


背景
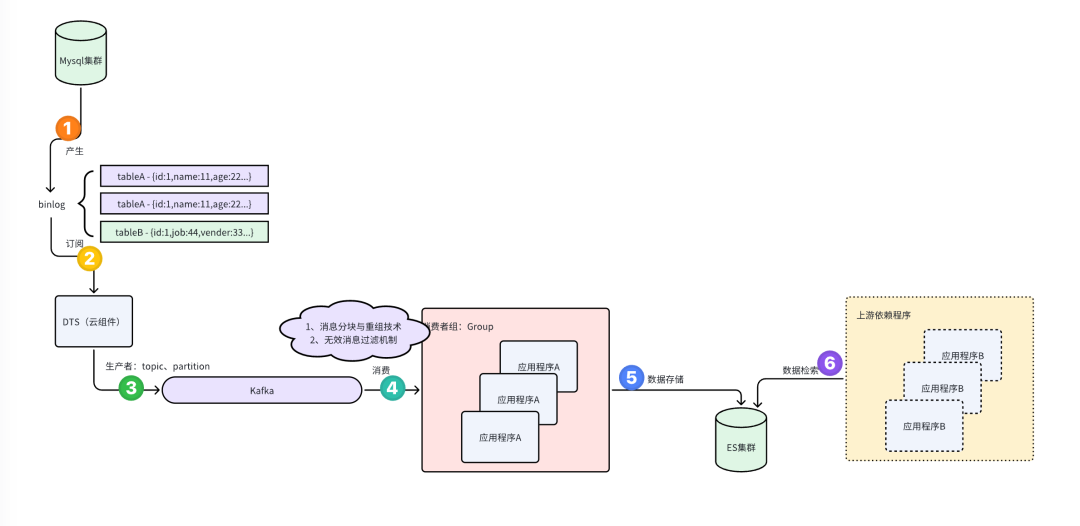
业务架构图
根据 微服务重构:Mysql+DTS+Kafka+ElasticSearch解决跨表检索难题所描述,我们使用了Es解决微服务重构中遇到的Mysql库拆分问题,业务架构图如下所示:
Kakfa消息堆积导致的数据一致性问题
在下午14:15左右,收到用户反馈,短暂时间内,出现了业务数据一致性问题
具体表现是:用户提交了一个页面操作,但是在查询接口里,没有返回最新的操作结果
具体校验是:通过问题反馈,我们直接对比DB和Es的具体索引,确实发现es的索引数据没有更新到
binLog/redoLog/undoLog对比
log类型日志类型作用数据类型用法支持级别redo log物理日志 -
在xx数据页做了xx修改”称为重做日志,当MySQL服务器意外崩溃或者宕机后,保证已经提交的事务持久化到磁盘中(持久性)redo log 数据主要分为两类:
内存中的日志缓冲(redo log buffer)
磁盘上的日志文件(redo logfile)- 崩溃恢复Innodb存储引擎undo log物理日志 -
在xx数据页做了xx修改”事务可以进行回滚从而保证事务操作原子性则是通过undo log 来保证的undo log 数据主要分两类:insert undo log
update undo log- 事务回滚
MVCCInnodb存储引擎bin log逻辑日志 -
