
hadoop保姆级安装教程
文章目录
实现分布式集群安装,不再从入门到放弃!!
这是一篇超详细的Hadoop安装教程,历时两个星期,重装了三次!基本把能踩的坑全踩了,还好没放弃😂
下面标了注意的地方基本就是我踩过的坑了
以下分为三个大点:准备,配置网络环境,安装hadoop
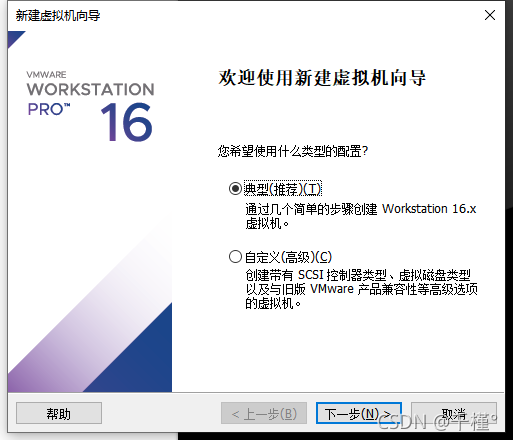
一、准备步骤:虚拟机安装
1.VMware下载
官网下载,安装VMware Workstation 10以上版本。
没有什么技术含量,基本就是疯狂点击下一步,更改安装路径。
2.下载centos6.7镜像
网上找对应的资源下载即可
注意: 一定要下载centos6
为什么呢?
centos6支持从Windows系统拷贝文件等到linux操作系统,便于后续hadoop,Java的传输。
3.安装虚拟机
这里我用的是三个集群分布,所以要安装三台虚拟机。
注意: 要新建三个虚拟机,不要克隆,不要克隆!
(因为这里我只尝试了新建的方法,克隆的话后面要按照克隆的方法来进行配置,避免不必要的麻烦,直接按照相同的方法新建三个就好)
新建一台虚拟机步骤(另外两台一样)
- 打开VMware
- 点击左上角 :文件->新建虚拟机
- 点击下一步
- 点击浏览,选择你下载的centos镜像文件

- 全名和用户名可以是一样的,这里我设置的是hadoop,密码建议填写123456,便于后期维护

- 点击浏览可选择安装位置
- 默认就好
- 点击完成
 由于我已经安装过了,就不进行下面的步骤了
由于我已经安装过了,就不进行下面的步骤了 - 命名虚拟机:我填的是hadoop1 (后面两台可以填hadoop2,hadoop3)
接下来就是等待啦,可能需要一点时间。 至此,第一台虚拟机就装好了,输入密码即可登录。
至此,第一台虚拟机就装好了,输入密码即可登录。
注意: 另外两台重复上面的步骤,用户名也一样,直接用一样的,不然后面会有问题
全部装好之后就可以打开三台虚拟机
准备步骤就绪
二、配置网络
1.设置
- 点击左上角:编辑->虚拟网络编辑器
- 选择NAT模式

- 点击:更改设置
 选择允许对设备更改
选择允许对设备更改 - 选择NAT模式,取消使用本地dhcp服务的勾选

- 点击NAT设置,查看子网,子网掩码,网关(后面要用到)

- .点击确定
 2.修改主机名
2.修改主机名
输入su root命令,再输入密码,(密码不会显示在屏幕上,只要输入正确,再按回车键即可)进入root用户
打开配置文件,按下i键进入插入模式,可以开始修改
进入文件,修改,命令:
vi /etc/sysconfig/network
第一台:
