
生产者调优、硬件选择:
假设:100万日活,每人每天 100 条日志,每天总共的日志条数是 100 万 * 100 条 = 1 亿条
处理速度=1亿/(24*3600s)=1150条/s
一条日志按1k计算,1150 条/每秒钟 * 1k ≈ 1m/s 。
高峰期每秒钟:1150 条 * 20 倍 = 23000 条。数据量:20MB/s
服务器台数选择:
服务器台数= 2 * (生产者峰值生产速率 * 副本 / 100) + 1 = 2 * (20m/s * 2 / 100) + 1 = 3 台
磁盘选择:kafka 底层主要是顺序写,固态硬盘和机械硬盘的顺序写速度差不多
每天总数据量:1 亿条 * 1k ≈ 100g
100g * 副本 2 * 保存时间 3 天 / 0.7 ≈ 1T
建议三台服务器硬盘总大小,大于等于 1T
内存选择:堆内存 + 页缓存
kafka 堆内存建议每个节点:10g ~ 15g,默认是1g
堆内存修改方式
在 kafka-server-start.sh 中修改
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx10G -Xms10G"
fi
查看 Kafka 的 GC 情况,次数少则不用修改
#Kafka 进程号
jps
#查看 Kafka 的 GC 情况
jstat -gc 进程 ls 10
查看内存使用率
jmap -heap 进程号
配置页缓存
页缓存是 Linux 系统服务器的内存。我们只需要保证 1 个 segment(1g)中 25%的数据在内存中就好
每个节点页缓存大小 =(分区数 * 1g * 25%)/ 节点数。例如 10 个分区,页缓存大小 =(10 * 1g * 25%)/ 3 ≈ 1g
CPU 选择
kafka中最占cpu的三个线程,总量建议占总cpu的2/3
num.io.threads = 8 负责写磁盘的线程数,整个参数值要占总核数的 50%。
num.replica.fetchers = 1 副本拉取线程数,这个参数占总核数的 50%的 1/3。
num.network.threads = 3 数据传输线程数,这个参数占总核数的 50%的 2/3
生产者优化
生产者发送数据过程:
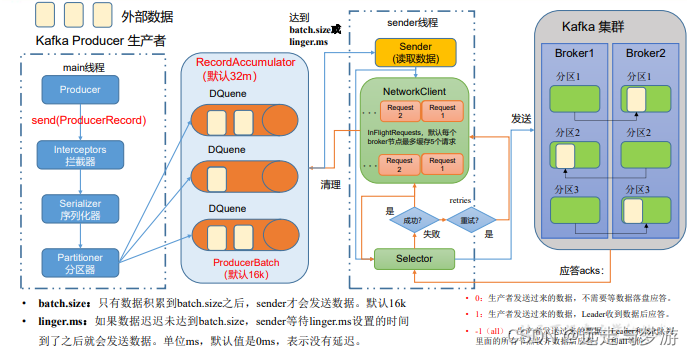
如何提高吞吐量
参数名称描述buffer.memoryRecordAccumulator 缓冲区总大小,默认 32mbatch.size缓冲区一批数据最大值,默认 16k。适当增加该值,可 以提高吞吐量,但是如果该值设置太大,会导致数据传 输延迟增加linger.ms如果数据迟迟未达到 batch.size,sender 等待 linger.time 之后就会发送数据。单位 ms,默认值是 0ms,表示没有 延迟。生产环境建议该值大小为 5-100ms 之间compression.type生产者发送的所有数据的压缩方式。默认是 none,也就 是不压缩。 支持压缩类型:none、gzip、snappy、lz4 和 zstd。
数据可靠性: ACK 级别设置为-1 + 分区副本大于等于 2 + ISR 里应 答的最小副本数量大于等于 2
acks:0:生产者发送过来的数据,不需要等数据落盘应答。 1:生产者发送过来的数据,Leader 收到数据后应答。 -1(all):生产者发送过来的数据,Leader+和 isr 队列 里面的所有节点收齐数据后应答。默认值是-1,-1 和 all 是等价的。
数据去重
开启幂等性:保证单分区单回话数据可靠
enable.idempotenc:是否开启幂等性,默认 true,表示开启幂等性
完全去重:开启事务
事务api
// 1 初始化事务
void initTransactions();
// 2 开启事务
void beginTransaction() throws ProducerFencedException;
// 3 在事务内提交已经消费的偏移量(主要用于消费者)
void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets,
String consumerGroupId) throws
ProducerFencedException;
// 4 提交事务
void commitTransaction() throws ProducerFencedException;
// 5 放弃事务(类似于回滚事务的操作)
