
作者简介:肖杨,软件开发工程师
在数据密集型业务场景中,数据管理策略是否有效至关重要,它直接关系到系统性能与存储效率的提升。数据归档作为该策略的关键环节,不仅有助于优化数据库性能,还能有效降低存储成本。
在众多数据归档工具中,pt-archiver 深受 MySQL 用户青睐。我撰写此博客的目的,正是为了分享我对 pt-archiver 的亲身体验与深入测试,为大家提供一份详尽的试用报告。同时,我也借此机会向大家介绍我最近开发的 ob-archiver,这是一款专为 OceanBase 设计的数据归档命令行工具,期待能为大家带来便利与帮助。
1. pt-archiver 上手体验
最近在调研数据生命周期管理相关的工具,了解到 Percona-Toolkit 工具集中的 pt-archiver 很受 MySQL 用户的欢迎,于是打算上手体验下。Percona-Toolkit 工具集中包含了 30 多个命令行工具,已经开源了(GitHub - percona/percona-toolkit: Percona Toolkit: a collection of advanced open source command-line tools.),并且收获了 900+ Star。

废话不多说,直接上手试试吧~
1.1. 安装
# percona-toolkit 依赖 perl 环境库,需要提前安装
sudo yum install perl-DBI perl-DBD-MySQL perl-IO-Socket-SSL perl-Digest-MD5 perl-TermReadKey
# 安装 percona-toolkit rpm 包
sudo rpm -ivh percona-toolkit-3.5.5-1.el7.x86_64.rpm
# 验证 pt-archiver 命令是否可用
pt-archiver --version
1.2. 准备环境
pt-archiver 是针对 MySQL 设计的,没有对 OceanBase MySQL 模式做兼容处理。我这里使用的是 MySQL 5.7.42。
源端数据库/源表:gaoda_archive_source/employee
目标数据库/归档表:gaoda_archive_dest/employee_arc
源表的基本信息:1,000,000 rows with 6 columns
源表 DDL:
CREATE TABLE `employee` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`birthday` datetime DEFAULT NULL,
`weight` double DEFAULT NULL,
