
Flink反压利用了网络传输和动态限流。Flink的任务的组成由流和算子组成,那么流中的数据在算子之间转换的时候,会放入分布式的阻塞队列中。当消费者的阻塞队列满的时候,则会降低生产者的处理速度。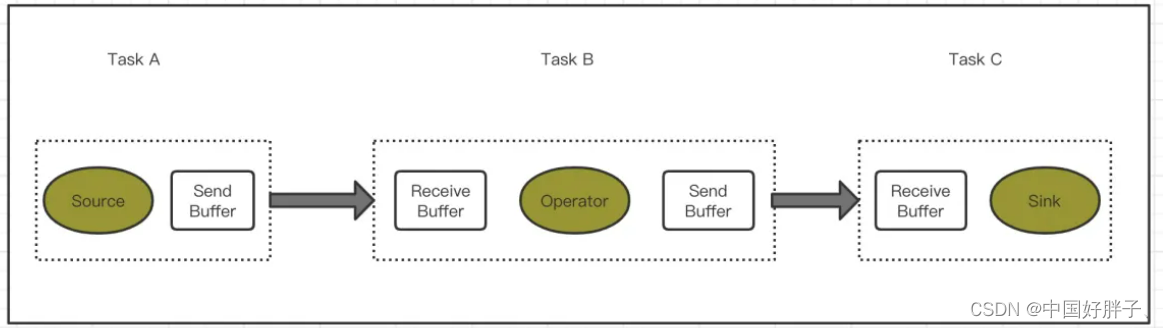
如上图所示,当Task C 的数据处理速度发生异常的时候,Receive Buffer会呈现出队列满的情况,Task B发送端就会感知到这一点,因为发不过去了吗。然后把数据的发送速度降低,以此类推,整个反压会一直从下到上传递到Source端;反之,当task处理能力有提升后,会在此反馈到Source Task,数据发送和读取的速率就会升高,提高了整个flink任务的处理能力以及容错能力。
当任务出现反压时,如果你的上游是类似kafka的消息系统,很明显的表现就是消费速度过慢,kafka消费出现积压。如果业务对数据延迟要求不搞,那么反压其实没有很大的影响。但是对于规模很大的集群中的大作业,反而反压会造成很严重的问题。首先状态会变大,因为数据大规模堆积在系统中,这些暂时不被处理的数据,同样会被放到状态中。另外,Flink会因为数据堆积和处理速度变慢导致Checkpoint超时。Checkpoint超时的话,checkpoint是我们数据一致性的关键所在,如果一直checkpoint超时,会导致kafka lag一直居高不下,一直失败,一直失败,导致状态变大。有可能造成OOM导致JOB失败。此时重新消费数据有可能会出现重复消费数据的可能,严重的会导致数据不一致的产生。
那么我们如何判断是否反压呢,我们可以在flink任务的后台页面进行查看
在默认的设置下,Flink的TaskManager会每隔50ms触发一次反压状态检测,共检测100次,并将结果反馈给JobManager,最后由JobManager进行计算反压的比例,然后进行展示。
这个比例展示逻辑如下:
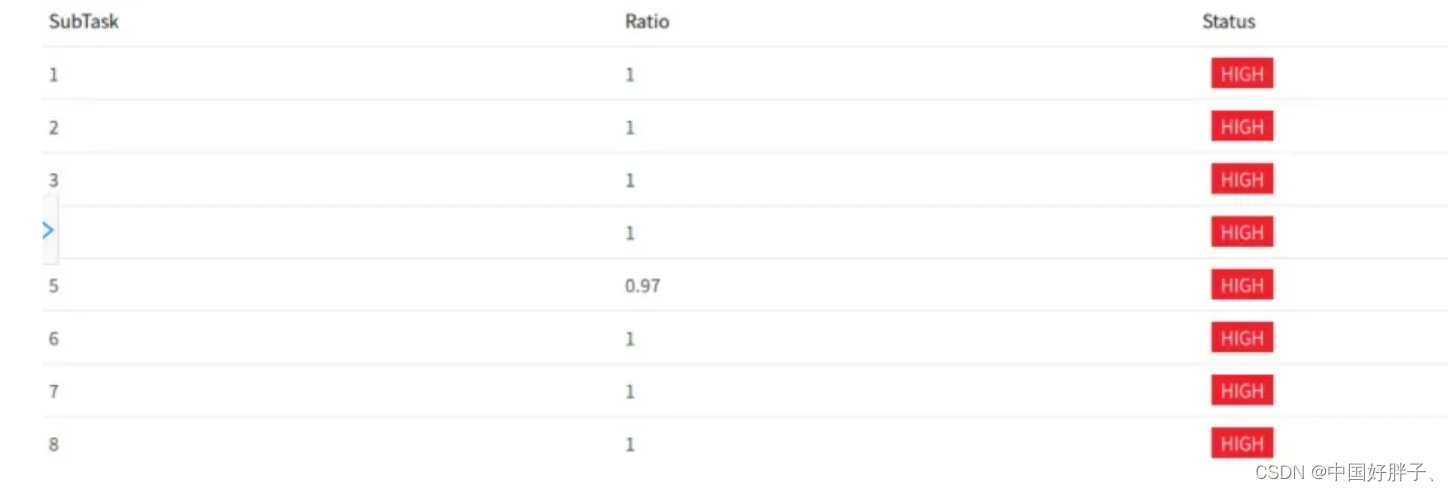
OK:0 <= Ratio <= 0.10,正常
LOW:0.10 < Ratio <= 0.50,一般
HIGH:0.5 < Ratio <= 1,严重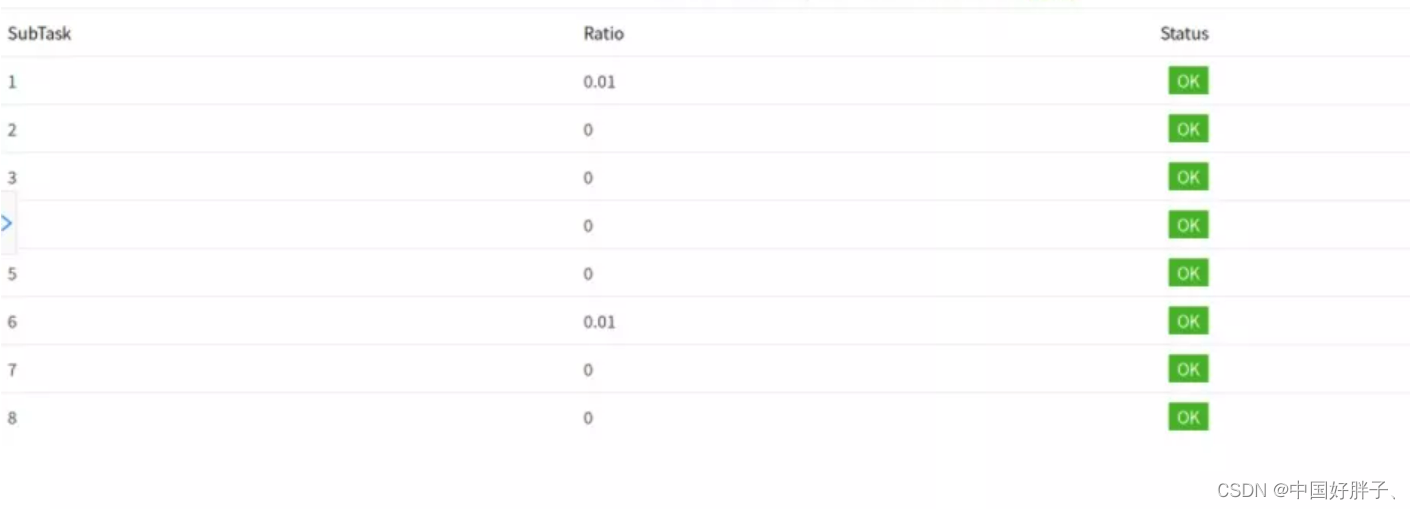
要解决反压首先要做的是定位到造成反压的节点,这主要有两种办法:
