
嗨,大家好,我是小萝卜算子。(微信公众号:数据仓库践行者。感谢关注)
首先先更新一下我的VIP群里的状态
日常答疑
飞书上的视频课程 也已经有条不紊的进行了。
欢迎有需要的小伙伴一起来搬砖。
下面开始今天的正题
Hive版本:hive-2.1.1
经常听到【谓词下推】这个词,却从来没有对它进行全面的深入的研究,直到前些天,我们的数据产品跑过来跟我讨论 他写的一个sql,这个sql最终出现的结果并不是他想要的。看了具体的sql后,引发了我的一些思考,决定来挖一挖谓词下推。
1、那个引人思考的sql
原sql业务比较复杂,我们用一些简单的测试数据复现场景。
创建两张表:
create table test1(id int,openid string) PARTITIONED BY ( day string ) STORED AS ORC;
create table test2(id int,openid string) PARTITIONED BY ( day string ) STORED AS ORC;
数据:
insert into table test1 partition (day='20190521') values(1,'apple');
insert into table test1 partition (day='20190521') values(2,'peach');
insert into table test2 partition (day='20190521') values(1,'apple');
insert into table test2 partition (day='20190521') values(3,'lemon');
数据产品跑过来跟我讨论的那个sql:
select
count(distinct case when b.openid is null then a.openid end) as n1,
count(distinct case when a.openid is null then b.openid end) as n2
from test2 a full join test1 b on a.openid = b.openid
where a.day = '20190521' and b.day = '20190521'
本意:想计算出20190521 这天,test1和test2表 openid字段各自己非交集的条数,如下图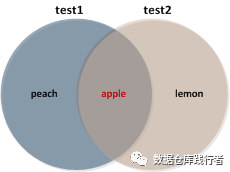
理想中的结果应该是 1,1
但实际上输出结果是:0,0
为什么呢?其实也不难判断
是使用者对该sql的执行顺序理解有误(Joins occur BEFOREWHERE CLAUSES)
这里需要明白一点, join之后的where决定了最终要呈现的数据
hive full join不管会不会进行谓词下推, where后面的a.day = ‘20190521’ and b.day = ‘20190521’ 的条件一定会在full join之后 过滤一遍,full join的中间结果如下:
在这样的结果中,计算a.day = ‘20190521’ and b.day = ‘20190521’ 条件下,a.openid为null的条数 及b.openid为null的条数,肯定都是0了
谓词下推复盘
上面那条sql引发的场景,实际上跟有没有进行谓词下推关系不大,但是这样的一个sql却引发我们的思考。
这次复盘的hive版本是 hive 2.1.1,不同的版本,对谓词下推做的优化有所不同,尤其是不同大版本间,相差比较多,比如:hive1.x和hive2.x。 当然,hive2.x相对于hive1.x是更智能,更优化了。
2.1 谓词
谓词下推概念中的谓词指返回bool值即true和false的函数,或是隐式转换为bool的函数,
比如:like ,is null,in,exists,=,!、= 这些返回bool值的函数
2.2 几个概念
2.2.1 Preserved Row table(保留表)
在outer join中需要返回所有数据的表叫做保留表,也就是说在left outer join中,左表需要返回所有数据,则左表是保留表;right outer join中右表则是保留表;在full outer join中左表和右表都要返回所有数据,则左右表都是保留表。
2.2.2 Null Supplying table(空表)
在outer join中对于没有匹配到的行需要用null来填充的表称为Null Supplying table。在left outer join中,左表的数据全返回,对于左表在右表中无法匹配的数据的相应列用null表示,则此时右表是Null Supplying table,相应的如果是right outer join的话,左表是Null Supplying table。但是在full outer join中左表和右表都是Null Supplying table,因为左表和右表都会用null来填充无法匹配的数据。
2.2.3 During Join predicate(Join中的谓词)
Join中的谓词是指 Join On语句中的谓词。如:R1 join R2 on R1.x = 5 the predicate R1.x = 5是Join中的谓词
2.2.4 After Join predicate(Join之后的谓词)
where语句中的谓词称之为Join之后的谓词
2.3 谓词下推
谓词下推的基本思想:将过滤表达式尽可能移动至靠近数据源的位置,以使真正执行时能直接跳过无关的数据。
在hive官网上给出了outer join【left outer join、right out join、full outer join】的谓下推规则: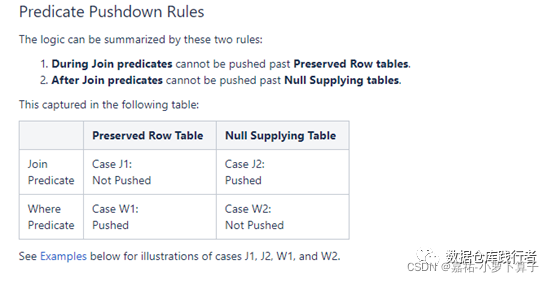
翻译一下 如下:
Join(只包括left join ,right join,full join)中的谓词如果是保留表的,则不会下推
Join(只包括left join ,right join,full join)之后的谓词如果是Null Supplying tables的,则不会下推
这种规则在hive2.x版本以后,就不是很准确了,hive2.x对CBO做了优化,CBO也对谓词下推规则产生了一些影响。
因此在hive2.1.1中影响谓词下推规则的,主要有两方面
- Hive逻辑执行计划层面的优化
- CBO 下面写例子来加深理解:
为了方便我们再往test1里插入几条数据
insert into table test1 partition (day='20190521') values(1,'pear');
insert into table test1 partition (day='20190521') values(2,'pear');
insert into table test1 partition (day='20190521') values(3,'banana');
在执行例子之前,避免map join影响到各个例子的执行计划,先关闭map join:
set hive.auto.convert.join=false;
set hive.cbo.enable=false;
case1 inner join 中的谓词
由于CBO对谓词下推也做了优化,我们在分析时,主要分析两部分,CBO功能关闭和开启,控制CBO的参数:hive.cbo.enable 在hive2版本中默认都是开启的 true
select t1.*,t2.* from test1 t1 join test2 t2 on t1.id=t2.id and t1.openid='pear'
and t2.openid='apple';
hive> set hive.cbo.enable=false;
hive> explain select t1.*,t2.* from test1 t1 join test2 t2 on t1.id=t2.id and t1.openid='pear' and t2.openid='apple';
OK
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: t1
Statistics: Num rows: 5 Data size: 465 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: ((openid = 'pear') and id is not null) (type: boolean)
Statistics: Num rows: 2 Data size: 186 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: id (type: int)
sort order: +
Map-reduce partition columns: id (type: int)
