
「发表于知乎专栏《移动端算法优化》」
本节主要介绍基本 SIMD 及其他的指令流与数据流的处理方式,NEON 的基本原理、指令以及与其他平台及硬件的对比。
🎬个人简介:一个全栈工程师的升级之路!
📋个人专栏:高性能(HPC)开发基础教程
🎀CSDN主页 发狂的小花
🌄人生秘诀:学习的本质就是极致重复!
一、SIMD
ARM NEON 是适用于 ARM Cortex-A 和 Cortex-R 系列处理器的一种 SIMD(Single Instruction Multiple Data)扩展架构。
SIMD 采用一个控制器来控制多个处理器,同时对一组数据(又称“数据向量”)中的每个数据分别执行相同操作,从而实现并行技术。
SIMD 特别适用于一些常见的任务,如音频图像处理。大部分现代 CPU 设计都包含了 SIMD 指令,来提高多媒体使用的性能。

SIMD 操作示意图
如上图所示,标量运算时一次只能对一对数据执行乘法操作,而采用 SIMD 乘法指令,则一次可以对四对数据同时执行乘法操作。
A. 指令流与数据流
费林分类法根据指令流(Instruction)和数据流(Data)的处理方式进行分类,可分成四种计算机类型:

费林分类示意图
1. SISD(Single Instruction Single Data)
机器的硬件不支持任何形式的并行计算,所有的指令都是串行执行。单个核心执行单个指令流 , 操作存储在单个内存中的数据 , 每次一个操作。早期的计算机都是SISD机器,如冯诺.依曼架构,IBM PC机等。
2. MISD(Multiple Instruction Single Data)
是采用多个指令流来处理单个数据流。由于实际情况中,采用多指令流处理多数据流才是更有效的方法,因此MISD只是作为理论模型出现,没有投入到实际应用之中。
3. MIMD(Mutiple Instruction Mutiple Data)
计算机具有多个异步和独立工作的处理器。在任何时钟周期内,不同的处理器可以在不同的数据片段上执行不同的指令,也即是同时执行多个指令流,而这些指令流分别对不同数据流进行操作。MIMD架构可以用于诸如计算机辅助设计、计算机辅助制造、仿真、建模、通信交换机的多个应用领域。
除了以上模型外,由NVIDIA公司生产的GPU引入SIMT体系结构:
4. SIMT(Single Instruction Multiple Threads)
类似 CPU 上的多线程,所有的核心各有各的执行单元,数据不同,执行的命令是相同的。多个线程各有各的处理单元,和 SIMD 共用一个 ALU 不同。
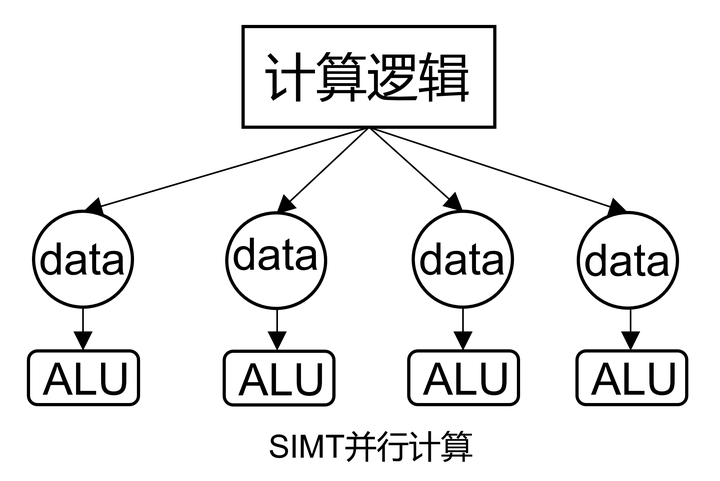
SIMT 示意图
B. SIMD 特点及发展趋势
1. SIMD 优势与不足
优势不足- 效率高
- 适合计算密集型
- 提供专用指令- 适用场景有限
- 功耗高和芯片面积大
- 开发难度大
- 数据对齐要求
2. SIMD发展趋势
