
安装步骤
按照本文的步骤一步一步做完,你就可以实现将本地代码通过docker上传到阿里云镜像上,以及通过docker从阿里云镜像下拉代码到本地中运行。
一、docker的安装和云端的推送
1.本地安装docker工具
ubutun环境下
1输入以下代码以安装docker工具
sudoaptinstall docker.io
 2.安装Nvidia-docker,为自己的docker做GPU服务器环境搭建
2.安装Nvidia-docker,为自己的docker做GPU服务器环境搭建
# Add the package repositoriesdistribution=$(. /etc/os-release;echo $ID$VERSION_ID)curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey |sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list |sudotee /etc/apt/sources.list.d/nvidia-docker.list
sudoapt-get update &&sudoapt-getinstall -y nvidia-container-toolkit
sudo systemctl restart docker
centos环境下
注:以下内容部分选取了:linux centos7 docker GPU服务器环境搭建,如果前面安装过程遇到问题,可以按照原文操作从头来一遍。
1.卸载旧版本(如果没有可忽略)
sudo yum remove docker\
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
2.下载安装包
sudo yum install -y yum-utils
sudo yum-config-manager \
--add-repo \
https://download.docker.com/linux/centos/docker-ce.repo
3.做相关配置
sudo yum-config-manager --enable docker-ce-nightly
sudo yum-config-manager --enable docker-ce-test
4.安装docker Engine
sudo yum install docker-ce docker-ce-cli containerd.io
5.启动docker
sudo systemctl start docker
6.验证docker是否安装成功
sudodocker run hello-world
按下图所示输出表示安装成功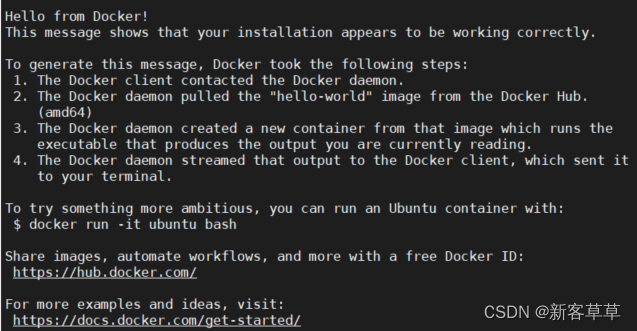
7.安装Nvidia-docker
7.1安装依赖