Statistics: Num rows: 2 Data size: 186 Basic stats: COMPLETE Column stats: NONE
value expressions: day (type: string)
TableScan
alias: t2
Statistics: Num rows: 2 Data size: 186 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: ((openid = 'apple') and id is not null) (type: boolean)
Statistics: Num rows: 1 Data size: 93 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: id (type: int)
sort order: +
Map-reduce partition columns: id (type: int)
Statistics: Num rows: 1 Data size: 93 Basic stats: COMPLETE Column stats: NONE
value expressions: day (type: string)
Reduce Operator Tree:
Join Operator
condition map:
Inner Join 0 to 1
keys:
0 id (type: int)
1 id (type: int)
outputColumnNames: _col0, _col2, _col6, _col8
Statistics: Num rows: 2 Data size: 204 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: int), 'pear' (type: string), _col2 (type: string), _col6 (type: int), 'apple' (type: string), _col8 (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5
Statistics: Num rows: 2 Data size: 204 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 2 Data size: 204 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
Time taken: 0.682 seconds, Fetched: 59 row(s)
hive> set hive.cbo.enable=true;
hive> explain select t1.*,t2.* from test1 t1 join test2 t2 on t1.id=t2.id and t1.openid='pear' and t2.openid='apple';
OK
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: t1
Statistics: Num rows: 5 Data size: 465 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: ((openid = 'pear') and id is not null) (type: boolean)
Statistics: Num rows: 2 Data size: 186 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: int), day (type: string)
outputColumnNames: _col0, _col2
Statistics: Num rows: 2 Data size: 186 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: int)
sort order: +
Map-reduce partition columns: _col0 (type: int)
Statistics: Num rows: 2 Data size: 186 Basic stats: COMPLETE Column stats: NONE
value expressions: _col2 (type: string)
TableScan
alias: t2
Statistics: Num rows: 2 Data size: 186 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: ((openid = 'apple') and id is not null) (type: boolean)
Statistics: Num rows: 1 Data size: 93 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: int), day (type: string)
outputColumnNames: _col0, _col2
Statistics: Num rows: 1 Data size: 93 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: int)
sort order: +
Map-reduce partition columns: _col0 (type: int)
Statistics: Num rows: 1 Data size: 93 Basic stats: COMPLETE Column stats: NONE
value expressions: _col2 (type: string)
Reduce Operator Tree:
Join Operator
condition map:
Inner Join 0 to 1
keys:
0 _col0 (type: int)
1 _col0 (type: int)
outputColumnNames: _col0, _col2, _col3, _col5
Statistics: Num rows: 2 Data size: 204 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: int), 'pear' (type: string), _col2 (type: string), _col3 (type: int), 'apple' (type: string), _col5 (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5
Statistics: Num rows: 2 Data size: 204 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 2 Data size: 204 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
Time taken: 0.704 seconds, Fetched: 67 row(s)
从执行计划上来看,hive对join的谓下推优化做的很到位,不管有没有开启CBO优化,在on中的两个条件都提至table scan阶段进行过滤。 实际上,这个也是因为join的特殊性,要求左表和右表必须完全匹配,这个也为做优化提供了可能性。
case2 inner join 之后的谓词
select t1.*,t2.* from test1 t1 join test2 t2 on t1.id=t2.id where t1.openid='pear'
and t2.openid='apple';
inner join之后的谓词 与 inner join之中的谓词的效果是完全一样的,很容易理解,执行计划如下:
hive> set hive.cbo.enable=false;
hive> explain select t1.*,t2.* from test1 t1 join test2 t2 on t1.id=t2.id where t1.openid='pear' and t2.openid='apple';
OK
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: t1
Statistics: Num rows: 5 Data size: 465 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: (id is not null and (openid = 'pear')) (type: boolean)
Statistics: Num rows: 2 Data size: 186 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: id (type: int)