以ARM架构下的下一代 SIMD 指令集 SVE(Scalable Vector Extension,可扩展矢量指令)为例,其是针对高性能计算(HPC)和机器学习等领域开发的一套全新的矢量指令集。
SVE 指令集中有很多概念与 NEON 指令集类似,例如矢量、通道、数据元素等。
SVE指令集也提出了一个全新的概念:可变矢量长度编程模型。

SVE 可扩展模型
传统的 SIMD 指令集采用固定大小的向量寄存器,例如 NEON 指令集采用固定的 64/128 位长度的矢量寄存器。
而支持 VLA 编程模型的 SVE 指令集则支持可变长度的矢量寄存器。因此允许芯片设计者根据负载和成本来选择一个合适的矢量长度。
SVE 指令集的矢量寄存器的长度最小支持 128 位,最大可以支持 2048 位,以 128 位为增量。SVE 设计确保同一个应用程序可以在支持不同矢量长度的 SVE 指令机器上运行,而不需要重新编译代码。
ARM 在 2019 年便推出了 SVE2,以最新的 Armv9 为基础,扩充了更多的运算类型以全面替代 NEON,同时增加了矩阵相关运算的支持。
**二、 **ARM 的 SIMD 指令集
1. ARM 处理器的 SIMD 支持 - NEON
ARM NEON 单元默认包含在 Cortex-A7 和 Cortex-A15 处理器中,但在其他 ARMv7 Cortex-A 系列处理器中是可选的,某些实现 ARMv7–A 或 ARMv7–R 架构配置文件的Cortex-A 系列处理器可能不包含NEON单元。
符合 ARMv7 的内核的可能组合有以下四种:
NEONVFP有无无无有有五有
因此必须首先确认处理器是否支持 NEON 和 VFP。可以在编译和运行的时候进行检查。

NEON 发展史
2. ARM 处理器的 SIMD 支持检查
2.1 编译阶段检查
检测 NEON 单元是否存在的最简单方法。在 ARM 编译器工具链(armcc)v4.0 及更高版本或 GCC 中,检查预定义宏 **ARM_NEON **或者 __arm_neon 是否开启。
**armasm **等效的预定义宏是 TARGET_FEATURE_NEON。
2.2 运行阶段检查
在运行时检测 NEON 单元需要操作系统的帮助。ARM 架构有意不向用户模式应用程序公开处理器功能。在Linux下,
/proc/cpuinfo
以可读的形式包含此信息,比如:
- 在Tegra(带有FPU的双核Cortex-A9处理器)
$ /proc/cpuinfo
swp half thumb fastmult vfp edsp thumbee vfpv3 vfpv3d16
- 带有 NEON 单元的 ARM Cortex-A9 处理器
$ /proc/cpuinfo
swp half thumb fastmult vfp edsp thumbee neon vfpv3
由于
/proc/cpuinfo
输出是基于文本的,因此通常首选查看辅助向量
/proc/self/auxv
,其包含二进制格式的内核 hwcap,可以轻松地在
/proc/self/auxv
