
🔥《Kafka运维管控平台》🔥
✏️更强大的管控能力✏️ 🎾更高效的问题定位能力🎾 🌅更便捷的集群运维能力🌅 🎼更专业的资源治理🎼 🌞更友好的运维生态🌞
文章目录
大家好,我是石臻臻
上周我们分别讲解了
《Kafka分区副本同步限流机制三部曲》中的第一篇 《源码篇》
《图解Kafka中的数据采集和统计机制 》
之所以中间插入了 《图解Kafka中的数据采集和统计机制 》 是因为理解了 数据的采集和统计机制有利于我们对 限流的理解。
今天我们来讲解一下 《Kafka分区副本同步限流机制三部曲》中的第二篇 《原理篇》
我们这里讲的限流机制, 只是副本之间的同步限流机制,并不包含 生产者 、消费组 等等其他的限流。
那么讲到副本同步, 我们都知道正常情况下,我们是不会给副本的同步加上限流值的,因为这样子很可能会导致副本跟不上ISR, 那么什么情况下我们需要加上这个限流值呢?
分区副本重分配的场景下,我们可能怕大批量的数据进行迁移会占用过得的资源,导致kafka集群压力增大,影响正常使用, 所以一般情况下我们可能会选择在低峰期进行操作,也会对整个操作做一个限流处理
具体的分区副本重分配的运维操作教程可以看文章 【kafka运维】kafka-reassign-partitions.sh分区副本重分配、数据迁移、副本扩缩容 (附教学视频)
设置限流的时候有两个参数选项,可以同时配置
--replica-alter-log-dirs-throttle
: broker内部副本跨路径迁移数据流量限制功能,限制数据拷贝从一个目录到另外一个目录带宽上限 单位 bytes/sec 。
--throttle:
迁移过程Broker之间传输的速率,单位 bytes/sec
如果你之前看过我写的 【kafka运维】kafka-reassign-partitions.sh分区副本重分配、数据迁移、副本扩缩容 (附教学视频) 肯定对这个两个参数非常熟悉。
那么你会不会发出这样的疑问
--throttle:迁移过程Broker之间传输的速率 。 这个Broker之间是谁和谁之间?- Broker之间传输的速率 怎么算?是Broker整体所有分区副本的传输速率,还是指定几个分区副本的传输速率?
- 这个传输速率是什么?是Broker数据流出的速率,还是数据流入的速率?还是网卡的速率?
--replica-alter-log-dirs-throttle这个又是怎么限制住 Broker 不同目录直接的流量的?- 如何正确的 设置这些限流值呢?有哪些参考标准?
- 我可以手动设置限流吗?
假如你有这些疑问, 并稍作思考🤔之后, 跟着我下面的讲解来重新梳理一下吧!
不同Broker之间副本同步限流
注意: 这里的副本限流前提是不在ISR中, 如果已经在ISR中了不管如何都不会被限流。
对于这个问题,我写一个例子,就很容易明白了。
当前我有3个Broker,有一个Topic
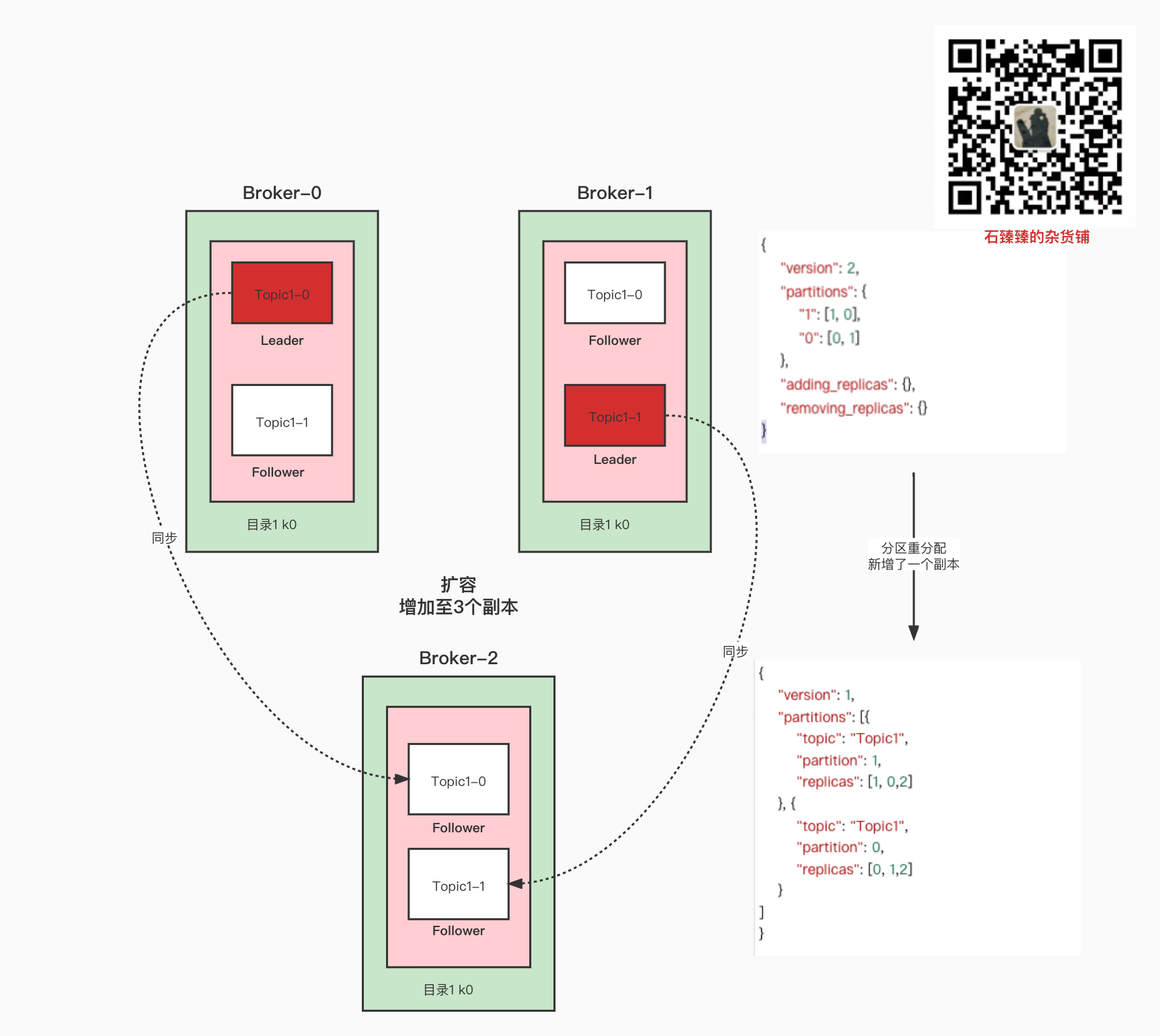
