
时间序列分解是一种技术,它将时间序列分解为几个部分,每个部分代表一个潜在的模式类别、趋势、季节性和噪声。在本教程中,我们将向您展示如何使用Python自动分解时间序列。
首先,我们来讨论一下时间序列的组成部分:
- 季节性:描述时间序列中的周期性信号。
- 趋势:描述时间序列是随时间递减、不变还是递增。
- 噪音:描述从时间序列中分离出季节性和趋势后剩下的东西。
换句话说,数据的可变性是模型无法解释的。
对于本例,我们将使用来自Kaggle的航空乘客数据。
import pandas as pd
import numpy as np
from statsmodels.tsa.seasonal import seasonal_decompose
#https://www.kaggle.com/rakannimer/air-passengers
df=pd.read_csv(‘AirPassengers.csv’)
df.head()
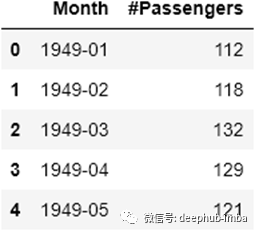
首先,我们需要将Month列设置为索引,并将其转换为Datetime对象。
df.set_index('Month',inplace=True)
df.index=pd.to_datetime(df.index)
#drop null values
df.dropna(inplace=True)
df.plot()
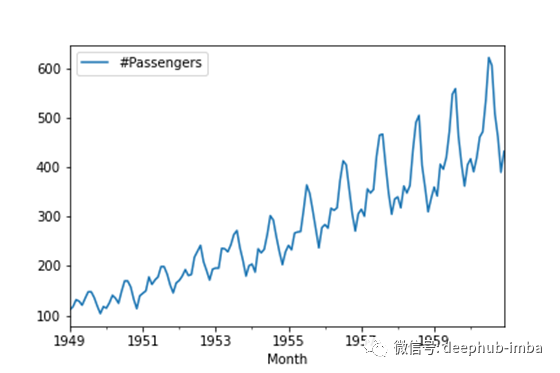
分解
我们将使用python的statmodels函数seasonal_decomposition。
result=seasonal_decompose(df['#Passengers'], model='multiplicable', period=12)
在季节性分解中,我们必须设置模型。我们可以将模型设为加的或乘的。选择正确模型的经验法则是,在我们的图中查看趋势和季节性变化是否在一段时间内相对恒定,换句话说,是线性的。如果是,那么我们将选择加性模型。否则,如果趋势和季节性变化随时间增加或减少,那么我们使用乘法模型。
我们这里的数据是按月汇总的。我们要分析的周期是按年的所以我们把周期设为12。
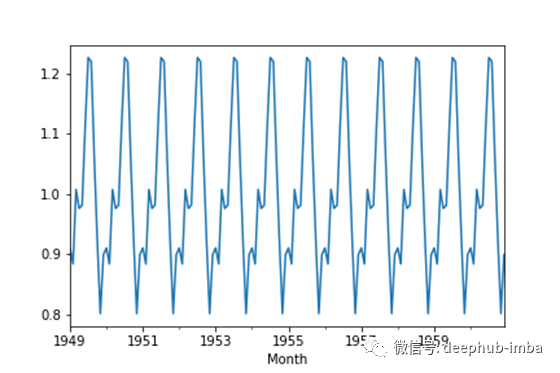
我们可以得到每个组件如下:
result.seasonal.plot()
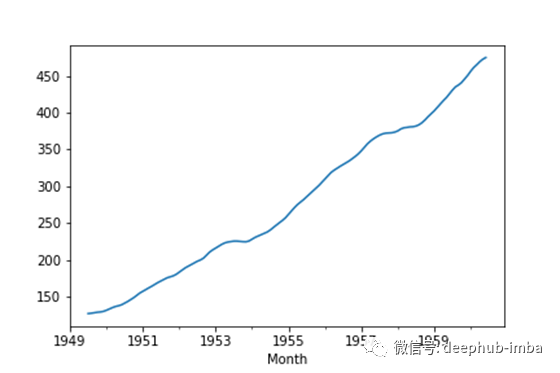
result.trend.plot()
同样,我们可以一次绘制每个组件
result.plot()
总结
通常,在查看时间序列数据时,很难手动提取趋势或识别季节性。幸运的是,我们可以自动分解时间序列,并帮助我们更清楚地了解组件,因为如果我们从数据中删除季节性,分析趋势会更容易,反之亦然。
作者:Billy Bonaros
deephub翻译组