
Spark Shell 的使用
Spark shell 作为一个强大的交互式数据分析工具,提供了一个简单的方式学习 API。它可以使用 Scala(在Java 虚拟机上运行现有的Java库的一个很好方式)或 Python。
Spark Shell 命令
启动 Spark Shell 的时候我们可以指定master 也可以不指定
spark-shell

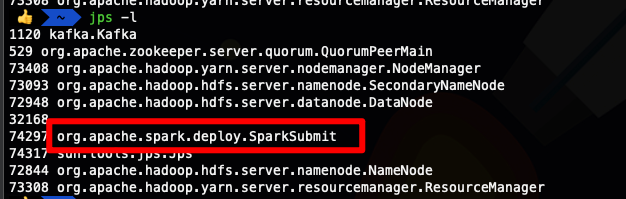
你也可以看到进程相关的信息
‘
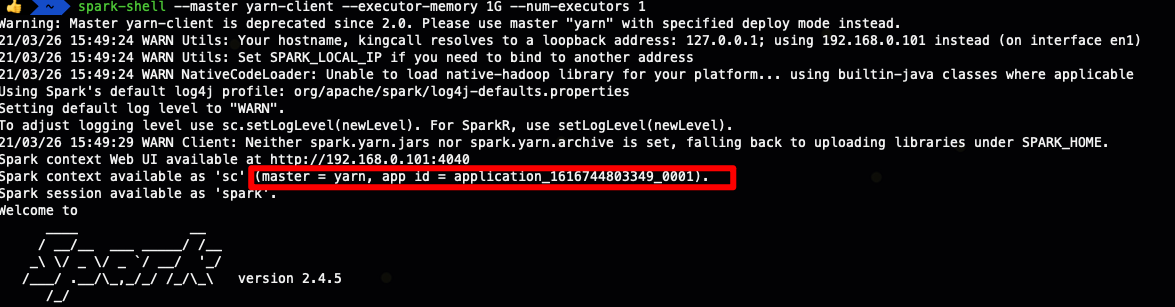
spark-shell --master yarn-client --executor-memory 1G --num-executors 1
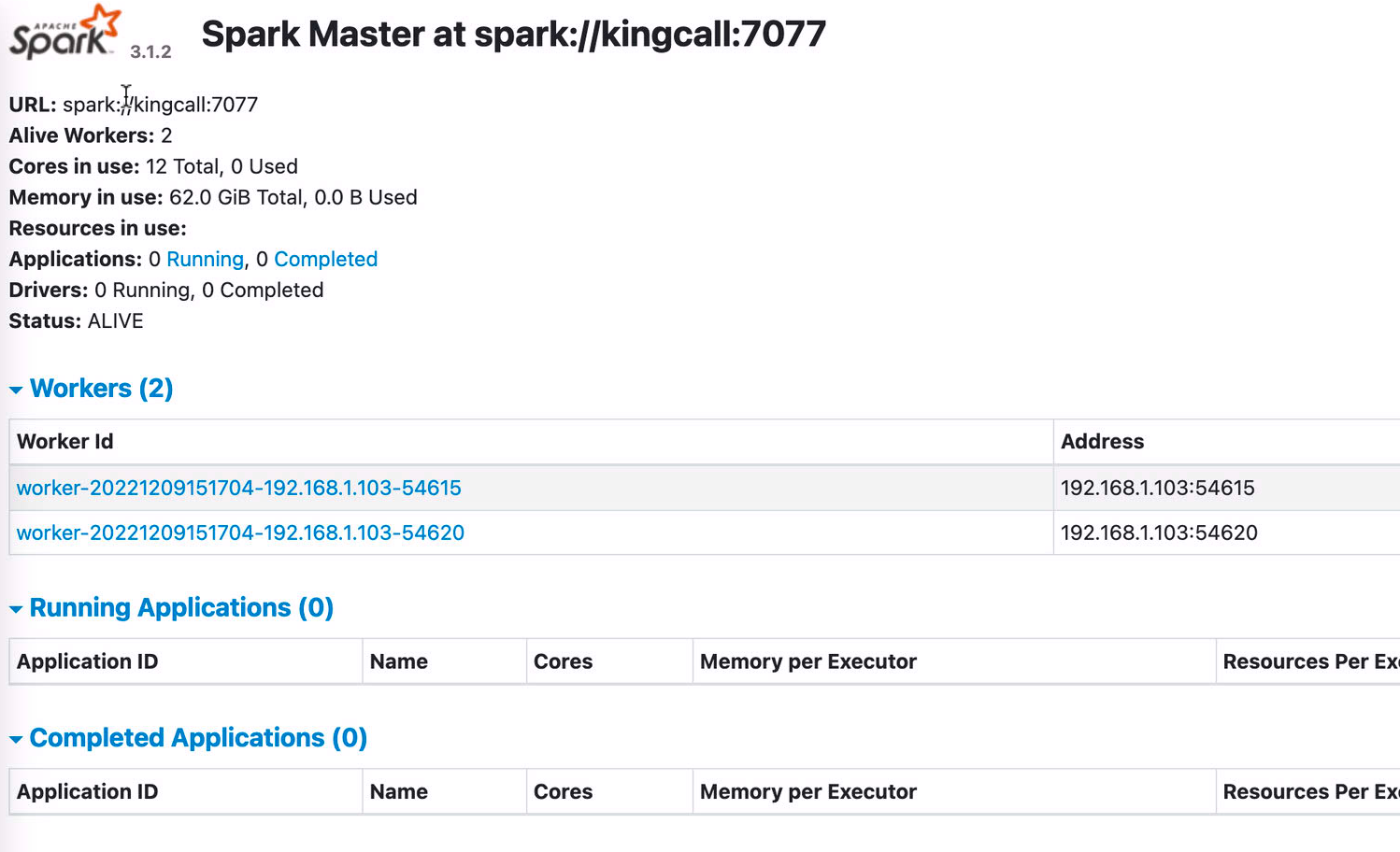
spark-shell --master spark://localhost:7077
