
爬虫和反爬虫之间的斗争
爬虫的建议
动态HTML技术了解
获取ajax数据的方式
selenium+chromedriver获取动态数据
selenium
下载chromedriver
安装Seleniumselenium入门
Chrome(了解)
Chrome案例
selenium案例
定位元素
执行JS
操作表单元素
登录豆瓣练习
行为链
Cookie操作
页面等待
打开多窗口和切换页面
selenium被识别解决方案
爬虫和反爬虫之间的斗争
俗话说得好,有阴必要阳,,那么有爬虫就会有反爬,作为其中的一员我们要明白,这条道路一旦上路就会加入其中一方,后面我们会不断遇见各种情况,但我们都会慢慢克服过去
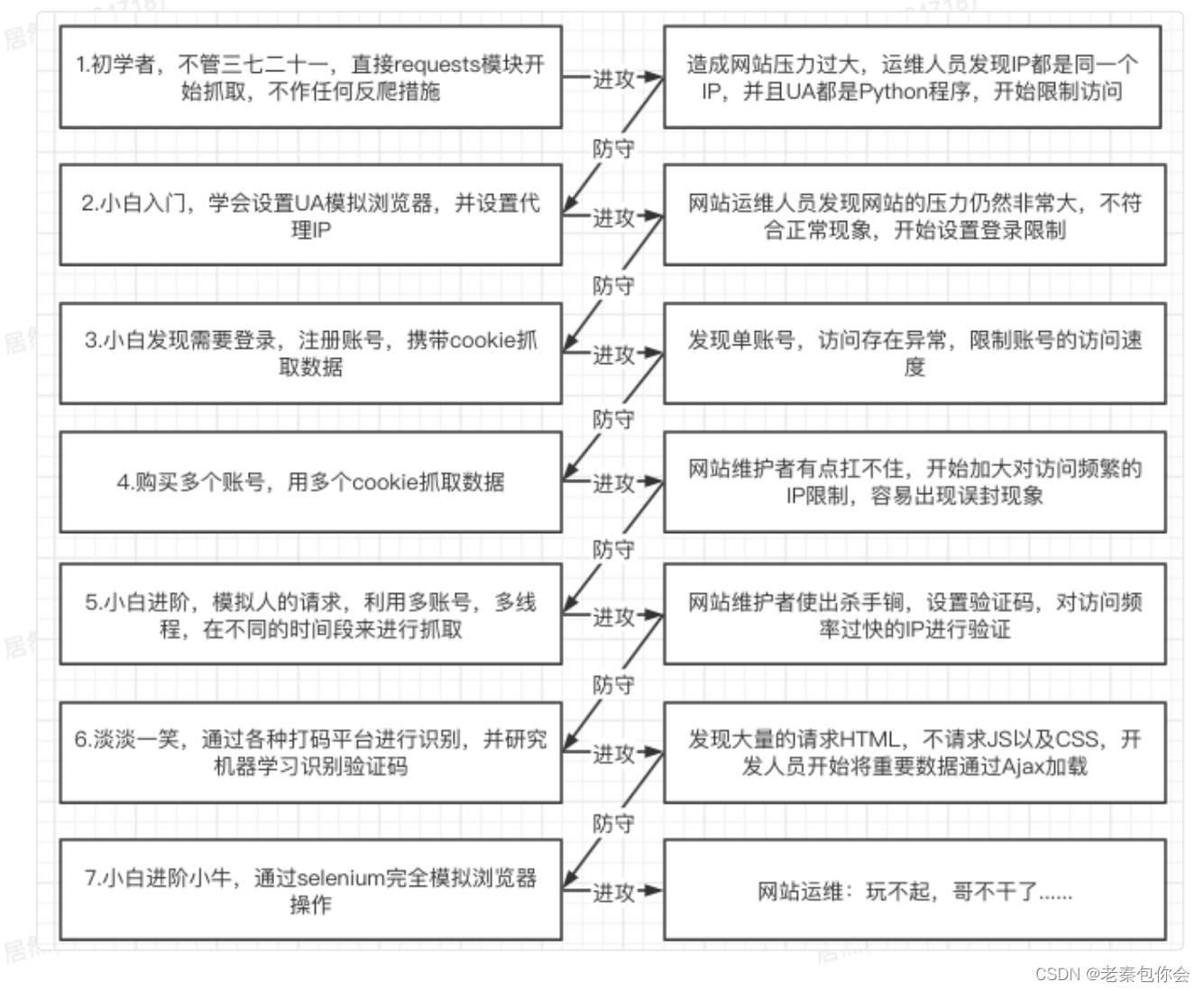
** 爬虫的建议**
有一些小可爱可能觉得就爬的次数和网站的容纳数比例很小,就使劲爬呀爬,突然发现,自己被制裁了,
送你几个字:你完了,等着换网站爬,所以我们又想爬又怕被封,我的建议有以下几点:
● 尽量减少请求次数
○ 能抓取列表⻚就不抓详情⻚
○ 保存获取到的HTML,供查错和重复使⽤
● 关注⽹站的所有类型的⻚⾯
○ H5⻚⾯
○ APP
● 多伪装
○ 代理IP
○使⽤cookie
○利⽤多线程分布式
○在不被ban的请求下尽可能的提⾼速度
动态HTML技术了解
JS
是⽹络上最常⽤的脚本语⾔,它可以收集⽤户的跟踪数据,不需要重载⻚⾯
直接提交表单,在⻚⾯嵌⼊多媒体⽂件,甚⾄运⾏⽹⻚
jQuery
jQuery是⼀个快速、简介的JavaScript框架,封装了JavaScript常⽤的功
能代码
ajax
ajax可以使⽤⽹⻚实现异步更新,可以在不重新加载整个⽹⻚的情况下,对
⽹⻚的某部分进⾏更新
我们碰见到的大多数还是ajax可能一些小可爱不知道ajax是啥,这是一种用于加密的html一种模块
是为了防止爬虫的,身为爬虫的我们怎么能被这个拦住呢,下面我来一一破解
获取ajax数据的方式
对症下药能很快治疗,所有我们要想破解这个就要对症下药,深入源点了解一下,重要时可以补一刀
1.直接分析ajax调⽤的接⼝。然后通过代码请求这个接⼝。
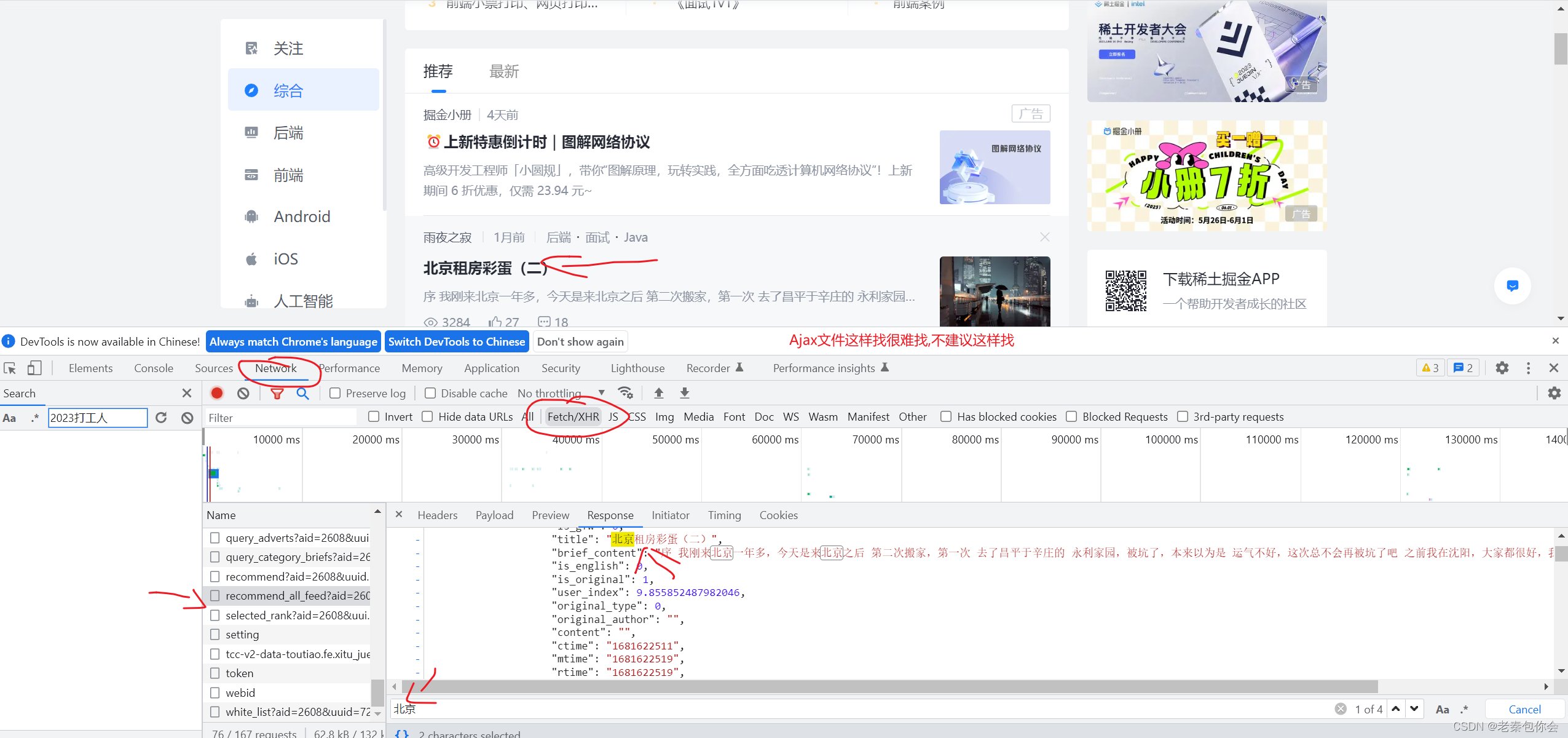