sort order: +
Map-reduce partition columns: id (type: int)
Statistics: Num rows: 2 Data size: 186 Basic stats: COMPLETE Column stats: NONE
value expressions: day (type: string)
TableScan
alias: t2
Statistics: Num rows: 2 Data size: 186 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: (id is not null and (openid = 'apple')) (type: boolean)
Statistics: Num rows: 1 Data size: 93 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: id (type: int)
sort order: +
Map-reduce partition columns: id (type: int)
Statistics: Num rows: 1 Data size: 93 Basic stats: COMPLETE Column stats: NONE
value expressions: day (type: string)
Reduce Operator Tree:
Join Operator
condition map:
Inner Join 0 to 1
keys:
0 id (type: int)
1 id (type: int)
outputColumnNames: _col0, _col2, _col6, _col8
Statistics: Num rows: 2 Data size: 204 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: int), 'pear' (type: string), _col2 (type: string), _col6 (type: int), 'apple' (type: string), _col8 (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5
Statistics: Num rows: 2 Data size: 204 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 2 Data size: 204 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
Time taken: 0.41 seconds, Fetched: 59 row(s)
hive> set hive.cbo.enable=true;
hive> explain select t1.*,t2.* from test1 t1 join test2 t2 on t1.id=t2.id where t1.openid='pear' and t2.openid='apple';
OK
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: t1
Statistics: Num rows: 5 Data size: 465 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: ((openid = 'pear') and id is not null) (type: boolean)
Statistics: Num rows: 2 Data size: 186 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: int), day (type: string)
outputColumnNames: _col0, _col2
Statistics: Num rows: 2 Data size: 186 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: int)
sort order: +
Map-reduce partition columns: _col0 (type: int)
Statistics: Num rows: 2 Data size: 186 Basic stats: COMPLETE Column stats: NONE
value expressions: _col2 (type: string)
TableScan
alias: t2
Statistics: Num rows: 2 Data size: 186 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: ((openid = 'apple') and id is not null) (type: boolean)
Statistics: Num rows: 1 Data size: 93 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: int), day (type: string)
outputColumnNames: _col0, _col2
Statistics: Num rows: 1 Data size: 93 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: int)
sort order: +
Map-reduce partition columns: _col0 (type: int)
Statistics: Num rows: 1 Data size: 93 Basic stats: COMPLETE Column stats: NONE
value expressions: _col2 (type: string)
Reduce Operator Tree:
Join Operator
condition map:
Inner Join 0 to 1
keys:
0 _col0 (type: int)
1 _col0 (type: int)
outputColumnNames: _col0, _col2, _col3, _col5
Statistics: Num rows: 2 Data size: 204 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: int), 'pear' (type: string), _col2 (type: string), _col3 (type: int), 'apple' (type: string), _col5 (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5
Statistics: Num rows: 2 Data size: 204 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 2 Data size: 204 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
Time taken: 0.462 seconds, Fetched: 67 row(s)
case3 left join 中的谓词
select t1.*,t2.* from test1 t1 left join test2 t2 on t1.id=t2.id and t1.openid='pear'
and t2.openid='apple';
hive> set hive.cbo.enable=false;
hive> explain select t1.*,t2.* from test1 t1 left join test2 t2 on t1.id=t2.id and t1.openid='pear'
> and t2.openid='apple';
OK
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: t1
Statistics: Num rows: 5 Data size: 465 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: id (type: int)
sort order: +
Map-reduce partition columns: id (type: int)
Statistics: Num rows: 5 Data size: 465 Basic stats: COMPLETE Column stats: NONE