void abortTransaction() throws ProducerFencedException;
数据有序:直接将数据放入一个分区
单分区内,有序(有条件的,不能乱序);多分区,分区与分区间无序;
数据乱序:开启幂等性设置ack
enable.idempotence是否开启幂等性,默认 true,表示开启幂等性。max.in.flight.requests.per.connection允许最多没有返回 ack 的次数,默认为 5,开启幂等性 要保证该值是 1-5 的数字
Broker 核心参数配置
工作流程
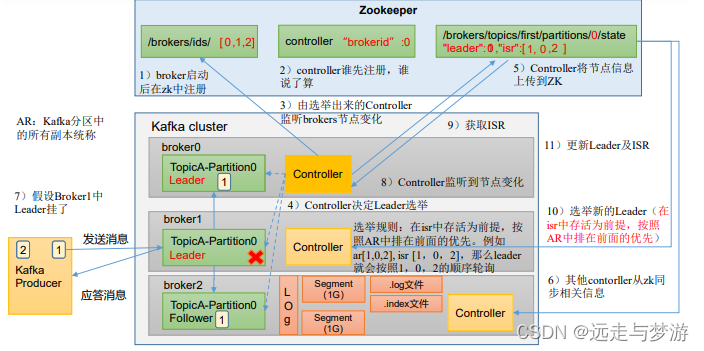
参数名称描述replica.lag.time.max.msISR 中,如果 Follower 长时间未向 Leader 发送通 信请求或同步数据,则该 Follower 将被踢出 ISR。 该时间阈值,默认 30s。auto.leader.rebalance.enable默认是 true。 自动 Leader Partition 平衡。建议 关闭。leader.imbalance.per.broker.percentage默认是 10%。每个 broker 允许的不平衡的 leader 的比率。如果每个 broker 超过了这个值,控制器 会触发 leader 的平衡。leader.imbalance.check.interval.seconds默认值 300 秒。检查 leader 负载是否平衡的间隔 时间。log.segment.bytesKafka 中 log 日志是分成一块块存储的,此配置 是指 log 日志划分 成块的大小,默认值 1G。log.index.interval.bytes默认 4kb,kafka 里面每当写入了 4kb 大小的日志 (.log),然后就往 index 文件里面记录一个索引。log.retention.hoursKafka 中数据保存的时间,默认 7 天。log.retention.minutesKafka 中数据保存的时间,分钟级别,默认关闭log.retention.msKafka 中数据保存的时间,毫秒级别,默认关闭log.retention.check.interval.ms检查数据是否保存超时的间隔,默认是 5 分钟log.retention.bytes默认等于-1,表示无穷大。超过设置的所有日志 总大小,删除最早的 segmentlog.cleanup.policy默认是 delete,表示所有数据启用删除策略; 如果设置值为 compact,表示所有数据启用压缩 策略。num.io.threads默认是 8。负责写磁盘的线程数。整个参数值要 占总核数的 50%。num.replica.fetchers默认是 1。副本拉取线程数,这个参数占总核数 的 50%的 1/3num.network.threads默认是 3。数据传输线程数,这个参数占总核数 的 50%的 2/3log.flush.interval.messages强制页缓存刷写到磁盘的条数,默认是 long 的最 大值,9223372036854775807。一般不建议修改, 交给系统自己管理log.flush.interval.ms每隔多久,刷数据到磁盘,默认是 null。一般不 建议修改,交给系统自己管理
服役新节点/退役旧节点
创建一个要均衡的主题
vim topics-to-move.json
#写入
{
"topics": [
{"topic": "first"}
],
"version": 1
}
生成一个负载均衡的计划
bin/kafka-reassign-partitions.sh --
bootstrap-server hadoop102:9092 --topics-to-move-json-file
topics-to-move.json --broker-list "0,1,2,3" --generate
创建副本存储计划(所有副本存储在 broker0、broker1、broker2、broker3 中)
vim increase-replication-factor.json
执行副本存储计划
bin/kafka-reassign-partitions.sh --
bootstrap-server hadoop102:9092 --reassignment-json-file increasereplication-factor.json --execute