在执行以下脚本进行分区重分配之后:
sh bin/kafka-reassign-partitions.sh --zookeeper xxxx:2181/src1 --reassignment-json-file config/reassignment-json-file.json --execute --bootstrap-server xxxxxx:9090 --throttle 1048576
可以看到zk的配置中新增了以下几个属性:
Broker节点配置
/config/brokers/0
/config/brokers/1
/config/brokers/2
这三个Broker都新增了属性
{"version":1,"config":{"leader.replication.throttled.rate":"1048576","follower.replication.throttled.rate":"1048576"}}
leader.replication.throttled.rate:
需要对Leader端 Fetcher返回的数据做限流,这里的配置就是限流的阈值
follower.replication.throttled.rate:
需要对Follower端去Leader 副本 Fetcher数据做限流,这里的配置就是限流的阈值
可以看到, 里面配置的值都是我刚刚通过
--throttle 1048576
设置的值 也就是说 1M/s.
这里配置了这两个属性的意思是, 3个Broker 既要做Leader端的限流 又要做 Follower 端的限流。
并且限流的阈值都是 1M/s.
当然, 这里配置了限流阈值就完了吗?
是需要所有的数据流入流出都要限流? 还是只是部分分区限流?
Topic节点配置
/config/topics/Topic1
新增了以下几个配置
{"version":1,"config":{"leader.replication.throttled.replicas":"1:1,1:0,0:0,0:1","follower.replication.throttled.replicas":"1:2,0:2"}}
**
leader.replication.throttled.replicas:
** Leader端的限流副本, 他的格式是
分区号:BrokerID
上面配置的意思如下
1:1
: Topic1-1分区在Broker-1 上需要做Leader限流
1:0
: Topic1-1分区在Broker-0 上需要做Leader限流
0:0
: Topic1-0分区在Broker-0 上需要做Leader限流
0:1
: Topic1-0分区在Broker-1 上需要做Leader限流
从这里可以看到, 基本上原始分区副本都需要配置Leader端进行限流,并且是所有涉及到的Broker
为什么呢?
