
大数据基准测试工具HiBench部署与测试
构建HiBench
准备工作
构建HiBench测试工具,需要在Linux中安装以下软件:
- Spark2.4.0
- Scala2.11.12
- Maven3.5.0
查看已安装软件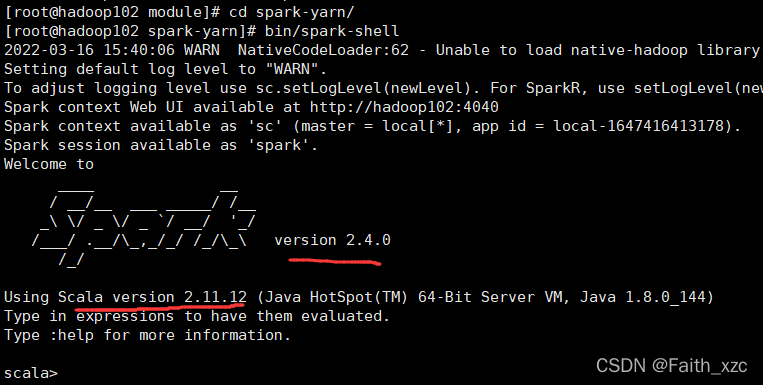
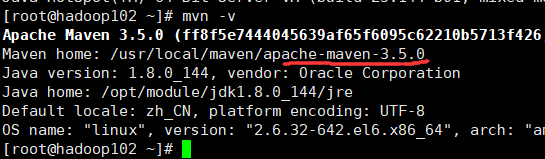
这是我安装的版本,看下自己的版本,后面会用到
构建流程
下载HiBench
[root@hadoop102/]# git clone https://github.com/intel-hadoop/HiBench.git
注: 如果出现-bash: git: command not found,则需要执行命令:yum install -y git,然后再执行上面的命令
编译HiBench
HiBench的编译形式有很多种,大家可以根据自己的需要进行选择:
- Build All
- Build a specific framework benchmark
- Build a single module
- Build Structured Streaming
