
webUI自动化背景
因为web页面经常会变化,所以UI自动化测试的维护成本很高。不如接口的适用面广,所以大部分公司会做接口自动化测试,但是未必会做UI自动化测试;
UI自动化测试要做也是覆盖冒烟测试,不会到很高的覆盖率:
接口自动化测试框架覆盖率: 90%+,能做回归测试。
UI自动化测试框架覆盖率【用例】:30%-40%,能做冒烟测试【正常用例】,覆盖核心功能的页面配置,减少重复的页面操作。
webUI自动化使用工具: selenium
【其他框架: cypress,robotframework,playwright-- 录播课程】
Selenium是用于Web应用自动化测试的工具,开源并且免费
支持Chrome、FireFox、Edge、IE、Safari等主流浏览器 【Chrome支持的最好 最稳定 推荐】
支持Java、Python、Net、Perl等编程语言进行自动化测试脚本编写
官网地址:https://selenium.dev/
selenium工具家族
selenium ide : 录制工具。 谷歌和火狐的插件。用途:录制回放bug的过程。不推荐用,录制基本都需要再修改;30分钟就学会了。
- Firefox可以下载插件,并录制回放;可以导入成为代码脚本,也很方便。
- 但是这个录制的功能不够灵活,比如需要做一些判断,循环控制等复杂的业务场景自动化,稳定性不太好。
selenium webdriver : 核心,重点学习的,,提供了各种语言环境的API来支持更多控制权和编写符合标准软件开发实践的应用程序
- 结合代码(PythonJava,C#,JavaScript、Perl、PHP,Ruby)一起来完成自动化。
- 提供了非常多的浏览器网页操作的接口【api】
selenium grid : 分布式测试,通过Selenium Grid可以将自动化测试脚本分发到不同的测试机器中执行;用例分布不同的设备上运行,提高运行效率。
Selenium及其相关驱动和浏览器的安装使用步骤
1、pip install selenium==4.3.0,最好指定版本安装,因为不同的版本可能会有一些兼容
性的问题。
- 注意: 检查一下你电脑的urllib3的版本,pip show urllib3 ,如果是2.x 以上的版本,会有兼容性问题。pip uninstall urllib3 ,pip install urllib3==1.26.15 【执行版本安装】
2、下载浏览器驱动:注意 驱动程序要与浏览器的类型和版本匹配。
- 驱动程序放在了Python的安装目录下:selenium会自动从path环境变量中去找这个驱动文件;如果驱动不在Python安装目录 就需要加参数初始化。
浏览器安装文件及对应的驱动:
浏览器安装文件下载地址对应驱动下载地址Chrome
【稳定
推荐】Google Chrome 64bit Windows版_chrome浏览器,chrome插件,谷歌浏览器下载,谈笑有鸿儒CNPM Binaries MirrorFirefoxMicrosoft Edge WebDriver | Microsoft Edge Developerhttps://npm.taobao.org/mirrors/geckodriver/Edgehttps://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/Microsoft Edge WebDriver | Microsoft Edge DeveloperIE -
old,不
推荐驱动版本需求与selenium保持一致,建议使用32位的
IE驱动,兼容性更好http://selenium-release.storage.googleapis.com/index.html
3、装好浏览器,正确安装。最好在默认的路径下。一定要记得关闭自动更新。
- 特别注意:chrome浏览器关闭自动更新: https://blog.csdn.net/weixin_48337566/article/details/123242827
- 火狐浏览器关闭自动更新: https://www.lmlphp.com/user/58724/article/item/840150/
- 一旦浏览器自动升级了,原来的驱动就会不能用了,所以一定要记得关闭这个自动更新!
4、测试:能否利用代码打开浏览器。
from selenium import webdriver
# 启动与浏览器的会话。打开浏览器,同时也会去启动驱动程序。chrome.driver启动后 就是一个IP+ 端
口,就是启动了一个服务。
driver = webdriver.Chrome()
# 打开谷歌浏览器,然后访问百度首页。
driver.get("http://www.baidu.com")
# 关闭当前正在使用的窗口。
driver.close()
# # 主动结束与浏览器的会话,关闭浏览器,关闭驱动程序。
# driver.quit()
页面常用的操作
"""
因为页面执行速度很快,UI需要加一些等待。-- 为了就看清楚
time.sleep(1) == 时间是秒的单位
"""
from selenium import webdriver
import time
# 启动一个空的浏览器程序,建立了浏览器的会话 后续的操作都是在这个会话上面做的,存在一个变量里 driver
driver = webdriver.Chrome() # 注意: Chrome 大写的,后面有括号; 写错了会有问题
# 第二步: 在启动的浏览器里输入网址 打开网站
driver.get("https://www.baidu.com/")
