
系列文章
Zookeeper系列(一)集群搭建(非容器)
前言
Zookeeper是一个开源的分布式协调服务,其设计目标是将那些复杂的且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一些简单的接口提供给用户使用。ZooKeeper 背后的动机是减轻分布式应用程序从头开始实现协调服务的责任。
Zookeeper是一个典型的分布式数据一致性的解决方案,分布式应用程序可以基于它实现诸如数据订阅/发布、负载均衡、命名服务、集群管理、分布式锁和分布式队列等功能。
下载
从官网 Apache ZooKeeper 下载相应版本,这里版本为 3.7.2(本系列后续所用版本也是)。
搭建
Data目录
- 首先创建集群项目存放的位置,当前是 /home/zookeeper/file ,这里可自定义
mkdir -p /home/zookeeper/file
- 将下载的压缩包上传到linux服务器,路径 /home/zookeeper/file 下,然后解压(通过wget和其他方式亦可)
tar -zxvf apache-zookeeper-3.7.2-bin.tar.gz -C zookeeper-3.7.2
- 复制一份作为 zookeeper1
cp -r zookeeper-3.7.2 zookeeper1
- 切换到 zookeeper1 目录下,创建 data 和 logs 目录
cd zookeeper1
mkdir data
mkdir logs
- 进入 data 目录,生成一个内容为 1 的 myid
cd data
vim myid
Conf目录
- 接下来,操作配置相关内容,进入 conf 中,路径为 /home/zookeeper/file/zookeeper1/conf
cd /home/zookeeper/file/zookeeper1/conf
- 复制一份 zoo_sample.cfg 为 zoo.cfg
cp zoo_sample.cfg zoo.cfg
- 编辑 zoo.cfg,修改 dataDir 和 添加 server.服务器ID 列表
dataDir=/home/zookeeper/file/zookeeper1/data
server.1=192.168.119.142:2881:3881
server.2=192.168.119.142:2882:3882
server.3=192.168.119.142:2883:3883
注意:dataDir 为当前节点的 data 目录路径,这里为 zookeeper1节点的
server.服务器ID有几个配置几个(这里为3个),配置表达式如下:
server.服务器ID=服务器IP地址:服务器之间通信端⼝:服务器之间投票选举端⼝
集群复制和修改
- 复制 zookeeper1,分别命名为 zookeeper2,zookeeper3(3个节点构成的集群)
cp -r zookeeper1 zookeeper2
cp -r zookeeper1 zookeeper3
- 分别进入 zookeeper2 和 zookeeper3 下的 data 目录,分别修改 myid 的内容为 2 和 3(注意节点和值的对应)
- 接下来就是 conf 的修改,进入 zookeeper2 下的 conf 目录,修改 zoo.cfg 的 dataDir 和 clientPort