验证副本存储计划
bin/kafka-reassign-partitions.sh --
bootstrap-server hadoop102:9092 --reassignment-json-file increasereplication-factor.json --verify
增加分区:分区数只能增加,不能减少
bin/kafka-topics.sh --bootstrap-server
192.168.6.100:9092 --alter --topic first --partitions 3
增加副本因子
创建 topic
bin/kafka-topics.sh --bootstrap-server
hadoop102:9092 --create --partitions 3 --replication-factor 1 --
topic four
手动增加副本存储,创建副本存储计划(所有副本都指定存储在 broker0、broker1、broker2 中)
vim increase-replication-factor.json
{"version":1,"partitions":[{"topic":"four","partition":0,"replica
s":[0,1,2]},{"topic":"four","partition":1,"replicas":[0,1,2]},{"t
opic":"four","partition":2,"replicas":[0,1,2]}]}
执行副本存储计划
bin/kafka-reassign-partitions.sh --
bootstrap-server hadoop102:9092 --reassignment-json-file increasereplication-factor.json --execute
手动调整分区副本存储
创建副本存储计划(所有副本都指定存储在 broker0、broker1 中)
vim increase-replication-factor.json
{
"version":1,
"partitions":[{"topic":"three","partition":0,"replicas":[0,1]},
{"topic":"three","partition":1,"replicas":[0,1]},
{"topic":"three","partition":2,"replicas":[1,0]},
{"topic":"three","partition":3,"replicas":[1,0]}]
}
执行副本存储计划
bin/kafka-reassign-partitions.sh --
bootstrap-server 192.168.6.100:9092 --reassignment-json-file increasereplication-factor.json --execute
验证副本存储计划
bin/kafka-reassign-partitions.sh --
bootstrap-server 192.168.6.100:9092 --reassignment-json-file increasereplication-factor.json --verify
Leader Partition 负载平衡
auto.leader.rebalance.enable默认是 true。自动 Leader Partition 平衡。生产环 境中,leader 重选举的代价比较大,可能会带来 性能影响,建议设置为 false 关闭leader.imbalance.per.broker.percentage默认是 10%。每个 broker 允许的不平衡的 leader 的比率。如果每个 broker 超过了这个值,控制器 会触发 leader 的平衡leader.imbalance.check.interval.seconds默认值 300 秒。检查 leader 负载是否平衡的间隔 时间
自动创建主题
如果 broker 端配置参数 auto.create.topics.enable 设置为 true(默认值是 true),那么当生 产者向一个未创建的主题发送消息时,会自动创建一个分区数为 num.partitions(默认值为 1)、副本因子为 default.replication.factor(默认值为 1)的主题。除此之外,当一个消费者 开始从未知主题中读取消息时,或者当任意一个客户端向未知主题发送元数据请求时,都会 自动创建一个相应主题。这种创建主题的方式是非预期的,增加了主题管理和维护的难度。 生产环境建议将该参数设置为 false
