
Kaggle 是全球首屈一指的数据科学网,Kaggle 现在每月提供表格竞赛,为像我这样的新手提供提高该领域技能的机会。因为 Kaggle 提供了一个很好的机会来提高我的数据科学技能,所以我总是期待着这些每月的比赛,并在时间允许的情况下参加。虽然有些人为了获胜而参加每月的比赛,但不幸的是我没有时间投入到一场比赛中,所以我通过这些比赛来编写整洁的代码并提高我的编程技能。
在这篇文章中,我将讨论我如何使用 sklearn 的 GenericUnivariateSelect 函数来提高我最初获得的分数。GenericUnivariateSelect 是 sklearn 的特征选择工具之一,具有可配置的策略。此函数使用超参数搜索估计器执行单变量特征选择。在这篇文章中,GenericUnivariateSelect 将执行一个测试,只执行最好的十个特征。该函数将以评分函数作为输入并返回单变量分数和 p 函数。
2021 年 8 月表格比赛的问题陈述如下:-

我使用 Kaggle 的免费在线 Jupyter Notebook 为这次比赛创建了程序。创建程序后,我导入了执行程序所需的库。我通常只在需要时导入库,但我最初导入的库是 numpy、pandas、os、sklearn、matplotlib 和 seaborn。Numpy 用于计算代数公式,pandas 用于创建数据帧并对其进行操作,os 进入操作系统以检索程序中使用的文件,sklearn 包含大量机器学习函数,matplotlib 和 seaborn 将数据点转换为 图形表示的df:-
导入库并检索程序中使用的文件后,我将这三个文件用 Pandas 读入程序,并将它们命名为train、test和submit:-