HOSTNAME=hadoop1
第二台:
HOSTNAME=hadoop2
第三台:
HOSTNAME=hadoop3
按下Esc键,退出插入模式输入:wq保存退出
用exit退出root用户
*(后面的修改配置文件都要先进入root用户,
修改文件是同样的:打开配置文件,按下i键进入插入模式,可以开始修改,修改完成后按下Esc键,退出插入模式输入:wq保存退出。用exit退出root用户。
为简化步骤过程,后面就省略了)*
3.配置IP地址
- 使用命令:ifconfig查看
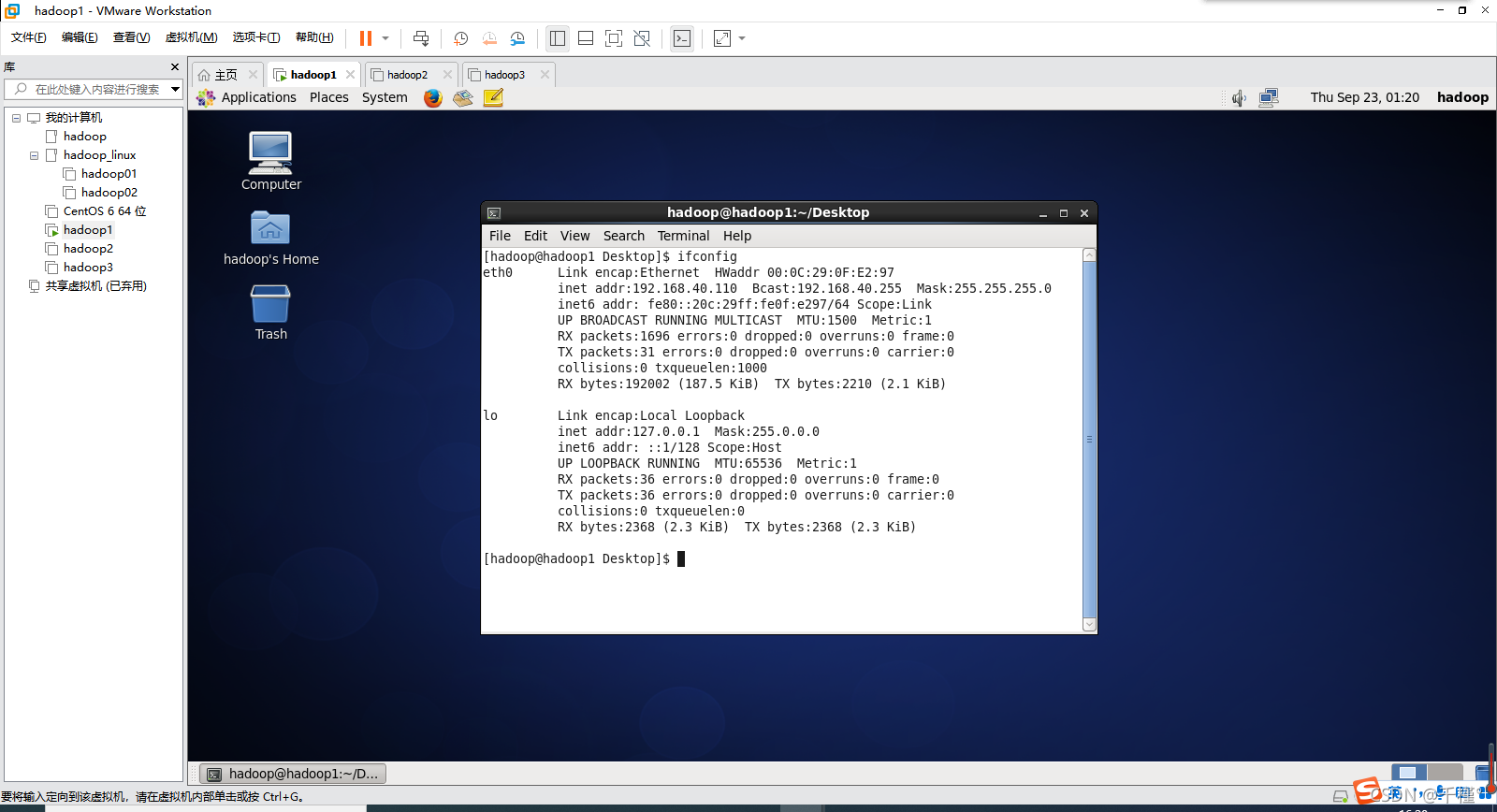
- 输入su root命令,再输入密码,(密码不会显示在屏幕上,只要输入正确,再按回车键即可)进入root用户若是eth0则使用命令:vi /etc/sysconfig/network-scripts/ifcfg-eth0 若是ens33则使用命令:vi /etc/sysconfig/network-scripts/ifcfg-ens33 打开配置文件,按下i键进入插入模式,可以开始修改修改信息:
BOOTPROTO="static"改为BOOTPROTO=“dhcp”
IPADDR=192.168.40.110 # 前三位必须和前面查看的子网前三位一致,最后一位必须是三位数
第二台和第三台的IPADDR前三位和第一台设置成一样的(保证在同一个子网下)
#比如以我的为例,第二台:IPADDR=192.168.40.120
第二台:IPADDR=192.168.40.130
NETMASK=255.255.255.0 #子网掩码
GATEWAY=192.168.XX.X #虚拟机里的网关IP一致
DNS1=8.8.8.8 #默认dns为谷歌的,也可以设置为别的,比如百度的
 按下Esc键,退出插入模式输入:wq保存退出
按下Esc键,退出插入模式输入:wq保存退出
3.重启服务器
输入命令:service network restart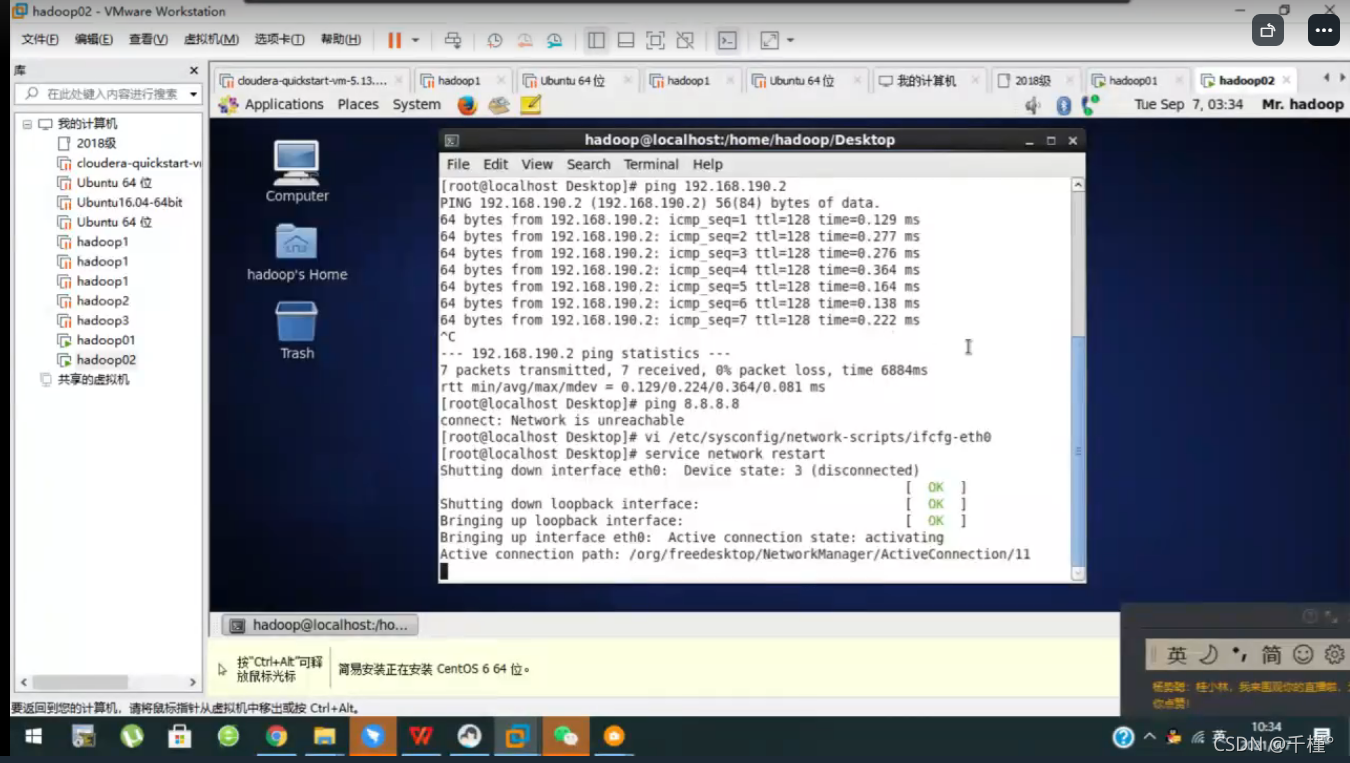
右上角显示这个字样即成功
3.主机名与IP地址做映射
修改配置文件,命令
vi /etc/hosts
加上
192.168.xxx.xxx hadoop1
192.168.xxx.xxx hadoop2
192.168.xxx.xxx hadoop3
最后:可以输入ping www.baidu.com看看能否ping通,或打开火狐浏览器看能不能正常访问网页,如果可以,那么说明网络配置成功。
三、免密登录
