.jar不同,不能适配es版本 7.x已经不建议使用,8以后就要废弃
2)9200: HTTP
- jestClient: 非官方,更新慢;
- RestTemplate:模拟HTTP请求,ES很多操作需要自己封装,麻烦;
- HttpClient:同上;
- Elasticsearch-Rest-Client:官方RestClient,封装了ES操作,API层次分明,上手简单;
我们最终选择Elasticsearch-Rest-Client(elasticsearch-rest-high-level-client),具体说明文档:
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-high.html
1.导入依赖:(springboot这里默认给的版本是7.6,和咱们的不一样,这里排除重新引入)
<properties><elasticsearch.version>7.4.2</elasticsearch.version></properties><!-- elasticsearch --><!-- elasticsearch开始 --><dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId><version>${elasticsearch.version}</version></dependency><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-client</artifactId><version>${elasticsearch.version}</version></dependency><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>${elasticsearch.version}</version><exclusions><exclusion><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId></exclusion><exclusion><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-client</artifactId></exclusion></exclusions></dependency><!-- elasticsearch结束 -->
修改后: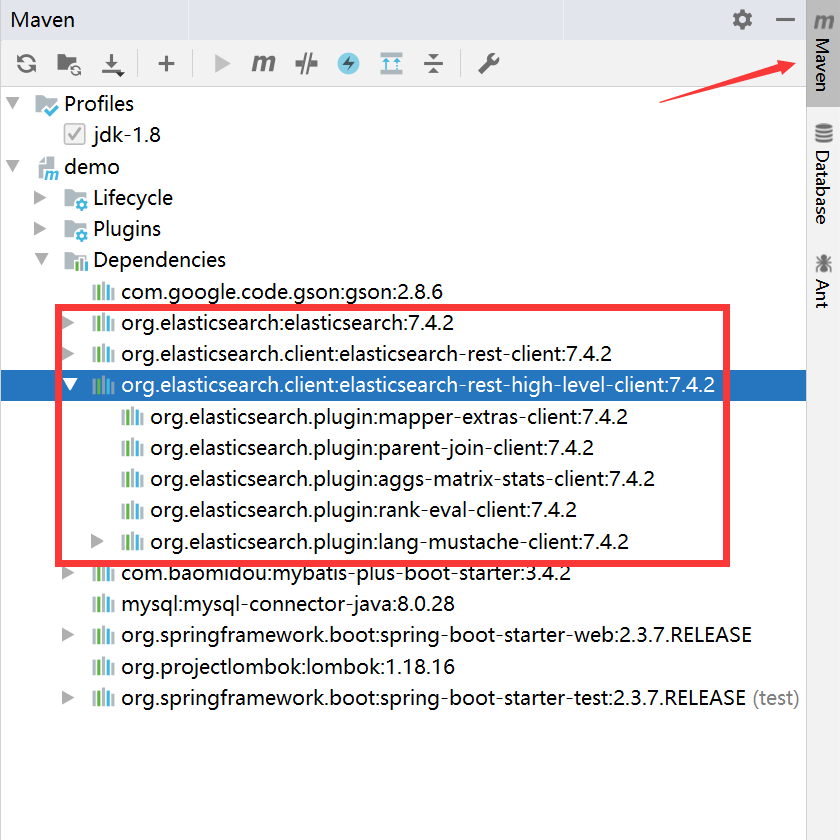
修改前: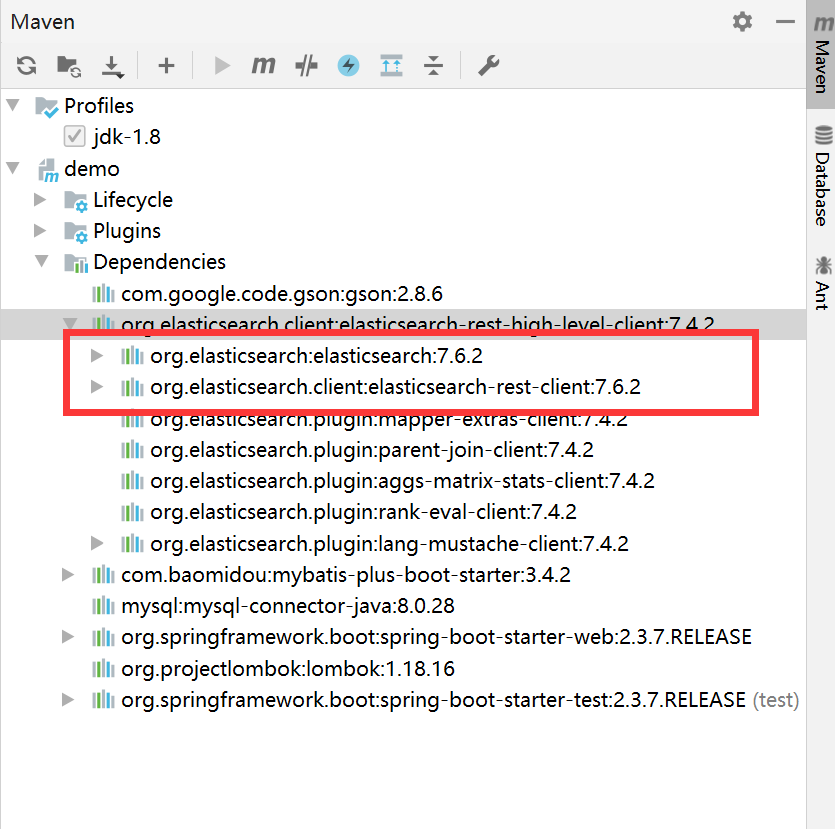
2.配置信息:
application.yml:
elasticsearch:schema: http
host: 192.168.56.10
port:9200username: elastic
password:123456
编写ElasticSearchConfig配置类:
packagecom.example.demo.config;importlombok.Data;importorg.apache.http.HttpHost;importorg.apache.http.auth.AuthScope;importorg.apache.http.auth.UsernamePasswordCredentials;importorg.apache.http.client.CredentialsProvider;importorg.apache.http.impl.client.BasicCredentialsProvider;importorg.elasticsearch.client.*;importorg.springframework.boot.context.properties.ConfigurationProperties;importorg.springframework.context.annotation.Bean;importorg.springframework.context.annotation.Configuration;/**
* @author xh
* @Date 2022/10/8
*/@Data@Configuration@ConfigurationProperties(prefix ="elasticsearch")publicclassElasticSearchConfig{publicstaticfinalRequestOptions COMMON_OPTIONS;static{RequestOptions.Builder builder =RequestOptions.DEFAULT.toBuilder();// 默认缓存限制为100MB,此处修改为30MB。
builder.setHttpAsyncResponseConsumerFactory(newHttpAsyncResponseConsumerFactory
.HeapBufferedResponseConsumerFactory(30*1024*1024));
COMMON_OPTIONS = builder.build();}privateString schema;privateString host;privateInteger port;privateString username;privateString password;@BeanpublicRestHighLevelClientclient(){// Elasticsearch需要basic auth验证finalCredentialsProvider credentialsProvider =newBasicCredentialsProvider();// 配置账号密码