记录内容是语句的原始逻辑记录了对MySQL数据库执行更改的所有的写操作,包括所有对数据库的数据、表结构、索引等等变更的操作。三种格式,分别为 STATMENT 、 ROW 和 MIXED- 数据恢复主从复制MySQL Server层
分析:redo log和undo log都是物理日志,记录的是“在某个数据页做了什么修改”,属于Innodb存储引擎,如果换了一个存储引擎,这俩能力都将不复存在,它们分别是用来。binlog日志是逻辑日志,记录内容是语句的原始逻辑,属于MySQL Server层。所有的存储引擎只要发生了数据更新,都会产生binlog日志,binlog会记录所有涉及更新数据的逻辑规则,并且按顺序写。redo log 和undo log的核心是为了保证innodb事务机制中的持久性和原子性,事务提交成功由redo log保证数据持久性,而事务可以进行回滚从而保证事务操作原子性则是通过undo log 来保证的。
binlog 数据格式
能力
优点
不足
备注
ROW
基于行的复制(row-based replication, RBR),不记录每条SQL语句的上下文信息,仅需记录哪条数据被修改了
稳定性较好,不会出现某些特定情况下的存储过程、或function、或trigger的调用和触发无法被正确复制的问题;
会产生大量的日志,尤其是 alter table 的时候会让日志暴涨。
MySQL 5.7.7 之后,默认值是 ROW
STATMENT
基于SQL语句的复制( statement-based replication, SBR ),每一条会修改数据的SQL语句会记录到 binlog 中
