
悟懂Linux第25章shell编程-创建与WEB相关的脚本②
第 25章 创建与数据库、Web及电子邮件相关的脚本

本章内容
编写数据库shell脚本
在脚本中使用互联网
在脚本中发送电子邮件
目前为止,我们已经讲述了shell脚本的很多特性。不过这还不够!要想提供先进的特到性,还得利用shell脚本之外的高级功能,例如访问数据库、从互联网上检索数据以及使用电子邮件发送报表。本章将为你展示如何在脚本中使用这三个Linux系统中的常见功能。
25.2 使用Web
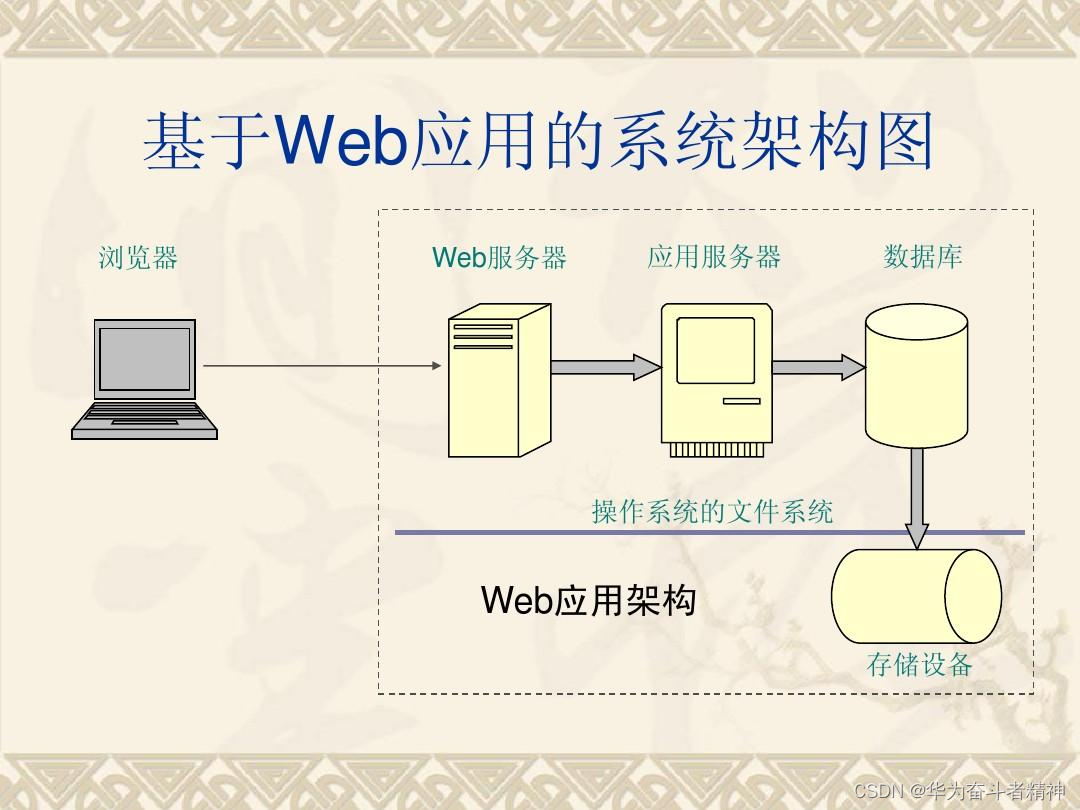
通常在考虑shell脚本编程时,最不可能考虑到的就是互联网了。命令行世界看起来往往跟丰富多彩的互联网世界格格不入。但你可以在shell脚本中非常方便的利用一些工具访问Web以及其他网络设备中的数据内容。
作为一款于1992年由堪萨斯大学的学生编写的基于文本的浏览器,Lynx程序的历史几乎和互联网一样悠久。因为该浏览器是基于文本的,所以它允许你直接从终端会话中访问网站,只不过Web页面上的那些漂亮图片被替换成了HTML文本标签。这样你就可以在几乎所有类型的Linux终端上浏览互联网了。图25-2展示了Lynx的界面。
图25-2 使用Lynx浏览Web页面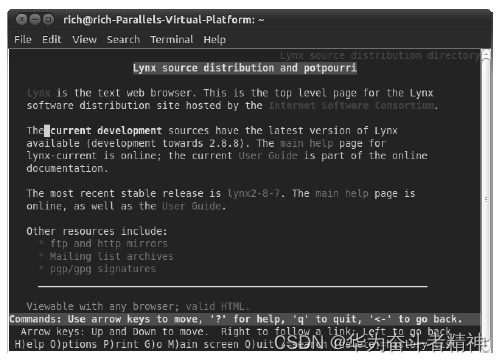
Lynx使用标准键盘按键浏览网页。链接会在Web页面上以高亮文本的形式出现。使用向右方向键可以跟随一个链接到下一个Web页面。
你可能想知道如何在shell脚本中使用图形化文本程序。Lynx程序还提供了一个功能,允许你将Web页面的文本内容转储到STDOUT中。这个功能非常适合用来挖掘Web页面中包含的数据。本节将会介绍如何在shell脚本中用Lynx程序提取网站中的数据。
25.2.1 安装Lynx
尽管Lynx程序有点古老,但它的开发仍然很活跃。在本书写作时,Lynx的最新版本是2010年6月发布的2.8.8,新版本正在研发中。鉴于它在shell脚本程序员中十分流行,许多Linux发行版都将它作为默认程序安装。
如果你正在用一个不带Lynx程序的Linux系统,请检查一下该发行版的安装包。大多数情况下,你都能在那里找到Lynx包并轻松地安装好。
如果发行版没有提供Lynx包,或者你想用最新版的,可以从lynx.isc.org网站上下载源码并编译(假定你已经在Linux系统上安装了C开发库)。参考第9章获取有关如何编译并安装源码包的相关信息。
说明 Lynx程序使用了Linux中的curses文本图形库。大多数发行版会默认安装这个库。如果你的发行版没有安装,在尝试编译Lynx前先参考你的发行版的安装指南来安装curses库。 下一节将会介绍如何在命令行上使用lynx命令。
25.2.2 lynx命令行
lynx命令行命令极其擅长从远程网站上提取信息。当用浏览器查看Web页面时,你只是看到了传送到浏览器中信息的一部分。Web页面由三种类型的数据组成:
HTTP头部
cookie
HTML内容
HTTP头部提供了连接中传送的数据类型、发送数据的服务器以及采用的连接安全类型的相关信息。如果你发送的是特殊类型的数据,比如视频或音频剪辑,服务器会将其在HTTP头部中标示出来。Lynx程序允许你查看Web页面会话中发送的所有HTTP头部。
如果你浏览过Web页面,对Web页面cookie一定不会陌生。网站用cookie存储有关网站的访问数据,以供将来使用。每个站点都能存储信息,但只能访问它自己设置的信息。lynx命令提供了一些选项来查看Web服务器发送的cookie,还可以接受或拒绝服务器发过来的特定cookie。