credentialsProvider.setCredentials(AuthScope.ANY,newUsernamePasswordCredentials(username, password));// 通过builder创建rest client,配置http client的HttpClientConfigCallback。RestClientBuilder builder =RestClient.builder(newHttpHost(host, port, schema)).setHttpClientConfigCallback(httpClientBuilder ->{
httpClientBuilder.disableAuthCaching();return httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider);});returnnewRestHighLevelClient(builder);}}
3.测试:
@SpringBootTestclassDemoApplicationTests{@AutowiredRestHighLevelClient client;/**
* 测试获取elasticsearch对象
*/@TestvoidcontextLoads(){System.out.println(client);}/**
* 新建索引测试
**/@TestpublicvoidindexData()throwsIOException{// 设置索引IndexRequest indexRequest =newIndexRequest("users");
indexRequest.id("1");User user =newUser();
user.setUsername("张三");Gson gson =newGson();String jsonString = gson.toJson(user);//设置要保存的内容,指定数据和类型
indexRequest.source(jsonString,XContentType.JSON);//执行创建索引和保存数据IndexResponse index = client.index(indexRequest,ElasticSearchConfig.COMMON_OPTIONS);System.out.println(index);}@DataclassUser{privateString username;}}
运行结果:
org.elasticsearch.client.RestHighLevelClient@47248a48
说明elasticsearch对象成功加载到spring上下文中
IndexResponse[index=users,type=_doc,id=1,version=1,result=created,seqNo=0,primaryTerm=1,shards={"total":2,"successful":1,"failed":0}]
索引建立成功
数据库、索引设计
新增数据库:
data_info
CREATETABLE`dict_info`(`id`BIGINTNOTNULLAUTO_INCREMENTCOMMENT'主键ID',`dict_id`BIGINTNOTNULLCOMMENT'节点ID',`info_id`BIGINTNOTNULLCOMMENT'信息ID',`deleted`TINYINTNOTNULLCOMMENT'是否删除:0-未删除;1-已删除',PRIMARYKEY(`id`,`dict_id`,`info_id`))ENGINE=INNODBDEFAULTCHARSET= utf8mb4 COLLATE= utf8mb4_0900_ai_ci;
建立
data_info
索引:
PUT data_info
{"mappings":{"properties":{"dataId":{"type":"long"},"dataTitle":{"type":"text","analyzer":"ik_max_word","search_analyzer":"ik_smart"},"dataInfo":{"type":"text","analyzer":"ik_max_word","search_analyzer":"ik_smart"},"dataLike":{"type":"long"},"dataImg":{"type":"keyword","index":false,"doc_values":false},"node":{"type":"nested","properties":{"nodeId":{"type":"long"},"nodeName":{"type":"keyword","index":false,"doc_values":false}}}}}}
索引说明:
PUT data_info
{"mappings":{"properties":{"dataId":{"type":"long"}, # 信息ID"dataTitle":{ # 信息标题
"type":"text","analyzer":"ik_max_word","search_analyzer":"ik_smart"},"dataInfo":{ # 简略信息
"type":"text","analyzer":"ik_max_word","search_analyzer":"ik_smart"},"dataLike":{"type":"long"}, # 信息点赞量
"dataImg":{ # 信息预览图
"type":"keyword","index":false, # 不可被检索,不生成index,只用做页面使用
"doc_values":false # 不可被聚合,默认为true},"node":{ # 节点信息
