
**
【概述】
**
在使用jmeter的时候,需要对业务并发比例进行设置,可以一个业务对应一个线程组,设置数量进行并发比例设置,但这种方式不科学,因为并发事务数量依赖于事务响应时间,如果某个线程组内的取样器响应时间比较慢时,就影响最终的并发事务了。因此在同一个线程组中设置并发比例,是比较合理的。
**
【需求背景】
现在有个被测支付系统,支付业务有 微信被扫、支付宝被扫、公众号支付三个业务,模拟其并发比例为2: 3:5。
以下是通过随机数的生成概率来控制并发权重
【操作步骤】
**
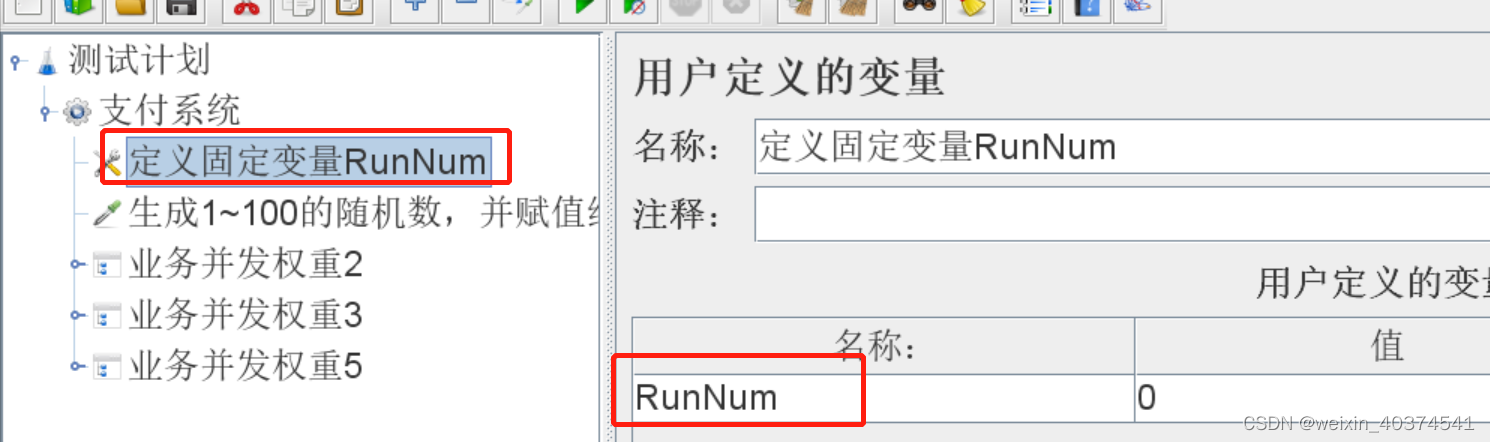