因为在副本分配过程中,以前的所有副本都有可能成为Leader
比如之前 Broker-0里面的Topic1-0 是Leader副本,如果Broker-0不小心宕机了,那么Leader就变成了Broker-1中的副本了。
所以需要把之前的所有副本都要设置Leader限流。
**
follower.replication.throttled.replicas
**:Follower端的限流副本,他的格式是
分区号:BrokerID
上面配置的意思如下
1:2
: Topic1-1分区在Broker-2 上需要做Follower限流
0:2
: Topic1-0分区在Broker-2 上需要做Follower限流
这里更简单一点, 相当于是 新增的副本 和对应的Broker都做 Follower限流。
一句话:重分配后的新增的副本 均设置成 Follower副本限流, 重分配前的所有副本 均设置成Leader限流
看看整体Leader限流 和Follower限流图
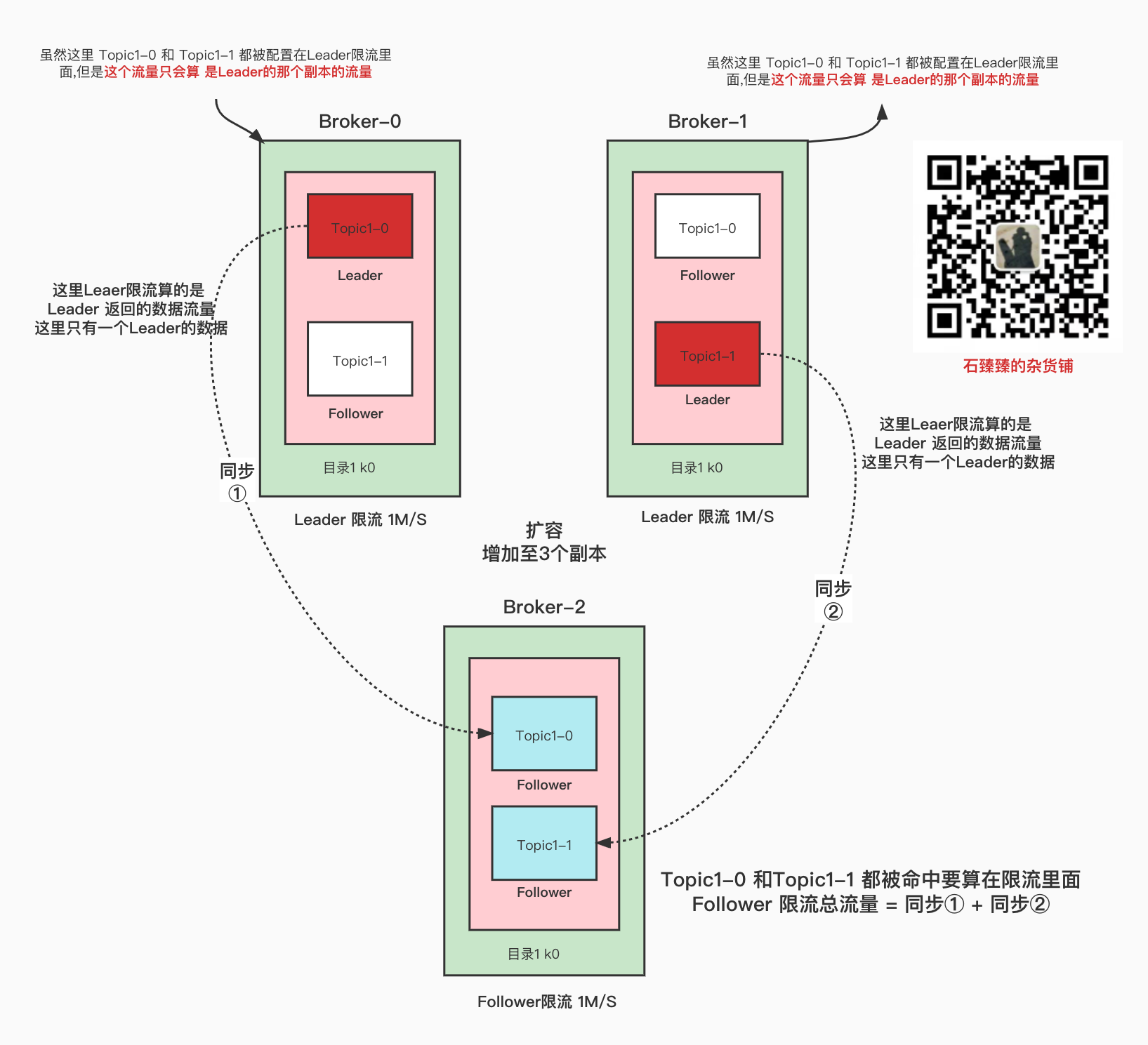
看完这个图,给你一个问题思考一下.
