
本文介绍Flume监听端口采集数据流到Kafka
我还写了一篇文章是Flume监听本地文件采集数据流到HDFS【点击即可跳转,写的也非常详细】
任务一:实时数据采集
前摘:
Flume
- 是一种分布式、高可靠、高可用的数据收集系统,用于高效地从多个源收集、聚合和传输大量日志数据。
- Flume的设计目标是用于构建高度可扩展的日志收集解决方案,它能够从多种数据源中捕获数据,并将数据送到指定的目的地,例如HDFS或Kafka。
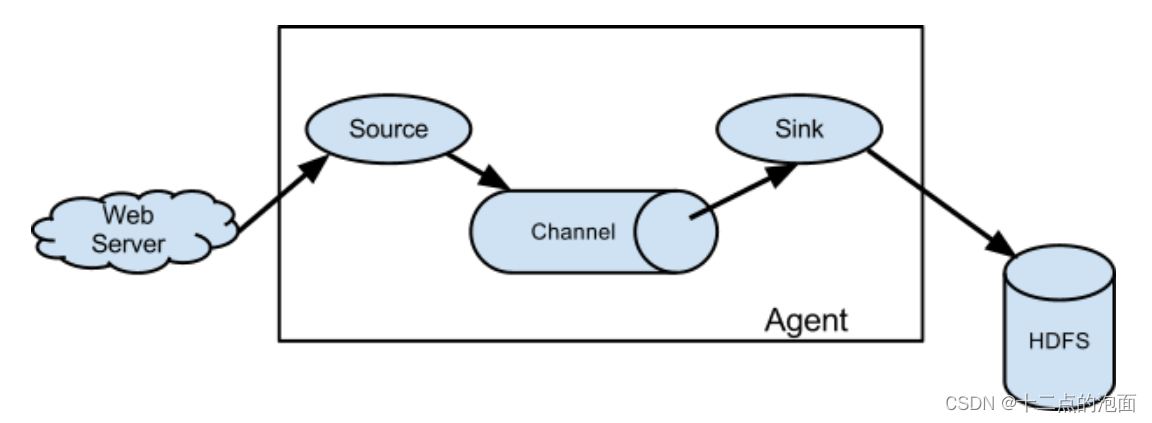
- Flume的核心是由agent组成的,每个agent内部包含三个主要的组件:source、channel和sink。
Source组件负责从数据源捕获数据
sink则负责将数据写入到最终的目标存储中,如HDFS或Kafka。
Channel组件作为临时存储,用于缓冲source和sink之间的数据
- 重点:因为source的收集速度和sink的存储速度不一样
kafka
- 是一个分布式消息系统,主要用于处理和传输大规模数据流。
- 具有高吞吐、可持久化、可水平扩展等特点,非常适合大数据实时处理领域。
- Kafka不仅能够作为消息队列使用,提供消息的传输和存储功能,还能作为流式处理平台的源头,为诸如Storm、Spark Streaming等流式处理框架提供稳定的数据来源。
- Kafka中的数据以主题(Topic)为单位进行归类。生产者(Producer)负责创建消息并将其发送到特定的主题。消费者(Consumer)则从主题订阅并接收消息进行进一步的处理。
实操
题目:
- 在Master节点使用Flume采集实时数据生成器25001端口的socket数据(实时数据生成器脚本为Master节点/data_log目录下的gen_ds_data_to_socket脚本,该脚本为Master节点本地部署且使用socket传输),将数据存入到Kafka的Topic中(Topic名称为ods_mall_log,分区数为4),使用Kafka自带的消费者消费ods_mall(Topic)中的数据,查看前2条数据的结果;
注:需先启动已配置好的****Flume再启动脚本,否则脚本将无法成功启动,启动方式为进入/data_log目录执行./gen_ds_data_to_socket (如果没有权限,请执行授权命令chmod 777 /data_log/gen_ds_data_to_socket)
使用Flume来监听Kafka,实际上是通过配置Flume作为数据消费者,从Kafka的主题中读取数据。配置Flume为从Kafka获取数据时,需要将source类型配置为Kafka Source,然后指定相应的Kafka集群地址、主题名称以及其他必要参数。Sink则配置为Kafka Sink,用于将数据发送到Kafka。Channel作为source和sink之间的缓冲,可以配置为内存channel或者其他类型的channel,取决于具体的性能和可靠性要求
①根据题目要求编写Agent
([Source 数据源] [Sink 数据目的地] [Channel 数据通道])
在/opt/module/flume-1.9.0目录下创建 job文件夹存放Agent
cd /opt/module/flume-1.9.0
mkdir job
cd job
编辑Agent
vim net-flume-logger.conf
内容如下:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 25001
# Describe the sink KafkaSink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.bootstrap.servers = bigdata1:9092
a1.sinks.k1.kafka.topic = ods_mall_log
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
具体含义:
a1.sources = r1:定义了一个名为r1的数据源(source),这是Flume代理接收数据的地方。a1.sinks = k1:定义了一个名为k1的数据汇(sink),这是Flume代理发送数据的地方。a1.channels = c1:定义了一个名为c1的通道(channel),这是Flume代理在source和sink之间临时存储数据的缓冲区。a1.sources.r1.type = netcat:指定r1源的类型为netcat,这是一种简单的TCP/IP客户端-服务器程序,可以用于测试和调试目的。a1.sources.r1.bind = localhost:指定r1源绑定到本地主机(localhost)。a1.sources.r1.port = 25001:指定r1源监听的端口为25001。a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink:指定k1汇的类型为KafkaSink,这意味着数据将被发送到Kafka集群。a1.sinks.k1.kafka.bootstrap.servers = bigdata1:9092:指定Kafka集群的bootstrap servers地址为bigdata1:9092。a1.sinks.k1.kafka.topic = ods_mall_log:指定数据将被发送到Kafka的哪个主题(topic),这里是ods_mall_log。a1.channels.c1.type = memory:指定c1通道的类型为内存(memory),这意味着数据将在JVM的内存中存储。a1.channels.c1.capacity = 1000:指定c1通道的最大容量为1000条事件。a1.channels.c1.transactionCapacity = 100:指定c1通道的事务容量为100条事件,这决定了每次事务可以处理的事件数量。a1.sources.r1.channels = c1:将r1源连接到c1通道。a1.sinks.k1.channel = c1:将k1汇连接到c1通道。这个配置定义了一个从netcat源接收数据,通过内存通道传输,然后将数据发送到Kafka集群的Flume代理。
②创建Topic 名字为:ods_mall_log
bin/kafka-topics.sh --create --bootstrap-server bigdata1:9092 --replication-factor 1 --partitions 4 --topic test
bin/kafka-topics.sh --list --bootstrap-server bigdata1:9092
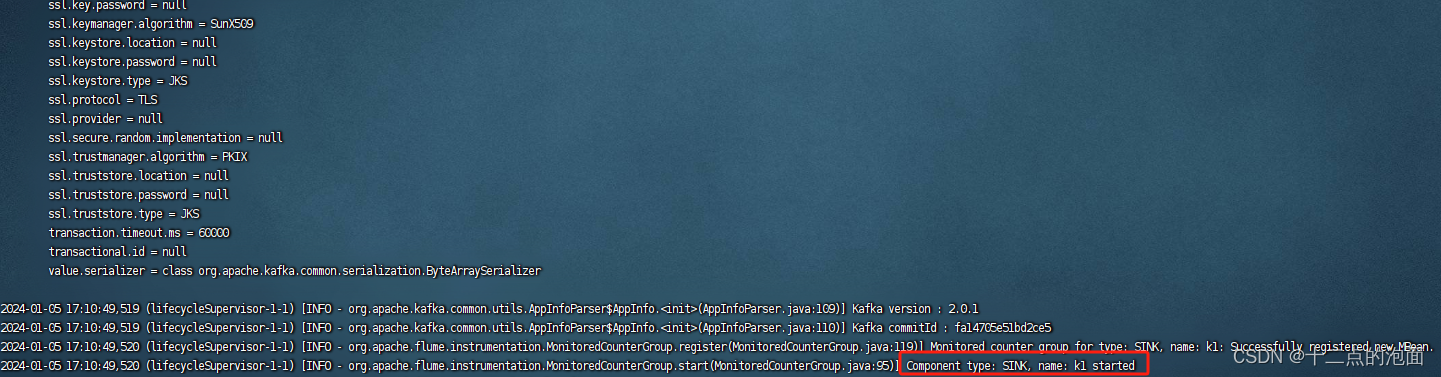
③启动Flume代理
flume-ng agent -c conf/ -n a1 -f /opt/module/flume-1.9.0/job/net-flume-logger.conf -Dflume.root.logger=INFO,console
参数解释:
-c conf/:这个参数指定了Flume的配置文件所在的目录。在这个例子中,配置文件位于conf/目录下。
-n a1:这个参数指定了要启动的Flume agent的名字。在这个例子中,agent的名字是a1。
-f /opt/module/flume-1.9.0/job/net-flume-logger.conf:这个参数指定了Flume的配置文件的路径。在这个例子中,配置文件位于/opt/module/flume-1.9.0/job/net-flume-logger.conf。
-Dflume.root.logger=INFO,console:这个参数设置了Java的系统属性,它告诉Flume将日志输出到控制台,并且只记录INFO级别的日志。
④启动实时数据生成脚本
cd /data_log
./gen_ds_data_to_socket
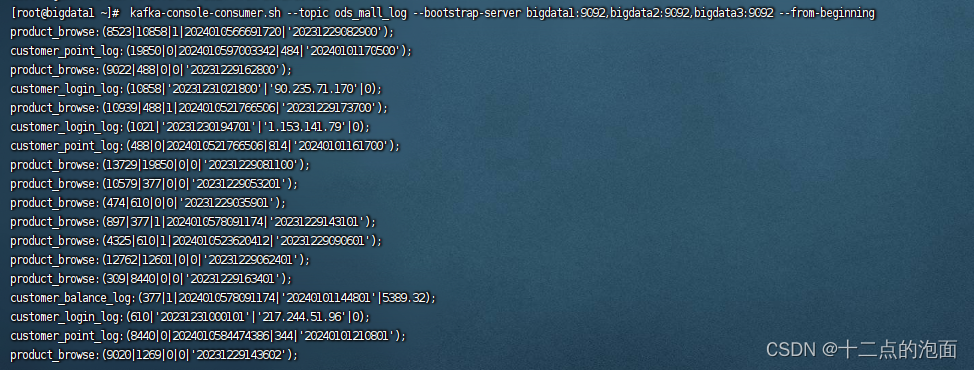
⑤消费数据
kafka-console-consumer.sh --topic ods_mall_log --bootstrap-server bigdata1:9092,bigdata2:9092,bigdata3:9092 --from-beginning
版权归原作者 十二点的泡面 所有, 如有侵权,请联系我们删除。