- 通过 Flink Web UI 自带的反压监控面板
- 通过 Flink Task Metrics 前者比较容易上手,适合简单分析,后者则提供了更加丰富的信息,适合用于监控系统。因为反压会向上游传到,这两种方式都要求我们从Source节点到Sink的逐一排查。 如果出于反压状态,那么有两种可能性:
- 该节点的发送速率跟不上它产生数据的速率
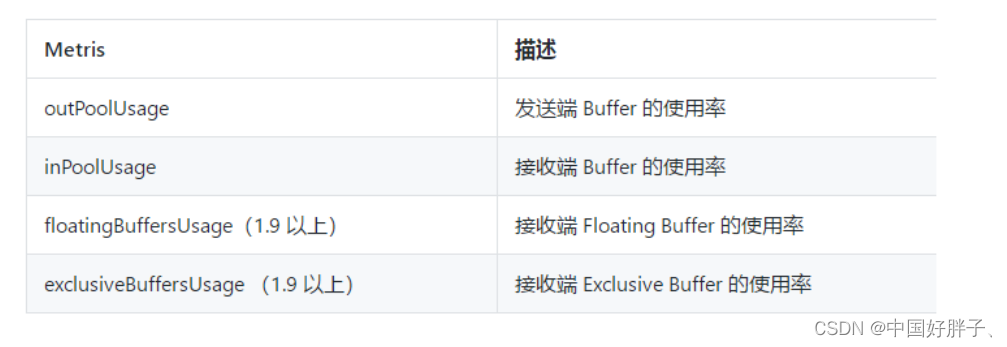
- 下游的节点接速率较慢,通过反压机制限制了该节点的发送速率 如果是第一种状况,那么该节点则为反压的根源节点,它是从Source Task到SInk Task 第一个出现反压的节点 如果是第二种情况,则需要排查下游节点 值得注意的是,反压的根源节点并不一定在反压面板出现高反压。因为反压面板监控的是发送端,如果某个节点是性能瓶颈并不会导致它本身出现高反压,而是导致它的上游出现高反压。总体来看,如果我们找到第一个出现反压的节点,那么反压根源要么就是这个节点,要么是它紧接着的下有节点。 怎么区分这两种情况呢,通过监控面板是无法给出判断的。这个时候就可以根据 Flink的指标监控来寻找是那一个sub task出现了反压的问题。 我们在监控反压时会用到的Metrics主要和Channel 接收端的buffer使用率有关,最有用的是以下几个Metrics:
TaskManager传输数据时,不同的TaskManager上的两个SubTask间通常根据key的数量有多个Channel,这些Channel会复用同一个TaskManager级别的TCP链接,并且共享接收端SubTask级别的BufferPool。
TaskManager 传输数据时,不同的TaskManager上的两个SubTask间通常根据key的数量有多个channel,这些channel会复用同一个TaskManager级别的TCP链接,并且共享接收端SubTask级别的Buffer Pool。
在接收端,每个Channel在初始阶段会分配固定数量的 Exclusive Buffer,这些Buffer会被用于存储接收到的数据,交给Operator使用后再次被释放。Channel接收端空闲的Buffer数量成为Credit,Credit会被定时同步给发送端被后者用于决定发送多少个Buffer的数据。