# 页面常用操作
# 1、最大化窗口
driver.maximize_window()
time.sleep(2)
# 2、刷新页面
driver.refresh()
time.sleep(2)
# 3、打开新的页面网址
driver.get("https://www.lagou.com/wn/")
time.sleep(2)
# 4、回退到上一个页面
driver.back()
time.sleep(2)
# 5、前进到下一个页面
driver.forward()
time.sleep(2)
# 6、获取页面源码
# print(driver.page_source)
# 7、获取页面的标题
print(driver.title)
# 8、获取页面的url
print(driver.current_url)
# 9、执行完用例之后 把打开的浏览器关闭
driver.close()
# driver.quit()
quit和close的区别
driver.close():关闭当前正在使用的窗口。
- 1、如果你的当前浏览器窗口只有一个情况下,它就会关闭窗口并且关闭浏览器
- 2、如果你的当前浏览器窗口有多个的情况下,它就会关闭driver驱动焦点所在的窗口
driver.quit():真正关闭浏览器(把所有的窗口都关闭,并且退出浏览器,关闭驱动程序)
进阶的用法:
- 获取页面的url地址
- 获取页面的标题
- 获取页面源码
# 6、获取页面源码
# print(driver.page_source)
# 7、获取页面的标题
print(driver.title)
# 8、获取页面的url
print(driver.current_url)
元素定位方法
并不是所有的页面内容都有直接对应的方法进行操作的,更多的内容操作需要使用特定方法进行元素的定位。要进行元素定位,需要先知道HTML页面的组成部分:
HTML页面的组成:HTML+CSS+javascript
1、HTML 是用来描述网页的一种语言。 指的是超文本标记语言 (Hyper Text Markup Language) ,HTML 不是一种编程语言,而是一种标记语言 (markup language)
- 负责定义页面呈现的内容:标签语言:<标签名>标签值</标签名>,每一种类型的元素都有自己独特的标签名来表示,是为了表达页面的内容,有统一的表达标准。
- 了解html网页结构:https://www.runoob.com/html/html-paragraphs.html --html页面是树形结 构。
- HTML标签也可称之为元素,元素的特征: 文本内容 ----- 【通过 F12可以查看页面源码】
- ctrl +F 可以调出来页面的 搜索框 可以用来搜索值 是否唯一。
- 所以元素有3个特征: - 1、标签名 : - input【输入】| a【超链接】| span | button- HTML 标签是由尖括号包围的关键词,比如, 标签通常是成对出现的,比如 和 ,标签对中的第一个标签是标签头,第二个标签是标签尾;- 2、属性 : - HTML 元素可拥有属性 : id name class等,元素通用的属性【常见的属性】- id - 在当前html页面当中,独一无二的身份标识。 但是请注意,它可能是变动的(一 般有数字的都很容易变化)。== 相当于人的身份证- class - 在当前html页面当中,并不唯一。一个元素可以有多个class值,用空格隔 开。 (不同的元素用同样的样式设计的,很多元素class一样): class="commenttext quickinput"- name - 在当前html页面当中,并不唯一。一般来讲跟当前元素的功能有关。- style - 样式,高 宽 背景图片 ---基本很少会用于元素定位- 3、文本内容:标签可以拥有文本内容, 就是标签头和标签尾中间的内容: text
2、CSS:Cascading style sheets控制页面该如何呈现,即布局设置;比如字体颜色,字体大小,在页面呈 现的大小等。
3、Javascript:可以让你页面依据不同的情形做不同的事情。
元素的八大定位方法:【selenium的版本:4.3.0】
元素定位的目标:找到要操作的元素(唯一),然后进行操作。一定要找到唯一的元素,如果找到多个,就考虑换一个定位方法。 8大元素定位:分为2大类
代码里查找元素的方法: driver.find_element()
第一大类(6个):只根据元素的单一特征定位。 ==用的少
- 1、id属性 : 优先选择,因为id一般都是唯一的。
import timefrom selenium import webdriverfrom selenium.webdriver.common.by import Bybrowser = webdriver.Chrome()browser.get("https://www.baidu.com")browser.find_element(By.ID,'kw').clear()browser.find_element(By.ID,'kw').send_keys('selenium')browser.find_element(By.ID,'su').click()time.sleep(20)browser.quit() - 2、class属性: 样式,比如颜色,宽高 大小等 ,可以修改。但是要确保class的属性值是唯一的才可以 用。