"type":"nested","properties":{"nodeId":{"type":"long"},"nodeName":{"type":"keyword","index":false,"doc_values":false}}}}}}
数据新增
ApiController新增新的接口:
save
@AutowiredDataDictService dataDictService;@AutowiredDataInfoService dataInfoService;@AutowiredRestHighLevelClient client;@PostMapping("/save")publicResult<String>saveData(@RequestBodyList<ESModel> esModels){boolean flag = dataInfoService.saveDatas(esModels);if(flag){// TODO 审核后可检索到
flag =esUpdate(esModels);}if(flag){returnnewResult<String>().ok("数据保存成功!");}else{returnnewResult<String>().error("数据保存失败!");}}privatebooleanesUpdate(List<ESModel> esModel){// 1.给ES建立一个索引 dataVoBulkRequest bulkRequest =newBulkRequest();for(ESModel model : esModel){// 设置索引IndexRequest indexRequest =newIndexRequest("data_info");// 设置索引id
indexRequest.id(model.getDataId().toString());Gson gson =newGson();String jsonString = gson.toJson(model);
indexRequest.source(jsonString,XContentType.JSON);// add
bulkRequest.add(indexRequest);}// bulk批量保存BulkResponse bulk =null;try{
bulk = client.bulk(bulkRequest,ElasticSearchConfig.COMMON_OPTIONS);}catch(IOException e){
e.printStackTrace();}boolean hasFailures = bulk.hasFailures();if(hasFailures){List<String> collect =Arrays.stream(bulk.getItems()).map(BulkItemResponse::getId).collect(Collectors.toList());
log.error("ES新增错误:{}",collect);}return!hasFailures;}
具体解释都在注释中,这里就不赘述了。
DataInfoServiceImpl:
packagecom.example.demo.service.impl;importcom.example.demo.entity.DataDictEntity;importcom.example.demo.vo.ESModel;importorg.springframework.stereotype.Service;importcom.baomidou.mybatisplus.extension.service.impl.ServiceImpl;importcom.example.demo.dao.DataInfoDao;importcom.example.demo.entity.DataInfoEntity;importcom.example.demo.service.DataInfoService;importjava.util.ArrayList;importjava.util.List;@Service("dataInfoService")publicclassDataInfoServiceImplextendsServiceImpl<DataInfoDao,DataInfoEntity>implementsDataInfoService{@OverridepublicbooleansaveDatas(List<ESModel> esModels){List<DataInfoEntity> dataInfoEntities =newArrayList<>();for(ESModel esModel : esModels){DataInfoEntity dataInfoEntity =newDataInfoEntity();
dataInfoEntity.setImg(esModel.getDataImg());
dataInfoEntity.setInfo(esModel.getDataInfo());
dataInfoEntity.setLikes(0L);
dataInfoEntity.setTitle(esModel.getDataTitle());
dataInfoEntities.add(dataInfoEntity);
baseMapper.insert(dataInfoEntity);
esModel.setDataId(dataInfoEntity.getId());
esModel.setDataLike(dataInfoEntity.getLikes());}// return saveBatch(dataInfoEntities);returntrue;}}
TODO:这里批量处理待优化,先鸽这!
启动项目测试:
测试数据:
[{"dataTitle":"title","dataInfo":"dataInfo","dataImg":"dataImg","nodes":[{"nodeId":1,"nodeName":"1"}]}]