在流量较大时,Channel的Exclusive Buffer可能会被写满,此时Flink会向Buffer Pool 申请剩余的Floating Buffer。这些Floating Buffer属于备用的Buffer,哪个Channel需要就去哪里。而在Channel 发送端一个Subtask所有的Channel会共享同一个Buffer Pool,这边就没有区分Exclusive Buffer和Floating Buffer。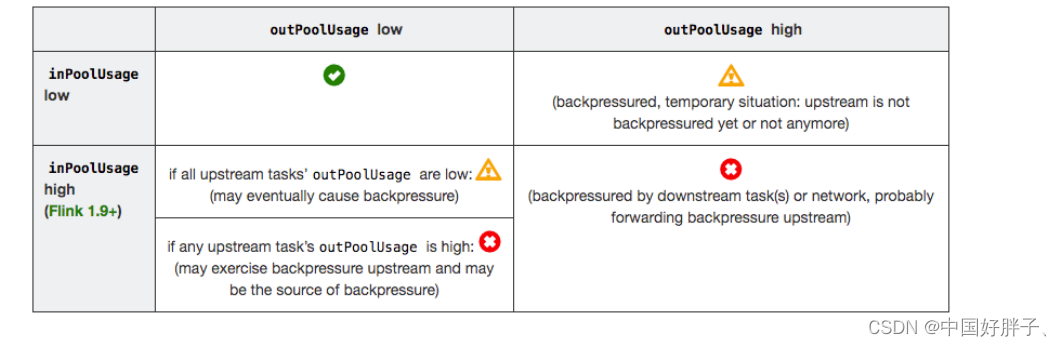
outPoolUsage 和 inPoolUsage 同为低或同为高分别表明当前 Subtask 正常或处于被下游反压,这应该没有太多疑问。而比较有趣的是当 outPoolUsage 和 inPoolUsage 表现不同时,这可能是出于反压传导的中间状态或者表明该 Subtask 就是反压的根源。
如果一个 Subtask 的 outPoolUsage 是高,通常是被下游 Task 所影响,所以可以排查它本身是反压根源的可能性。如果一个 Subtask 的 outPoolUsage 是低,但其 inPoolUsage 是高,则表明它有可能是反压的根源。因为通常反压会传导至其上游,导致上游某些 Subtask 的 outPoolUsage 为高,我们可以根据这点来进一步判断。值得注意的是,反压有时是短暂的且影响不大,比如来自某个 Channel 的短暂网络延迟或者 TaskManager 的正常 GC,这种情况下我们可以不用处理。
对于 Flink 1.9 及以上版本,除了上述的表格,我们还可以根据 floatingBuffersUsage/exclusiveBuffersUsage 以及其上游 Task 的 outPoolUsage 来进行进一步的分析一个 Subtask 和其上游 Subtask 的数据传输。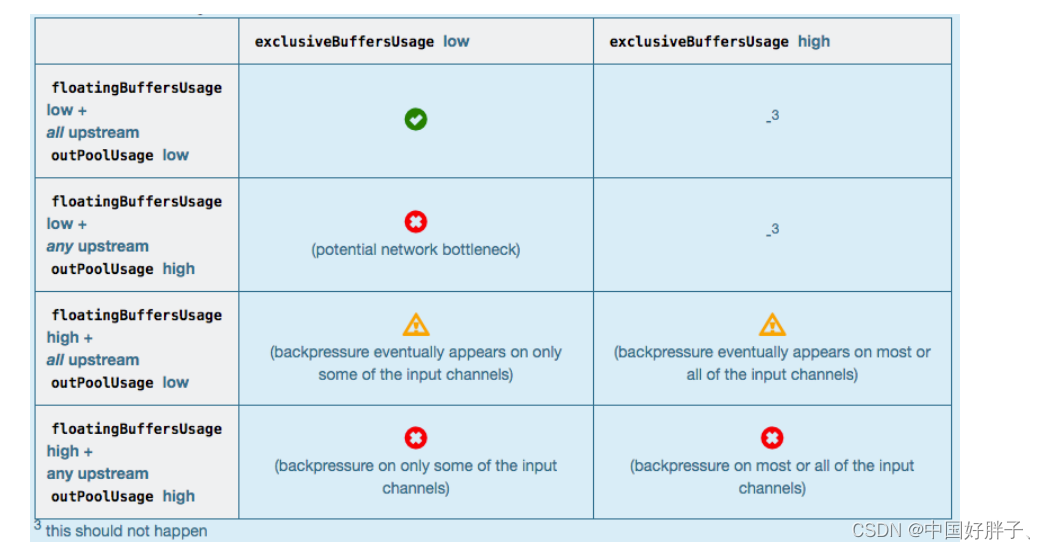
通常来说,floatingBuffersUsage 为高则表明反压正在传导至上游,而 exclusiveBuffersUsage 则表明了反压是否存在倾斜(floatingBuffersUsage 高、exclusiveBuffersUsage 低为有倾斜,因为少数 channel 占用了大部分的 Floating Buffer)。