我只需要测试Hadoop和Spark,所以我这里只构建了Hadoop和Spark基准,编译方法:
[root@hadoop102HiBench]# mvn -Phadoopbench-Psparkbench-Dspark=2.4-Dscala=2.11 clean package
这个会需要一段时间(几个小时吧,快的话一个小时)
但需要注意,在编译阶段,会出现失败的情况如下(也不一定到最后,可能在上面任何一个SUCCESS的地方出现FAILURE):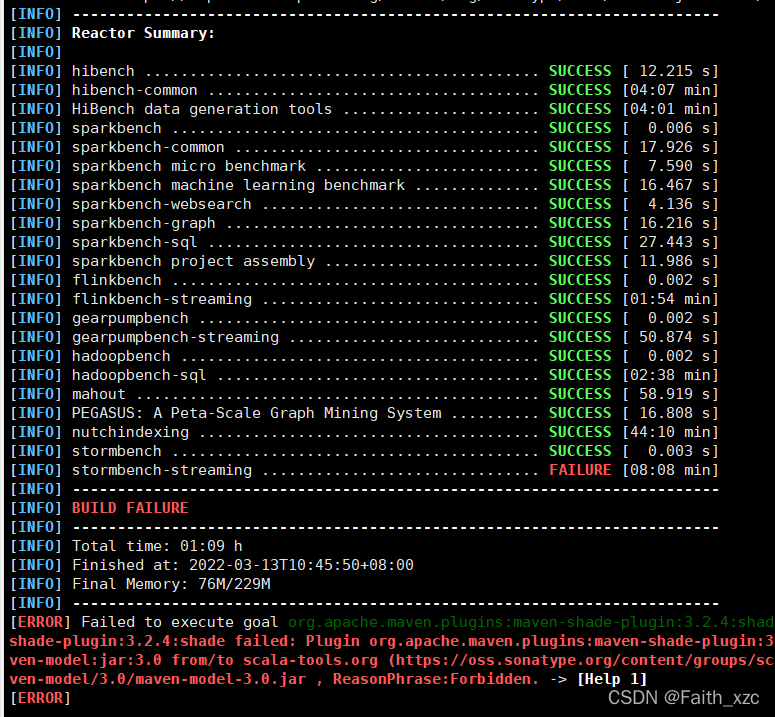
不用担心,再执行上面的命令,直到出现下面的情况: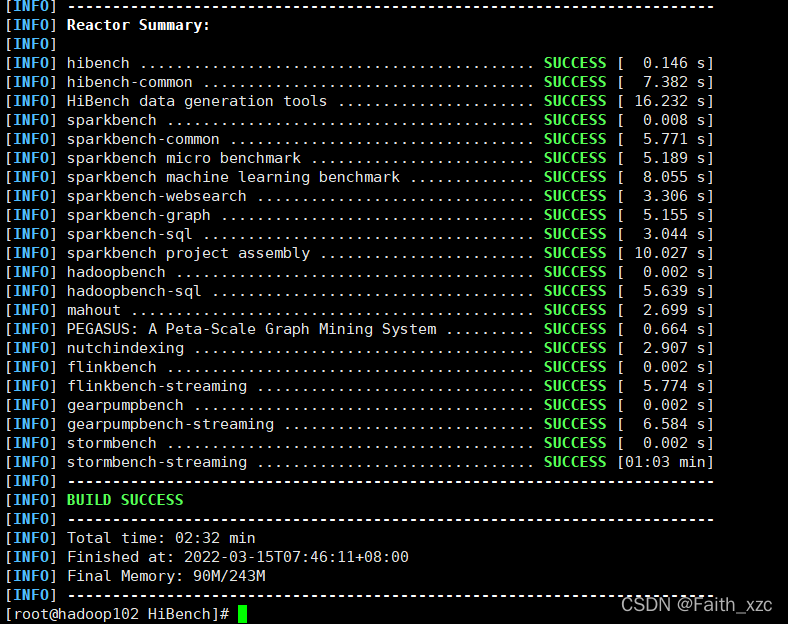
测试
根据上面我构建的测试基准,下面测试了HadoopBench和SparkBench
测试HadoopBench
测试HadoopBench,需要进行下面设置:
- 安装 Python 2.x(>=2.6)
- 安装bc
- 构建HiBench
- 在集群中启动 HDFS、Yarn
配置文件
执行下面的命令
[root@hadoop102HiBench]# cd conf/[root@hadoop102 conf]# cp conf/hadoop.conf.template conf/hadoop.conf