sudo yum install dnf
sudo dnf install -y tarbzip2make automake gcc gcc-c++ vim pciutils elfutils-libelf-devel libglvnd-devel iptables
7.2安装docker CE
sudo yum-config-manager --add-repo=https://download.docker.com/linux/centos/docker-ce.repo
sudo yum repolist -v
sudo yum install -y https://download.docker.com/linux/centos/7/x86_64/stable/Packages/containerd.io-1.4.3-3.1.el7.x86_64.rpm
sudo yum install docker-ce -y
sudo systemctl --now enabledockersudodocker run --rm hello-world
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)\&&curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.repo |sudotee /etc/yum.repos.d/nvidia-docker.repo
sudo yum clean expire-cache
sudo yum install -y nvidia-docker2
sudo systemctl restart dockersudodocker run --rm --gpus all nvidia/cuda:10.1-base nvidia-smi
以下输出表示docker的NVIDIA驱动安装成功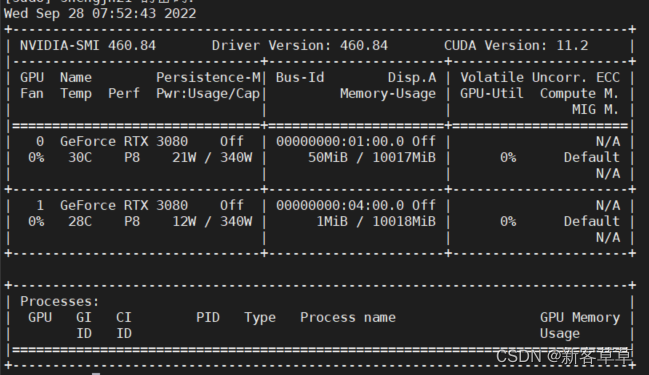
2.创建镜像仓库
这里以申请阿里云容器镜像服务(免费),并创建仓库为例,其他仓库如dockerhub、谷歌、亚马逊、腾讯等详见对应产品说明书。我们建议用阿里云容器镜像服务。
阿里云容器服务地址为https://cr.console.aliyun.com,注册开通后产品页面如下:
第一步切换标签页到命名空间,创建地址唯一的命名空间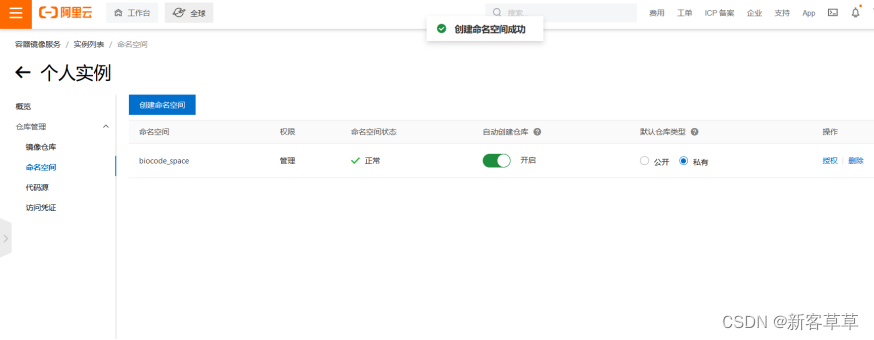
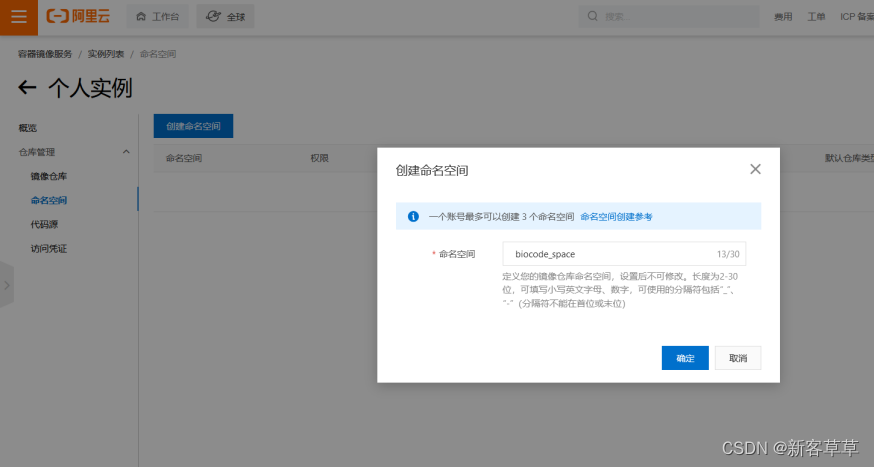 在选择地域时,可以按照距离自己最近的地方
在选择地域时,可以按照距离自己最近的地方
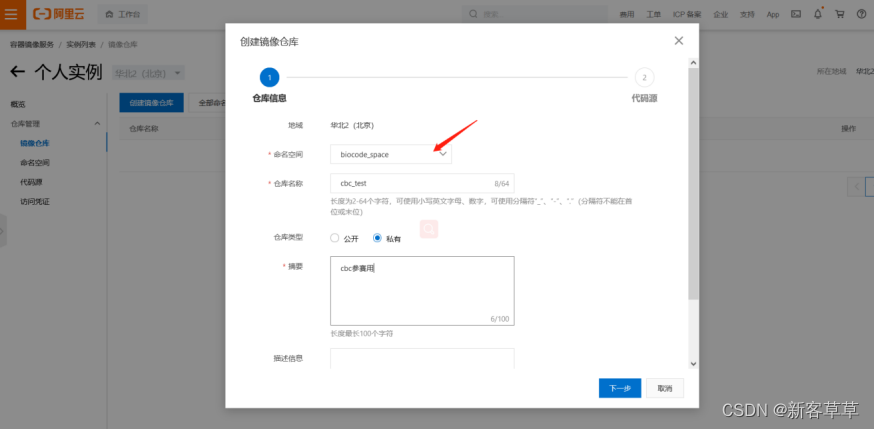
下一步,选择本地仓库,不建议其他选项,完成创建。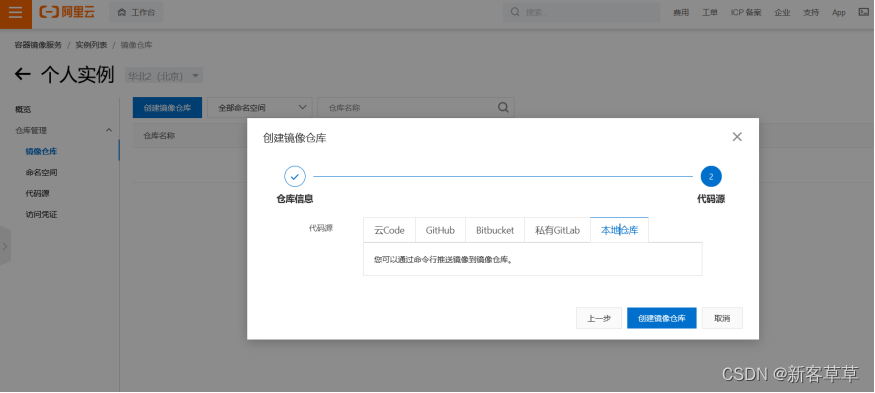 点击管理,可查看详情。