value expressions: openid (type: string), day (type: string)
TableScan
alias: t2
Statistics: Num rows: 2 Data size: 186 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: (openid = 'apple') (type: boolean)
Statistics: Num rows: 1 Data size: 93 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: id (type: int)
sort order: +
Map-reduce partition columns: id (type: int)
Statistics: Num rows: 1 Data size: 93 Basic stats: COMPLETE Column stats: NONE
value expressions: openid (type: string), day (type: string)
Reduce Operator Tree:
Join Operator
condition map:
Left Outer Join0 to 1
filter predicates:
0 {(VALUE._col0 = 'pear')}
1
keys:
0 id (type: int)
1 id (type: int)
outputColumnNames: _col0, _col1, _col2, _col6, _col7, _col8
Statistics: Num rows: 5 Data size: 511 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: int), _col1 (type: string), _col2 (type: string), _col6 (type: int), _col7 (type: string), _col8 (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5
Statistics: Num rows: 5 Data size: 511 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 5 Data size: 511 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
Time taken: 0.237 seconds, Fetched: 59 row(s)
在hive.cbo.enable=false的情况下,执行计划如上图,test2表进行了谓词下推,将predicate: (openid = ‘apple’) (type: boolean)过滤件 放在table scan之后。 在这里,test1为保留表,符合【Join(只包括left join ,right join,full join)中的谓词如果是保留表的,则不会下推】 ,test2进行了下推。
查询的过程:遍历test1所有的数据,提取test2中openid为apple的数据,该条数据即为:
1 apple 20190521
然后,拿test1中 openid为pear的数据与test2表中的这条关联,关联上的就展示,关联不上的,补null;另外,test1中的openid不为pear的数据不与test2表做关联,直接补null。。。
因此,执行结果如下: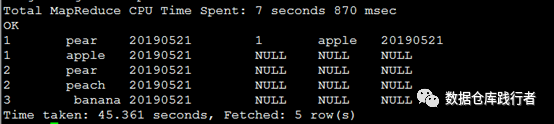
由于join中谓词执行过程的特殊性,CBO也不可能再做什么优化,因此,打开CBO开关,执行计划不变:
hive> set hive.cbo.enable=true;
hive> explain select t1.*,t2.* from test1 t1 left join test2 t2 on t1.id=t2.id and t1.openid='pear'
> and t2.openid='apple';
OK
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: t1
Statistics: Num rows: 5 Data size: 465 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: int), openid (type: string), day (type: string)
outputColumnNames: _col0, _col1, _col2
Statistics: Num rows: 5 Data size: 465 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: int)
sort order: +
Map-reduce partition columns: _col0 (type: int)
Statistics: Num rows: 5 Data size: 465 Basic stats: COMPLETE Column stats: NONE
value expressions: _col1 (type: string), _col2 (type: string)
TableScan
alias: t2
Statistics: Num rows: 2 Data size: 186 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: (openid = 'apple') (type: boolean)
Statistics: Num rows: 1 Data size: 93 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: int), 'apple' (type: string), day (type: string)
outputColumnNames: _col0, _col1, _col2
Statistics: Num rows: 1 Data size: 93 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: int)
sort order: +
Map-reduce partition columns: _col0 (type: int)
Statistics: Num rows: 1 Data size: 93 Basic stats: COMPLETE Column stats: NONE
value expressions: _col1 (type: string), _col2 (type: string)
Reduce Operator Tree:
Join Operator
condition map:
Left Outer Join0 to 1
filter predicates:
0 {(VALUE._col0 = 'pear')}
1
keys:
0 _col0 (type: int)
1 _col0 (type: int)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5
Statistics: Num rows: 5 Data size: 511 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 5 Data size: 511 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
Time taken: 0.383 seconds, Fetched: 63 row(s)
case4 left join 之后的谓词
select t1.*,t2.* from test1 t1 left join test2 t2 on t1.id=t2.id where t1.openid='pear'
and t2.openid='apple';
hive> set hive.cbo.enable=false;
hive> explain select t1.*,t2.* from test1 t1 left join test2 t2 on t1.id=t2.id where t1.openid='pear' and t2.openid='apple';
OK
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: t1
Statistics: Num rows: 5 Data size: 465 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: (openid = 'pear') (type: boolean)