from selenium import webdriverfrom selenium.webdriver.common.by import By驱动 = webdriver.Chrome()驱动.get("https://www.baidu.com/")驱动.find_element(By.CLASS_NAME,'s_ipt').send_keys("美女")驱动.find_element(By.ID,'su').click()驱动.sleep(20)驱动.quit() - 3、name属性
from selenium import webdriver驱动 = webdriver.Chrome()from selenium.webdriver.common.by import By驱动.get("https://www.baidu.com")驱动.find_element(By.NAME,"wd").send_keys('美女')驱动.find_element(By.ID,'su').click()驱动.sleep(20)驱动.quit() - 4、tag_name属性 - 标签名 : 有多个重复的标签名,会默认找到第一个标签名 ;基本上不用,因为会 有很多个;
from selenium import webdriverfrom selenium.webdriver.common.by import By驱动 = webdriver.Chrome()驱动.get("https://www.baidu.com")驱动.find_element(By.TAG_NAME,"input")驱动.find_element(By.ID,'su').click() - 5、link_text:a元素的文本内容完全匹配: a标签是一个超链接元素,超链接元素有属性target="_blank",超链接会打开一个新的窗口,否 则就是在原窗口上打开新页面 【测试派的文章元素】----注意,后面学习窗口切换会用。
from selenium import webdriverfrom selenium.webdriver.common.by import By驱动 = webdriver.Chrome()驱动.get("https://www.baidu.com")驱动.find_element(By.LINK_TEXT,"hao123").click()驱动.sleep(20)驱动.quit() - 6、partial_link_text: a元素的文本内容部分匹配,当文本内容非常长的时候用部分匹配。
from selenium import webdriverfrom selenium.webdriver.common.by import By驱动 = webdriver.Chrome()驱动.get("https://www.baidu.com")#文本精准匹配驱动.find_element(By.LINK_TEXT,"hao123").click()#文本模糊匹配驱动.find_element(By.PARTIAL_LINK_TEXT,'帮助').click()驱动.sleep(20)驱动.quit()
第二大类(2个):组合元素的特征以及关系来定位。 万能定位。==用的很多
- xpath定位(相对) :万能,推荐使用,重点学习。
- css selector:有弊端,不能支持文本定位,但是xpath可以。而且只支持web页面,app不支持。所 以不如xpath用的多。
css选择器元素定位
1、根据标签名定位 :它的问题是不唯一,一般页面中会有很多相同标签的元素,所以基本不用
driver.find_element(By.CSS_SELECTOR,"input");
2、根据ID定位
driver.find_element(By.CSS_SELECTOR,"#kw");
driver.find_element(By.CSS_SELECTOR,"标签名#id"); //使用html标签拼上#id
3、根据className定位: 可以支持多个样式一起写
driver.find_element(By.CSS_SELECTOR,".样式名");
driver.find_element(By.CSS_SELECTOR,"标签名.样式名"); //标签名拼上样式
4、单属性选择定位: 需要其他的属性一起定位,可以用标签[属性名=“属性值”]
driver.find_element(By.CSS_SELECTOR,"标签名[属性名='属性值']");
5、多属性选择定位: 如果一个属性不能唯一定位,用个属性组合
driver.find_element(By.CSS_SELECTOR,"标签名[属性1='属性值'][属性2='属性值']");
xpath元素定位:支持web页面+App页+小程序 ,高级强大,重点。
- xpath其实就是一个path(路径),一个描述页面元素位置信息的路径,相当于元素的坐标
- xpath基于XML文档树状结构,是XML路径语言,用来查询xml文档中的节点
- 既可以用于XML,也可以用于HTML(因为XML与HTML结构类似,所以xpath都可以解析)
绝对路径:从根节点开始,一层一层写出来,直到要找到元素。父/子 路径和位置都涵盖 了,所以特别不稳定。
- 从根节点(/)开始,一层一层写出来,直到要找到元素。父/子 【路径和位置依赖】 copy xpath :/html/body/div[2]/div[2]/div/div[1]/div[2]/ul/li[1]/a[2] -- 9代单传的路径。
相对路径: 以//开头,相对于某个节点的路径来找通过条件在html里面找。
在页面当中查看xpath表达式,可以匹配多少元素:F12 -- ctrl + F
第一种写法:
- //元素标签名称[@属性=值] # 属性值是不变的。 == 区分一下css选择器
- //元素标签名称[text()=值] # 文本是不变的