如果这个上面的每个分区副本大小都是 100M, 那么上面的配置(限流1M/S) 最终执行完成同步, 需要多长的时间呢?
站在Leader的角度看限流
Broker-0中只有
Topic1-0
一个Leader需要进行同步(数据流出),并且只有一个Broker-2上的副本需要同步(同步①)
那么完成同步的时间 = 100M / Leader端的限流 1M/S = 100秒。意思是最少需要100秒
同理
Broker-1 也是最少需要100秒。
站在Follower的角度看限流
Broker-2 因为有2个副本同时在同步, 那么总共需要Fetche的数据量是 100*2 = 200M
然后又因为Follower限流是 1M/S
所以完成同步的时间最少需要 200/1M/S = 200S.
也就是说 还没有等到Broker-0 和 Broker-1 达到它的限流值之前, Broker-2 就已经被限流了
所以最终的时间是 200秒。
所以跟你想到的答案一致吗?
各种情况的限流情况
Leader 限流 Follower不限流 结论
- Leader端的限流只会计算需要被限流的分区流量值。
- 如果多个副本向Leader端Fetch数据,那么都会被算进限流阈值, 基本上多一个副本就多一倍的时间。
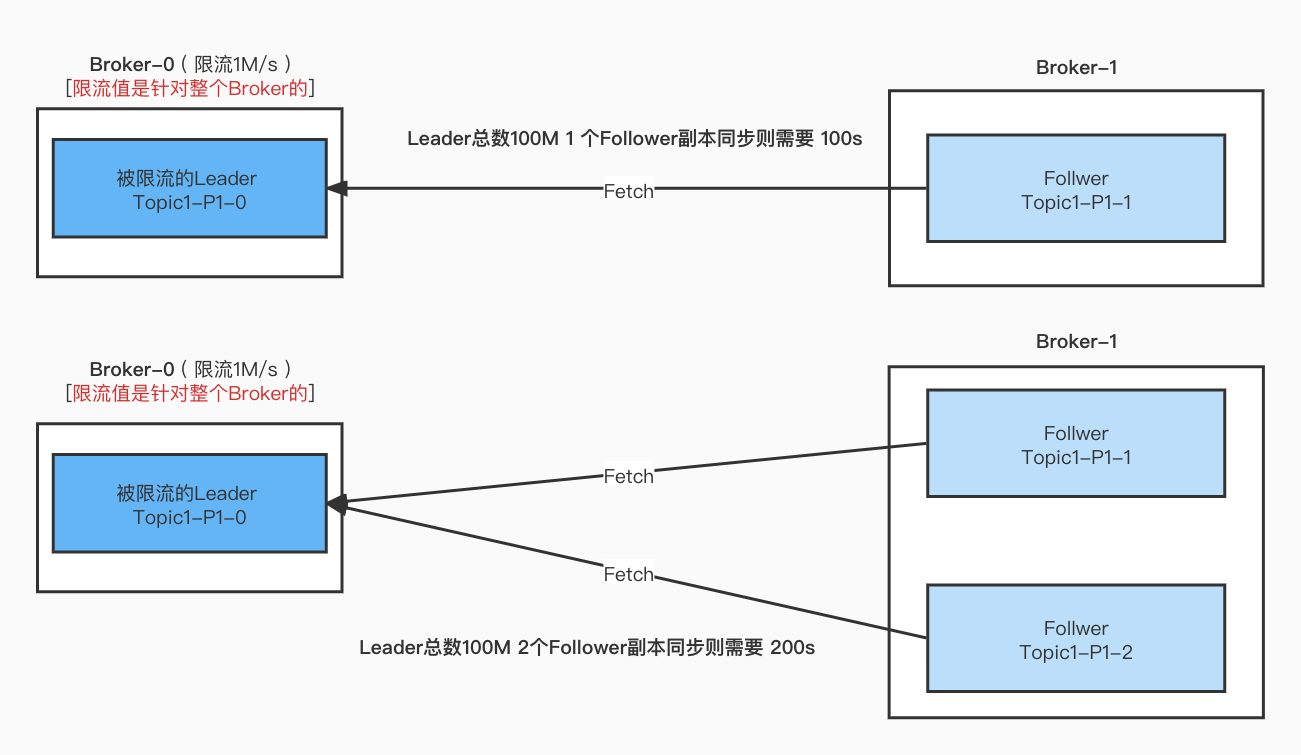
如果有多个Leader分区都限流呢?