`gender` enum('MALE','FEMALE') DEFAULT NULL,
`description` tinytext,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8
1.3. 场景一:表归档到表
在目标数据库新建相同结构的归档表(必须提前新建,否则会报错)
逐行归档表数据,且不删除源端表已归档数据
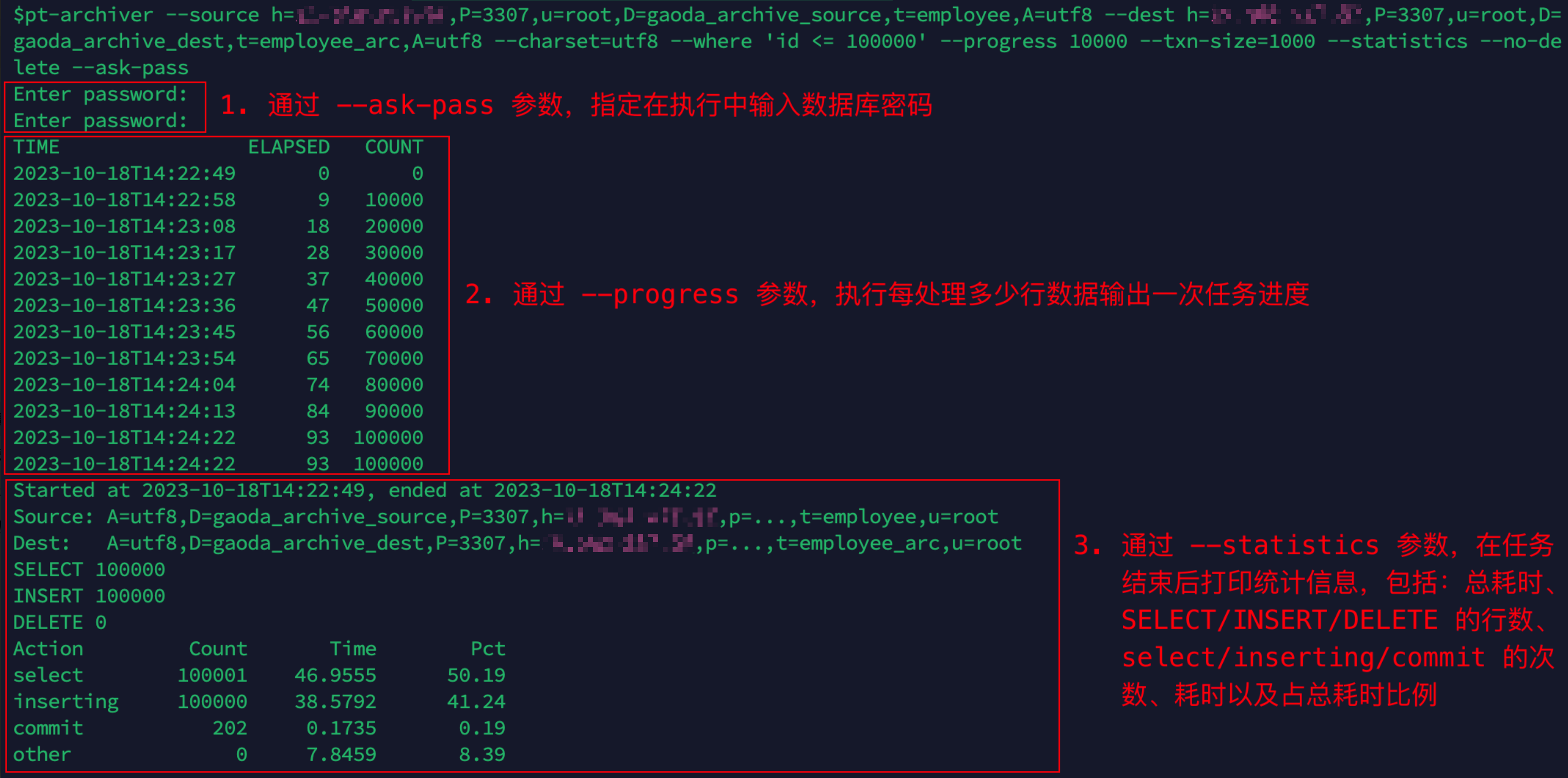
- 查看归档表数据
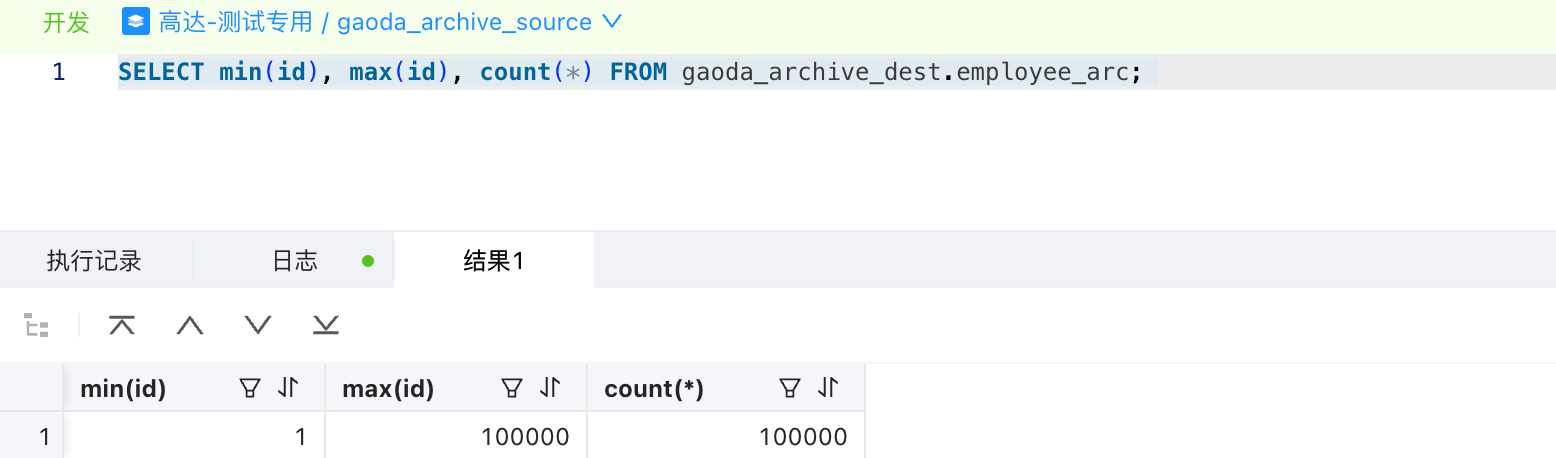
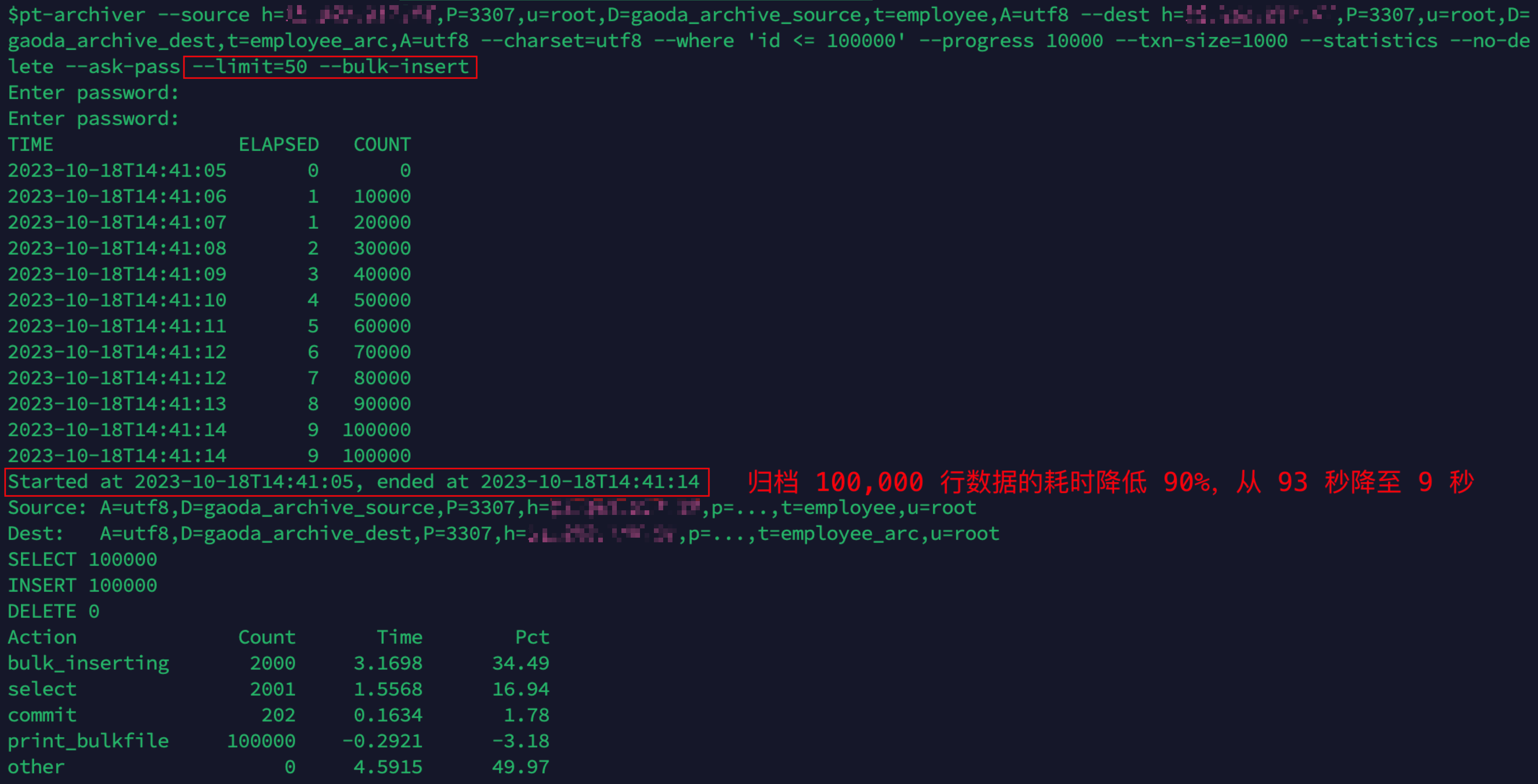
- TRUNCATE 归档表,然后在上述命令增加
```
--limit
和
--bulk-insert
选项以**批量**归档
### 1.4. 场景二:表归档到文件
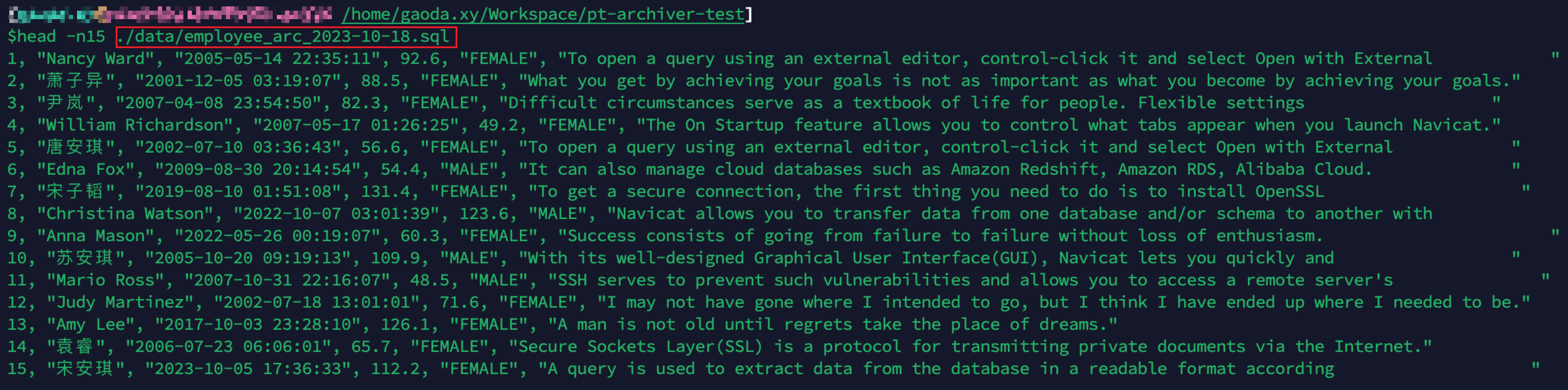
1. 归档 100,000 行表数据到文件(需要确保文件路径已存在)
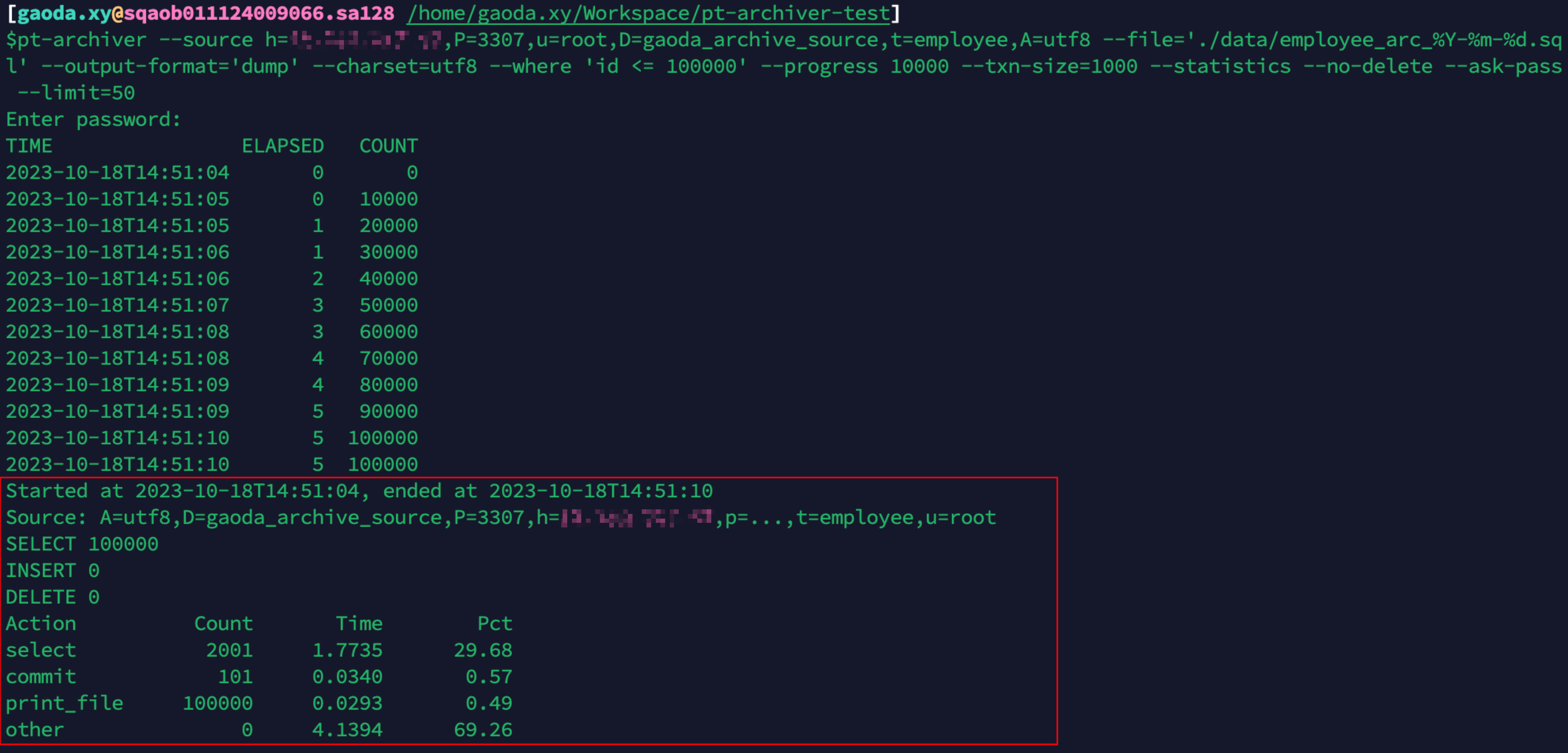
2. 查看归档文件
### 1.5. 场景三:数据清理
1. 通过
--purge
选项执行清理,通过
--dry-run
选项可以打印 SQL 并退出而不执行任何操作(类似
EXPLAIN
SQL)

2. 删除命令中的
--dry-run
选项,执行数据清理

### 1.6. 体验小结
pt-archiver 的试用过程是比较丝滑的。作为命令行工具,其安装和使用方法简单、参数清晰易懂、日志可读性好。最重要的是**轻量化,轻量化,还是 xxx 轻量化**,不需要打开任何专业软件就能归档大批量数据,这体验真的很爽啊。另外
--dry-run
选项查看执行计划的功能非常亮眼。
### 2. pt-archiver 深入测试
用起来很爽,但我更想了解 pt-archiver 归档、清理数据的底层逻辑,比如它的数据查询和删除策略、如何保障归档准确性。PT 官方描述是:
> The strategy is to find the first row(s), then scan some index forward-only to find more rows efficiently. Each subsequent query should not scan the entire table; it should seek into the index, then scan until it finds more archivable rows.