这种就是我们自己搭建的spark 集群
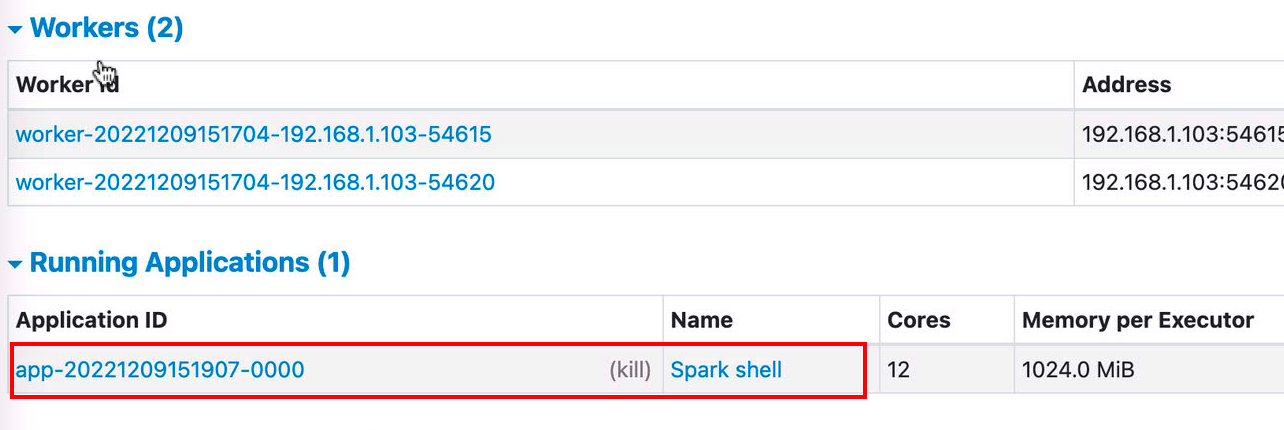
当我们的spark shell 程序提交后我们可以在
Running Applications
中看到
spark-submit
spark-submit 是spark 给我们提供的一个提交任务的工具,就是我们将代码打成jar 包后,提交任务到集群的方式
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster examples/jars/spark-examples_2.11-2.4.5.jar
这个日志信息还是很全的,我们可以看到大量相关的信息
Warning: Master yarn-cluster is deprecated since 2.0. Please use master "yarn" with specified deploy mode instead.