dataDir=/home/zookeeper/file/zookeeper2/data
clientPort=2182
- 进入 zookeeper3 下的 conf 目录,修改 zoo.cfg 的 dataDir 和 clientPort
dataDir=/home/zookeeper/file/zookeeper3/data
clientPort=2183
- 以上就配置完成了,就可以启动了
启动
- 分别进入zookeeper1、zookeeper2 和 zookeeper3 的 bin 目录,执行命令
./zkServer.sh start
- 启动后,显示

- 查看状态和是否主节点
./zkServer.sh status
- 关闭
./zkServer.sh stop
配置示例
选择 zookeeper3 的 zoo.cfg 配置给列位参照(不同版本可能不同)
- zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/home/zookeeper/file/zookeeper3/data
# the port at which the clients will connect
clientPort=2183
server.1=192.168.119.142:2881:3881
server.2=192.168.119.142:2882:3882
server.3=192.168.119.142:2883:3883
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
## Metrics Providers
#
# https://prometheus.io Metrics Exporter
#metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
#metricsProvider.httpPort=7000
#metricsProvider.exportJvmInfo=true
测试
启动全部节点后,可通过多种方式确认集群的可用性,这里选择客户端工具
- 通过客户端工具,分别连接 zookeeper1 、zookeeper2 和 zookeeper3
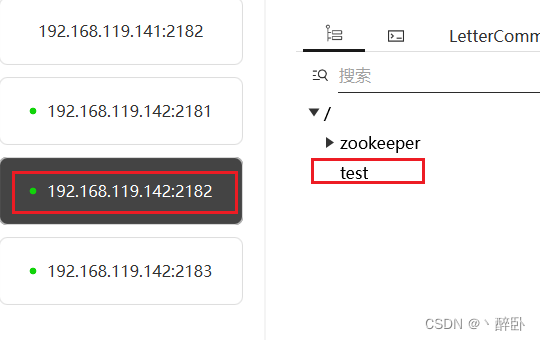
- 在 zookeeper1 下新增持久节点 test

- 分别查看 zookeeper2 和 zookeeper3 对应的节点树数据情况,显示节点已同步
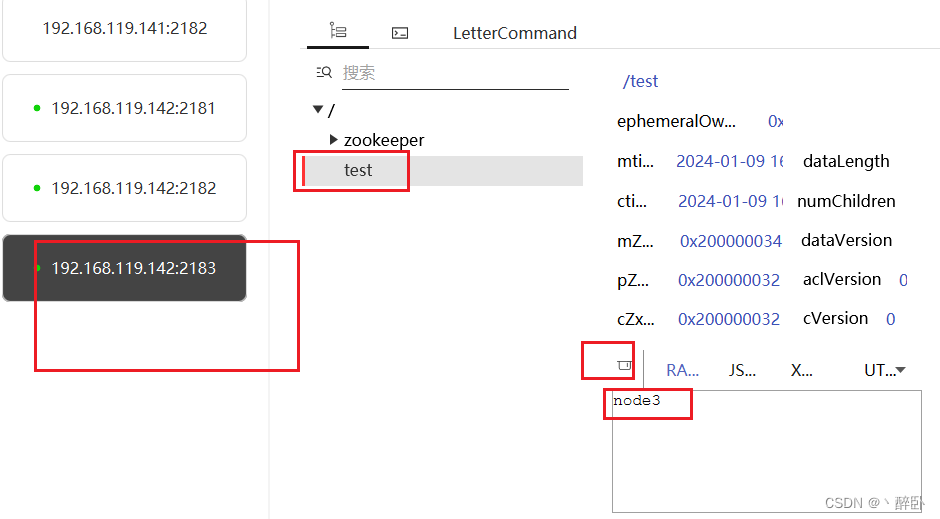
- 然后在 zookeeper3 修改 test 的内容为 node3
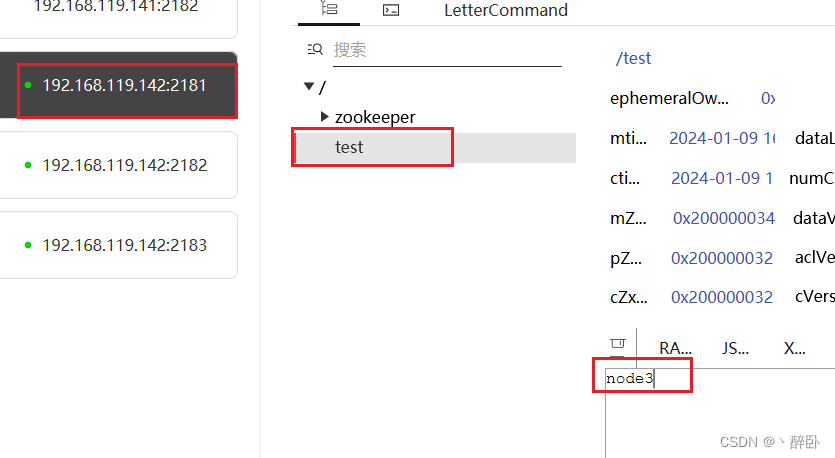
- 分别查看 zookeeper1 和 zookeeper2 的 test节点内容,显示节点内容已更新
- 经过以上步骤,可初步确认集群是成功启动的
总结
Zookeeper是一个强大的分布式协调工具,接下来会持续更新Zookeeper的其他内容,包括但不限于分布式锁、分布式队列、源码分析等等。
本文转载自: https://blog.csdn.net/qq_35427539/article/details/135474206
版权归原作者 丶醉卧 所有, 如有侵权,请联系我们删除。
版权归原作者 丶醉卧 所有, 如有侵权,请联系我们删除。