点击管理,可查看详情。 详情页如下,有基本的操作命令,仓库地址一般使用公网地址即可。
详情页如下,有基本的操作命令,仓库地址一般使用公网地址即可。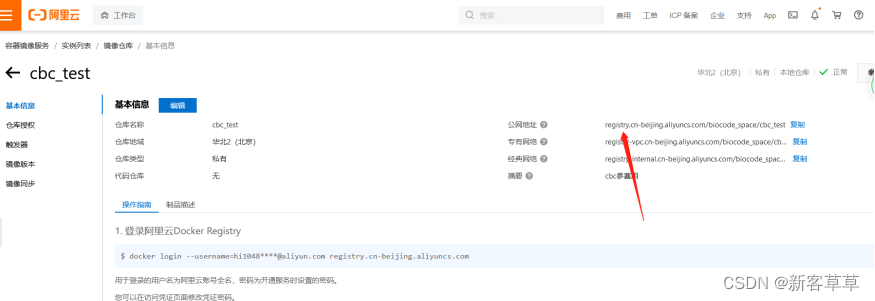 注意一下 如果是后面docker登录时,用到的用户名就是阿里云帐号,密码要自己在信息中生成,如下图
注意一下 如果是后面docker登录时,用到的用户名就是阿里云帐号,密码要自己在信息中生成,如下图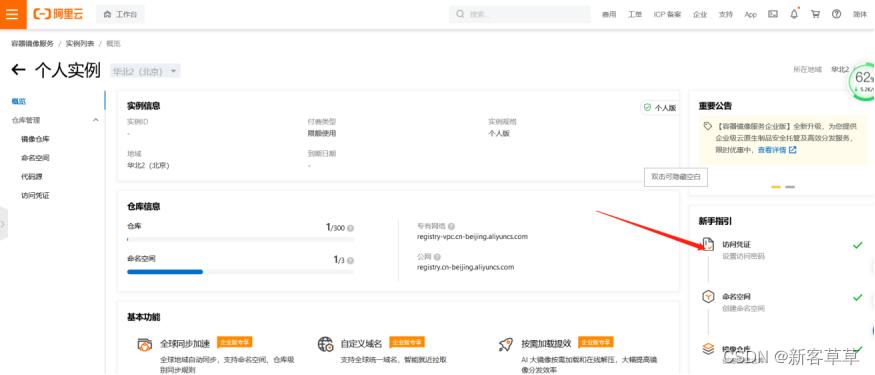
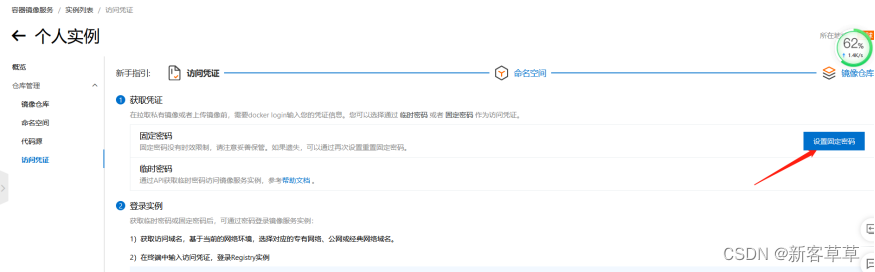 按照页面的指令在本地完成登陆:
按照页面的指令在本地完成登陆:
exportDOCKER_REGISTRY= your_registry_url<docker registry url>docker login $DOCKER_REGISTRY\
--username your_username \
--password your_password
注:上面代码中的your_registry_url是下图中红框部分的内容
your_username是你申请阿里云容器时给你的账号,一般都是:aliyun12435543…形式
your_password是你的密码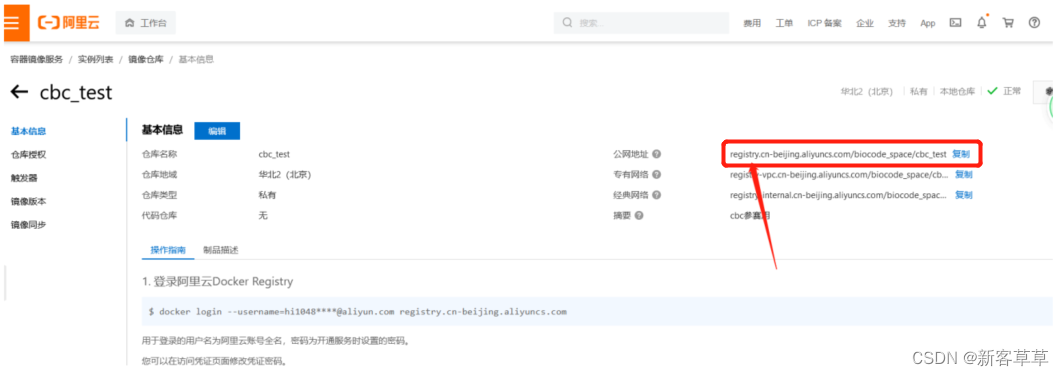
3.构建docker镜像,并push到云端
所需文件的准备
我们需要先把自己的项目生成docker镜像,最后通过push提交到云端。
新建一个目录用来构建docker镜像,这里为了演示,使用’cbc_test’来命名:
①bert.py:自己项目的源代码
②requirement.txt:在bert.py文件所在目录下,使用
pip freeze > requirements.txt
命令将自己项目所依赖的包导出,名字为requirement.txt,打开如下图,
④Dockerfile文件:首先打开当前目录的终端,输入
vim Dockerfile
然后在Dockerfile文件里输入
# 基于的基础镜像
FROM python:3.8.12
# 将自己的项目文件复制到容器的 /code 目录下
ADD . /code
# 设置code文件夹是工作目录
WORKDIR /code
# 安装支持
RUN pip installtorch==1.9.0+cu111 torchvision==0.10.0+cu111 torchaudio==0.9.0 -f https://download.pytorch.org/whl/torch_stable.html
RUN pip install -r requirements.txt
# Run hello.py when the container launches
CMD ["python", "bert.py"]