//input[@placeholder="Say sth..."]
//a[text()="新闻"]
第二种写法:and or 来组合多个属性和文本 //元素标签名称[@属性=值 and @属性=值 and text()=值]

//a[@class="title fn__ellipsis" and @href="http://testingpai.com/article/1595507317340"]
//a[@target='_blank'and@class='mnav c-font-normal c-color-t'and text()="新闻"]
第三种:*代表通配符,表示筛选所有的标签名

//*[@id='kw']
//*[@class="sign-num"]
第四种方法:contains(text(), 包含的内容) contains(@属性名, 包含的内容)

- 什么情况下去使用:当你的文本/属性的值过长的情况,可以通过它来简化表达式 - 注意:写被包含的部分的时候,这部分内容必须是原始值连续的一段字串,不能是间隔的。
- 属性包含匹配 + 文本包含匹配
//标签名[contains(@属性名,'值')]#案例-百度的://span[contains(@class,'s-top-right-text')]//a[contains(@class,'mnav') and contains(text(),'新闻')]//span[contains(text(),"已有") and contains(text(),"人加入")]//span[contains(text(),"已有") and @class="member"]
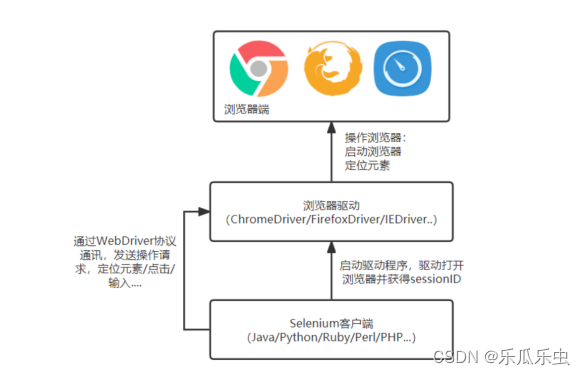
Selenium WebDriver原理
WebDriver协议(制定通讯的规则-底层基于http协议,作为一个翻译的角色):启动驱动程序,就是http 协议 监听某个端口【就是一个服务】; 由selenium代码向他发起请求。实现各种操作。
The WebDriver Wire Protocol,由Selenium基于Http设计并定义的协议,各大浏览器厂商都提供了实现 了该协议的驱动程序(ChromeDriver,Geckodriver、EdgeDriver等),通过这套协议我们可以操作浏览 器实现各种控制动作:打开、关闭、最大化、最小化、元素定位、元素操作等等。
原理:核心部分通过统一化WebDriver协议通讯,客户端(代码段端)会发送法指令给驱动程序,驱动程 序是由不同的浏览器厂商开发的,驱动程序会自己内部将指令翻译,再去将翻译之后的指令做转发,转发 给浏览器,浏览器就能去执行对应的指令并且将结果告诉给客户端。
1、按照html页面的顺序,从上到下定位。--层级定位
写法://.......//.......//.....
- 第一个//, 在整个html当中从上到下去查找
- 第二个//, 以第一个//找到的元素为根元素,在它的子孙后代当中去找。 - 注意如果是一个/ 就是儿子 不是所有的后代。
- 示例: //div[@class="number"]//p
轴定位
什么情况下用到轴定位:如果元素之间有父子关系(儿子找爸爸)、兄弟关系 (找哥哥/找弟弟)
- 从子孙元素,倒着找父元素或者祖先元素。
- 从兄弟姐妹元素,顺着关系找到其它的兄弟姐妹。 - 关系疏理:要找的元素,是已知元素的 xxx 关系。
- 以下6个轴定位,重点关注标黑的三个: - 语法 : //已找到的元素/轴定位名称::元素名称[....]
轴名称释义
选择当前节点的所有祖先节点。(包括父节点)**ancestorparent
**选择当前节点的父节点。
child
选择当前节点的所有子节点。
descendant
选择当前节点的所有后代节点。**
following-sibling