不需要记录每一行的变化,减少了 binlog 日志量,节约了 IO , 从而提高了性能;
在某些情况下会导致主从数据不一致,比如执行sysdate() 、 slepp() 等
MySQL 5.7.7 之前,默认的格式是 STATEMENT
MIXED
基于 STATMENT 和 ROW 两种模式的混合复制(mixed-based replication, MBR),一般的复制使用 STATEMENT 模式保存 binlog ,对于一些函数,STATEMENT 模式无法复制的操作使用 ROW 模式保存 binlog。
小结
binlog 是MySQL server层的日志,而redo log 和undo log都是引擎层(InnoDB)的日志,要换其他数据引擎那么就未必有redo log和undo log了。
它的设计目标是支持innodb的“事务”的特性,事务ACID特性分别是原子性、一致性、隔离性、持久性, 一致性是事务的最终追求的目标,隔离性、原子性、持久性是达成一致性目标的手段,根据的之前的介绍我们已经知道隔离性是通过锁机制来实现的,而事务的原子性和持久性则是通过redo log 和undo log来保障的。
排查流程
流程步骤如下所示:
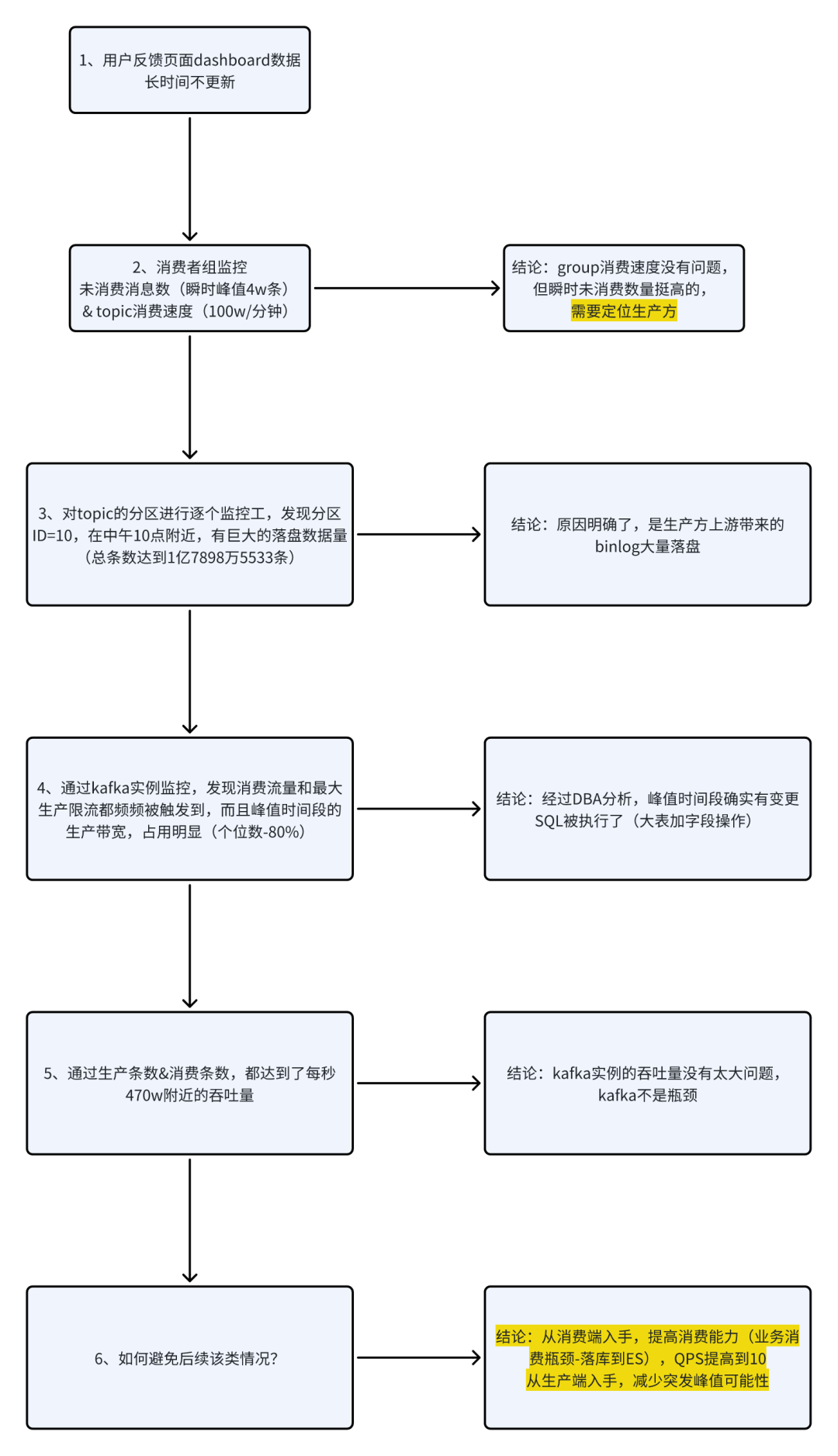
1、Kafka消费者组-监控
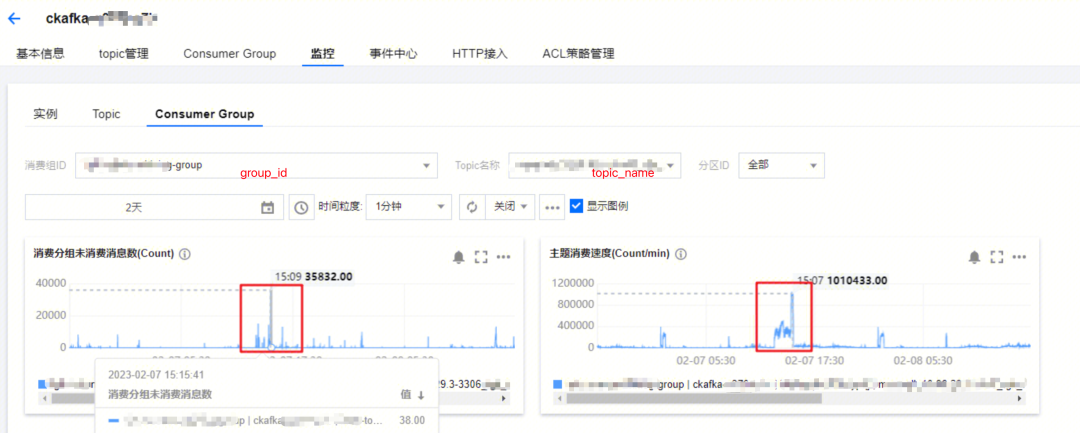
通过云组件监控,可以得到:
- 从14:00起,kafka不断有待消费数据的毛刺点出现,同时kafka的具体topic消费速度也随着毛刺点出现而升高