1、现在线程下面,设置“用户自定义变量”,比如RunNum,起到占位作用。 路径:配置元件—>用户自定义变量。
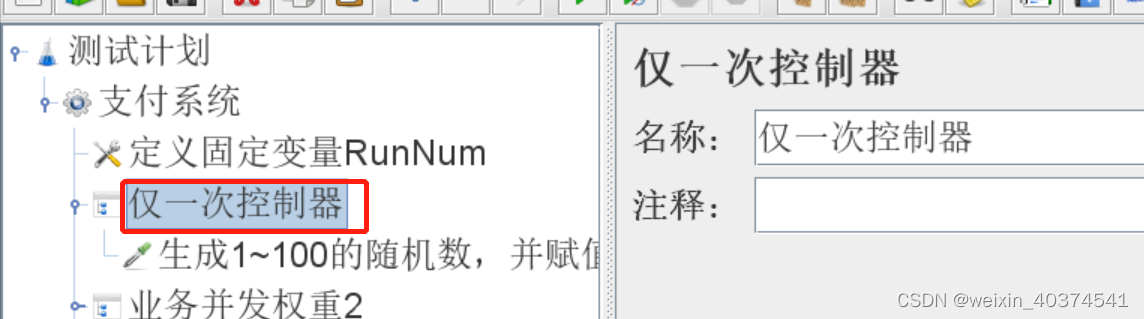
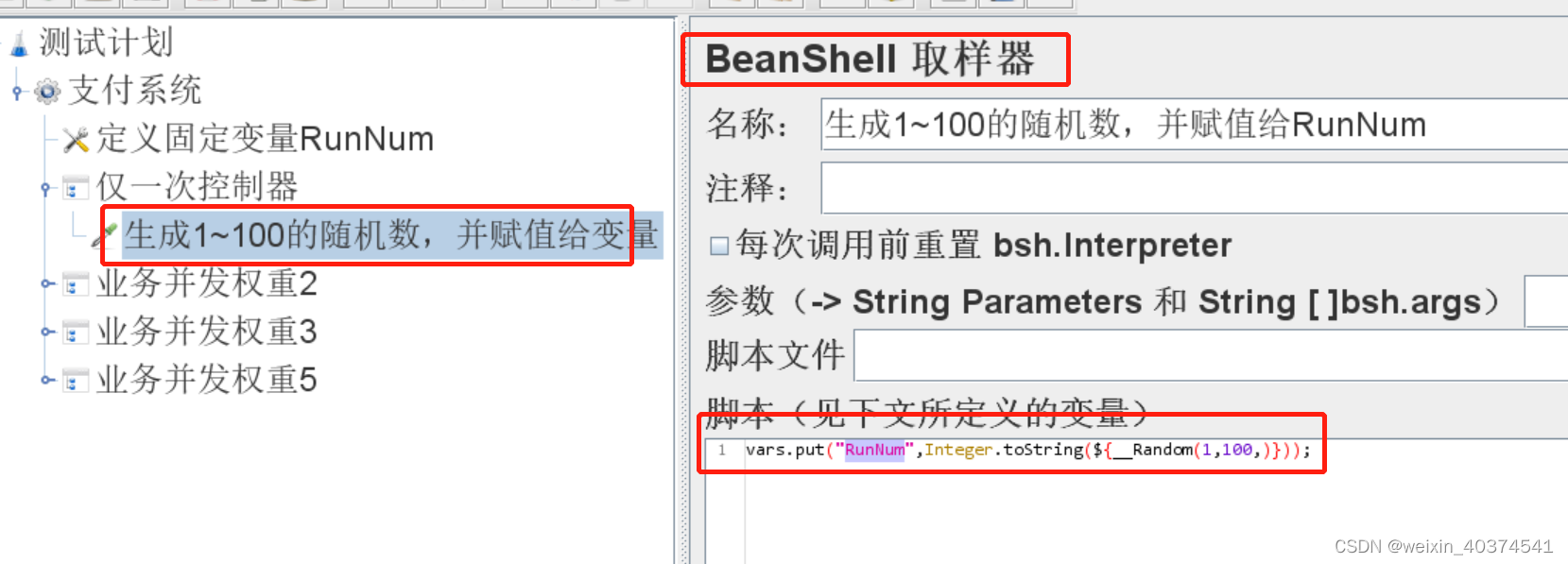
2、在线程组下面,添加“仅一次控制器”,然后添加beanshell,对RunNum进行赋值,值是使用随机函数生成的。
*
beanshell代码:vars.put(“RunNum”,Integer.toString(${__Random(1,100,)}));
beanshell代码解读:生成1~100的随机数,赋值给RunNum*
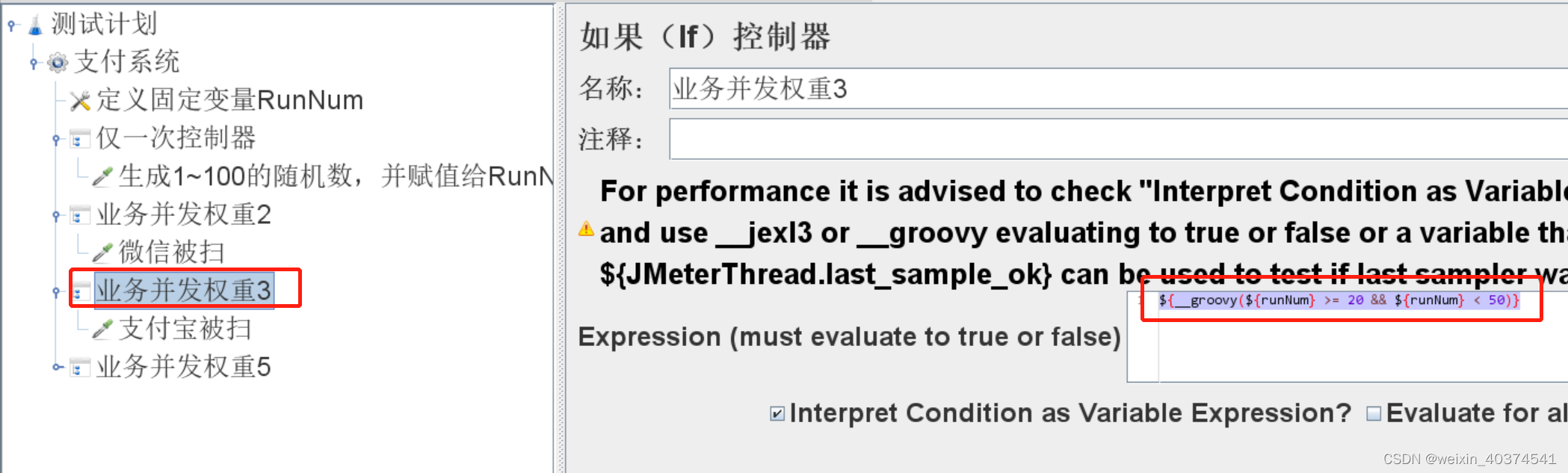