21/03/26 16:01:34 WARN Utils: Your hostname, kingcall resolves to a loopback address: 127.0.0.1; using 192.168.0.101 instead (on interface en1)
21/03/26 16:01:34 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
log4j:WARN No appenders could be found for logger (org.apache.hadoop.util.Shell).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
21/03/26 16:01:35 INFO Client: Requesting a new application from cluster with 1 NodeManagers
21/03/26 16:01:35 INFO Client: Verifying our application has not requested more than the maximum memory capability of the cluster (8192 MB per container)
21/03/26 16:01:35 INFO Client: Will allocate AM container, with 1408 MB memory including 384 MB overhead
21/03/26 16:01:35 INFO Client: Setting up container launch context for our AM
21/03/26 16:01:35 INFO Client: Setting up the launch environment for our AM container
21/03/26 16:01:35 INFO Client: Preparing resources for our AM container
21/03/26 16:01:35 WARN Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
21/03/26 16:01:38 INFO Client: Uploading resource file:/private/var/folders/27/mfdfy0s57037jxrxpl47g15h0000gn/T/spark-1816798f-0b99-40d2-9deb-a1397e9a90e3/__spark_libs__7076815768544123255.zip -> hdfs://kingcall:9000/user/liuwenqiang/.sparkStaging/application_1616744803349_0002/__spark_libs__7076815768544123255.zip
21/03/26 16:01:38 INFO Client: Uploading resource file:/usr/local/spark2.4/examples/jars/spark-examples_2.11-2.4.5.jar -> hdfs://kingcall:9000/user/liuwenqiang/.sparkStaging/application_1616744803349_0002/spark-examples_2.11-2.4.5.jar
21/03/26 16:01:39 INFO Client: Uploading resource file:/private/var/folders/27/mfdfy0s57037jxrxpl47g15h0000gn/T/spark-1816798f-0b99-40d2-9deb-a1397e9a90e3/__spark_conf__1386212354544661399.zip -> hdfs://kingcall:9000/user/liuwenqiang/.sparkStaging/application_1616744803349_0002/__spark_conf__.zip
21/03/26 16:01:39 INFO SecurityManager: Changing view acls to: liuwenqiang
21/03/26 16:01:39 INFO SecurityManager: Changing modify acls to: liuwenqiang
21/03/26 16:01:39 INFO SecurityManager: Changing view acls groups to:
21/03/26 16:01:39 INFO SecurityManager: Changing modify acls groups to:
21/03/26 16:01:39 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(liuwenqiang); groups with view permissions: Set(); users with modify permissions: Set(liuwenqiang); groups with modify permissions: Set()
21/03/26 16:01:40 INFO Client: Submitting application application_1616744803349_0002 to ResourceManager
21/03/26 16:01:40 INFO YarnClientImpl: Submitted application application_1616744803349_0002
21/03/26 16:01:41 INFO Client: Application report for application_1616744803349_0002 (state: ACCEPTED)
21/03/26 16:01:41 INFO Client:
client token: N/A
diagnostics: AM container is launched, waiting for AM container to Register with RM
ApplicationMaster host: N/A
ApplicationMaster RPC port: -1
queue: default
start time: 1616745700680
final status: UNDEFINED
tracking URL: http://localhost:8088/proxy/application_1616744803349_0002/
user: liuwenqiang
21/03/26 16:01:42 INFO Client: Application report for application_1616744803349_0002 (state: ACCEPTED)
21/03/26 16:01:43 INFO Client: Application report for application_1616744803349_0002 (state: ACCEPTED)
21/03/26 16:01:44 INFO Client: Application report for application_1616744803349_0002 (state: ACCEPTED)
21/03/26 16:01:45 INFO Client: Application report for application_1616744803349_0002 (state: ACCEPTED)
21/03/26 16:01:46 INFO Client: Application report for application_1616744803349_0002 (state: ACCEPTED)