2.使⽤Selenium+chromedriver模拟浏览器⾏为获取数据
下面会慢慢介绍
小结:第一种方法找ajax文件太麻烦,不建议,下面还有一些情况:

** Selenium 模块**
下面我将来一一介绍selenium
selenium是⼀个web的⾃动化测试⼯具,最初是为⽹站⾃动化测试⽽开发的,
selenium可以直接运⾏在浏览器上,它⽀持所有主流的浏览器,可以接收指
令,让浏览器⾃动加载⻚⾯,获取需要的数据,甚⾄⻚⾯截屏
下载chromedriver
当我们要使用selenium前要有一个工具来操作页面这样我们才能自动操作页面
这里我推荐谷歌浏览器
chromedriver文件下载:
https://registry.npmmirror.com/binary.html?path=chromedriver/
后操作如下:

找到对应的版本下载就可以了
安装Seleniumselenium入门

输入pip install selenium下载就可以了
Phantomjs(了解)/Chrome
Phantomjs是⼀个基于webkit的"⽆界⾯"浏览器,它会把⽹站加载到内存并执
⾏⻚⾯上的JavaScript
由于我们使用的是谷歌浏览器,所以就使用Chrome
Chrome案例
在百度搜索小姐姐
代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
# 创建一个浏览器
driver = webdriver.Chrome()
# 利用浏览器打开网站
driver.get("https://www.baidu.com/?tn=02003390_19_hao_pg")
# 截图
driver.save_screenshot("百度.png")
# 定位输入框
input1=driver.find_element_by_id("kw")
# input1=driver.find_element_by_xpath('//div[@id="kw"]')
# input1=driver.find_element_by_name("wd")
# input1=driver.find_element_by_class_name("s_ipt")
