
前言:
最近chatGPT火出圈,其实不是chatGPT多智能,只是它用了一种新的交互方式来组织我们现有的知识,然后通过“高智商”的表达来使我们惊艳。但是目前或者未来的人工智能缺少创造力,他们只会整合信息目的是提高我们的效率。现在好多人不是说,ChatGPT可以写小说吗?至少可以先让程序写一个初版,然后作家再亲自上手精修。针对这个现象,作为一个作家,特德·姜给自己的同行提了个建议。就是,不要这么干。因为初稿对作家来说,其实很重要。
借用特德·姜的原话。你的初稿只是一个原始想法的拙劣表达,你对它是不满意的,而初稿的价值,就在于让你意识到,你所说的和想说的之间的距离。这能够指导你重写东西。当你使用人工智能写初稿时,你将缺少这种指导。正如有句话说的,最适合你往上攀登的台阶,往往不是别人,而是昨天的自己。其实在我们身边的很多工具早就有了chatGPT的功能了。今天分享kettle中的那些人工智能。
一、kettle的AI能力目录
跨库同步
传统
kettle
效果对比
源库与目标库类型一致
需提前整理表名、表结构等
只能全库同步、批量SQ表同步
不限制数据库类型
无需整理SQ
1:1灵活复制
传统方式耗时长、数据库类型限制
kettle可灵活选择、无数据库类型限制
kettle更AI(智能)
例:
源库是oracle,目标库必须是oracle,同步时数据泵或者第三方同步软件全库或者批量表同步
例:
源库是mysql,目标库可以是oracle、mysql、sqlserver任一类型,灵活选择同步方式
2.自动开发
传统
kettle
效果对比
写数据泵脚本、等待同步耗时在一天左右
编写建表SQ、同步表超一百时,错误率高、开发周期长
购买第三方软件,选型时间长,部署服务器、运维等,耗时长、成本高
1、可视化开发,可见即可得
2、标准化开发,几步自动完成
3、零代码开发,DevOps
传统方式耗时长、成本高
kettle更AI、更高效
例:
