

V8 之 what & why & when?
**waht:**V8
是一个由
Google
开源的采用
C++
编写的高性能
JavaScript
和
WebAssembly
引擎,应用在
Chrome
和
Node.js
等中。它实现了
ECMAScript
和
WebAssembly
,运行在
Windows 7
及以上、
macOS 10.12+
以及使用
x64、IA-32、ARM
或
MIPS
处理器的
Linux
系统上。
V8
可以独立运行,也可以嵌入到任何
C++
应用程序中。
when:V8最初是由
Lars Bak
团队开发的,以汽车的
V8
发动机(有八个气缸的V型发动机)进行命名,预示着这将是一款性能极高的
JavaScript
引擎,在
2008年9月2号
同
chrome
一同开源发布。
why:
JavaScript
代码最终要在机器中被执行,需要经过一系列的处理,将高级语言转换成二进制码指令,机器才可以识别和执行。而转换过程由
V8 负责完成
。
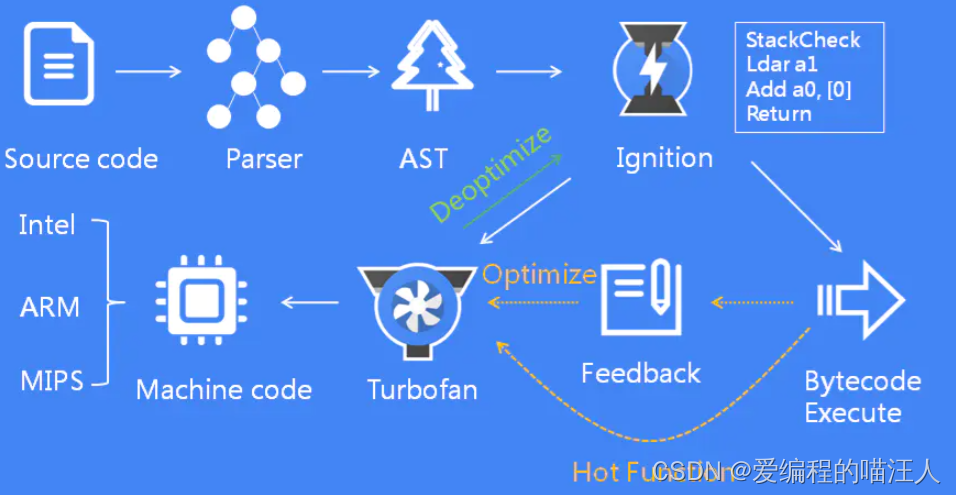
V8的组成部分
V8
的内部有很多模块,其中最重要的4个如下:
- Parser: 解析器,负责将源代码解析成
AST; - Ignition: 解释器,负责将
AST转换成字节码并执行,同时会标记热点代码; - TurboFan: 编译器,负责将热点代码编译成机器码并执行;
- Orinoco: 垃圾回收器,负责进行内存空间回收;
以下是 **
V8
中这几个重要模块的具体工作流程图**。接下来我们除垃圾回收器 **Orinoco **之外逐个进行分析。
Parser 解析器
Parser解析器的转换过程有两个重要阶段:
词法分析(Lexical Analysis)
和
语法分析(Syntax Analysis)。
词法分析阶段是扫描输入的源代码字符串,生成一系列的词法单元 (tokens),这些词法单元包括数字,标点符号,运算符等。词法单元之间都是独立,该阶段并不关心代码的组合方式。
JavaScript
中的
token
主要包含以下几种:
关键字:var、let、const等;
标识符:没有被引号括起来的连续字符,可能是一个变量,也可能是 if、else 这些关键字,又或者是 true、false 这些内置常量;
运算符: +、-、 *、/ 等;
数字:像十六进制,十进制,八进制以及科学表达式等;
字符串:变量的值等;
空格:连续的空格,换行,缩进等;
注释:行注释或块注释都是一个不可拆分的最小语法单元;
标点:大括号、小括号、分号、冒号等。
比如, const name = 'zedran'
经过
esprima
词法分析后生成的
tokens:
[
{
"type": "Keyword",
"value": "const"
},
{
"type": "Identifier",
"value": "name"
},
{
"type": "Punctuator",
"value": "="
},
{
"type": "String",
"value": "'zedran'"
}
]
语法分析阶段是将词法分析产生的
token
按照某种给定的形式文法转换成
AST
的过程。也就是把单词组合成句子的过程。在转换过程中会验证语法,语法如果有错的话,会抛出语法错误。
上述
const name = 'zedran'
经过语法分析后生成的
AST
如下:
{
"type": "Program",
"start": 0,
"end": 21,
"body": [
{
"type": "VariableDeclaration",
"start": 0,
"end": 21,
"declarations": [
{
"type": "VariableDeclarator",