数据归档中,为了保障数据一致性和表查询效率,应该会对表结构(主键、索引、约束等)和 WHERE 条件(引用的列是否为索引列等)有一定的要求。pt-archiver 并没有在文档中作出明确说明,因此需要通过更深度地测试,分析其功能细节和使用限制。
### 2.1. 索引与约束
在下面的测试中,约束全部使用主键约束,索引全部使用普通索引。
**先说结论:pt-archiver 数据归档时,要求源表有主键或至少包含一个索引(任意类型),对 WHERE 条件中引用的列没有特殊要求。**如果表中存在主键,则使用主键拼接 WHERE 子句,并使用 ORDER BY 按序查询,使用 LIMIT 分批操作;如果表中不存在主键,则使用第一个索引。另外,pt-archiver 会添加 WHERE 子句条件限制具有 AUTO_INCREMENT 属性字段所对应的数据行操作(目的是为了在数据库重启之后,之前 AUTO_INCREMENT 的值还可以使用)。
以下是我的测试过程,不需要关注的同学建议直接跳过哈,因为太枯燥了~
#### 2.1.1. 表-无主键无索引
CREATE TABLE table_without_pk_and_index (
col1 varchar(120) DEFAULT NULL,
col2 varchar(120) DEFAULT NULL,
col3 varchar(120) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
运行报错:"Cannot find an ascendable index in table at /usr/bin/pt-archiver line 3262, <STDIN> line 2"。尝试通过使用
--no-ascend
并取消
--no-delete
选项来禁用升序索引优化(直译的,官方描述是 Ascending Index Optimization),仍然报上述错误,可以确认 **必须要有约束或索引**。
#### 2.1.2. 表-有主键无索引
CREATE TABLE table_only_with_pk (
col1 varchar(120) NOT NULL,
col2 varchar(120) DEFAULT NULL,
col3 varchar(120) DEFAULT NULL,