返回结果:
{"code":0,"msg":"success","data":"数据保存成功!"}
我们打开ES控制台查看一下结果:
命令:
GET/data_info/_search
{"query":{"match_all":{}}}
结果:
{"took":5,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":1,"relation":"eq"},"max_score":1.0,"hits":[{"_index":"data_info","_type":"_doc","_id":"1","_score":1.0,"_source":{"dataId":1,"dataTitle":"title","dataInfo":"dataInfo","dataLike":0,"dataImg":"dataImg","nodes":[{"nodeId":1,"nodeName":"1"}]}}]}}
Perfectly!
数据检索
我们先来思考一下检索条件可能有哪些:
全文检索:dataTitle、dataInfo
排序:dataLike(点赞量)
过滤:node.id
聚合:node
keyword=小航&
sort=dataLike_desc/asc&
node=3:4
额,貌似需求有点简单,好像不够把知识点都串上
增加一组测试数据:
[{"dataTitle":"速度还是觉得还是觉得合适机会减少","dataInfo":"网络新词 网络上经常会出现一些新词,比如“蓝瘦香菇”,蓝瘦香菇默认情况下会被分词,分词结果如下所示 蓝,瘦,香菇 这样的分词会导致搜索出很多不相关的结果,在这种情况下,我们使用扩展词库","dataImg":"dataImg","nodes":[{"nodeId":1,"nodeName":"节点1"}]}]
编写DSL查询语句:
GET/data_info/_search
{"query":{"bool":{"must":[{"multi_match":{"query":"速度","fields":["dataTitle","dataInfo"]}}],"filter":{"nested":{"path":"nodes","query":{"bool":{"must":[{"term":{"nodes.nodeId":{"value":1}}}]}}}}}},"sort":[{"dataLike":{"order":"desc"}}],"from":0,"size":5,"highlight":{"fields":{"dataTitle":{},"dataInfo":{}},"pre_tags":"<b style='color:red'>","post_tags":"</b>"}}
查询结果:
{"took":3,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":1,"relation":"eq"},"max_score":null,"hits":[{"_index":"data_info","_type":"_doc","_id":"17","_score":null,"_source":{"dataId":17,"dataTitle":"速度还是觉得还是觉得合适机会减少","dataInfo":"网络新词 网络上经常会出现一些新词,比如“蓝瘦香菇”,蓝瘦香菇默认情况下会被分词,分词结果如下所示 蓝,瘦,香菇 这样的分词会导致搜索出很多不相关的结果,在这种情况下,我们使用扩展词库","dataLike":0,"dataImg":"dataImg","nodes":[{"nodeId":1,"nodeName":"节点1"}]},"highlight":{"dataTitle":["<b style='color:red'>速度</b>还是觉得还是觉得合适机会减少"]},"sort":[0]}]}}
接下来我们使用Java的方式操作DSL:
SearchParam
请求参数:
packagecom.example.demo.vo;importlombok.Data;importjava.util.List;/**
* @author xh
* @Date 2022/10/12
*/@DatapublicclassSearchParam{// 页面传递过来的全文匹配关键字:keyword=小航privateString keyword;//排序条件:sort=dataLike_desc/ascprivateString sort;/*** 按照节点进行筛选 */// node=3:4privateList<String> nodes;/*** 页码*/privateInteger pageNum =1;/*** 原生所有查询属性*/privateString _queryString;}
SearchResult
返回结果:
packagecom.example.demo.vo;importcom.example.demo.entity.DataInfoEntity;importlombok.Data;importjava.util.List;/**
* @author xh
* @Date 2022/10/12
*/@DatapublicclassSearchResult{/** 查询到所有的DataInfos*/privateList<DataInfoEntity> dataInfos;/*** 当前页码*/privateInteger pageNum;/** 总记录数*/privateLong total;/** * 总页码*/privateInteger totalPages;}
由于我们的需求有:每条信息对应的标签也需要显示