这里的两个RUN pip都是为我们要上传的镜像做环境配置,包括代码运行需要的所有包
⑤model.pth,MASKED_IN.fasta等等:运行代码所需要的所有其他文件
将上面提到的5个文件等复制到cbc_test目录下,如下图所示: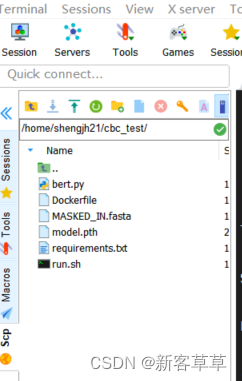
镜像的构建和PUSH到云端
在刚刚的cbc_test目录的终端下,执行命令
sudodocker build -t [ImageId].
这里的[ImageId]表示你在本地构建的镜像,比如你希望本地的镜像名是project,那么这段代码就可以改为
sudodocker build -t project .
注:最后有个‘.’不要省略,直接复制我的代码即可。
当按照下文提示完成后,本地镜像就构建好了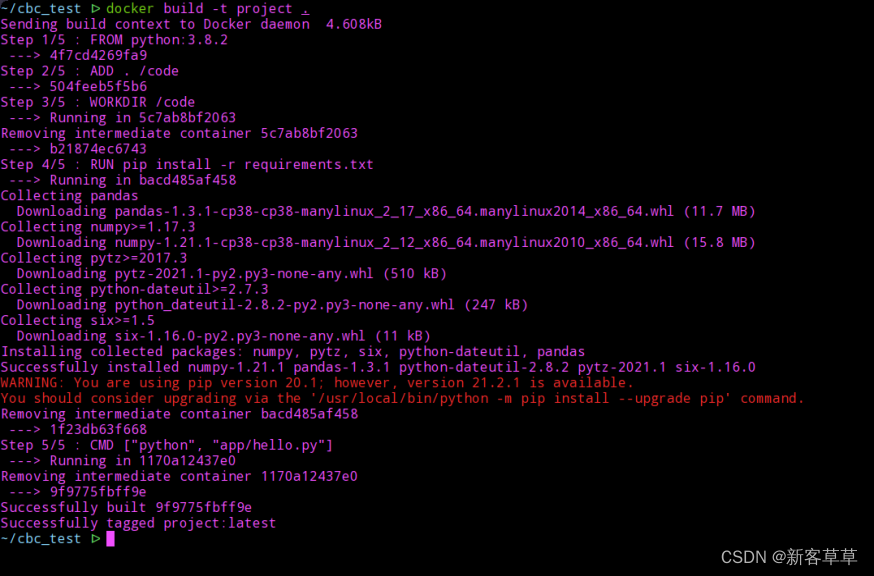 输入
输入
sudodocker images
可以查看刚才本地构建的所有镜像 最后将本地的镜像push到云端(阿里云镜像)
最后将本地的镜像push到云端(阿里云镜像)
sudodocker tag [ImageId]$DOCKER_REGISTRY:[镜像版本号]sudodocker push $DOCKER_REGISTRY:[镜像版本号]
这里的$DOCKER_REGISTRY我们在前面已经设置过了(创建镜像仓库那里有提到),[ImageId]的设置还是和之前一样(这里指的是你希望上传的本地镜像),镜像版本号可以自己设定(比如你是第一次发布该镜像,那么可以设置为v1.0,第二次就是v2.0。当然你也可以设置成latest,如果不设置好像默认也是latest)
比如我下面的例子
sudodocker tag project $DOCKER_REGISTRY:latest # 为本地的镜像打标签,注意DOCKER_REGISTRY=registry.cn-beijing.aliyuncs.com/sjh_biocode_space/cbc_test sudodocker push $DOCKER_REGISTRY:latest # 将镜像上传到阿里云
push成功之后,可以在阿里云镜像的网站中查看到刚刚推送的镜像: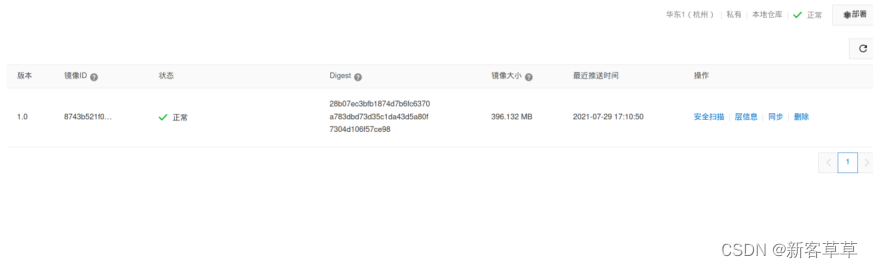 至此推送就完成了!
至此推送就完成了!
二、云端镜像的本地使用
例如我们刚刚推动上去的镜像中有一个bert.py文件,现在我们的本地有一个pull.sh文件,该文件可以调用名为bert.py的文件,现在我们要用这个pull.sh文件调用云端镜像中的bery.py文件,那么可以在该pull.sh文件所在文件目录中进行如下操作:
bash pull.sh your_usename your_password $DOCKER_REGISTRY:latest