PRIMARY KEY (col1)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1. where 条件使用主键(varchar 类型):执行成功,数据准确
2. where 条件使用非主键:执行成功,数据准确
使用
--dry-run
查看执行 SQL 可以发现,**pt-archiver 会主动去寻找主键,并利用主键 order by 和 limit 来实现 forward 寻找列,并不依赖 WHERE 条件指定索引列**:

3. where 条件使用主键和非主键:执行成功,数据准确
#### 2.1.3. 表-无主键有索引
1. 仅有一个索引
CREATE TABLE table_only_with_index (
col1 varchar(255) DEFAULT NULL,
col2 varchar(255) DEFAULT NULL,
col3 varchar(255) DEFAULT NULL,
KEY idx_col1 (col1)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
a. where 条件使用索引:执行成功,数据准确
b. where 条件使用非索引:执行成功,数据准确
使用
--dry-run
查看执行 SQL 可以发现,**pt-archiver 会主动去寻找索引列,并利用索引列 order by 和 limit 来实现 forward 寻找列,并不依赖 WHERE 条件指定索引列,不过其 SQL 的 WHERE 子句的拼接与主键存在差异**:

**注意,这种情况下,理论上存在丢数据风险,下文会给出复现案例。**
c. where 条件使用索引和非索引:执行成功,数据准确
2. 存在多个索引
CREATE TABLE table_only_with_multi_index (
col1 varchar(255) DEFAULT NULL,
col2 varchar(255) DEFAULT NULL,
col3 varchar(255) DEFAULT NULL,
col4 varchar(255) DEFAULT NULL,
KEY idx_col1 (col1),
KEY idx_col2 (col2),
KEY idx_col3 (col3)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