Lynx程序支持三种不同的格式来查看Web页面实际的HTML内容:
在终端会话中利用curses图形库显示文本图形;
文本文件,文件内容是从Web页面中转储的原始数据;
文本文件,文件内容是从Web页面中转储的原始HTML源码。
对于shell脚本,原始数据或HTML源码可是一座金山。一旦你获得了从网站上检索到的信息,就能轻松地从中提取每一条信息。
如你所见,Lynx程序将它的本职工作发挥到了极致。但随之而来的是复杂性,尤其是对命令行参数来说。Lynx程序是你在Linux世界中遇到的较复杂的程序之一。
lynx命令的基本格式如下。
lynx options URL
其中URL是你要连接的HTTP或HTTPS地址,options则是一个或多个选项。这些选项可以在Lynx与远程网站交互时改变它的行为。许多命令行参数定义了Lynx的行为,可以用来控制全屏模式下的Lynx,允许在浏览Web页面时对其进行定制。
在正常的浏览环境中,你通常会发现有几组命令行参数非常有用。你不用每次使用Lynx时都在命令行上将这些参数输入一遍,Lynx提供了一个通用配置文件来定义Lynx的基本行为。我们将在下一节中讨论这个配置文件。
25.2.3 Lynx配置文件
lynx命令会从配置文件中读取大量的参数设置。默认情况下,这个文件位于/usr/local/lib/lynx.cfg,不过有许多Linux发行版将其改放到了/etc目录下(/etc/lynx.cfg)(Ubuntu发行版将lynx.cfg放到了/etc/lynx-curl目录中)。
lynx.cfg配置文件将相关的参数分组到不同的区域中,这样更容易找到参数。配置文件中条目的格式为:
PARAMETER:value
其中PARAMETER是参数的全名(通常都是用大写字母,但也不总是如此),value是跟参数关联的值。
浏览一下这个文件,你会发现许多参数都跟命令行参数类似,比如ACCEPT_ALL_COOKIES参数就等同于设置了-accept_all_cookies命令行参数。
还有一些配置参数功能类似,但名称不同。FORCE_SSL_COOKIES_SECURE配置文件参数设置可以用-force_secure命令行参数给覆盖掉。
你还会发现少数配置参数并没有对应的命令行参数。这些值只能在配置文件中设定。
最常见的你不能在命令行上设置的配置参数是代理服务器。有些网络(尤其是公司网络)使用代理服务器作为客户端浏览器和目标网站的桥梁。客户端浏览器不能直接向远程Web服务器发送HTTP请求,而是必须将它们的请求发到代理服务器上,然后由代理服务器将请求转发给远程Web服务器,获取结果,再将结果回传给客户端浏览器。
虽然这看起来像在浪费时间,但它是保护客户端不受互联网上危险侵害的重要功能。代理服务器可以过滤不良内容和恶意代码,甚至可以发现钓鱼网站(为了获取用户数据,假扮他人的流氓服务器)。代理服务器还可以帮助降低网络带宽的使用,因为它缓存了经常浏览的Web页面并将其直接返回给客户端,而不用再从原始地址处下载页面。
用来定义代理服务器的配置参数有:
http_proxy:http://some.server.dom:port/
https_proxy:http://some.server.dom:port/
ftp_proxy:http://some.server.dom:port/