@Data@TableName("data_info")publicclassDataInfoEntityimplementsSerializable{privatestaticfinallong serialVersionUID =1L;/**
* 主键ID
*/@TableId(type =IdType.AUTO)privateLong id;/**
* 标题
*/privateString title;/**
* 详情
*/privateString info;/**
* 标题图
*/privateString img;/**
* 点赞量
*/privateLong likes;/**
* 标签
*/@TableField(exist =false)privateList<String> nodeNames;}
编写接口:
ApiController
:
@AutowiredDataDictService dataDictService;@AutowiredDataInfoService dataInfoService;@AutowiredRestHighLevelClient client;publicstaticfinalInteger PAGE_SIZE =5;@GetMapping("/search")publicResult<SearchResult>getSearchPage(SearchParam searchParam,HttpServletRequest request){// TODO 请求参数加密 && 反爬虫// 获取请求参数
searchParam.set_queryString(request.getQueryString());SearchResult result =getSearchResult(searchParam);returnnewResult<SearchResult>().ok(result);}/**
* 得到请求结果
*/publicSearchResultgetSearchResult(SearchParam searchParam){//根据带来的请求内容封装SearchResult searchResult=null;// 通过请求参数构建查询请求SearchRequest request =buildSearchRequest(searchParam);try{SearchResponse searchResponse = client.search(request,ElasticSearchConfig.COMMON_OPTIONS);// 将es响应数据封装成结果
searchResult =buildSearchResult(searchParam,searchResponse);}catch(IOException e){
e.printStackTrace();}return searchResult;}privateSearchResultbuildSearchResult(SearchParam searchParam,SearchResponse searchResponse){SearchResult result =newSearchResult();SearchHits hits = searchResponse.getHits();//1. 封装查询到的商品信息if(hits.getHits()!=null&&hits.getHits().length>0){List<DataInfoEntity> dataInfoEntities =newArrayList<>();for(SearchHit hit : hits){// 获取JSON并解析为ESModelString sourceAsString = hit.getSourceAsString();Gson gson =newGson();ESModel esModel = gson.fromJson(sourceAsString,newTypeToken<ESModel>(){}.getType());// ESModel转DataInfoEntityDataInfoEntity dataInfoEntity =newDataInfoEntity();
dataInfoEntity.setTitle(esModel.getDataTitle());
dataInfoEntity.setInfo(esModel.getDataInfo());
dataInfoEntity.setImg(esModel.getDataImg());
dataInfoEntity.setId(esModel.getDataId());
dataInfoEntity.setLikes(esModel.getDataLike());
dataInfoEntity.setNodeNames(esModel.getNodes().stream().map(ESModel.Node::getNodeName).collect(Collectors.toList()));//设置高亮属性if(!StringUtils.isEmpty(searchParam.getKeyword())){HighlightField dataTitle = hit.getHighlightFields().get("dataTitle");if(dataTitle !=null){String highLight = dataTitle.getFragments()[0].string();
dataInfoEntity.setTitle(highLight);}HighlightField dataInfo = hit.getHighlightFields().get("dataInfo");if(dataInfo !=null){String highLight = dataInfo.getFragments()[0].string();