原理:把本机的公钥内容放到另一台机子里,免密登录时进行匹配,主机向另一台机子发送一段随机字符串,另一台用自己的私钥加密后,再发回来。本机用自己的公钥进行解密,如果成功,说明另一台是可信的。
实现操作:要实现三台虚拟机相互信任,每台机子上都要存储这三台机子的公钥,(本机本来就有公钥),则我们要做的就是把另外两台的公钥拷贝到本机。
方便起见,每台机子都在/home/hadoop/.ssh目录下建一个authorized_keys文件,里面放三台机子的公钥。
(能实现每台机子存储这三台的公钥即可,方法不限)
这里我分享一下我的方法
1.第一台主机下
生成密钥和公钥,命令:
ssh-keygen -t rsa
随后不断点击回车,
密钥文件就存储在/home/hadoop/.ssh目录下
2.把三台机子的公钥放到第二台的authorized_keys文件下,(第二台没有authorized_keys,需要创建)
命令:
cd /home/hadoop/.ssh
回车即可看到两个文件
id_rsa:私钥
id_rsa.pub:公钥
3.第二台机子下
同样做步骤1,2,
在/home/hadoop/.ssh目录下使用命令:
touch authorized_keys
新建一个空白文件
命令:
cat id_rsa.pub
查看公钥内容,选中右击,然后copy
命令:
vi authorized_keys
进入插入模式,右击,然后paste粘贴,即把本机公钥复制到了authorized_keys里
回到第一台主机,
命令:
cat id_rsa.pub
查看公钥内容,选中右击,然后copy
再到第二台机子,
继续粘贴,即把第一台主机的公钥复制到了第二台机子的authorized_keys文件下
第三台机子
同样做步骤1,2,
在/home/hadoop/.ssh目录下使用命令:
touch authorized_keys
新建一个空白文件
命令:
cat id_rsa.pub
查看公钥内容,选中右击,然后copy
再次回到第二台机子
继续粘贴,即把第三台主机的公钥复制到了第二台机子的authorized_keys文件下
保存退出
至此,第二台机子的/home/hadoop/.ssh目录下的authorized_keys文件里存储了三台机子的公钥。
4.把第二台机子的authorized_keys文件传到第一台和第三台机子的/home/hadoop/.ssh目录下即可。
使用命令:
scp authorized_keys hadoop@hadoop1:/home/hadoop/.ssh/authorized_keys
传输到第一台
使用命令:
scp authorized_keys hadoop@hadoop3:/home/hadoop/.ssh/authorized_keys