文件中搜索 AT_HWCAP 记录,以检查 HWCAP_NEON 位(4096)。
某些 Linux 发行版 ld.so 链接器脚本被修改为通过 glibc 读取 **hwcap **,并为启用 NEON 的共享库添加额外的搜索路径。
3. 指令集关系
- 在ARMv7中,NEON 与 VFP 指令集具有以下关系: - 具有 NEON 单元但没有VFP单元的处理器无法在硬件中执行浮点运算。- 由于 NEON SIMD 操作更有效地执行向量计算,因此从 ARMv7 的引入开始,VFP 单元中的向量模式操作已被弃用。因此,VFP 单元有时也称为浮点单元(FPU)。- VFP 可以提供完全兼容 IEEE-754 的浮点运算,ARMv7 NEON 单元中的单精度运算不完全符合 IEEE-754。- NEON不能取代 VFP。VFP 提供了一些在 NEON 指令集中没有等效实现的专用指令。- 半精度指令仅适用于包含半精度扩展的 NEON 和 VFP 系统。- 在ARMv8中,VFP已被NEON取代,以上问题如 NEON 并不完全符合 IEEE 754 标准,并且有一些指令 VFP 支持而 NEON 不支持的问题已在 ARMv8 中得到解决。
三、NEON
NEON 是适用于 ARM Cortex-A 系列处理器的一种128位 SIMD 扩展结构,每个处理器核心均有一个 NEON 单元,因此可以实现多线程并行的加速效果。
1. NEON基本原理
1.1 NEON 指令执行流程

上图为 NEON 单元完成加速计算的流程图。其中向量寄存器中的每个元素同步执行计算,以此来加速计算过程。
1.2 NEON 计算资源
- NEON 与 ARM 处理器资源关系
NEON 单元作为 ARM指令集的扩展,使用独立于 ARM 原有寄存器的 64位 或 128 位寄存器进行 SIMD 处理,在 64位 寄存器的寄存器文件上运行。
NEON 和 VFP 单元完全集成到了处理器中,并共享处理器资源以进行整数运算、循环控制和缓存。
与硬件加速器相比,这显着降低了面积和功耗成本。并且其还使用更简单的编程模型,因为NEON 单元使用与应用程序相同的地址空间。
- NEON 与 VFP 资源关系
NEON 寄存器与 VFP 寄存器重叠,ARMv7 有 32 个 NEON D 寄存器,如下图所示。
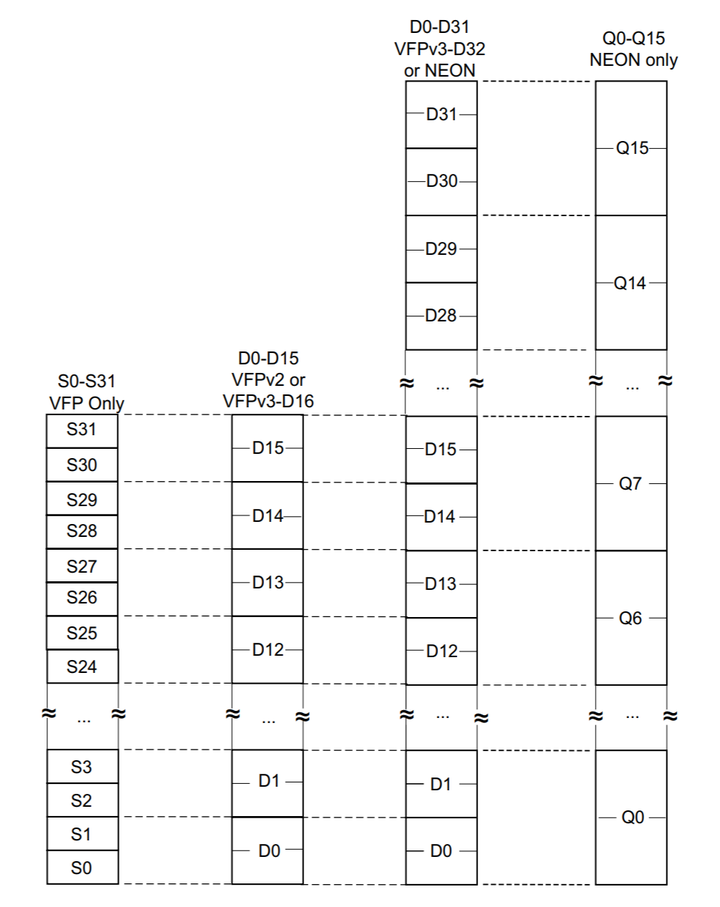
NEON 寄存器
2. NEON指令
2.1 自动矢量化
向量化编译器可以使用 C 或 C++ 源代码,以一种能够有效使用 NEO N硬件的方式对其进行矢量化。这意味着可以通过编写可移植的 C 代码,同时仍然可以获得 NEON 指令所带来的性能水平。
为了帮助矢量化,将循环迭代次数设为矢量长度的倍数。GCC 和 ARM 编译器工具链都具有为 NEON 技术启用自动矢量化的选项。
2.2 NEON汇编
对于性能要求特别高的程序,手工编写汇编代码是更适合的方式。
GNU 汇编器(gas) 和 ARM Compile r工具链汇编器(armasm)都支持 NEON 指令的汇编。
