
chrome浏览器,输入网址后,F12
按红色标记,找到数据请求地址url,
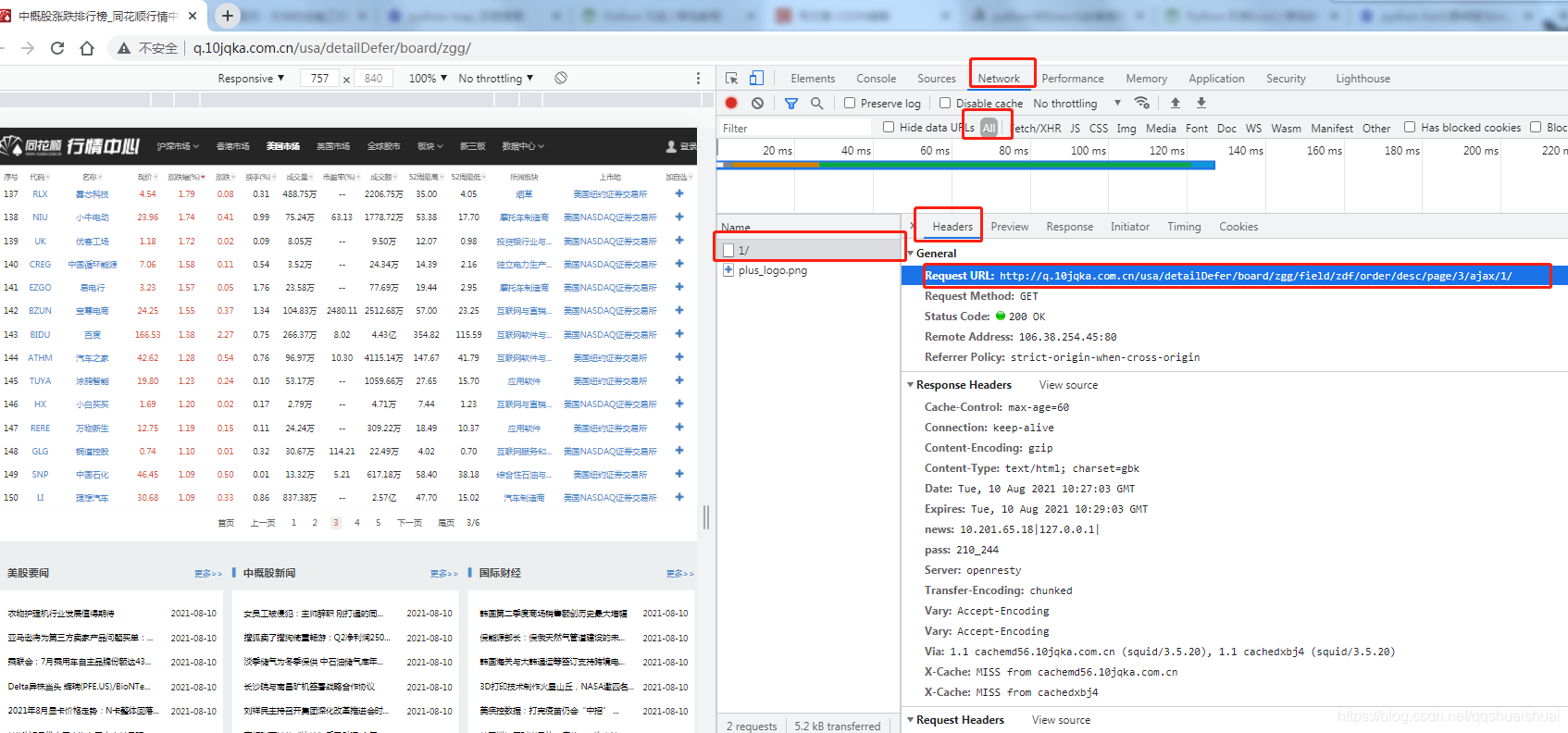
这是请求 Headers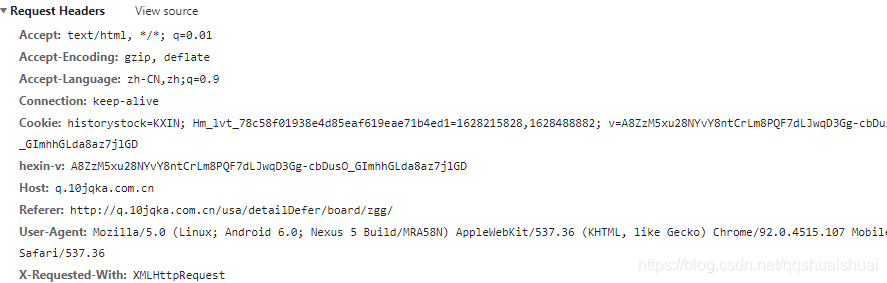
通过requests get方法抓取网页
requests.get(url=url, headers=headers)
get成功后,对网页进行解析,使用BeautifulSoup抓取想要的信息
soup = BeautifulSoup(req.text, 'html.parser')
学习了几个函数使用方法
res = ['1','2','3']
1.将列表里的字符串转换为int类型的值,可以使用map(int, res );
2.使用正则表达式,将字符串中的汉字去掉,只保留数字列表,可以用正则表达式处理:
pattern = re.compile(r'\d+') # 查找数字
result1 = pattern.findall(con7.text)
标签:
python
本文转载自: https://blog.csdn.net/qqshuaishuai/article/details/119576474
版权归原作者 阿土有品 所有, 如有侵权,请联系我们删除。
版权归原作者 阿土有品 所有, 如有侵权,请联系我们删除。