传输到第三台
三台机子的authorized_keys里都存储了三台机子的公钥,可以免密登录了。
修改权限:
chmod 644 authorized_keys
修改权限
6.关闭防火墙(root用户下)
chkconfig iptables stop
7.修改防火墙配置文件,命令
vi /etc/selinux/config
设置SELINUX=disabled
5.测试能否免密登录
注意: 第一次可能要输入密码,之后就不用了。
第一台主机下,
检测能否免密登录Hadoop2,
命令:ssh hadoop2
显示如下,则成功免密登录
inet addr:192.168.40.120即是当前ip地址
命令exit可退出 检测能否免密登录Hadoop3,
检测能否免密登录Hadoop3,
命令:ssh hadoop3
如果成功,则第一台主机可免密登录第二台,第三台。
在第二台,第三台上也是同样的方法测试。
四、安装hadoop
hadoop是以java为基础运行的,所以要先安装java环境。
安装JDK
1.从windows网上下载hadoop-2.6.0-cdh5.11.2.tar和jdk-1.8.0-8u60-linux-x64
2.直接从windows复制到linux的hadoop1虚拟机里(centos6自带这个功能)
注意: 不能使用快捷键ctrl+c,ctrl+v,只能右击复制粘贴
3.安装jdk包
方法一:双击rpm包
方法二:命令
rpm -ivh jdk-1.8.0-8u60-linux-x64.rpm
4.验证:
java -version
结果:java -version
java version “1.8.0_60”
Java™ SE Runtime Environment (build 1.8.0_60-b27)
Java HotSpot™ 64-Bit Server VM (build 25.60-b23, mixed mode)
即
进入root用户,命令
su root
先看看防火墙是否关闭,命令
service iptables status
 如上则表示防火墙是开着的,
如上则表示防火墙是开着的,
这时需要关闭防火墙,命令
service iptables stop
之后可再检查防火墙的状态是否关闭
service iptables ststus
 出现如图所示说明关闭防火墙
出现如图所示说明关闭防火墙
安装hadoop
1.解压
tar –xvf hadoop-2.6.0-cdh5.10.1.tar.gz -C /home/hadoop
为了方便后续操作
进入家目录
cd ~
修改hadoop的名字