"start": 6,
"end": 21,
"id": {
"type": "Identifier",
"start": 6,
"end": 10,
"name": "name"
},
"init": {
"type": "Literal",
"start": 13,
"end": 21,
"value": "zedran",
"raw": "'zedran'"
}
}
],
"kind": "const"
}
],
"sourceType": "module"
}
此后,经过
Parser
解析器生成的
AST
将交由
Ignition
解释器进行处理。
Ignition 解释器
Ignition 解释器负责**将
AST
转换成字节码(Bytecode)并执行。**字节码是介于
AST
和机器码之间的一种代码,与特定类型的机器代码无关,需要通过解释器转换成机器码才可以执行。
聪明的你可能会问:为何不直接将
AST
转换成机器码直接运行呢?
V8的
5.9版本之前是没有字节码的,而是直接将JS代码编译成机器码并将机器码存储到内存中,这样就占用了大量的内存,而早期的手机内存都不高,过度的占用会导致手机性能大大的下降;而且直接编译成机器码导致编译时间长,启动速度慢;再者直接将JS代码转换成机器码需要针对不同的
CPU架构编写不同的指令集,复杂度很高。
5.9版本以后引入了字节码,可以解决上述内存占用大、启动时间长、代码复杂度高这几个问题。
Ignition
解释器的工作流程图:

AST
需要先通过字节码生成器,再经过一系列的优化之后才能生成字节码。 其中的优化包括:
- Register Optimizer:主要是避免寄存器不必要的加载和存储
- Peephole Optimizer:寻找字节码中可以复用的部分,并进行合并
- Dead-code Elimination: 删除无用的代码,减少字节码的大小
Ignition 解释器
在执行字节码的过程中,会监视代码的执行情况并记录执行信息,如函数的执行次数、每次执行函数时所传的参数等。被执行多次的同一段代码,会被标记成热点代码,交给
TurboFan
编译器进行处理。
TurboFan 编译器
TurboFan 编译器
拿到
Ignition 解释器
标记的热点代码后,会先优先将优化后字节码编译成更高效的机器码存储起来。下次再次执行相同代码时,会直接执行相应的机器码,大大提升了代码的执行效率。
当一段代码不再是热点代码后,
TurboFan
会将优化编译后的机器码还原成字节码,将代码的执行权利交还给
Ignition 解释器
。
现在我们来看一看具体的执行过程:以多次执行
sum = sum + arr[i]
为例,
JS
是动态类型的语言,每次的
sum
和
arr[i]
都有可能是不同的类型,在执行这段代码时,
Ignition
每次都会检查
sum
和
arr[i]
的数据类型。其被标记为热点代码,交给
TurboFan 编译器直接以之前的
几次执行确定
sum
和
arr[i]
的数据类型编译成机器码。
但如果在后续的执行过程中,
arr[i]
的数据类型发生了改变,之前生成的机器码就不满足要求了,
TurboFan 编译器
会把之前生成的机器码丢弃,将执行权利再交给
Ignition 解释器
,完成去优化的过程。
这种将字节码与解释器和编译器结合的技术,就是我们通常所说的**即时编译(
JIT
)**。
总结
V8
的执行过程:
- 源代码经过
Parser解析器,经过词法分析和语法分析生成AST; AST经过Ignition解释器生成字节码并执行;- 在执行过程中,如果发现热点代码,将热点代码交给
TurboFan编译器生成机器码并执行; - 如果热点代码不再满足要求,进行去优化处理。
版权归原作者 爱编程的喵汪人 所有, 如有侵权,请联系我们删除。