
前言
我们知道,Hadoop常见的三种调度器:FIFO调度器(几乎不用,因为它是先来先服务)、容量调度器(Apache Hadoop 默认的调度器)、公平调度器(CDH默认调度器)。
其中,容量调度器和公平调度器都是支持多任务队列的,但是我们如果不去指定,它默认把任务都放到一个默认的队列(‘default’队列)当中去,如果提交的任务比较多,那么并发度肯定很低,毕竟每个队列都是一个FIFO队列。这就需要我们创建多个队列。
怎么创建队列
- 默认:调度器默认就 1 个 default 队列,不能满足生产要求(所有任务都在一个队列中,相当于在一个FIFO队列,并发度极低)。
- 按照框架:mr / hive /spark/ flink 每个框架的任务放入指定的队列(但是企业用的不是特别多,毕竟假如大公司,一次上万个任务,除以4之后每个队列的压力仍然很大
- 按照业务模块:登录注册、购物车、下单、业务部门 1、业务部门 2 ...(主流创建队列的方式)
创建多队列的好处
- 不用担心因为一个队列的原因,导致实习生直接一手递归死循环把整个集群资源耗尽干瘫痪。
- 降级使用,特殊时期保证重要的任务队列资源充足(双11、618)。
实际案例
需求
default 队列占总内存的 40%,最大资源容量占总资源 60%(也就是说当自己资源不足的时候,可以去抢占别人的资源,但是不能超过60%),hive 队列占总内存的 60%,最大资源容量占总资源 80%。
配置capacity-scheduler.xml
我们可以看到,目前default队列的总容量占总资源的100%,最大容量同样占100%。