mv hadoop-2.6.0-cdh5.10.1 hadoop
2.配置环境变量(在家目录下)
vi .bashrc
添加内容:
export HADOOP_HOME=/home/hadoop/hadoop
export PATH=P A T H : PATH: PATH:HADOOP_HOME/bin
使文件生效:
source .bashrc
把.bahsrc文件传送到hadoop2,使其生效
scp .bashrc hadoop@hadoop2:~/
source .bashrc
把.bahsrc文件传送到hadoop3,使其生效
scp .bashrc hadoop@hadoop3:~/
source .bashrc
3.配置系统文件
进入目录,命令
cd /home/hadoop/hadoop/etc/hadoop
(以下文件的内容复制过来会有缺失,所以选择图片形式)
- core-site.xml 在configutation,/configutation标签对内添加内容:(复制过来会有缺失,用了图片形式)

2.hdfs-site.xml
在configutation,/configutation标签对内添加内容:
3.在家目录下新建hadoopdata目录,在该目录下创建dn,nn,log,yarn目录。
把Hadoopdata目录传送到第二,第三台虚拟机
mkdir ~/hadoopdata
cd ~/hadoopdata
mkdir dn nn log yarn
scp -r hadoopdata hadoop@hadoop2:~
scp -r hadoopdata hadoop@hadoop3:~
4.进入/home/hadoop/hadoop/etc/hadoop目录下
cd /home/hadoop/hadoop/etc/hadoop
配置mapred-site.xml.template文件
在configutation,/configutation标签对内添加内容:
5.yarn-site.xml
在configutation,/configutation标签对内添加内容: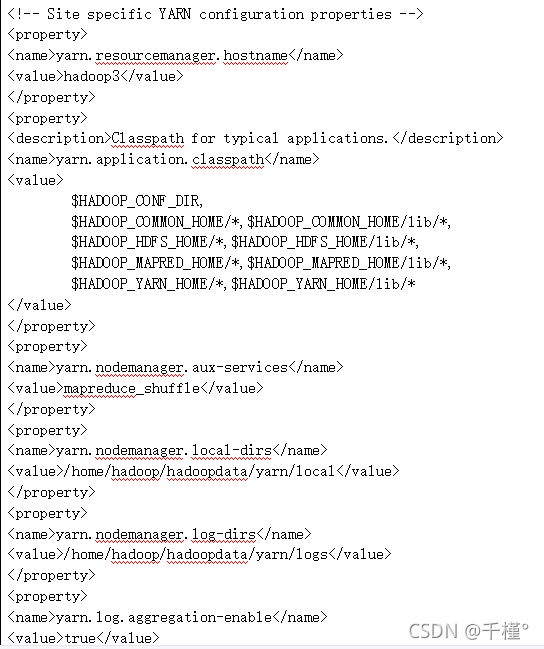
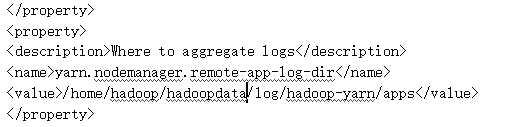
6.添加JAVA_HOME到hadoop-env.sh文件里
编辑hadoop-env.sh:
vi hadoop-env.sh
找到javahome,把路径改为:
export JAVA_HOME=/usr/java/default
7.添加所有主机名到slaves里
编辑slaves:
vi slaves