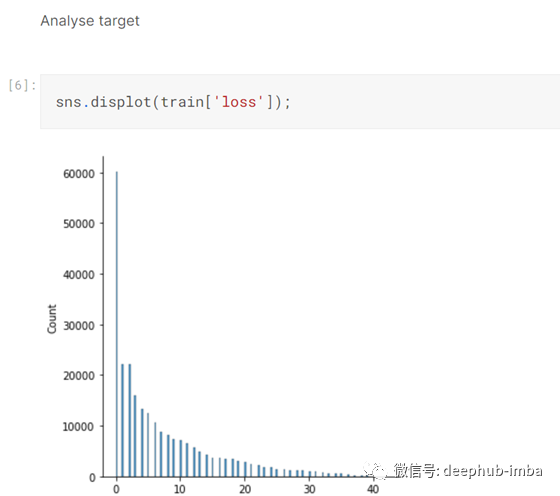
然后我分析了目标,发现我正在处理一个回归问题:-
我在训练数据中定义了目标列 loss。然后我从训练数据中将其删除:-

此时,train和test大小相同,所以我添加了test到train,并把他们合并成一个df:
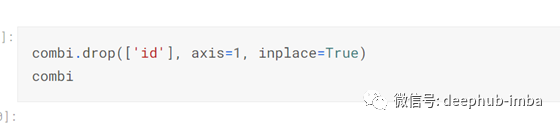
然后我从combi中删除了id列,因为它不需要执行预测:
现在我通过将每个数据点转换为0到1之间的值来规范化数据,因为这将更容易让模型做出预测:-

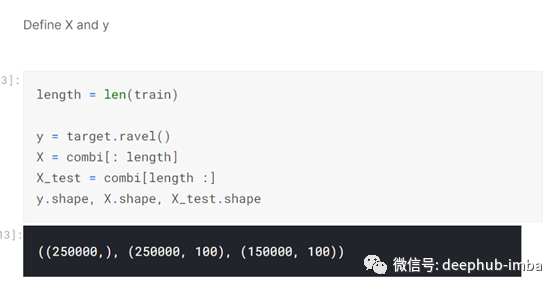
当combi经过预处理后,定义自变量和因变量,分别为X和y。y变量由之前定义的目标组成。X变量由combi数据帧到数据帧的长度train组成。
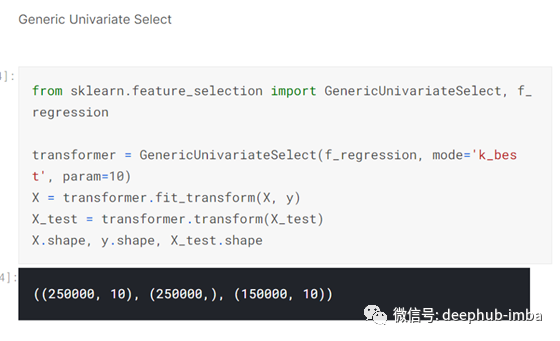
一旦定义了因变量和自变量,我就使用sklearn的GenericUnivariateSelect函数来选择10个最好的列或特性。这样做的原因是,在100列数据上进行训练在计算上是很费力的,因为系统中存在潜在的噪声,以及可以删除的大量冗余数据
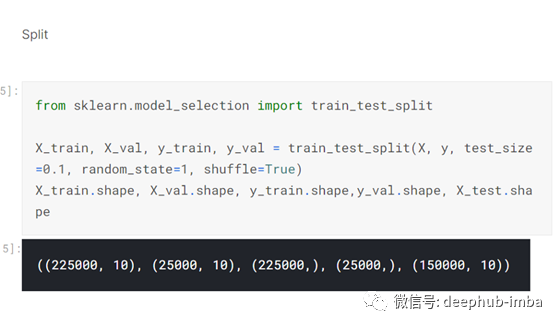
一旦数据集的特性被裁剪为10个最好的列,sklearn的train_test_split函数将数据集分割为训练集和验证集:-
现在是选择模型的时候了,在这个例子中,我决定使用sklearn的线性回归进行第一个尝试,训练和拟合数据到这个模型:-
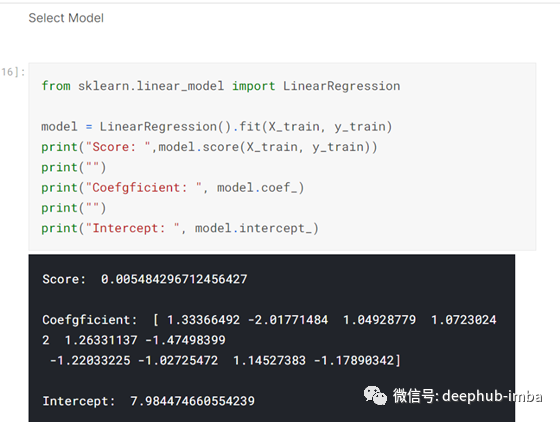
然后在验证集上预测:-