至此,我们已经有比较丰富的手段定位反压的根源是出现在哪个节点,但是具体的原因还没有办法找到。另外基于网络的反压 metrics 并不能定位到具体的 Operator,只能定位到 Task。特别是 embarrassingly parallel(易并行)的作业(所有的 Operator 会被放入一个 Task,因此只有一个节点),反压 metrics 则派不上用场。
定位到反压节点后,分析造成原因的办法和我们分析一个普通程序的性能瓶颈的办法是十分类似的,可能还要更简单一点,因为我们要观察的主要是 Task Thread。
在实践中,很多情况下的反压是由于数据倾斜造成的,这点我们可以通过 Web UI 各个 SubTask 的 Records Sent 和 Record Received 来确认,另外 Checkpoint detail 里不同 SubTask 的 State size 也是一个分析数据倾斜的有用指标。
此外,最常见的问题可能是用户代码的执行效率问题(频繁被阻塞或者性能问题)。最有用的办法就是对 TaskManager 进行 CPU profile,从中我们可以分析到 Task Thread 是否跑满一个 CPU 核:如果是的话要分析 CPU 主要花费在哪些函数里面,比如我们生产环境中就偶尔遇到卡在 Regex 的用户函数(ReDoS);如果不是的话要看 Task Thread 阻塞在哪里,可能是用户函数本身有些同步的调用,可能是 checkpoint 或者 GC 等系统活动导致的暂时系统暂停。
当然,性能分析的结果也可能是正常的,只是作业申请的资源不足而导致了反压,这就通常要求拓展并行度。值得一提的,在未来的版本 Flink 将会直接在 WebUI 提供 JVM 的 CPU 火焰图[5],这将大大简化性能瓶颈的分析。
另外 TaskManager 的内存以及 GC 问题也可能会导致反压,包括 TaskManager JVM 各区内存不合理导致的频繁 Full GC 甚至失联。推荐可以通过给 TaskManager 启用 G1 垃圾回收器来优化 GC,并加上 -XX:+PrintGCDetails 来打印 GC 日志的方式来观察 GC 的问题。
参考:
https://maimai.cn/article/detail?fid=1372302272&efid=s1cKvvDRtJYzA_5vRPJ7og
版权归原作者 中国好胖子、 所有, 如有侵权,请联系我们删除。