3、添加如果(if)逻辑控制器,控制随机数落在一个区间的时候,则触发下面的事件。
例如控制代码:
KaTeX parse error: Expected group after '_' at position 2: {_̲_groovy({runNum} < 20)} #如果RunNum小于20,那么就执行控制器下面的微信被扫取样器*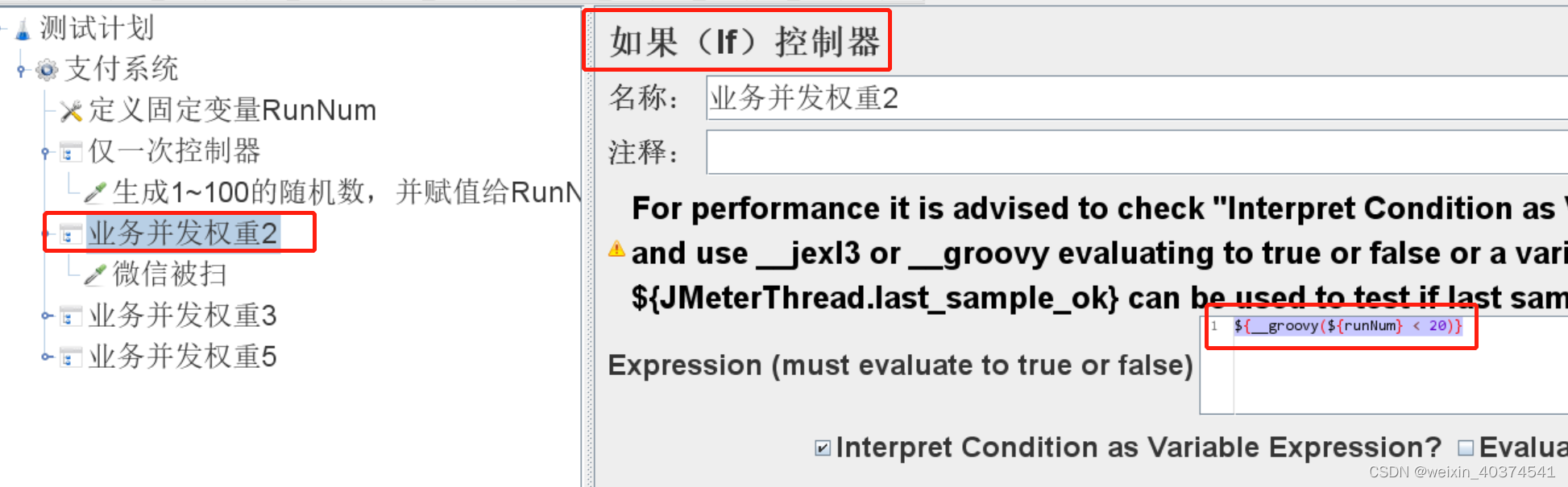
*KaTeX parse error: Expected group after '_' at position 2: {_̲_groovy({runNum} >= 20 && ${runNum} < 50)}