当表中没有主键,但是存在多个索引时,**pt-archiver 默认只会使用第一个索引**:

如果使用
--no-ascend
选项来关闭升序索引优化,并删除
--no-delete
选项来及时清理已归档的数据,则 SELECT 语句中直接不会使用任何索引:

#### 2.1.4. 表-有主键有索引
CREATE TABLE table_with_pk_and_index (
col1 varchar(255) NOT NULL,
col2 varchar(255) DEFAULT NULL,
col3 varchar(255) DEFAULT NULL,
PRIMARY KEY (col1),
KEY idx_col2 (col2)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
如果表中**同时存在主键和索引,则 pt-archiver 在查询中只会使用主键**。
1. where 条件使用非索引列

2. where 条件使用索引列

### 2.2. 异常案例——归档时漏数据
源表结构和数据如下:
CREATE TABLE table_for_test (
col1 varchar(120) DEFAULT NULL,
col2 varchar(120) DEFAULT NULL,
col3 varchar(120) DEFAULT NULL,
KEY idx_col1 (col1) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8
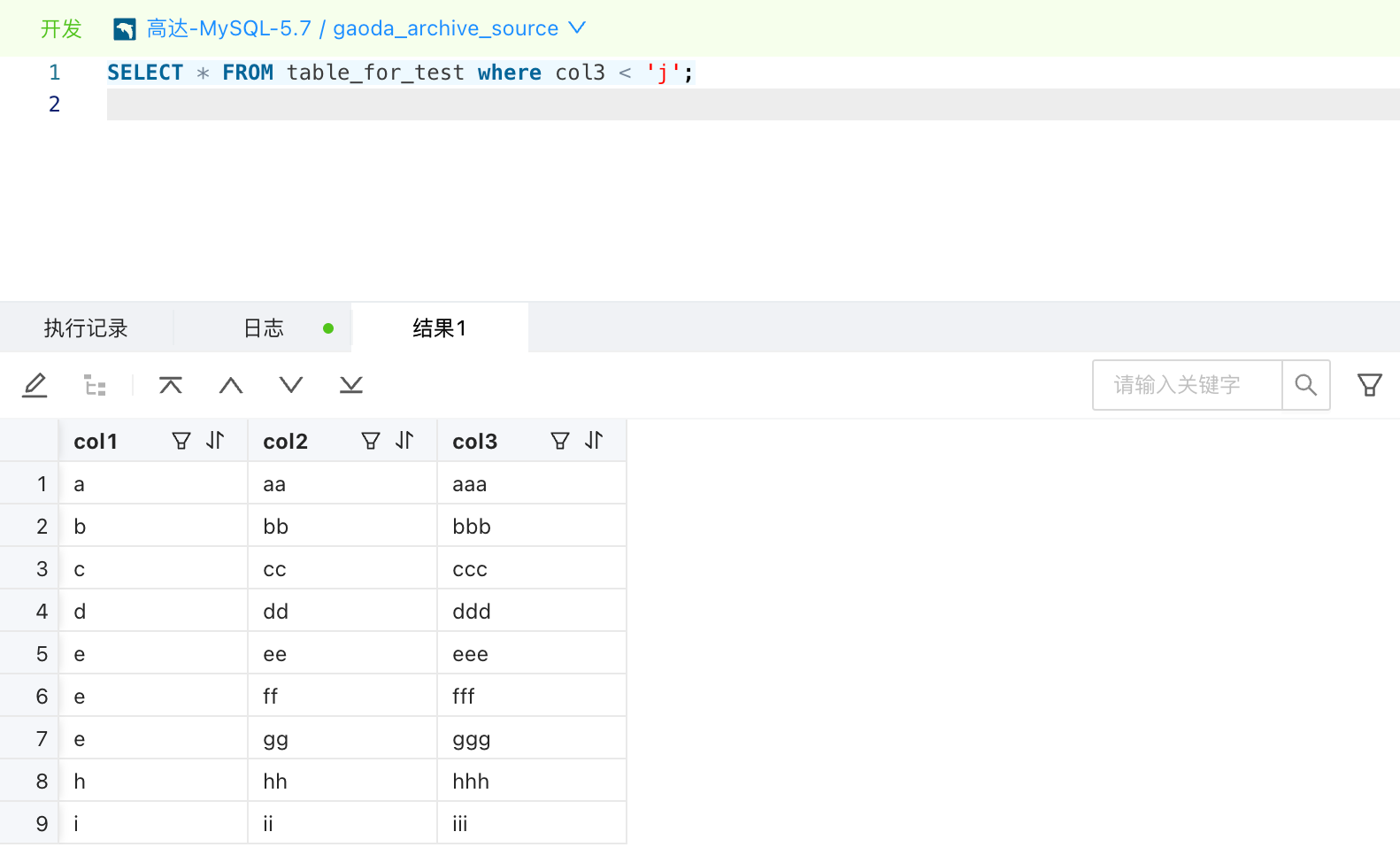
使用 pt-archiver 归档
WHERE col3 < 'j'
的数据,并且保留源端数据,执行以下命令:
pt-archiver --source h=xxx,P=3307,u=root,D=gaoda_archive_source,t=table_for_test,A=utf8 --dest h=xxx,P=3307,u=root,D=gaoda_archive_dest,t=table_for_test_arc,A=utf8 --charset=utf8 --where "col3 < 'j'" --progress 1 --txn-size=1 --statistics --no-delete --ask-pass --limit=5 --bulk-insert