# input1=driver.find_element(By.ID,"kw")
# input1=driver.find_element(By.XPATH,'//div[@id="kw"]')
# input1=driver.find_element(By.NAME,"wd")
# input1=driver.find_element(By.CLASS_NAME,"s_ipt")
# 输入内容
input1.send_keys("小姐姐")
# 定位百度一下
button=driver.find_element(By.ID,"su")
# 点击
button.click()
# 休息一下10s再运行
time.sleep(10)
# 关闭当前页面
driver.close()
# 关闭整个浏览器
driver.quit()
运行结果

导入库
**from selenium import webdriver**
drider=webdriver.Chrome():创建一个浏览器
driver.get(url):利用浏览器打开网站
driver.save_screenshot("百度.png"): 截图
下面的方法是导入旧版selenim模块的使用方法
input1=driver.find_element_by_id("kw")
# input1=driver.find_element_by_xpath('//div[@id="kw"]')
# input1=driver.find_element_by_name("wd")
# input1=driver.find_element_by_class_name("s_ipt")
# input1=driver.find_element(By.ID,"kw")
find_element_by_class_name :根据类名查找元素。
find_element_by_name :根据name属性的值来查找元素。
find_element_by_tag_name :根据标签名来查找元素。(上面没写有,小可爱们可以试试看看)
find_element_by_xpath :根据xpath语法来获取元素。
find_element_by_css_selector :根据css选择器选择元素。
注意:! ! !