[root@hadoop102 conf]# vim hadoop.conf
修改hadoop.conf文件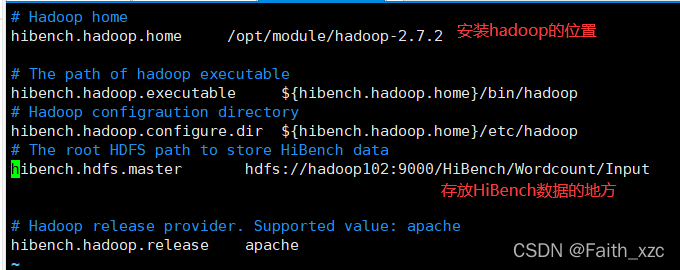
进行测试
依次执行下面的命令
bin/workloads/micro/wordcount/prepare/prepare.sh
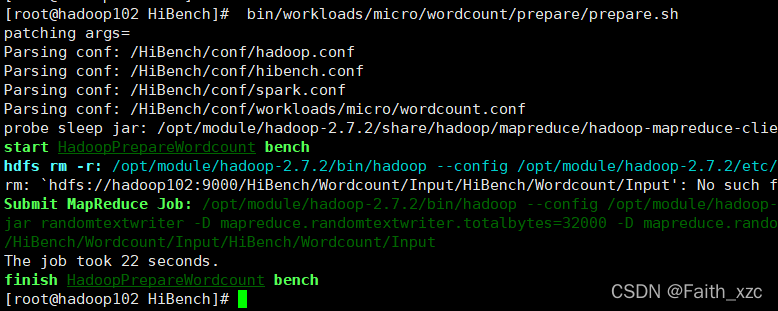
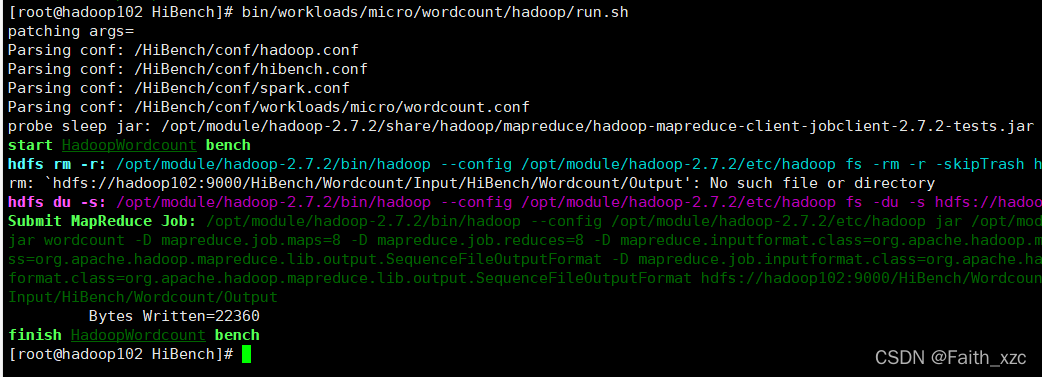
bin/workloads/micro/wordcount/hadoop/run.sh
查看report
可以通过HiBench的report里的hibench.report文件,查看下运行结果
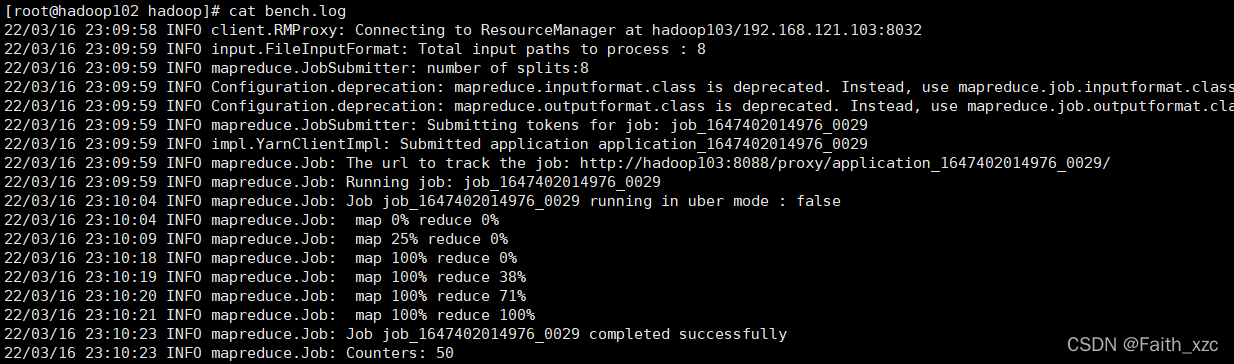
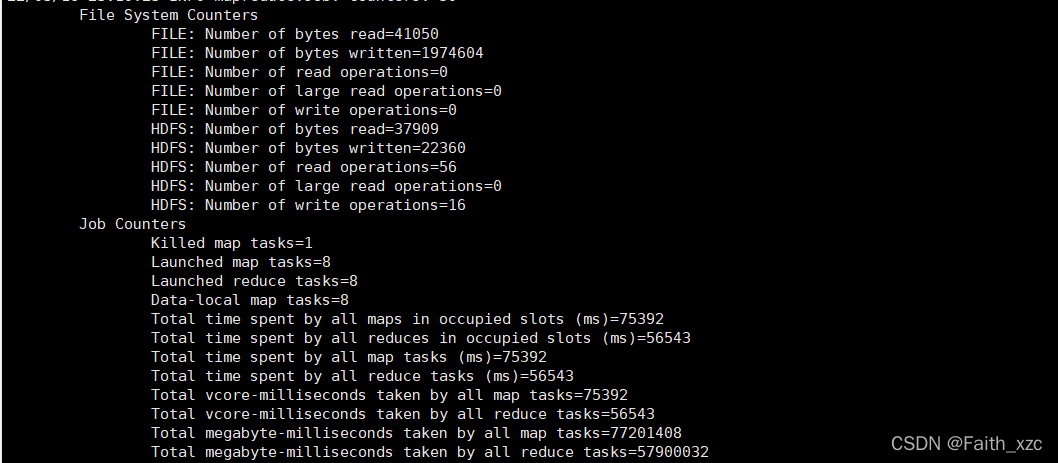
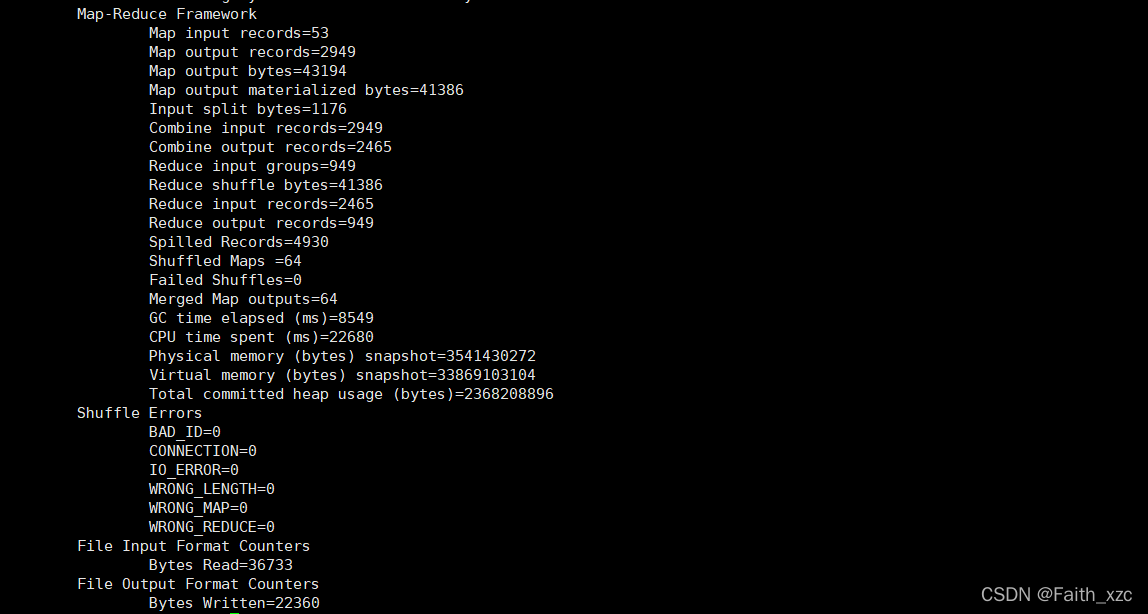
更详细的原始日志可以在相应的执行文件中看bench.log;这次执行的wordcount,所以操作过程如下:
[root@hadoop102 report]# cd wordcount/hadoop/[root@hadoop102 hadoop]# cat bench.log
测试SparkBench
测试HadoopBench,需要进行下面设置:
- 需要 Python 2.x(>=2.6)
- 安装bc
- 构建 HiBench
- 在集群中启动 HDFS、Yarn、Spark
配置文件
执行下面的命令
[root@hadoop102HiBench]# cd conf/[root@hadoop102 conf]# cp conf/hadoop.conf.template conf/hadoop.conf
[root@hadoop102 conf]# vim hadoop.conf
(同上)
[root@hadoop102 conf]# cp conf/spark.conf.template conf/spark.conf
[root@hadoop102 conf]# vim spark.conf
修改spark.conf文件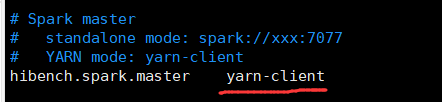
进行测试
依次执行下面的命令
[root@hadoop102HiBench]# bin/workloads/micro/wordcount/prepare/prepare.sh
prepare.sh启动 Hadoop 作业以在 HDFS 上生成输入数据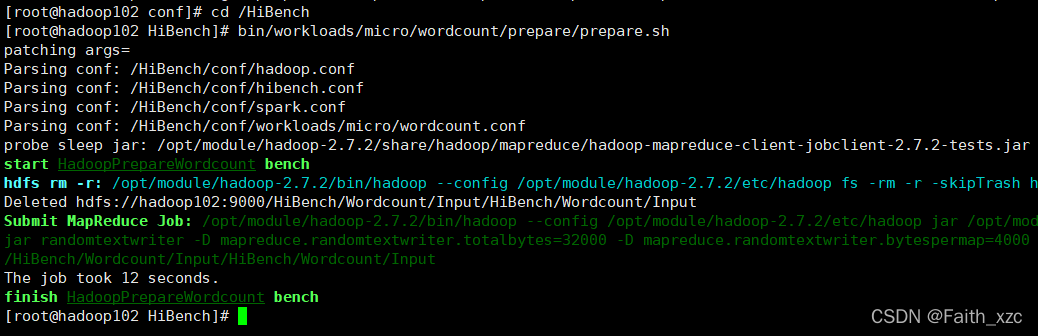
[root@hadoop102HiBench]# bin/workloads/micro/wordcount/spark/run.sh
将run.shSpark 作业提交到集群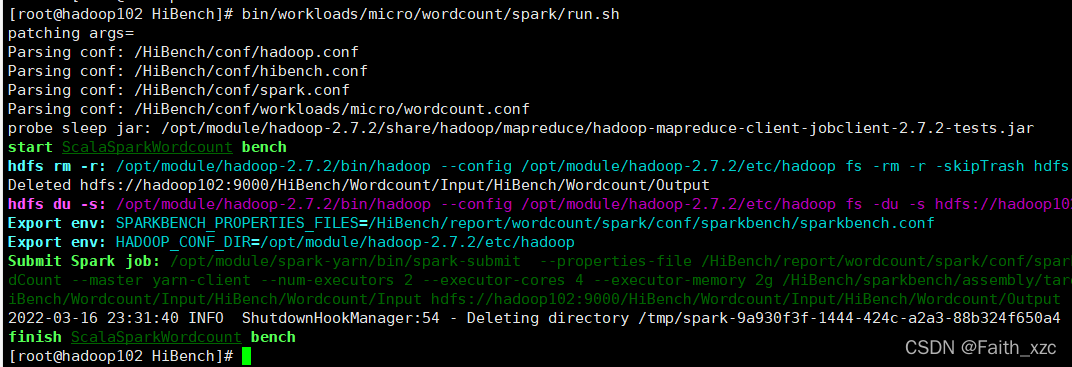
查看report
可以通过HiBench的report里的hibench.report文件,查看下运行结果
更详细的原始日志可以在相应的执行文件中看bench.log;这次执行的wordcount,所以操作过程如下:
[root@hadoop102 report]# cd wordcount/spark/[root@hadoop102 spark]# cat bench.log
(内容比较多,只截取一部分)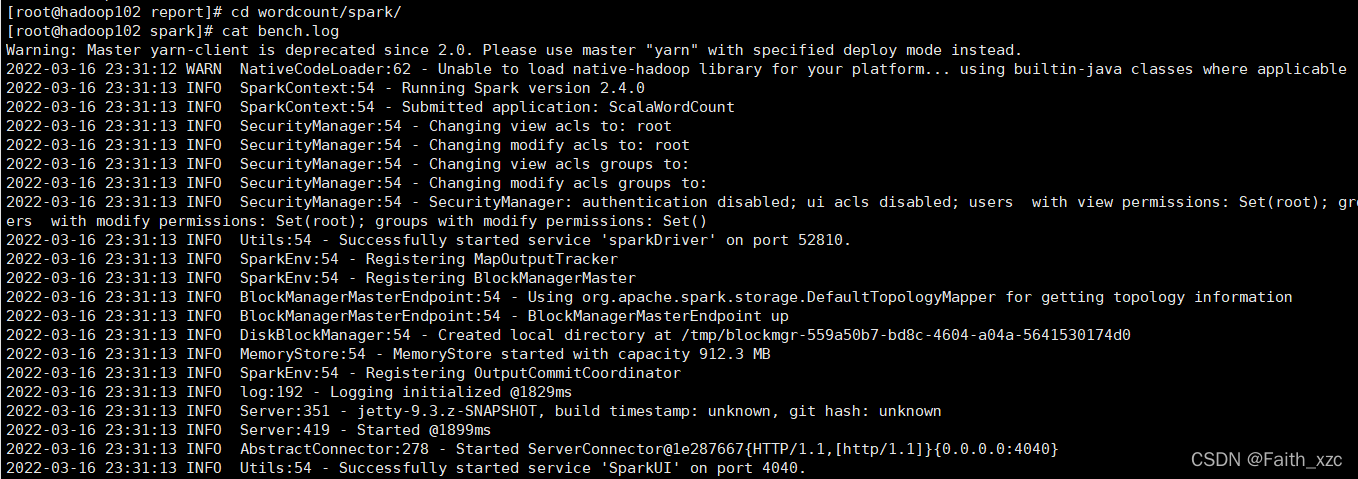
版权归原作者 Faith_xzc 所有, 如有侵权,请联系我们删除。