Kafka 消费者
消费者组初始化流程:
1、coordinator:辅助实现消费者组的初始化和分区的分配。
coordinator节点选择 = groupid的hashcode值 % 50( consumer_offsets的分区数量)
例如: groupid的hashcode值 = 1,1% 50 = 1,那么__consumer_offsets 主题的1号分区,在哪个broker上,就选择这个节点的coordinator 作为这个消费者组的老大。消费者组下的所有的消费者提交offset的时候就往这个分区去提交offset
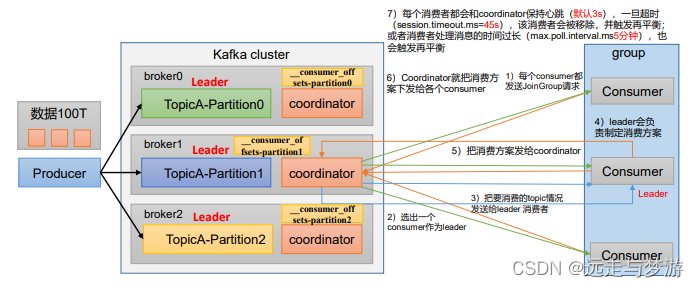
消费者组详细消费流程
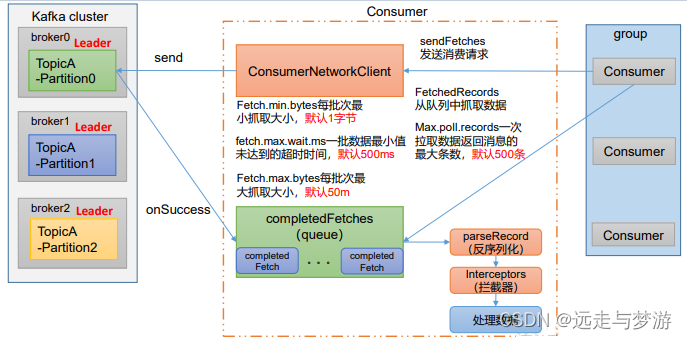
优化配置
enable.auto.commit默认值为 true,消费者会自动周期性地向服务器提交偏移量auto.commit.interval.ms如果设置了 enable.auto.commit 的值为 true, 则该值定义了 消费者偏移量向 Kafka 提交的频率,默认 5sauto.offset.reset当 Kafka 中没有初始偏移量或当前偏移量在服务器中不存在 (如,数据被删除了),该如何处理? earliest:自动重置偏 移量到最早的偏移量。 latest:默认,自动重置偏移量为最新 的偏移量。 none:如果消费组原来的(previous)偏移量不 存在,则向消费者抛异常。 anything:向消费者抛异常offsets.topic.num.partitions__consumer_offsets 的分区数,默认是 50 个分区。不建议修 改heartbeat.interval.msKafka 消费者和 coordinator 之间的心跳时间,默认 3s。 该条目的值必须小于 session.timeout.ms ,也不应该高于 session.timeout.ms 的 1/3。不建议修改session.timeout.msKafka 消费者和 coordinator 之间连接超时时间,默认 45s。超 过该值,该消费者被移除,消费者组执行再平衡max.poll.interval.ms消费者处理消息的最大时长,默认是 5 分钟。超过该值,该 消费者被移除,消费者组执行再平衡fetch.max.wait.ms默认 500ms。如果没有从服务器端获取到一批数据的最小字 节数。该时间到,仍然会返回数据fetch.max.bytes默认 Default: 52428800(50 m)。消费者获取服务器端一批 消息最大的字节数。如果服务器端一批次的数据大于该值 (50m)仍然可以拉取回来这批数据,因此,这不是一个绝 对最大值。一批次的大小受 message.max.bytes (broker config)or max.message.bytes (topic config)影响max.poll.records一次 poll 拉取数据返回消息的最大条数,默认是 500 条key.deserializer 和 value.deserializer指定接收消息的 key 和 value 的反序列化类型
消费者再平衡
heartbeat.interval.msKafka 消费者和 coordinator 之间的心跳时间,默认 3s。 该条目的值必须小于 session.timeout.ms,也不应该高于 session.timeout.ms 的 1/3session.timeout.msKafka 消费者和 coordinator 之间连接超时时间,默认 45s。 超过该值,该消费者被移除,消费者组执行再平衡max.poll.interval.ms消费者处理消息的最大时长,默认是 5 分钟。超过该值,该 消费者被移除,消费者组执行再平衡partition.assignment.strategy消 费 者 分 区 分 配 策 略 , 默 认 策 略 是 Range + CooperativeSticky。Kafka 可以同时使用多个分区分配策略。 可以选择的策略包括:Range、RoundRobin、Sticky、 CooperativeSticky
版权归原作者 远走与梦游 所有, 如有侵权,请联系我们删除。