find_element 是获取第⼀个满⾜条件的元
素。 find_elements 是获取所有满⾜条件的元素。
导入最新版本的使用方法
导入:from selenium.webdriver.common.by import By
# input1=driver.find_element(By.ID,"kw")
# input1=driver.find_element(By.XPATH,'//div[@id="kw"]')
# input1=driver.find_element(By.NAME,"wd")
# input1=driver.find_element(By.CLASS_NAME,"s_ipt")
可能一些小可爱们会想到如果输入框有内容咋办,其实很简单,就是全部删除:
driver.clear()
输入内容
input1.send_keys(文本)
.click()点击
关闭当前页面:driver.close()
关闭整个浏览器:driver.quit()
当我们进入页面后就会迫不及待想进行下一步:比如滑动下拉
首先我们还要再输入执行Js语句,这里的Js语句不是前端的,是python的叫法
js的操作
# 执行js语句滑动
# 滑到最底下
# js = "window.scrollTo(0, document.body.scrollHeight)"
# 滑到顶部
js = "window.scrollTo(0, 0)"
driver.execute_script(js)
element=driver.find_element()
# 下滑到指定元素的位置
driver.execute_script("arguments[0].scrollIntoView();", element)
# 下滑到指定元素的位置
driver.execute_script("arguments[0].scrollIntoView(false);", element)
登录豆瓣练习
代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
# 创建一个浏览器
driver=webdriver.Chrome()
# 打开网址
driver.get("https://www.douban.com/")
time.sleep(1)
# 定位iframe
frame=driver.find_element(By.XPATH, '//div[@class="wrapper"]//iframe')
# 切入进去
driver.switch_to.frame(frame)
# 定位
li=driver.find_element(By.CLASS_NAME,"account-tab-account")
# 点击
li.click()
