
1.在/opt/atguigu/目录下,新建两个txt文件
[root@lxm147 atguigu]# cat /opt/atguigu/student.txt
1001 student1
1002 student2
1003 student3
1004 student4
1005 student5
1006 student6
1007 student7
1008 student8
1009 student9
1010 student10
1011 student11
1012 student12
1013 student13
1014 student14
1015 student15
1016 student16
[root@lxm147 atguigu]# cat /opt/atguigu/student2.txt
1001 student1
1002 student2
1003 student3
1004 student4
1005 student5
1006 student6
1007 student7
1008 student8
1009 student9
1010 student10
2.在hadoop的web端递归创建一个目录,存储这两个文件
dfs -mkdir -p /file/txt;
dfs -put /opt/atguigu/student.txt /file/txt;
dfs -put /opt/atguigu/student2.txt /file/txt;
3.查看web端的文件
dfs -ls /file/txt;

一、内部表:
1.创建一个内部表,并指定内部表的存储位置
create table if not exists student
(
id int,
name string
)
row format delimited fields terminated by '\t'
location '/tables';
2.查看内部表,内部表中没有数据
select * from student;
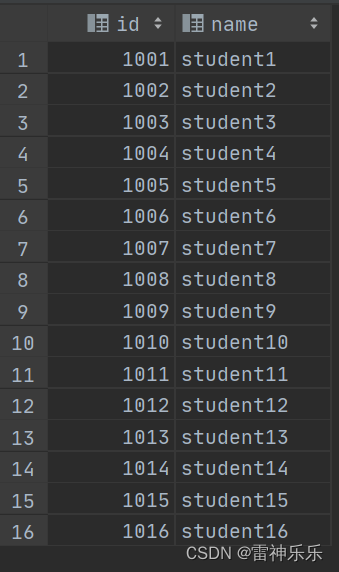
3.加载本地数据到内部表
load data local inpath '/opt/atguigu/student.txt' into table student;
4.再次查询,此时内部表中有数据
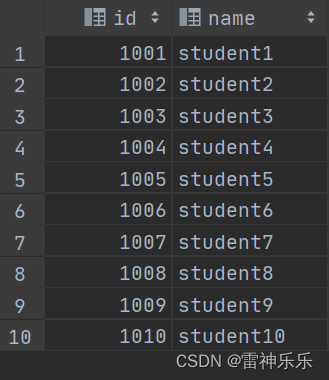
5.清空内部表,上传hdfs上的数据到内部表,内部表有数据
truncate table student;
load data inpath '/file/txt/student2.txt' into table student;
select * from student;
6.但是/file/txt目录下上传到内部表的文件数据被剪切

7.删除内部表,hdfs上传到内部表的数据也被删除
drop table student;
二、外部表
1.创建一个外部表,指定外部表的路径在公共文件目录下
create external table if not exists student_wb
(
id int,
name string
)
row format delimited fields terminated by '\t'
location '/file/txt';
2.直接查询外部表,公共文件中的数据直接上传到外部表
select * from student_wb;
3.删除外部表,公共文件的数据不会被删除
drop table student_wb;
dfs -ls /file/txt;

三、总结
将hdfs上的数据上传到内部表中,数据是被剪切到内部表中,内部表删除,hdfs上的数据也被删除;
将hdfs上的数据上传到外部表中,数据是被拷贝到外部表中,外部表删除,hdfs上的数据不会被删除。
本文转载自: https://blog.csdn.net/Helen_1997_1997/article/details/129148002
版权归原作者 雷神乐乐 所有, 如有侵权,请联系我们删除。
版权归原作者 雷神乐乐 所有, 如有侵权,请联系我们删除。