gopher_proxy:http://some.server.dom:port/
news_proxy:http://some.server.dom:port/
newspost_proxy:http://some.server.dom:port/
newsreply_proxy:http://some.server.dom:port/ snews_proxy:http://some.server.dom:port/
snewspost_proxy:http://some.server.dom:port/ snewsreply_proxy:http://some.server.dom:port/ nntp_proxy:http://some.server.dom:port/
wais_proxy:http://some.server.dom:port/
finger_proxy:http://some.server.dom:port/
cso_proxy:http://some.server.dom:port/
no_proxy:host.domain.dom
你可以为任何Lynx支持的网络协议定义不同的代理服务器。NO_PROXY参数是逗号分隔的网站列表。对于列表中的这些网站,不希望使用代理服务器直接访问。这些通常都是不需要过滤的内部网站。
25.2.4 从Lynx中获取数据
在shell脚本中使用Lynx时,大多数情况下你只是要提取Web页面中的某条(或某几条)特定信息。完成这个任务的方法称作屏幕抓取(screen scraping)。在屏幕抓取过程中,你要尝试通过编程寻找图形化屏幕上某个特定位置的数据,这样你才能获取它并在脚本中使用。
用lynx进行屏幕抓取的最简单办法是用-dump选项。这个选项不会在终端屏幕上显示Web页面。相反,它会将Web页面文本数据直接显示在STDOUT上。
$ lynx-dump http://localhost/RecipeCenter/
The Recipe Center
"Just like mom used to make"
Welcome
[1]Home
[2]Login to post
[3]Register forfree login
_____________________________________________________________
[4]Post a new recipe
每个链接都由一个标号标定,Lynx在Web页面数据后显示了所有标号所指向的地址。
在从Web页面中获得了所有文本数据之后,你可能已经知道我们会从工具箱中取出什么工具来提取数据了。没错,就是我们的老朋友sed编辑器和gawk程序(参见第19章)。
首先,让我们找一些有意思的数据来收集。Yahoo!天气页面是找出全世界任何地区当前气候的不错来源。每个位置都用一个单独的URL来显示该城市的天气信息(你可以在浏览器中打开该站点并输入你的城市信息来获取所在地的特定URL)。查看伊利诺伊州芝加哥市的天气情况的lynx命令如下:
lynx-dump http://weather.yahoo.com/united-states/illinois/chicago-2379574/
这条命令会从页面中转储出很多的数据。第一步是找到你需要的准确信息。要做到这点,需将lynx命令的输出重定向到一个文件中,然后在文件中查找数据。执行了前面的命令后,我们在输出文件中找到了这段文本。