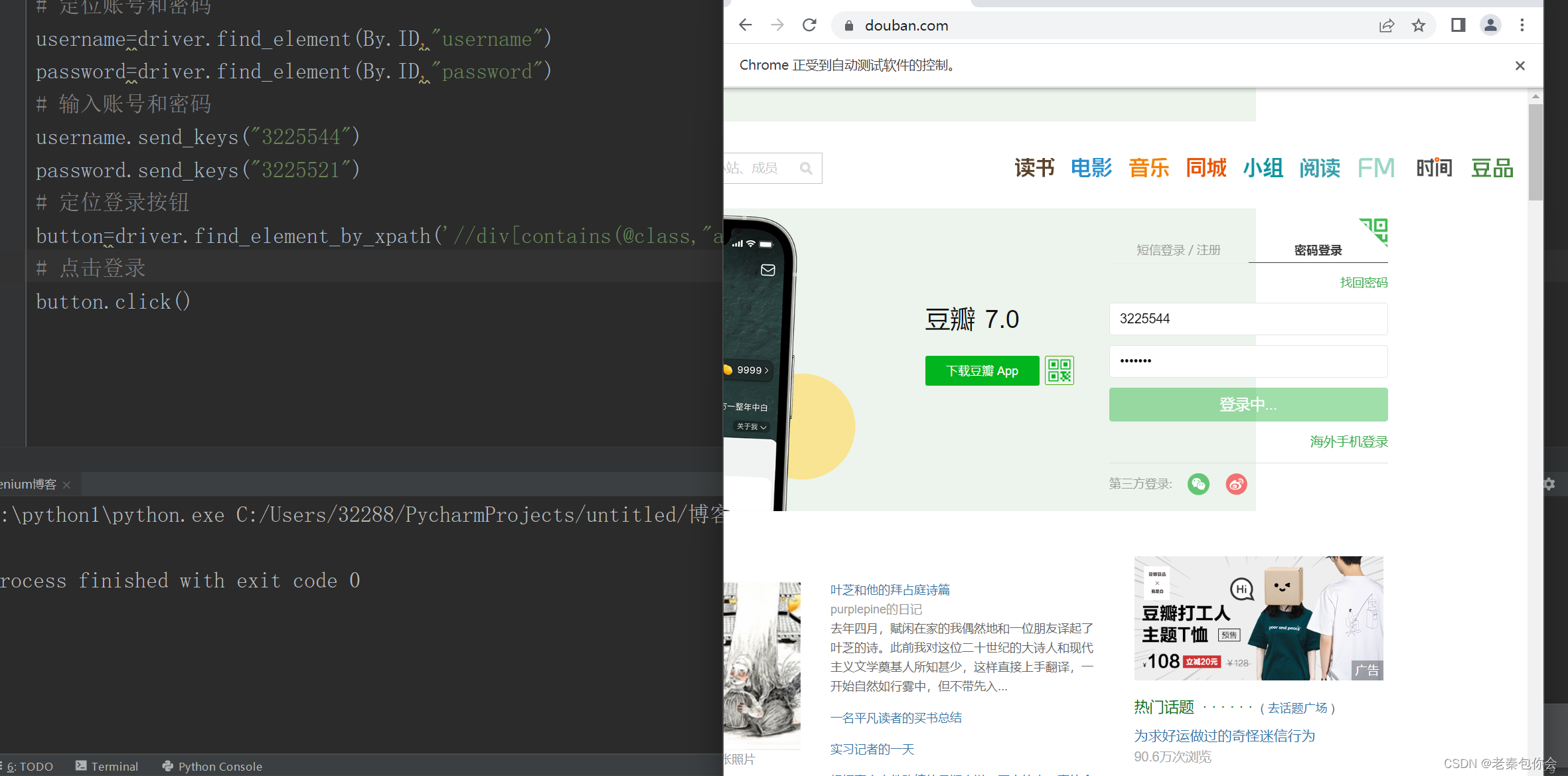
# 定位账号和密码
username=driver.find_element(By.ID,"username")
password=driver.find_element(By.ID,"password")
# 输入账号和密码
username.send_keys("3225544")
password.send_keys("3225521")
# 定位登录按钮
button=driver.find_element_by_xpath('//div[contains(@class,"account-form-field-submit ")]//a')
# 点击登录
button.click()
# 定位iframe
frame=driver.find_element(By.XPATH, '//div[@class="wrapper"]//iframe')
# 切入进去
driver.switch_to.frame(frame)
主要是登入界面是嵌入的需要切换进去才能正常操作或者操作不了
行为链
有时候在⻚⾯中的操作可能要有很多步,那么这时候可以使⽤⿏标⾏为链类
ActionChains来完成。⽐如现在要将⿏标移动到某个元素上并执⾏点击事件
代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
from selenium.webdriver.common.action_chains import ActionChains
# 创建一个浏览器
driver=webdriver.Chrome()
# 打开网址
driver.get("https://www.douban.com/")
time.sleep(1)
action=ActionChains(driver)
# 定位iframe
frame=driver.find_element(By.XPATH, '//div[@class="wrapper"]//iframe')
# 切入进去
driver.switch_to.frame(frame)
# 定位
li=driver.find_element(By.CLASS_NAME,"account-tab-account")
# 点击
li.click()
# action.click(li)
time.sleep(1)
# 定位账号和密码
username=driver.find_element(By.ID,"username")
password=driver.find_element(By.ID,"password")
# 点击并输入
action.send_keys_to_element(username,"3225544")