编写汇编函数时,需要了解 ARM EABI,其定义了如何使用寄存器。ARM嵌入式应用程序二进制接口(EABI)指定哪些寄存器用于传递参数、返回结果或必须保留,指定了除ARM内核寄存器之外的32个D寄存器的使用。下图对寄存器功能进行了总结。

寄存器功能
2.3 NEON Intrinsics
NEON intrinsic 函数提供了一种编写 NEON 代码的方法,该方法比汇编代码更易于维护,同时仍然可以控制生成的 NEON 指令。
内部函数使用与 D 和 Q NEON 寄存器对应的新数据类型。数据类型支持创建直接映射到NEON 寄存器的 C 变量。
NEON intrinsic 函数的编写类似于使用这些变量作为参数或返回值的函数调用。编译器做了一些通常与编写汇编语言相关的繁重工作,例如:
寄存器分配
代码调度或重新排序指令
- intrinsic 缺点
无法让编译器准确输出想要的代码,因此在转向NEON汇编代码时仍有一些改进的可能性。
- NEON 指令简类型
NEON 数据处理指令可以分为正常指令、长指令、宽指令、窄指令和饱和指令。
以 Intrinsic 的长指令为例
int16x8_t vaddl_s8(int8x8_t __a, int8x8_t __b);
- 上面的函数将两个64位的 D 寄存器向量(每个向量包含8个8位数字)相加,生成一个包含8个16位数字的向量(存储在128位的Q寄存器中),从而避免相加的结果溢出。
四、其他 SIMD 技术
1. 其他平台上的 SIMD 技术
SIMD 处理不是 ARM 独有的,下图将其与 x86 和 Altivec 进行了比较。
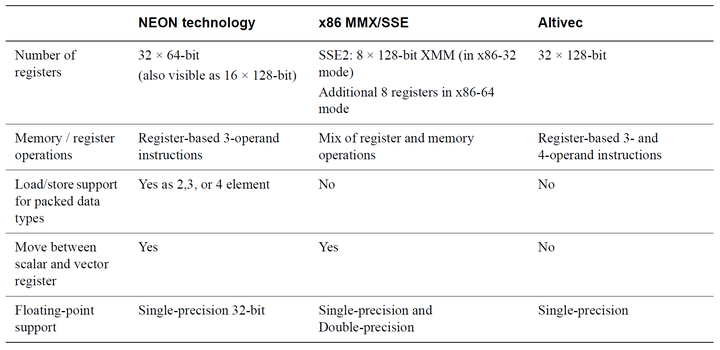
SIMD 对比
2. 与专用 DSP 对比
许多基于 ARM 的 SOC 中还包含 DSP 等协处理硬件,因此可以同时包含 NEON 单元和DSP。相对于 DSP,NEON 的特点有:
NEONDSP特点- 扩展了ARM 处理器流水线
- 使用 ARM 内核寄存器进行内存寻址- 简易的开发和调试
- SMP 能力。MPCore 处理器中的每个 ARM 内核都有一个 NEON 单元。
- 开源社区和ARM生态系统都提供了广泛的 NEON 工具支持- 与 ARM 处理器并行运行
- 与 ARM 处理器集成度较低。在 DSP 和 ARM 处理器之间传输数据可能会有一些缓存清理或刷新开销。
四、总结
本节主要介绍基本 SIMD 及其他的指令流与数据流的处理方式,NEON 的基本原理、指令以及与其他平台及硬件的对比。
期望大家都能有所收获。
未完待续。。。
🌈我的分享也就到此结束啦🌈
如果我的分享也能对你有帮助,那就太好了!
若有不足,还请大家多多指正,我们一起学习交流!
📢未来的富豪们:点赞👍→收藏⭐→关注🔍,如果能评论下就太惊喜了!
感谢大家的观看和支持!最后,☺祝愿大家每天有钱赚!!!欢迎关注、关注!
版权归原作者 发狂的小花 所有, 如有侵权,请联系我们删除。