如果前面的步骤都正确的话,那么此时会成功运行bert.py这个文件(不需要我们提前配置环境之类的)
三、附录:docker常用命令的总结
1.镜像的删除
注:删除镜像前必须先停用容器
全部删除
#停用全部运行中的容器:docker stop $(dockerps -q)#删除全部容器:dockerrm$(dockerps -aq)#删除所有镜像docker rmi -f $(docker images -qa)
部分删除
#停用某个运行中的容器:docker stop 容器id
#删除某个容器:dockerrm 容器id
#删除某个镜像docker rmi -f 镜像id
2.进入无法运行的镜像
如果一个镜像有问题,那么在启动这个镜像的容器时,会自动抛出异常然后结束容器,我们无法进入容器对这个镜像进行修改,也即如果一个容器已经stop,那么我们无法通过docker exec进入,会提示:Error response from daemon: Container 837ffa1d4…is not running
下面提供一种解决方案:
找到想要进入的容器id, 假设是 837ffa1d4
#如果是构建镜像时失败可以通过日志找到容器iddockerps -a
#保存"案发现场"为镜像docker commit 837ffa1d4 user/temp
#这里随便起一个镜像名称就行.#启动新容器docker run -it user/temp sh
3.问题记录
docker 运行ImportError: libtinfo.so.5: cannot
运行下面代码
yum update
yum install libgl1-mesa-glx
yum -c /etc/yum.conf --installroot=/usr/local --releasever=/ install love
查看镜像能否使用GPU
运行下面代码
sudodocker run --rm --gpus all nvidia/cuda:10.1-base nvidia-smi
弹出GPU信息则表示可以使用GPU
dockerfile文件
dockerfile文件中的RUN pip后面是主代码运行所需要安装的环境,如果requirement.txt中不全的话,可以自己加入需要的环境对应的包,以及这些包的源,如下所示
RUN pip install -r requirements.txt # 这是安装自动生成的requirement.txt里的包
RUN pip installtorch==1.9.0+cu111 torchvision==0.10.0+cu111 torchaudio==0.9.0 -f https://download.pytorch.org/whl/torch_stable.html # 这是自己补充的包,最后的网站是这些包的源
版权归原作者 新客草草 所有, 如有侵权,请联系我们删除。