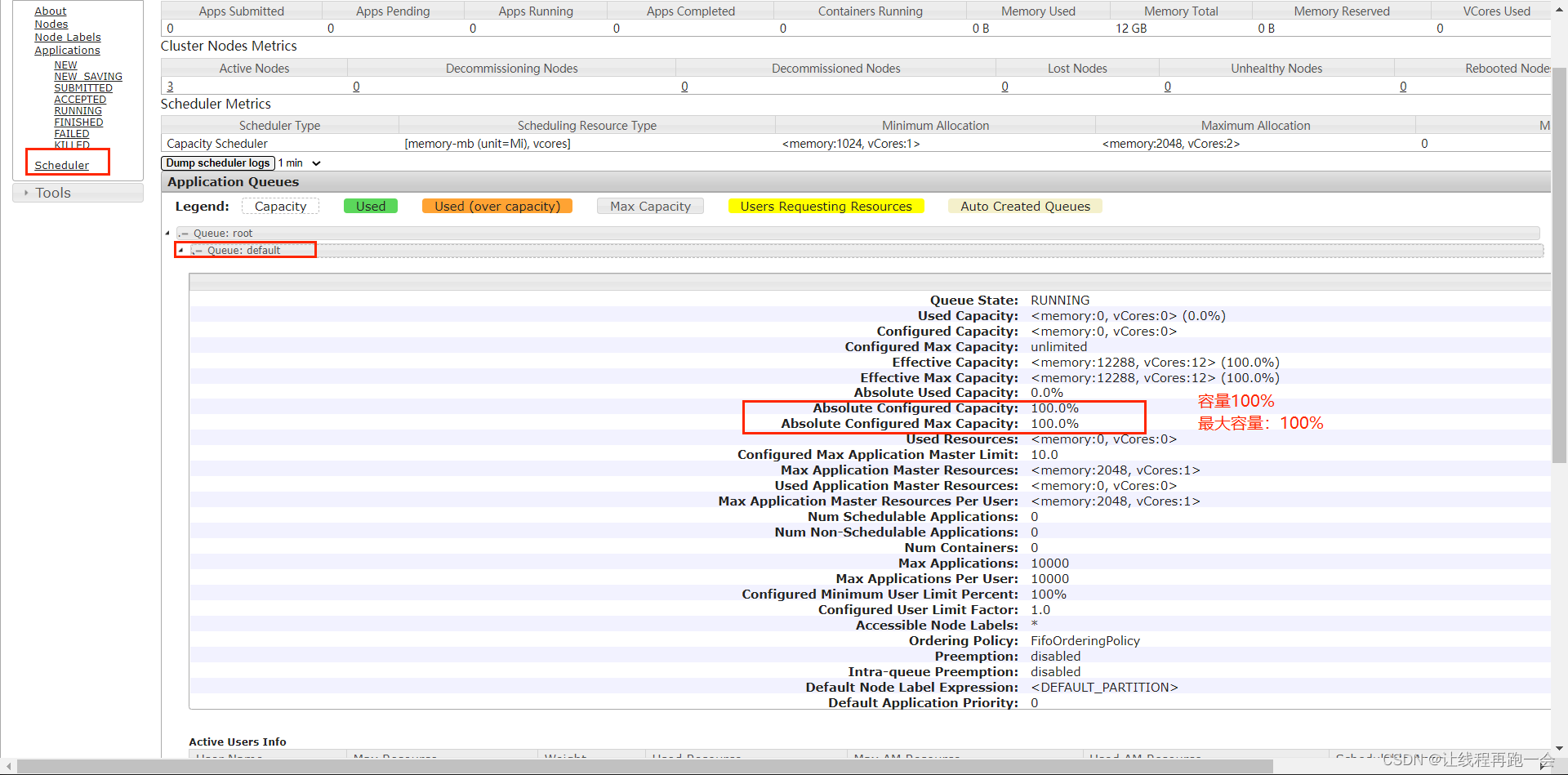
我们需要配置的是 hadoop3.1.3etc/hadoop/capacity-scheduler.xml

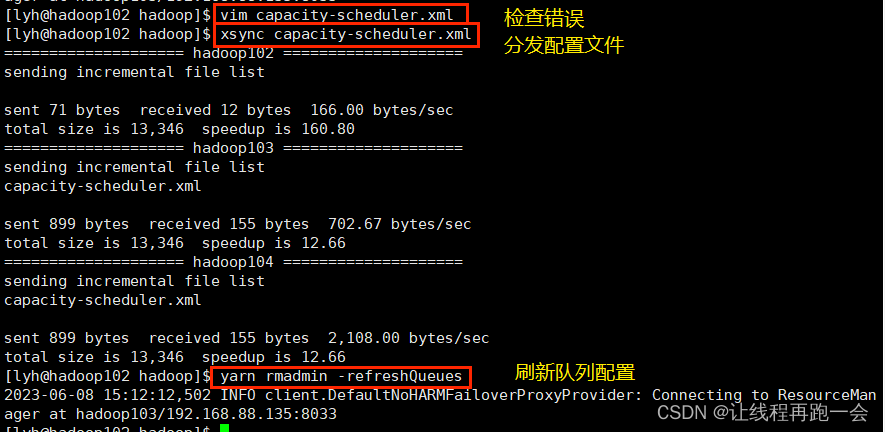
替换修改后的调度器配置文件

分发脚本

刷新队列
语法: ** yarn rmadmin -refreshQueues**
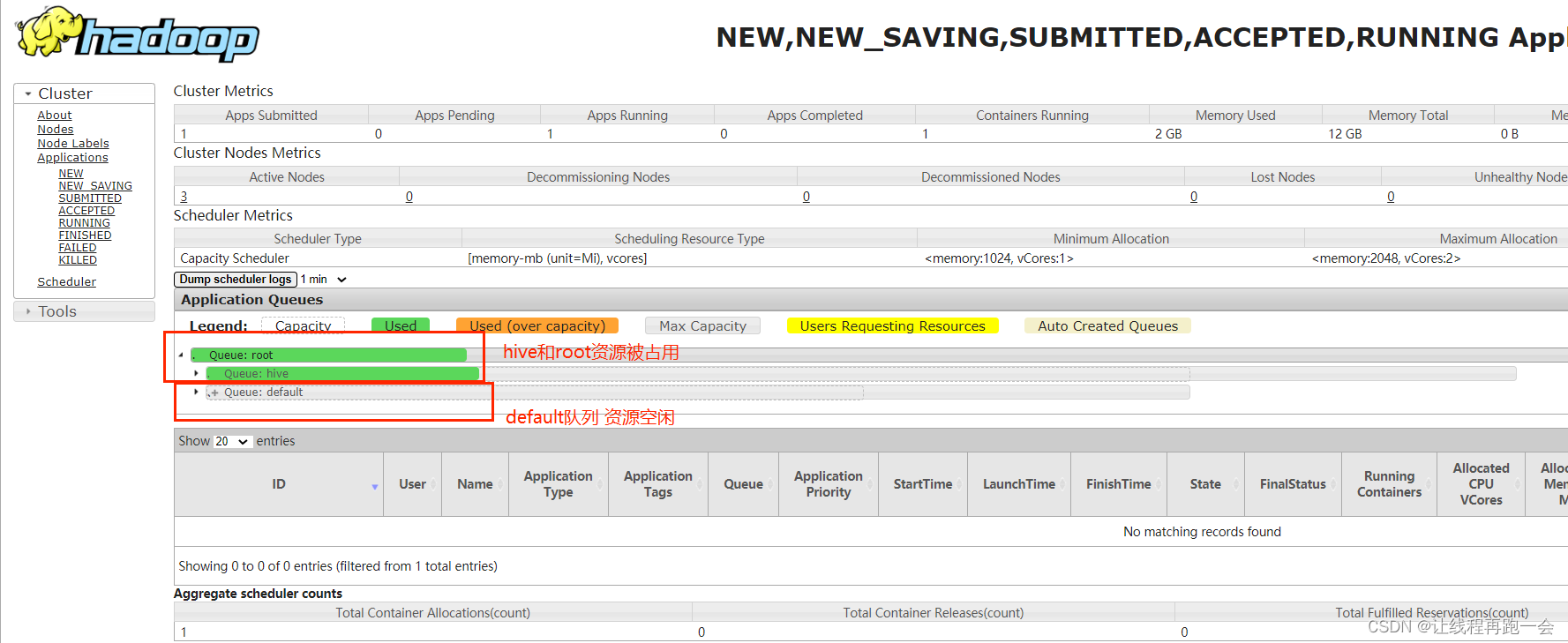
指定执行队列案例测试
使用wordcount案例进行测试,要求指定使用 hive 队列来提交任务。(不指定的话默认使用的是default队列)
命令:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount -D mapreduce.job.queuename=hive /wcinput /wcoutput2
此外,如果是我们自己编写的MapReduce程序,我们可以在Driver类中来指定提交任务的队列:
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
conf.set("mapreduce.job.queuename","hive");
//1. 获取一个 Job 实例
Job job = Job.getInstance(conf);
//....
//6. 提交 Job
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