选择当前节点之后的所有同级节点。(找弟弟)**
following
选择当前节点之后的所有节点,不包括后代节点。
preceding
选择当前节点之前的所有节点,不包括后代节点。**
preceding-sibling
**选择当前节点之前的所有同级节点。(找哥哥)
ancestor
//a[text()='新闻']/ancestor::div

**
parent
**
**
//a[text()='新闻']/parent::div
**

//a[text()='新闻']/parent::div//a[text()='地图']

child 与
following-sibling
//div[@class='mnav s-top-more-btn']/child::div/child::div//following-sibling::div

descendant
//div[@class='mnav s-top-more-btn']/child::div/descendant::a//div[text()='翻译']

**
preceding-sibling
**
//a[text()='网盘']/preceding-sibling::a/following-sibling::a[text()='地图']

定位到元素后代码操作 -find_element
- find_element --- 在页面当中找到匹配的第一个元素。返回的 WebElement对象 【就算元素定位的表达式不唯一,也会返回找到第一 个元素】
- find_elements --- 在页面当中,找到匹配的所有元素。返回的列表。列 表当中每个成员都是WebElement对象
By类中,定义了8种定位策略,可以直接导入使用:
from selenium.webdriver.common.by import By
driver.find_element(By.XPATH,"xpath表达式")
WebElement类当中定义常用的方法:
- send_keys() --- 输入 (Keys类定义了键盘上除了26个字母和0-9数字外其 它的按键。)
- click() --- 点击操作
- text --- 获取元素的文本内容(页面操作之后某些元素的文本发生变化)
- get_attribute() --- 获取元素的属性值
- clear() --- 清除内容
如果元素定位表达式对应的元素不在页面当中,则会报错 NoSuchElementException。
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
driver = webdriver.Chrome()
driver.get("http://baidu.com")
driver.maximize_window()
driver.find_element(By.ID, 'kw').clear()
sleep(2)
print(driver.find_element(By.ID, 'kw').get_attribute('class') )
driver.find_element(By.ID, 'kw').send_keys("selenium")
search_box_text = driver.find_element(By.ID, 'kw').text
print("-----------------:"+search_box_text)
sleep(2)
driver.find_element(By.ID, 'su').click
sleep(2)
driver.close()
搜索框(
<input>
元素)通常不会有可见的文本内容,因此
search_box_text
将返回一个空字符串。
版权归原作者 乐瓜乐虫 所有, 如有侵权,请联系我们删除。