- 在15:15前后有一个未消费消息数的峰值接近 4w条/分钟
结论:
- 某个group对topic进行的消费,出现了大量消息堆积,导致了下游业务的数据一致性问题
- 虽然产生了消费的波峰,但远未达到ckafka的消费瓶颈,因为Kafka是号称百万吞吐量的中间件
方向:
- 需要定位消息产生方,为什么会出现瞬时流量顶点
2、Kafka的topic分区消息堆积情况-监控
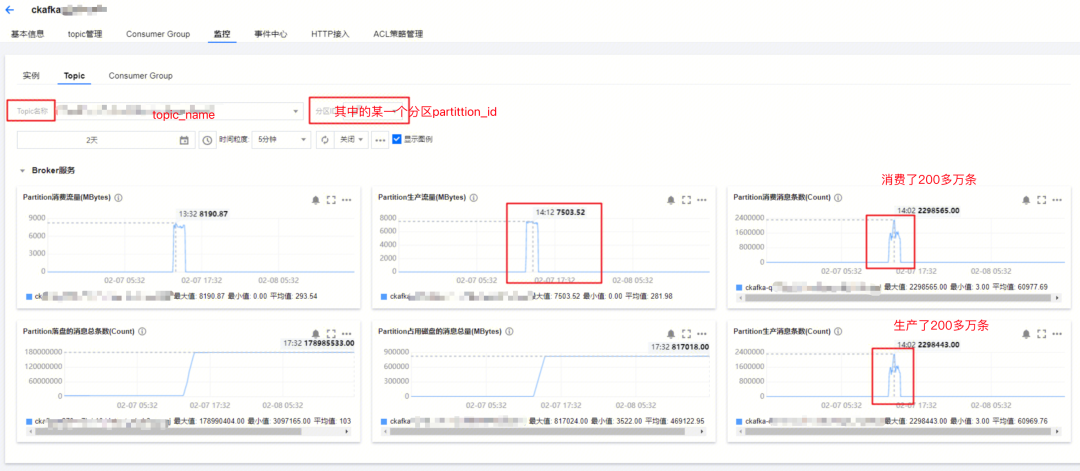
分析:
- topic级别监控,知道某一分区,存在大量被写入和被消费的情况
3、kakfa实例监控
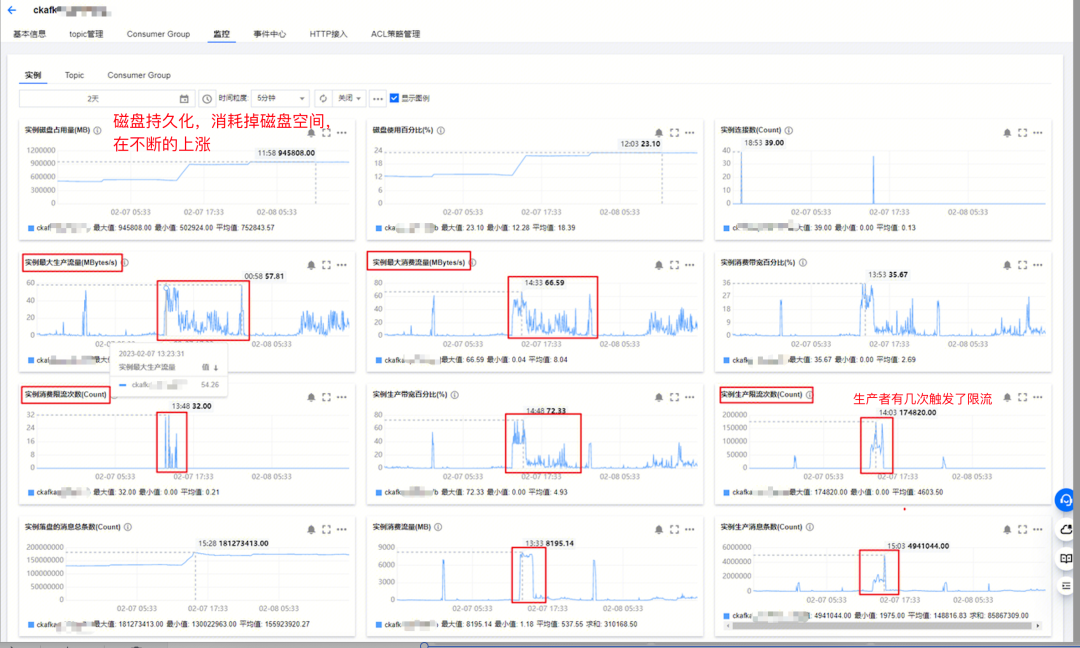
分析:
- kafka实例监控,各类指标挺多的,但都属于正常的范围
- 不存在以下情况:- 某个生产者环境阻塞,导致的消费瓶颈- 也不存在带宽到了瓶颈,阻塞了消息生产和消费- 实例的流量读入、读出都符合正常的云组件性能要求
4、生产者和消费者能力监控
Kafka 实例监控的指标有很多,我们主要关注下面几个:
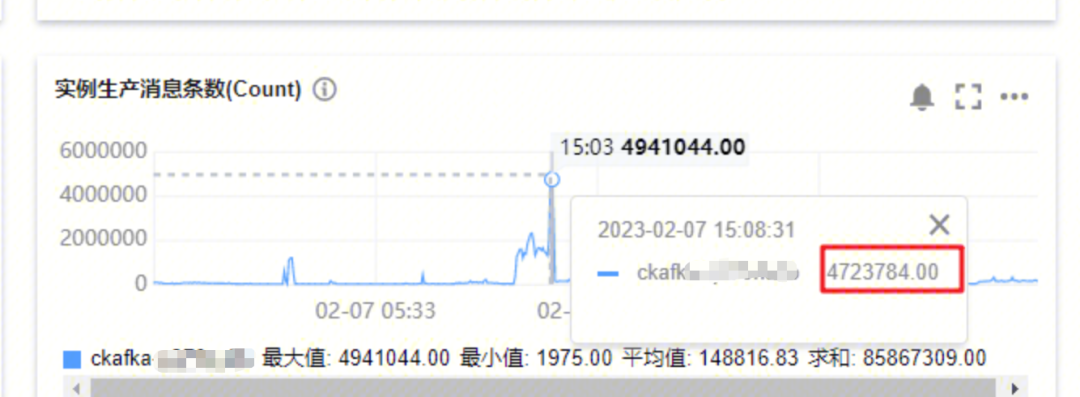
- 实例生产消息总数:
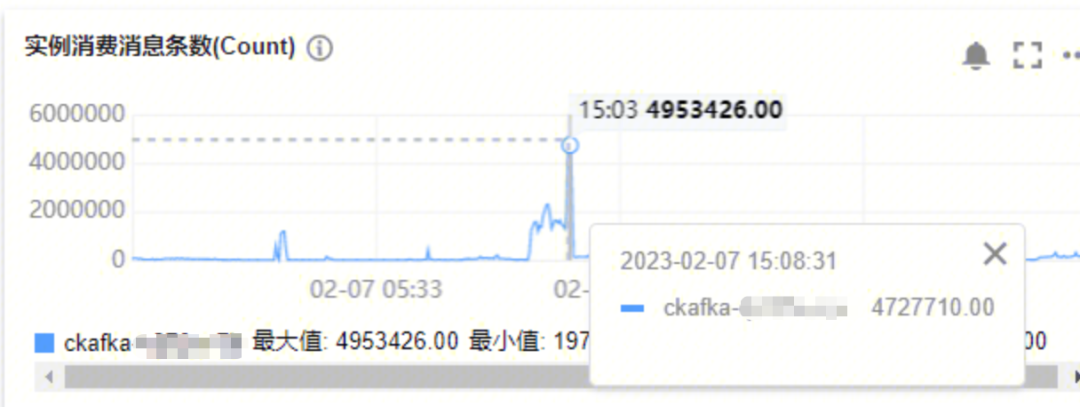
- 实例消费消息总数:
结论是:
- 最大生成消息数量是473w,最大消息消费速度是472w,Kakfa的生产和消费都很正常。
- kafka实例的吞吐量没有太大问题,kafka不是瓶颈
5、运维SQL变更