源库是oracle,目标库必须是oracle,同步时数据泵或者第三方同步软件全库或者批量表同步
例:
源库是mysql,目标库可以是oracle、mysql、sqlserver任一类型,灵活选择同步方式
3.自动优化
传统
kettle
效果对比
表同步后,数据进数据库后不会根据数据量和开发程序的特点提出优化建议
开发程序不同自动生成优化脚本如自动生成单主键、联合主键索引
根据开发程序自动生成增删字段语句
根据源数据库数据自动匹配字段类型
传统方式下数据库优化全靠经验
kettle模式下AI自动优化
例:
无
例:
插入更新模式下会自动生成插入更新主键索引
第一次抽取数据时会自动建表并根据数据量匹配数据类型,如number类型会根据源数据库的数的大小和小数点情况生成如number(10,5)的数据类型
更多优化知识可参加我上一节的文章
数据库优化
二、AI实例
1、跨库同步
sqlsever表同步至oracle数据库
1.1源库sqlserver
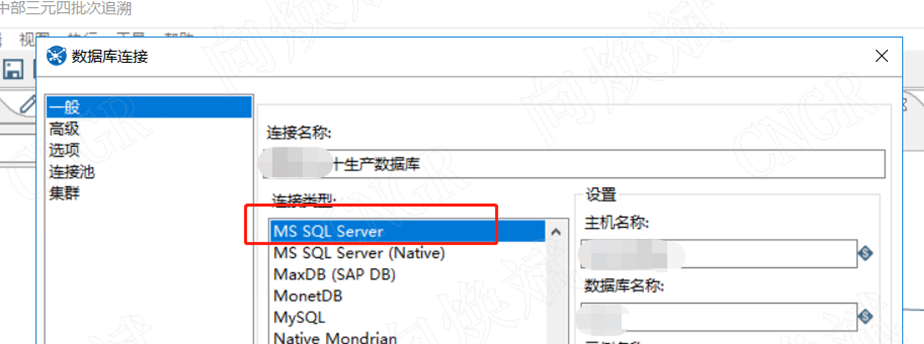
1.2目标库oracle
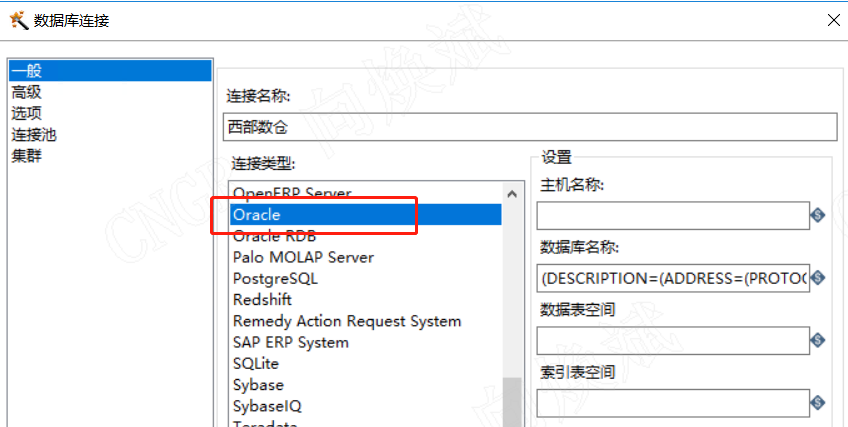
1.3可视化跨库同步
使用多表复制向导

选择跨库的表,下一步下一步,即可生成跨库同步程序
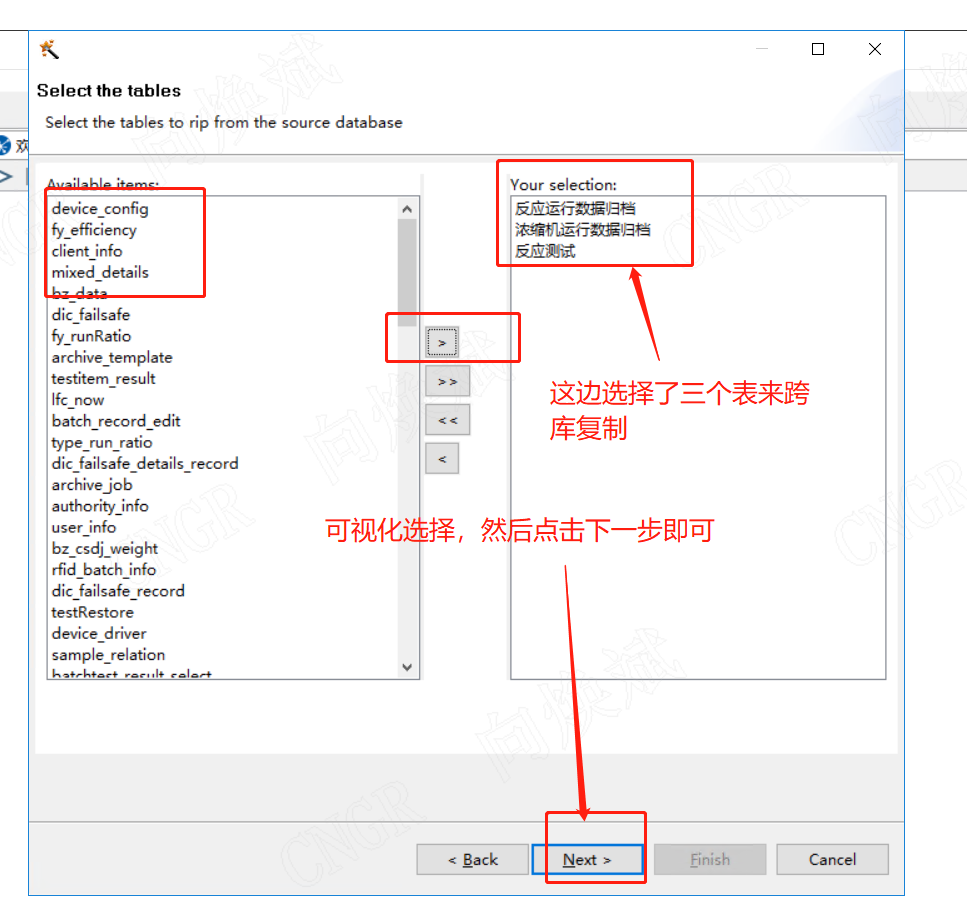
查看自动生成的复制程序,根据自己的需求可做微雕。如统一同步过来的表名称
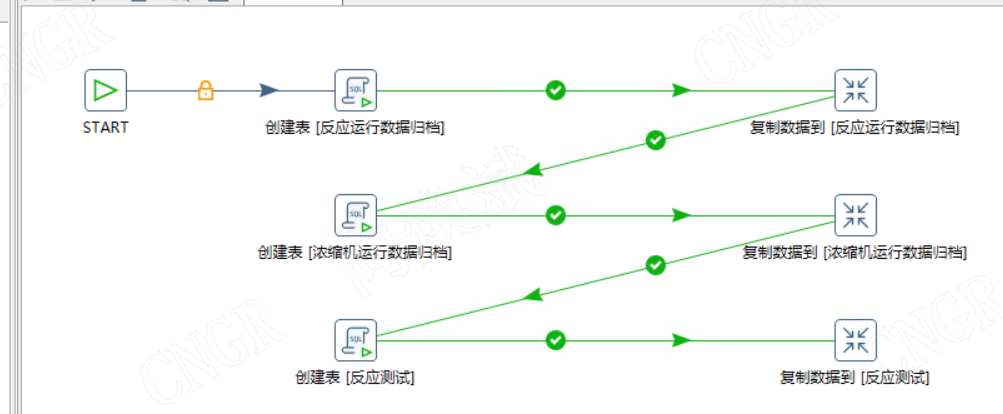
最终效果
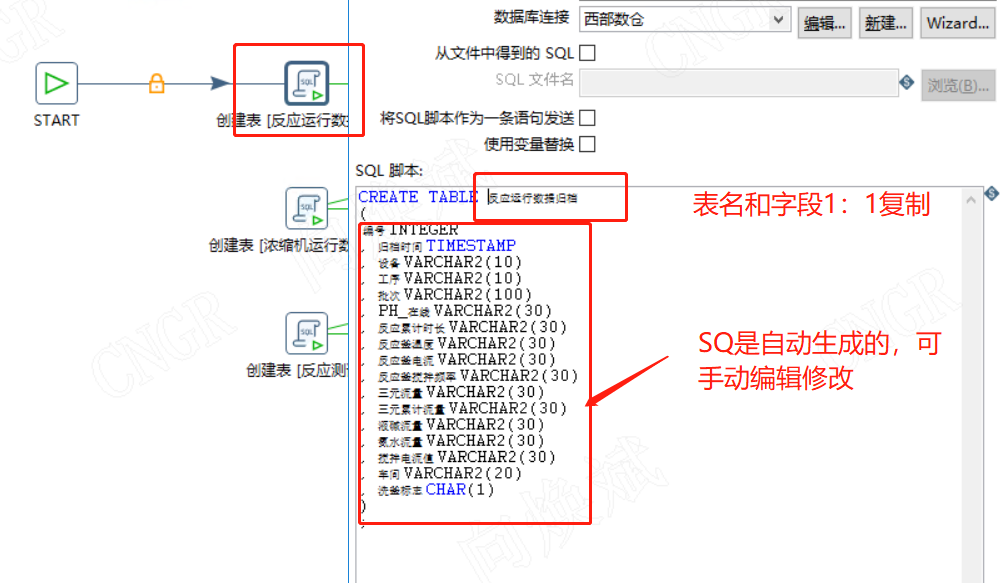
自动生成转换完成数据同步任务,非常的标准并且带有标准注释
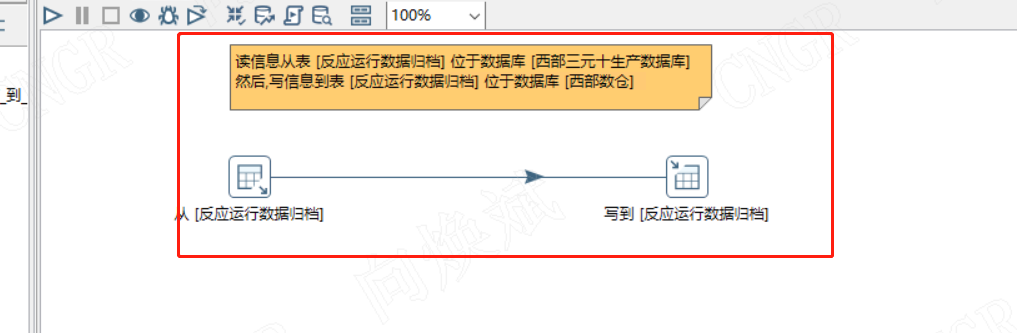
执行作业后,目标库可查看到对应同步表