在文件里添加如下内容:
hadoop1
hadoop2
hadoop3
==注意:==如果是拷贝文件内容,则很可能会缺失部分字符,一定要仔细核对!!
8.新建一个hadoopdata目录,下面建4个目录(在家目录下,三台机子都要)
命令
mkdir hadoopdata
cd hadoopdata
mkdir nn dn yarn log
9.将hadoop目录传送到第二台,第三台
scp -r hadoop hadoop@hadoop2:~
scp -r hadoop hadoop@hadoop3:~
10.格式化namenode
hadoop namenode–format
 如果状态码为0,则说明格式化成功。
如果状态码为0,则说明格式化成功。
启动进程
单个启动
hadoop1
进入hadoop的sbin目录下,逐个启动结点
cd /home/hadoop/hadoop/sbin
./hadoop-daemon.sh start namenode
./hadoop-daemon.sh start datanode
./yarn-daemon.sh start nodemanager
输入命令查看结点是否启动
jps
 显示上图结果,说明结点启动成功
显示上图结果,说明结点启动成功
hadoop2
进入hadoop的sbin目录下,逐个启动结点
cd /home/hadoop/hadoop/sbin
./hadoop-daemon.sh start secondarynamenode
./hadoop-daemon.sh start datanode
./yarn-daemon.sh start nodemanager
输入命令查看结点是否启动
jps
同理
hadoop3
进入hadoop的sbin目录下,逐个启动结点
cd /home/hadoop/hadoop/sbin
./hadoop-daemon.sh start datanode
./yarn-daemon.sh start resourcemanager
./yarn-daemon.sh start nodemanager
输入命令查看结点是否启动
jps
同理。
批量启动
验证集群是否成功(启动集群后)
在linux的火狐浏览器中访问http://hadoop1:50070和http://hadoop3:8088
到此,安装完毕。
最后,终于安装完了,如有不足,欢迎指正。
虽然教程有点长,但是写的很详细,耐心一步步跟着步骤走,相信一定能够成功安装hadoop!!
写在最后,如果觉得教程有用一键三连呗老铁们,欢迎评论区留言技术交流。
版权归原作者 千槿° 所有, 如有侵权,请联系我们删除。