action.send_keys_to_element(password,"3225521")
# 定位登录按钮
button=driver.find_element_by_xpath('//div[contains(@class,"account-form-field-submit ")]//a')
action.click(button)
# 提交行为
action.perform()
结果:

行为链比较特殊,先提交行为然后再执行,前面的是同时进行
click_and_hold(element):点击但不松开⿏标。
context_click(element):右键点击。
double_click(element):双击。
release() 松开鼠标
如果小可爱们想练习可以利用这个来练习操作:https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable
Cookie操作
获取所有cookie
cookies = driver.get_cookies()
删除某个cookie
driver.delete_cookie('key')
删除所有cookie
driver.delete_all_cookies()
如果你想利用获取到的cookie进行登录可以这样操作:
获取cookie到的保存到文件里面,
介绍两种方法保存cookie和取cookie
导入 import json
a=json.dumps(driver.get_cookies()) :把cookie转换为字符串进行写入文件
json.load(a): 把字符串转换回原来类型
写入cookie代码如下:
文件已经保存了cookie
写入cookie之前我们还要清除原来的cookie,然后自己添加cookie
driver.delete_all_cookies()
with open("cookie.txt","r",encoding="utf-8")as f:
# print(f.read())
cookie_list=json.loads(f.read())
for cookie in cookie_list:
if type(cookie.get("expiry"))==float:
cookie["expiry"]=int(cookie["expiry"])
# 添加cookie
driver.add_cookie(cookie)
# 刷新页面
driver.refresh()
页面等待
现在的⽹⻚越来越多采⽤了 Ajax 技术,这样程序便不能确定何时某个元素完全
加载出来了。如果实际⻚⾯等待时间过⻓导致某个dom元素还没出来,但是你
的代码直接使⽤了这个WebElement,那么就会抛出NullPointer的异常。为了
解决这个问题。所以 Selenium 提供了两种等待⽅式:⼀种是隐式等待、⼀种