dataInfoEntity.setInfo(highLight);}}
dataInfoEntities.add(dataInfoEntity);}
result.setDataInfos(dataInfoEntities);}//2. 封装分页信息//2.1 当前页码
result.setPageNum(searchParam.getPageNum());//2.2 总记录数long total = hits.getTotalHits().value;
result.setTotal(total);//2.3 总页码Integer totalPages =(int)total % PAGE_SIZE ==0?(int)total / PAGE_SIZE :(int)total / PAGE_SIZE +1;
result.setTotalPages(totalPages);return result;}/**
* 构建请求语句
*/privateSearchRequestbuildSearchRequest(SearchParam searchParam){// 用于构建DSL语句SearchSourceBuilder searchSourceBuilder =newSearchSourceBuilder();//1. 构建bool queryBoolQueryBuilder boolQueryBuilder =newBoolQueryBuilder();//1.1 bool mustif(!StringUtils.isEmpty(searchParam.getKeyword())){
boolQueryBuilder.must(QueryBuilders.multiMatchQuery(searchParam.getKeyword(),"dataTitle","dataInfo"));}// 1.2 filter nestedList<Long> nodes = searchParam.getNodes();BoolQueryBuilder queryBuilder =newBoolQueryBuilder();if(nodes!=null&& nodes.size()>0){
nodes.forEach(nodeId ->{
queryBuilder.must(QueryBuilders.termQuery("nodes.nodeId", nodeId));});}NestedQueryBuilder nestedQueryBuilder =QueryBuilders.nestedQuery("nodes", queryBuilder,ScoreMode.None);
boolQueryBuilder.filter(nestedQueryBuilder);//1.3 bool query构建完成
searchSourceBuilder.query(boolQueryBuilder);//2. sort eg:sort=dataLike_desc/ascif(!StringUtils.isEmpty(searchParam.getSort())){String[] sortSplit = searchParam.getSort().split("_");
searchSourceBuilder.sort(sortSplit[0],"asc".equalsIgnoreCase(sortSplit[1])?SortOrder.ASC :SortOrder.DESC);}//3. 分页 // 是检测结果分页
searchSourceBuilder.from((searchParam.getPageNum()-1)* PAGE_SIZE);
searchSourceBuilder.size(PAGE_SIZE);//4. 高亮highlightif(!StringUtils.isEmpty(searchParam.getKeyword())){HighlightBuilder highlightBuilder =newHighlightBuilder();
highlightBuilder.field("dataTitle");
highlightBuilder.field("dataInfo");
highlightBuilder.preTags("<b style='color:red'>");
highlightBuilder.postTags("</b>");
searchSourceBuilder.highlighter(highlightBuilder);}
log.debug("构建的DSL语句 {}",searchSourceBuilder.toString());SearchRequest request =newSearchRequest(newString[]{"data_info"}, searchSourceBuilder);return request;}
测试接口:
请求地址:
http://localhost:8080/search?keyword=速度&sort=dataLike_desc&nodes=1
GET请求
返回结果:
{"code":0,"msg":"success","data":{"dataInfos":[{"id":17,"title":"<b style='color:red'>速度</b>还是觉得还是觉得合适机会减少","info":"网络新词 网络上经常会出现一些新词,比如“蓝瘦香菇”,蓝瘦香菇默认情况下会被分词,分词结果如下所示 蓝,瘦,香菇 这样的分词会导致搜索出很多不相关的结果,在这种情况下,我们使用扩展词库","img":"dataImg","likes":0,"nodeNames":["节点1"]}],"pageNum":1,"total":1,"totalPages":1}}
大功告成!
版权归原作者 文艺倾年 所有, 如有侵权,请联系我们删除。