Statistics: Num rows: 2 Data size: 186 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: id (type: int)
sort order: +
Map-reduce partition columns: id (type: int)
Statistics: Num rows: 2 Data size: 186 Basic stats: COMPLETE Column stats: NONE
value expressions: day (type: string)
TableScan
alias: t2
Statistics: Num rows: 2 Data size: 186 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: id (type: int)
sort order: +
Map-reduce partition columns: id (type: int)
Statistics: Num rows: 2 Data size: 186 Basic stats: COMPLETE Column stats: NONE
value expressions: openid (type: string), day (type: string)
Reduce Operator Tree:
Join Operator
condition map:
Left Outer Join0 to 1
keys:
0 id (type: int)
1 id (type: int)
outputColumnNames: _col0, _col2, _col6, _col7, _col8
Statistics: Num rows: 2 Data size: 204 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: (_col7 = 'apple') (type: boolean)
Statistics: Num rows: 1 Data size: 102 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: int), 'pear' (type: string), _col2 (type: string), _col6 (type: int), 'apple' (type: string), _col8 (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5
Statistics: Num rows: 1 Data size: 102 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 1 Data size: 102 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
Time taken: 0.213 seconds, Fetched: 59 row(s)
屏蔽掉CBO对谓词下推的影响后,从执行计划中我们可以看到,对test1进行了下推,将predicate: (openid = ‘pear’) (type: boolean)过滤条件下推到 tablescan处进行;而test2没有下推,最后是在 join之后,才进行了 predicate: (_col7 = ‘apple’) (type: boolean)过滤。这个也符合【 Join之后的谓词如果是 Null Supplying tables的,则不会下推】。
但是,我们会发现, join之后的 where无论怎样都是要过滤一遍的,这里的test2实际上是可以下推的,下推了会更优化,也不会改变最终的结果。
hive> set hive.cbo.enable=true;
hive> explain select t1.*,t2.* from test1 t1 left join test2 t2 on t1.id=t2.id where t1.openid='pear' and t2.openid='apple';
OK
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: t1
Statistics: Num rows: 5 Data size: 465 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: ((openid = 'pear') and id is not null) (type: boolean)
Statistics: Num rows: 2 Data size: 186 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: int), day (type: string)
outputColumnNames: _col0, _col2
Statistics: Num rows: 2 Data size: 186 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: int)
sort order: +
Map-reduce partition columns: _col0 (type: int)
Statistics: Num rows: 2 Data size: 186 Basic stats: COMPLETE Column stats: NONE
value expressions: _col2 (type: string)
TableScan
alias: t2
Statistics: Num rows: 2 Data size: 186 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: ((openid = 'apple') and id is not null) (type: boolean)
Statistics: Num rows: 1 Data size: 93 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: int), day (type: string)
outputColumnNames: _col0, _col2
Statistics: Num rows: 1 Data size: 93 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: int)
sort order: +
Map-reduce partition columns: _col0 (type: int)
Statistics: Num rows: 1 Data size: 93 Basic stats: COMPLETE Column stats: NONE
value expressions: _col2 (type: string)
Reduce Operator Tree:
Join Operator
condition map:
Inner Join 0 to 1
keys:
0 _col0 (type: int)
1 _col0 (type: int)
outputColumnNames: _col0, _col2, _col3, _col5
Statistics: Num rows: 2 Data size: 204 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: int), 'pear' (type: string), _col2 (type: string), _col3 (type: int), 'apple' (type: string), _col5 (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5
Statistics: Num rows: 2 Data size: 204 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 2 Data size: 204 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
Time taken: 0.513 seconds, Fetched: 67 row(s)
打CBO开关 set hive.cbo.enable=true 后,我们会发现,test2也进行了谓词下推,做到了更优化
case5 full join 中的谓词
select t1.*,t2.* from test1 t1 full join test2 t2 on t1.id=t2.id and t1.openid='pear'
and t2.openid='apple';
hive> set hive.cbo.enable=false;