2、自动开发、优化
2.1自动开发
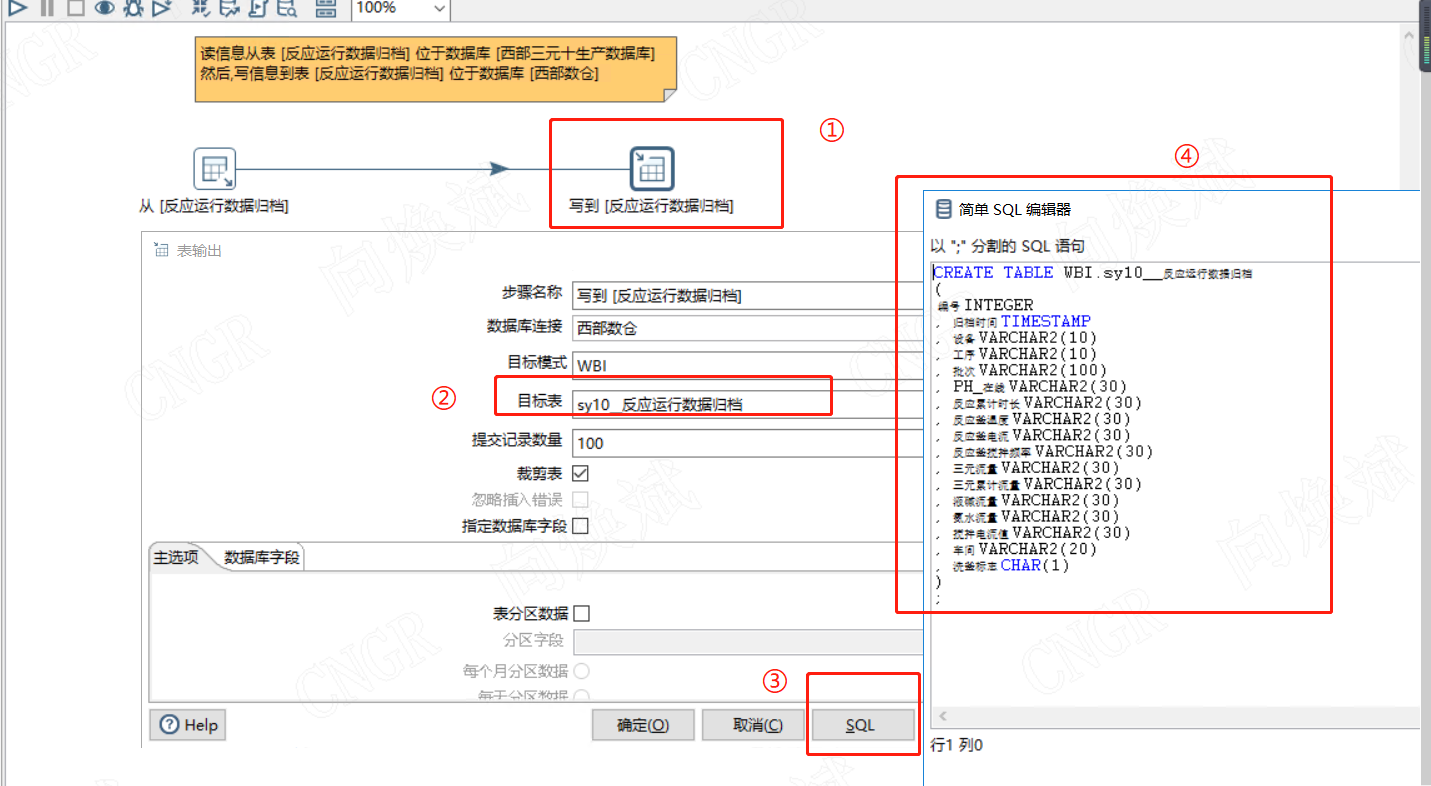
在上一步的跨库同步中,如果我们需要修改表名进行微雕时,我们直接修改目标表的名称,然后点击下面的SQL即可自动生成修改后的SQ语句点击执行即可。
2.2自动优化
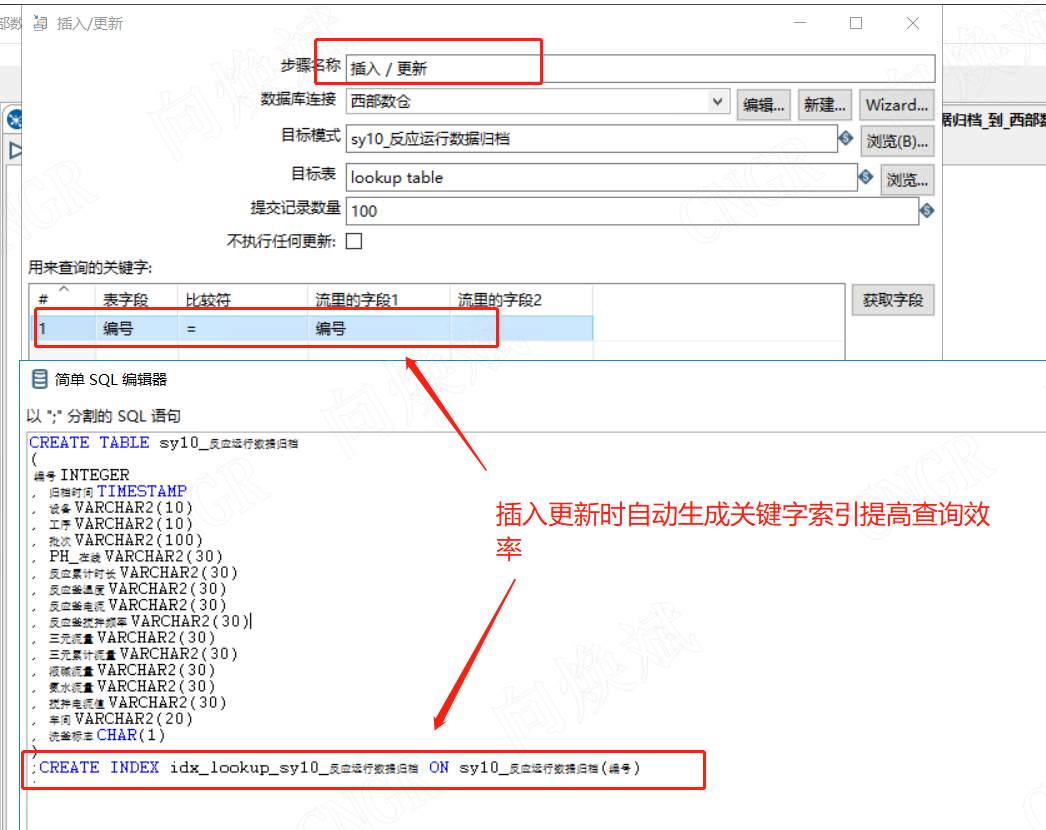
当我们抽取模式选择插入更新时,kettle会自动根据开发模式生成关键字索引来提高程序运行效率
三、总结
我们常用的程序和工具都在向智能化转型,当然设计之初也都傻瓜式处理了。chatGPT拥有数据整合的能力并将整合后的知识“高情商”的表达出来了,这就是它革命的点。但AI终究只是一个辅助工具,人类才是真正的高智商的存在,只是我们大部分的能力待开发而已。因此当AI潮水漫过膝盖时,不要慌张,这时候多想想大禹就好了。
版权归原作者 他们叫我技术总监 所有, 如有侵权,请联系我们删除。