通过数据库变更追溯,发现业务库的一张千万级数据量大表,执行了一次业务变更(执行了一个ALTER的DDL),导致了大量binlog产生。
6、提高消费者能力
当下Kafka的生产速率略大于消费速率,导致了部分数据滞后消费,要解决
瓶颈是业务消费逻辑(数据落库到ES)。
因此,从消费端入手,提高消费能力(业务消费瓶颈-落库到ES),将客户端限流的令牌数量提高,可以参考我公众号写的另外文章:源码解析:Guava客户端限流
7、其他原因
从生产端入手,后续运维变更,减少突发峰值可能性:
- 运维执行,建议后续放到业务低峰期执行SQL变更
- 对于部分大表进行性能优化,可以参考我公众号写的另外文章大表拆分方案:亿级大表冷热分级的工程实践、亿级大表冷热分级的工程实践
8、验证问题
通过对消费能力提升,我们通过对kafka的监控,找了一个业务低峰期执行SQL变更的时机,观察到topic分区消息堆积情况不再出现,说明问题得到了解决。
总结
在分布式系统下,业务链路往往一环扣一环,如果某个环节出现了性能卡点,可能会在其他环节暴露出问题。因此我们分析问题时,往往要结合上下游的来分析链路。
参考
其他文章
微服务重构:Mysql+DTS+Kafka+ElasticSearch解决跨表检索难题
基于SpringMVC的API灰度方案
SQL治理经验谈:索引覆盖
Mybatis链路分析:JDK动态代理和责任链模式的应用
大模型安装部署、测试、接入SpringCloud应用体系
一文带你看懂:亿级大表垂直拆分的工程实践
亿级大表冷热分级的工程实践
版权归原作者 后台技术汇 所有, 如有侵权,请联系我们删除。