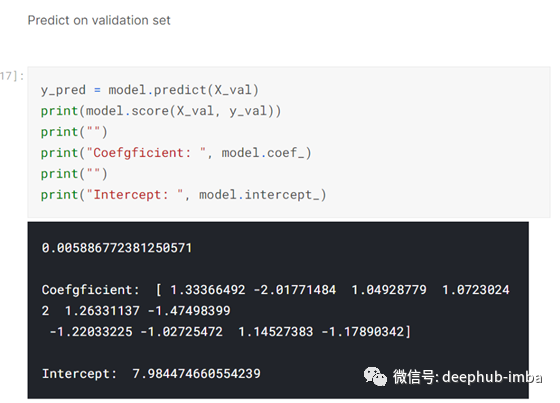
一旦对验证集进行了预测,我就会评估这些预测:-
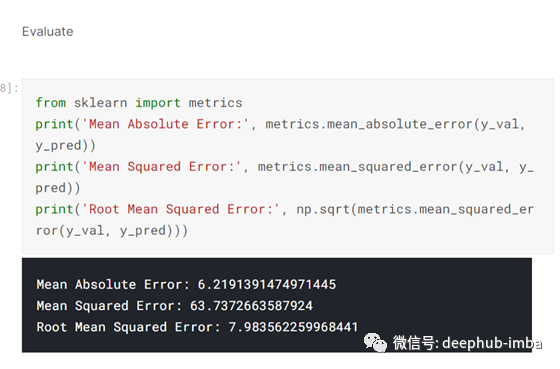
然后我将验证集的实际值与预测值进行比较:-
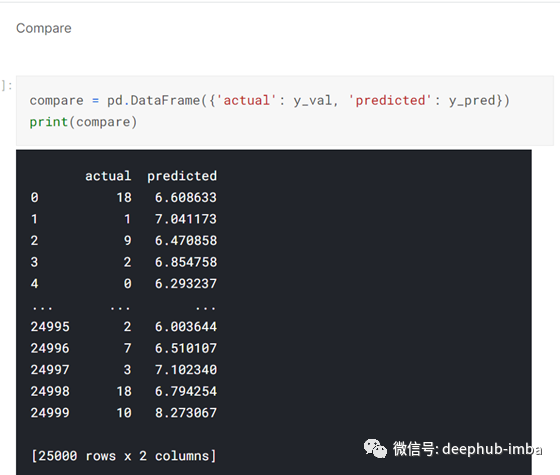
然后,我绘制了一张图,将验证集的实际值与预测值进行对比,这张图揭示了一些有趣的结果:-
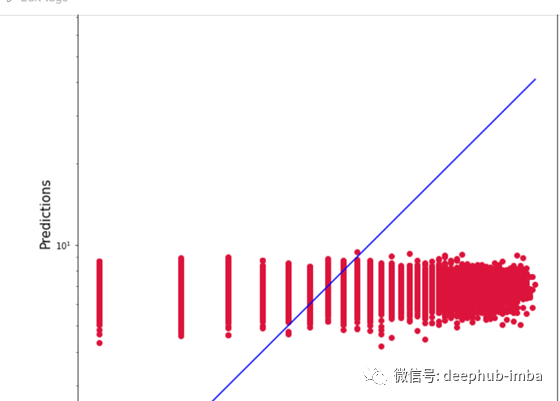
然后我在测试集上预测:-
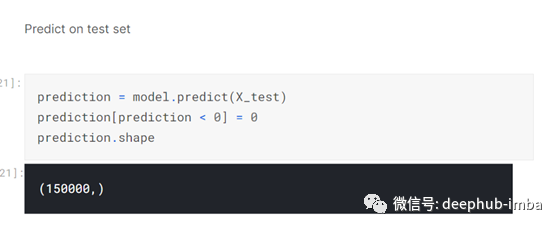
预测完成就要提交给Kaggle进行评分的预测。
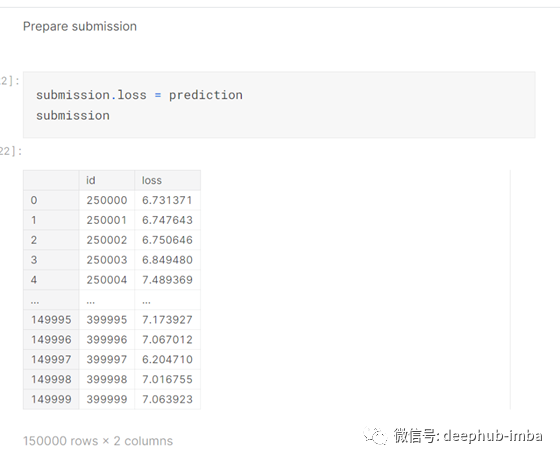
然后我将提交的数据转换为csv文件
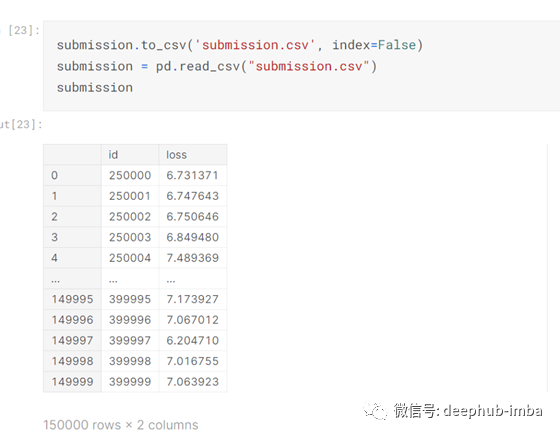
当我将提交的csv文件提交给Kaggle打分时,我的分数达到了7.97分,这比我之前的分数稍好一些
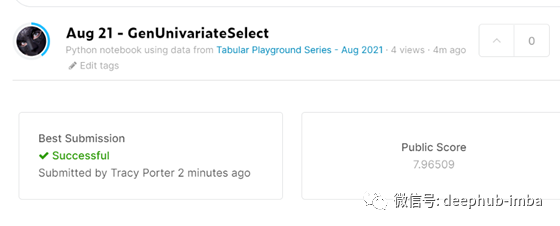
总之,当我尝试不同的特征选择技术时,能稍微提高我的分数。诀窍就是在这场比赛中尝试尽可能多的技巧来获得胜利。还有一些其他的技巧我可以使用,如果时间允许,我可能会尝试一下,看看我是否可以提高分数一点点。
这个程序的代码可以在我的个人GitHub账户中找到,链接在这里:- https://www.kaggle.com/tracyporter/aug-21-genunivariateselect?scriptVersionId=69573546
本文作者:Tracyrenee