```
预期应该归档 9 行数据,实际只归档了 7 条数据:

原因分析如下:

2.3. 原理浅析
根据前面的测试结果,推测 pt-archiver 的执行流程如下:

3. ob-archiver 来啦!
3.1. 功能简介
在 MySQL 领域,pt-archiver 以其轻量化、快捷易用而广受欢迎。然而在处理 OceanBase 数据库时,会遇到不兼容和效率不佳的问题:
- 4.x 版本 OB,无法使用
--bulk-insert批量插入功能。使用普通插入模式可以规避,但是性能差距约 6.5 倍 - 3.x 版本 OB,所有功能都无法使用,语法不支持
- 所有版本都无法设置
--charset=UTF8,因为 OB 用的是 utf8mb4
针对这一问题,我们开发了 ob-archiver。ob-archiver 是基于 OceanBase ODC 数据归档引擎 打造的轻量化命令行工具,兼容 pt-archiver 的命令行选项,并对 OceanBase 数据库提供原生支持和更强大的性能:
- 支持 MySQL 和 OceanBase MySQL 模式
- 支持数据限流
- 支持数据分片并发处理
「 后续会有文章揭秘 OceanBase ODC 数据归档引擎关键技术原理,例如断点恢复、数据校验、多维度限流、自动分片等,敬请期待 😚 」
3.2. 使用样例
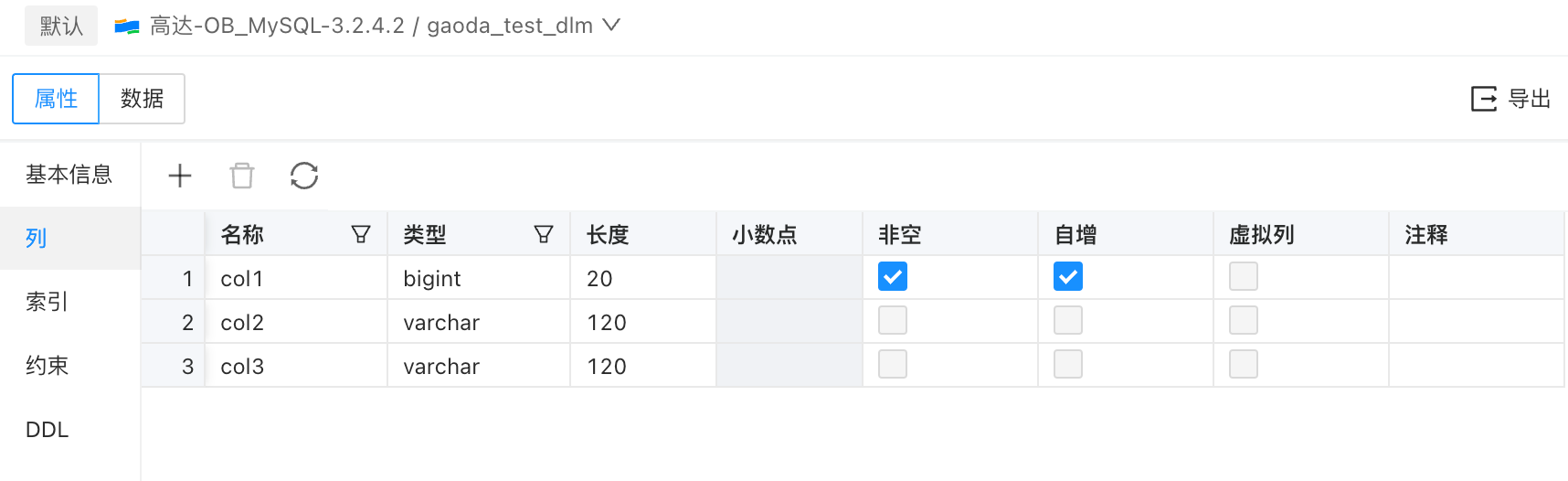
源表结构:
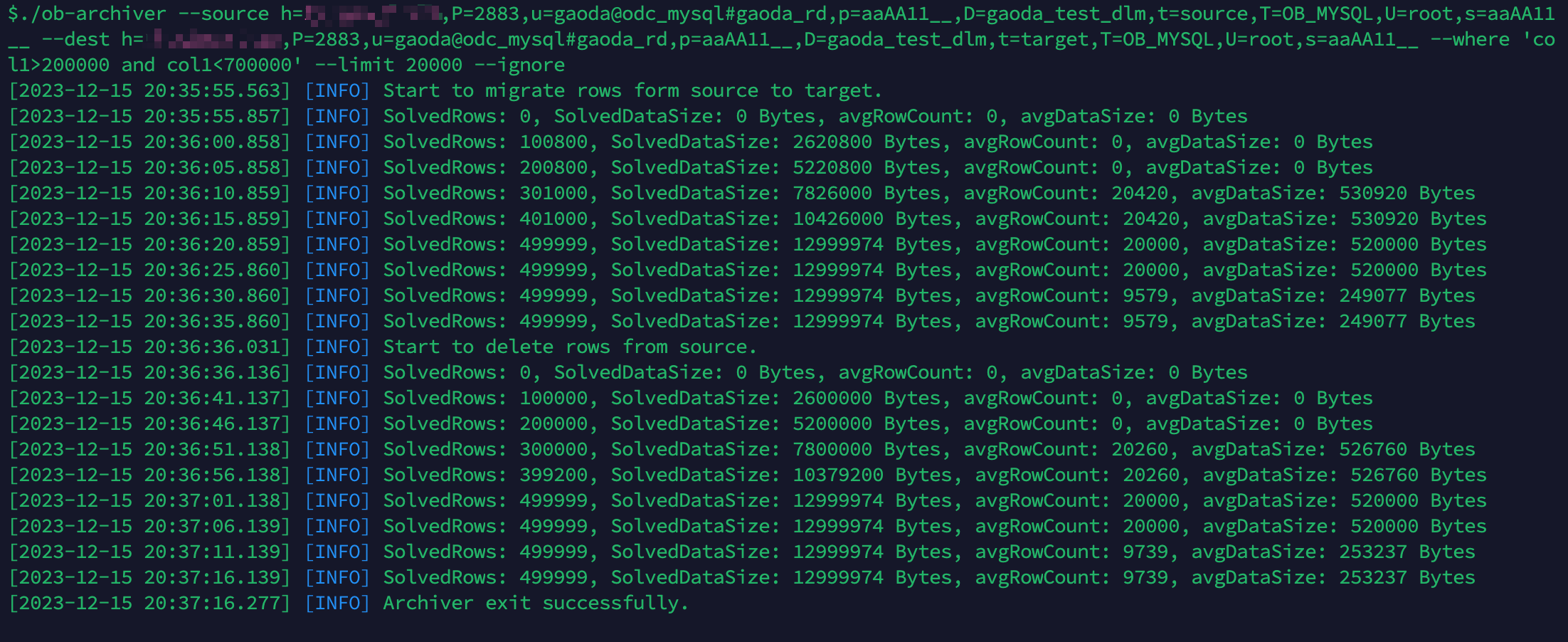
使用 ob-archiver 归档并清理源表中 col1 列在 200,000 和 700,000 之间的 499,999 行数据:
3.3. 下载使用
下载 ob-archiver 软件包并解压,按 README.md 文档指引使用。
ob-archiver-1.0.0-beta.tar.gz (15 MB)
ob-archiver-1.0.0-beta.zip (15 MB)
【结尾小彩蛋】 🎉
如果你不喜欢使用命令行工具,推荐使用 ODC(OceanBase Developer Center)体验完整的数据生命周期管理能力。可以通过 GUI 界面点点点,创建定时任务进行数据归档和清理工作,还支持断点恢复,从此解放双手,岂不美哉!点此直达。
版权归原作者 OceanBase数据库官方博客 所有, 如有侵权,请联系我们删除。