21/03/26 16:01:47 INFO Client: Application report for application_1616744803349_0002 (state: ACCEPTED)
21/03/26 16:01:48 INFO Client: Application report for application_1616744803349_0002 (state: RUNNING)
21/03/26 16:01:48 INFO Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: 192.168.0.101
ApplicationMaster RPC port: 56995
queue: default
start time: 1616745700680
final status: UNDEFINED
tracking URL: http://localhost:8088/proxy/application_1616744803349_0002/
user: liuwenqiang
21/03/26 16:01:49 INFO Client: Application report for application_1616744803349_0002 (state: RUNNING)
21/03/26 16:01:50 INFO Client: Application report for application_1616744803349_0002 (state: RUNNING)
21/03/26 16:01:51 INFO Client: Application report for application_1616744803349_0002 (state: RUNNING)
21/03/26 16:01:52 INFO Client: Application report for application_1616744803349_0002 (state: RUNNING)
21/03/26 16:01:53 INFO Client: Application report for application_1616744803349_0002 (state: FINISHED)
21/03/26 16:01:53 INFO Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: 192.168.0.101
ApplicationMaster RPC port: 56995
queue: default
start time: 1616745700680
final status: SUCCEEDED
tracking URL: http://localhost:8088/proxy/application_1616744803349_0002/
user: liuwenqiang
21/03/26 16:01:53 INFO ShutdownHookManager: Shutdown hook called
21/03/26 16:01:53 INFO ShutdownHookManager: Deleting directory /private/var/folders/27/mfdfy0s57037jxrxpl47g15h0000gn/T/spark-1816798f-0b99-40d2-9deb-a1397e9a90e3
21/03/26 16:01:53 INFO ShutdownHookManager: Deleting directory /private/var/folders/27/mfdfy0s57037jxrxpl47g15h0000gn/T/spark-1a6cc57e-8493-4ceb-b965-d85efd53cede
创建RDD
创建 RDD 主要有以下三种方式:
从本地文件系统创建RDD
先在 Spark_Home 目录下创建 data.txt。
scala> val data = sc.textFile("data.txt")
其中,sc 是 SparkContext 对象,在启动 Spark Shell 的时候自动生成的。
如果数据已经存在外部文件系统,例如本地文件系统,HDFS,HBase,Cassandra,S3 等,可以使用这种方式,即调用 SparkContext 的 textFile 方法,并把文件目录或者路径作为参数。
用 Parallelize 函数创建 RDD
scala> val no = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)scala> val noData = sc.parallelize(no)
这种方法可以用于数据集已经存在的情况。
从其他RDD创建新RDD
scala> val newRDD = no.map(data => (data * 2))
对RDD 进行操作
RDD 总记录条数
计算 RDD 的总记录数可以使用 count() 函数
scala> data.count()
数据过滤操作
过滤操作可以使用 RDD 的 filter 操作,即从已经存在的 RDD 中按条件过滤并创建新 RDD。
scala> val DFData = data.filter(line => line.contains("Elephant"))
执行转换操作和行动操作
可以用点操作符把转换和行动操作串起来执行。比如 filter 操作和 count 操作:
scala> data.filter(line => line.contains("Elephant")).count()
读取 RDD 第一条记录
为了从文件读取第一个记录,可以使用first()函数
scala> data.first()
从 RDD 读取5条记录
scala> data.take(5)
RDD 分区
一个 RDD 通常都会被分成多个分区,查看分区数:
scala> data.partitions.length
注意:如果从HDFS创建新RDD,那么HDFS数据文件的block数将等于分区数。
缓存 RDD
缓存 RDD 可以显著提高数据读取速度和计算速度。一旦把 RDD 缓存在内存中,后续使用这个 RDD 的计算,都会从内存中取数据,这样可以减少磁盘寻道时间,提高数据计算性能。
scala> data.cache()
上面这个操作其实是个转换(Tranformation)操作,也就是说这个命令执行完,RDD 并不会被立即缓存,如果你查看Spark Web UI页面:
http://localhost:4040/storage
,你是找不到相关缓存信息的。执行
cache()
操作,RDD并不会立即缓存,直到执行行动(Action)操作,数据才会真正缓存在内存中。比如
count()
或者
collect()
:
scala> data.count()
scala> data.collect()
现在我们已经执行了行动操作,执行这些操作需要从磁盘读取数据,Spark在处理这些操作的时候,会把数据缓存起来,后续不管对该RDD执行转换操作还是行动操作,都将直接从内存读取,而不需要和磁盘进行交互。所以,可以把多次使用的RDD缓存起来,提升数据处理性能。
从 HDFS 读取数据
要读取 HDFS 的文件,必须要提供文件的完整 URL。也可以是分布式文件系统,文件系统标识是 hdfs,比如:``hdfs://IP:PORT/PATHscala> var hFile = sc.textFile(“hdfs://localhost:9000/inp”)`
用 Scala 编写 wordcout 应用
wordcount 应用,即英文单词数量统计应用,堪称大数据界的 hello word 程序。是最经典的 MapReduce 操作案例之一。
scala> val wc = hFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)
在控制台读取前5个统计结果:
scala> wc.take(5)
把计算结果写入HDFS文件
可以用 saveAsTextFile 操作把计算好的结果保存在 HDFS。
scala> wc.saveAsTextFile("hdfs://localhost:9000/out")
版权归原作者 不二人生 所有, 如有侵权,请联系我们删除。