是显式等待
隐式等待:调⽤driver.implicitly_wait。那么在获取不可⽤的元素之前,会
先等待10秒中的时间。(针对所有的selenium语句)
等待10秒
driver.implicitly_wait(10)
显示等待;
显示等待:显示等待是表明某个条件成⽴后才执⾏获取元素的操作。也可以
在等待的时候指定⼀个最⼤的时间,如果超过这个时间那么就抛出⼀个异
常。(针对某一个)
导入
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
写法:
WebDriverWait(driver,5).until(EC.presence_of_element_located((By.ID,"kw")))
**打开多窗⼝和切换⻚⾯ **
有时候窗⼝中有很多⼦tab⻚⾯。这时候肯定是需要进⾏切换的。selenium提供
了⼀个叫做switch_to_window来进⾏切换,最高版本就用switch_to.window(句柄)
代码如下:
river=webdriver.Chrome()
driver.get("https://www.baidu.com/?tn=02003390_19_hao_pg")
#js 打开第二页面
driver.execute_script("window,open('https://www.douban.com/')")
结果:
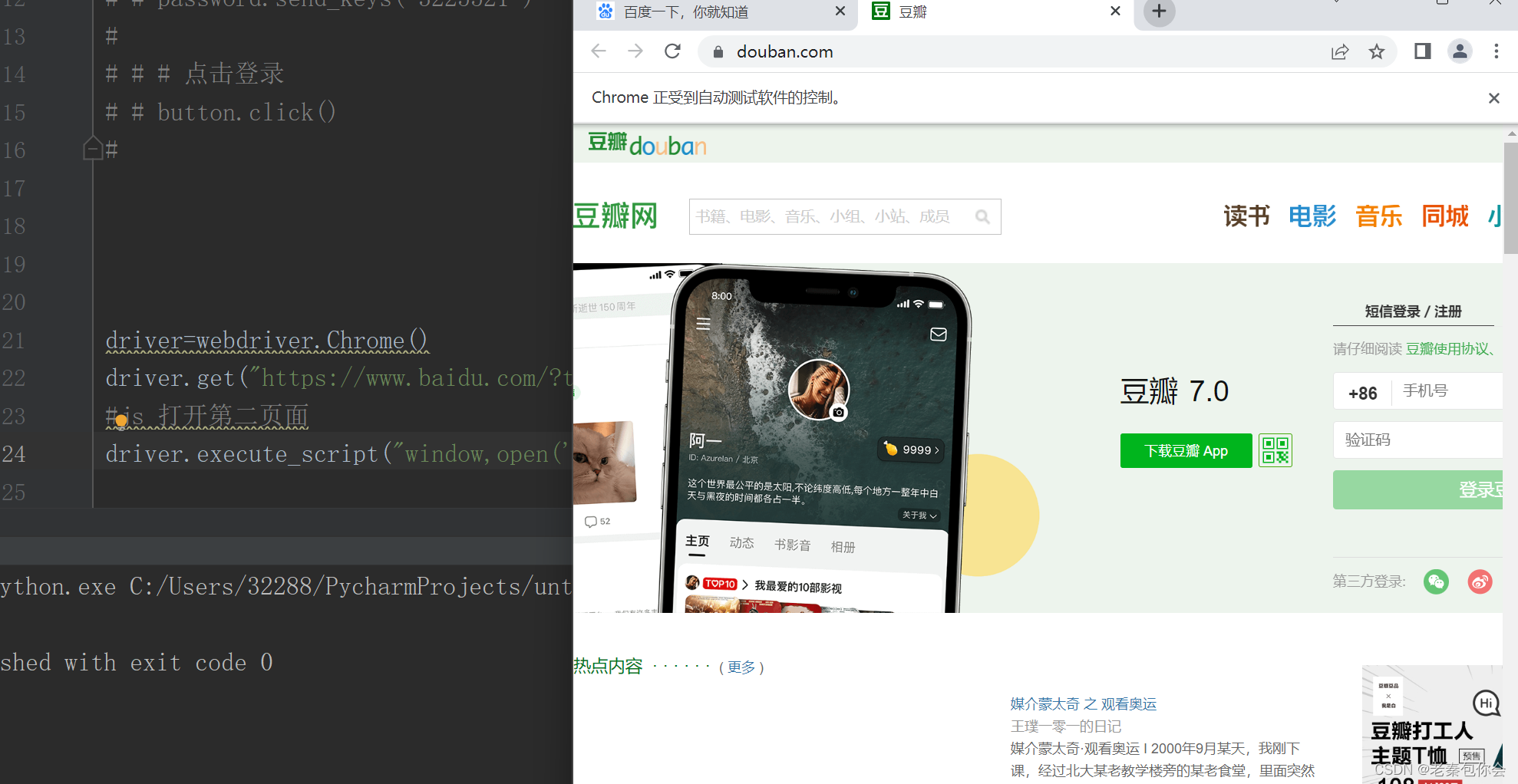
如果想操作第二页面所先要获取句柄:
driver=webdriver.Chrome()
driver.get("https://www.baidu.com/?tn=02003390_19_hao_pg")
#js 打开第二页面
driver.execute_script("window,open('https://www.douban.com/')")
#获取句柄
a=driver.window_handles
#切换页面
driver.switch_to.window(a[1])

selenium被识别解决方案
# 执行js语句(规避selenium被检测)
js="Object.defineProperty(navigator, 'webdriver', {get: () => undefined})"
driver.execute_script(js)
因为我们在自动登录有些网页会自动检测是不是selenium 造成了登入不成,所以我们要逃过检查就要过检,这个只是简单的,有一些网址的反爬做得很厉害,利用这个就不够用了
总结:爬的过程要有个度,过度爬取会造成网站崩塌,这些是我的建议,怎么来还得看你们的啦!!!
版权归原作者 老秦包你会 所有, 如有侵权,请联系我们删除。