hive> explain select t1.*,t2.* from test1 t1 full join test2 t2 on t1.id=t2.id and t1.openid='pear' and t2.openid='apple';
OK
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: t1
Statistics: Num rows: 5 Data size: 465 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: id (type: int)
sort order: +
Map-reduce partition columns: id (type: int)
Statistics: Num rows: 5 Data size: 465 Basic stats: COMPLETE Column stats: NONE
value expressions: openid (type: string), day (type: string)
TableScan
alias: t2
Statistics: Num rows: 2 Data size: 186 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: id (type: int)
sort order: +
Map-reduce partition columns: id (type: int)
Statistics: Num rows: 2 Data size: 186 Basic stats: COMPLETE Column stats: NONE
value expressions: openid (type: string), day (type: string)
Reduce Operator Tree:
Join Operator
condition map:
Outer Join 0 to 1
filter predicates:
0 {(VALUE._col0 = 'pear')}
1 {(VALUE._col0 = 'apple')}
keys:
0 id (type: int)
1 id (type: int)
outputColumnNames: _col0, _col1, _col2, _col6, _col7, _col8
Statistics: Num rows: 5 Data size: 511 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: int), _col1 (type: string), _col2 (type: string), _col6 (type: int), _col7 (type: string), _col8 (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5
Statistics: Num rows: 5 Data size: 511 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 5 Data size: 511 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
Time taken: 0.308 seconds, Fetched: 56 row(s)
full join 的左右表很矛盾,即是保留表,也是 Null Supplying tables。 但是有一条不变,就是左右表的数据都一定是要保留表下来的,因此也不难理解,这里为什么不能进行谓词下推,只要下推了,就不能保证两个表的数据都保留。。。
这也算是符合了【 Join(只包括 left join ,right join,full join)中的谓词如果是保留表的,则不会下推】
解释一下数据结果: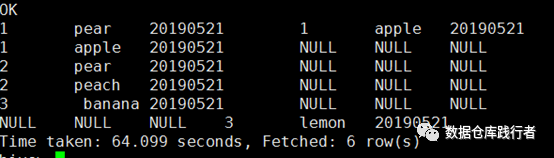
test1, test2 两个表全遍历,test1表 拿 openid为 pear的与test2表中的数据关联,其它 openid不为 pear的 ,test2表直接补 null。 而test2 表拿 openid为 apple的与test1表中的数据关联,其它 openid不为 apple的,test1 表直接补 null。
基于我们对full join的理解,打开CBO开关,也不会做谓词下推的优化:
hive> set hive.cbo.enable=true;
hive> explain select t1.*,t2.* from test1 t1 full join test2 t2 on t1.id=t2.id and t1.openid='pear' and t2.openid='apple';
OK
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: t1
Statistics: Num rows: 5 Data size: 465 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: int), openid (type: string), day (type: string)
outputColumnNames: _col0, _col1, _col2
Statistics: Num rows: 5 Data size: 465 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: int)
sort order: +
Map-reduce partition columns: _col0 (type: int)
Statistics: Num rows: 5 Data size: 465 Basic stats: COMPLETE Column stats: NONE
value expressions: _col1 (type: string), _col2 (type: string)
TableScan
alias: t2
Statistics: Num rows: 2 Data size: 186 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: int), openid (type: string), day (type: string)
outputColumnNames: _col0, _col1, _col2
Statistics: Num rows: 2 Data size: 186 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: int)
sort order: +
Map-reduce partition columns: _col0 (type: int)
Statistics: Num rows: 2 Data size: 186 Basic stats: COMPLETE Column stats: NONE
value expressions: _col1 (type: string), _col2 (type: string)
Reduce Operator Tree:
Join Operator
condition map:
Outer Join 0 to 1
filter predicates:
0 {(VALUE._col0 = 'pear')}
1 {(VALUE._col0 = 'apple')}
keys:
0 _col0 (type: int)
1 _col0 (type: int)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5
Statistics: Num rows: 5 Data size: 511 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 5 Data size: 511 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
Time taken: 0.321 seconds, Fetched: 60 row(s)
case6 full join 之后的谓词
select t1.*,t2.* from test1 t1 full join test2 t2 on t1.id=t2.id where t1.openid='pear'
and t2.openid='apple';
hive> set hive.cbo.enable=false;
hive> explain select t1.*,t2.* from test1 t1 full join test2 t2 on t1.id=t2.id where t1.openid='pear' and t2.openid='apple';
OK