#如果RunNum大于等于20且小于50,那么就执行控制器下面的支付宝被扫取样器
KaTeX parse error: Expected group after '_' at position 2: {_̲_groovy({runNum} >= 50}
#如果RunNum大于50,那么就执行控制器下面的支付宝被扫取样器
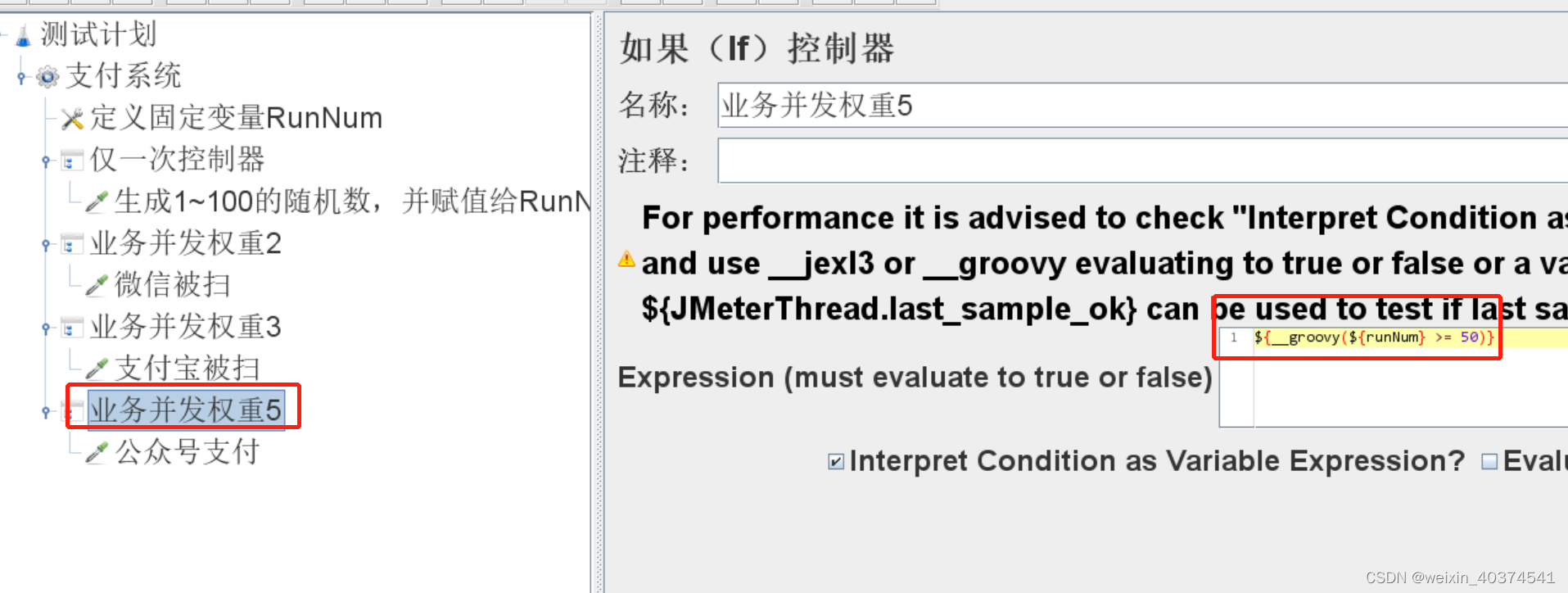
这样就可以实现并发比例的控制了。
总结
在各种并发比例控制方法中,这种是比较简单且容易理解的了。
其原理就是通过随机数“落点”区间的概率大小来控制并发。
版权归原作者 小昆虫抓bug 所有, 如有侵权,请联系我们删除。