容量调度器下的任务优先级
容量调度器,支持任务优先级的配置,在资源紧张时,优先级高的任务将优先获取资源。
默认情况,Yarn 将所有任务的优先级限制为 0(也就是说,默认每个队列都是一个FIFO队列,按照先来先服务的原则),若想使用任务的优先级功能,须开放该限制。
1、修改yarn-site.xml
设置5个优先级等级
<property>
<name>yarn.cluster.max-application-priority</name>
<value>5</value>
</property>
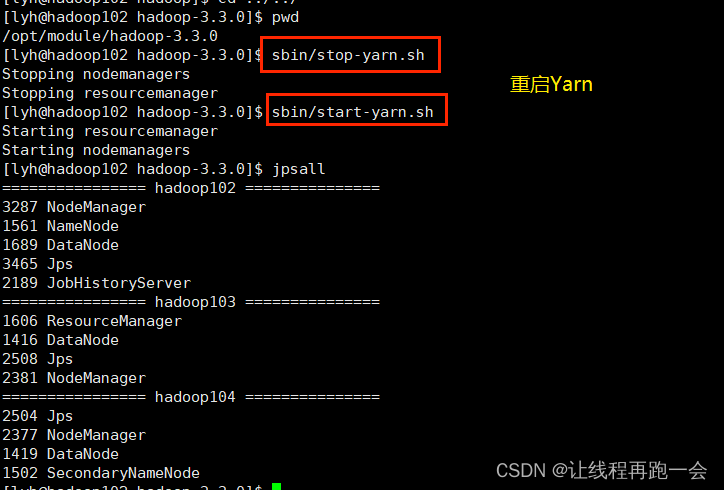
2、分发配置、重启Yarn
更新了yarn-site.xml需要重启yarn才能生效
3、提交任务时指定任务优先级
hadoop jar /opt/module/hadoop-3.3.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar pi -D mapreduce.job.priority=5 5 2000000
4、提交任务后指定任务优先级
yarn application -appID application_1611133087930_0009 -updatePriority 5
本文转载自: https://blog.csdn.net/m0_64261982/article/details/131096123
版权归原作者 让线程再跑一会 所有, 如有侵权,请联系我们删除。
版权归原作者 让线程再跑一会 所有, 如有侵权,请联系我们删除。