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: t1
Statistics: Num rows: 5 Data size: 465 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: id (type: int)
sort order: +
Map-reduce partition columns: id (type: int)
Statistics: Num rows: 5 Data size: 465 Basic stats: COMPLETE Column stats: NONE
value expressions: openid (type: string), day (type: string)
TableScan
alias: t2
Statistics: Num rows: 2 Data size: 186 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: id (type: int)
sort order: +
Map-reduce partition columns: id (type: int)
Statistics: Num rows: 2 Data size: 186 Basic stats: COMPLETE Column stats: NONE
value expressions: openid (type: string), day (type: string)
Reduce Operator Tree:
Join Operator
condition map:
Outer Join 0 to 1
keys:
0 id (type: int)
1 id (type: int)
outputColumnNames: _col0, _col1, _col2, _col6, _col7, _col8
Statistics: Num rows: 5 Data size: 511 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: ((_col1 = 'pear') and (_col7 = 'apple')) (type: boolean)
Statistics: Num rows: 1 Data size: 102 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: int), 'pear' (type: string), _col2 (type: string), _col6 (type: int), 'apple' (type: string), _col8 (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5
Statistics: Num rows: 1 Data size: 102 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 1 Data size: 102 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
Time taken: 0.274 seconds, Fetched: 56 row(s)
关掉CBO开关,我们会发现,没有进行谓词下推的优化,而是在 full join之后,做了 predicate: ((_col1 = ‘pear’) and (_col7 = ‘apple’)) (type: boolean)的过滤,这也符合【Join(只包括 left join ,right join,full join)之后的谓词如果是 Null Supplying tables的,则不会下推】这一规则,毕竟test1,test2也属于 Null Supplying tables 。
实际上,这里是可以下推的,与 left join同理,下推后,不影响最后的结果:
hive> set hive.cbo.enable=true;
hive> explain select t1.*,t2.* from test1 t1 full join test2 t2 on t1.id=t2.id where t1.openid='pear' and t2.openid='apple';
OK
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: t1
Statistics: Num rows: 5 Data size: 465 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: ((openid = 'pear') and id is not null) (type: boolean)
Statistics: Num rows: 2 Data size: 186 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: int), day (type: string)
outputColumnNames: _col0, _col2
Statistics: Num rows: 2 Data size: 186 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: int)
sort order: +
Map-reduce partition columns: _col0 (type: int)
Statistics: Num rows: 2 Data size: 186 Basic stats: COMPLETE Column stats: NONE
value expressions: _col2 (type: string)
TableScan
alias: t2
Statistics: Num rows: 2 Data size: 186 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: ((openid = 'apple') and id is not null) (type: boolean)
Statistics: Num rows: 1 Data size: 93 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: int), day (type: string)
outputColumnNames: _col0, _col2
Statistics: Num rows: 1 Data size: 93 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: int)
sort order: +
Map-reduce partition columns: _col0 (type: int)
Statistics: Num rows: 1 Data size: 93 Basic stats: COMPLETE Column stats: NONE
value expressions: _col2 (type: string)
Reduce Operator Tree:
Join Operator
condition map:
Inner Join 0 to 1
keys:
0 _col0 (type: int)
1 _col0 (type: int)
outputColumnNames: _col0, _col2, _col3, _col5
Statistics: Num rows: 2 Data size: 204 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: int), 'pear' (type: string), _col2 (type: string), _col3 (type: int), 'apple' (type: string), _col5 (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5
Statistics: Num rows: 2 Data size: 204 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 2 Data size: 204 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
Time taken: 0.606 seconds, Fetched: 67 row(s)
打开CBO开关,两表都进行了下推
结论
经过上面的案例分析,我们可以给出结论了,这里没有分析right join,因为right jion和left join原理是一样的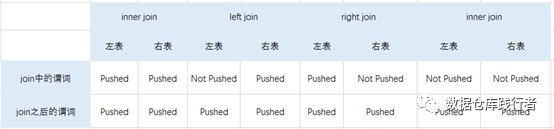
版权归原作者 嘉祐-小萝卜算子 所有, 如有侵权,请联系我们删除。