Current conditions as of 1:54 pm EDT Mostly Cloudy
Feels Like:
32 °F
Barometer:
30.13in and rising
Humidity:
50%
Visibility:
10 mi
Dewpoint:
15 °F
Wind:
W 10 mph
这都是你需要的关于当前天气的所有信息。但这段输出中有个小问题。你会注意到,数字都是在标题下面一行的。只提取单独的数字有些困难。第19章讨论过如何处理这样的问题。
解决这一问题的关键是先写一个能查找数据标题的sed脚本。找到之后,你就可以到正确的行中提取数据了。很幸运,这个例子中我们所需要的数据就是那些文本行。这里应该只用sed脚本就能解决了。如果在同一行中还有其他文本,就需要使用gawk工具来过滤出我们需要的数据。
首先,你需要创建一个sed脚本来查找表示地点的文本,然后跳到下一行来获取描述当前天气状况的文本并打印出来。输出芝加哥天气的脚本如下。
$ cat sedcond
/IL, United States/{ n
p
}
$
地址指明了要查找的行。如果sed命令找到了,n命令就会跳到下一行,然后p命令会打印当前行的内容,也就是描述该城市当前天气状况的文本。
下一步,你需要一段sed脚本来查找文本Feels Like,并打印出下一行的温度。
$ cat sedtemp /Feels Like/{ p
}
$
漂亮极了。现在你可以在shell脚本中用这两个sed脚本。首先将Web页面的lynx输出放入一个临时文件中,然后对Web页面数据使用这两个sed脚本,提取所需的数据。下面的例子演示了具体的做法。
$ cat weather
#!/bin/bash # extract the current weather for Chicago, IL URL="http://weather.yahoo.com/united-states/illinois/chicago-2379574/"LYNX=$(whichlynx)TMPFILE=$(mktemp tmpXXXXXX)$LYNX-dump$URL>$TMPFILEconditions=$(cat $TMPFILE |sed-n-f sedcond)temp=$(cat $TMPFILE |sed-n-f sedtemp |awk'{print $4}')rm-f$TMPFILEecho"Current conditions: $conditions"echo The current temp outside is: $temp $ ./weather
Current conditions: Mostly Cloudy
The current temp outside is: 32 °F
$
天气脚本会连接到指定城市的Yahoo!天气页面,将Web页面保存到一个文件中,提取对应的文本,删除临时文件,然后显示天气信息。这么做的好处在于,一旦你从网站上提取到了数据,就可以随心所欲地处理它,比如创建一个温度表。可以创建一个每天运行的cron任务(参见第16章)来跟踪当天的温度。
警告 互联网无时不刻不在发生变化。如果你花费了几个小时找到了Web页面上数据的精确位置,而几个星期后却发现数据已经不在了,脚本也没法工作了,不必感到惊讶。事实上,很有可能上面这个例子在你阅读本书时已经无法工作了。重要的是要知道从Web页面提取数据的过程。这样你就可以将原理运用到任何情形中。
版权归原作者 华为奋斗者精神 所有, 如有侵权,请联系我们删除。