按照最终有多少个副本在Fetch数据.
Leader不限流 Follower限流
对应的配置有
follower.replication.throttled.replicas:Follower分区副本的限流配置
follower.replication.throttled.rateFollower分区副本限流阈值 b/s
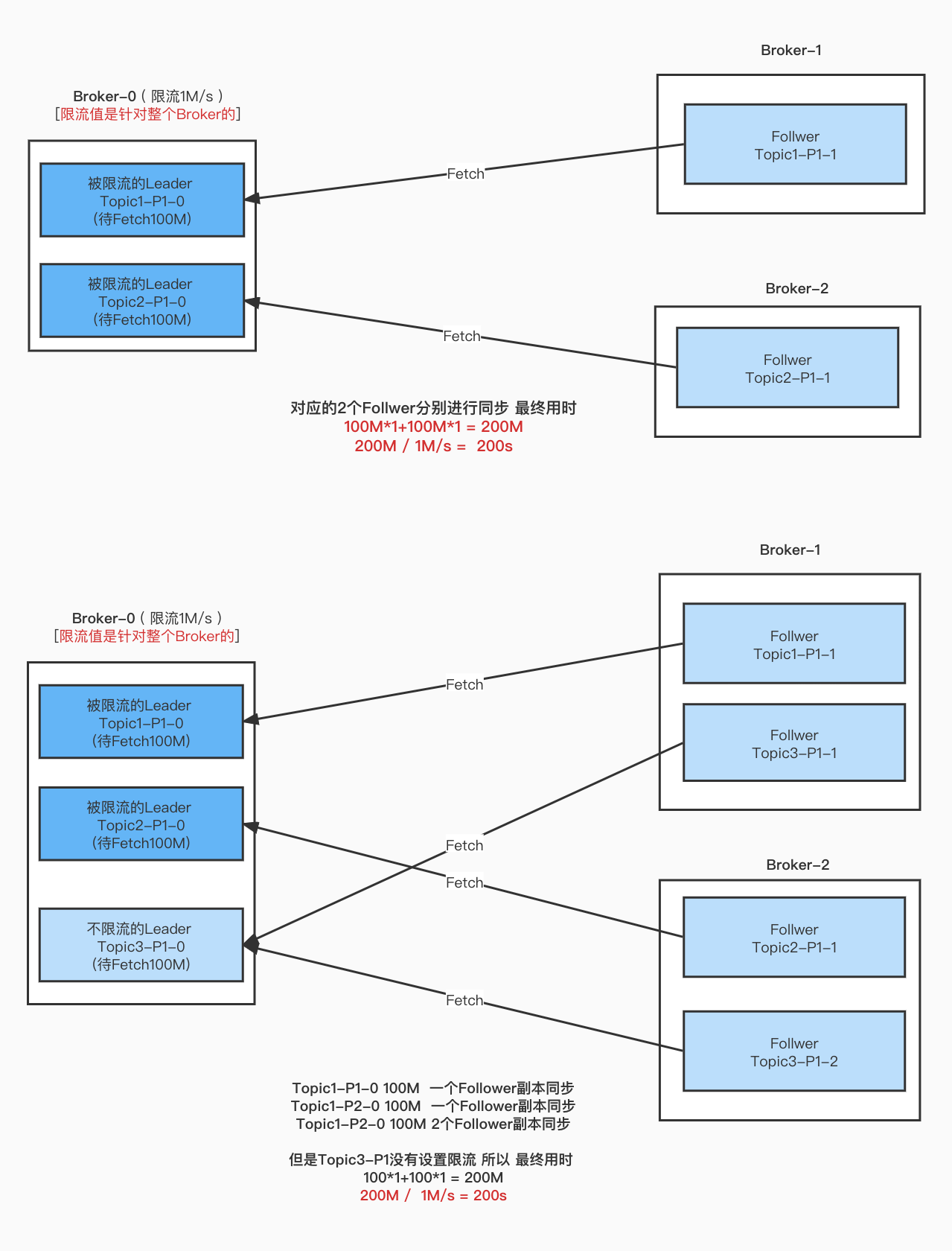
Topic1 单分区 2副本 和 Topic1 2分区 2 副本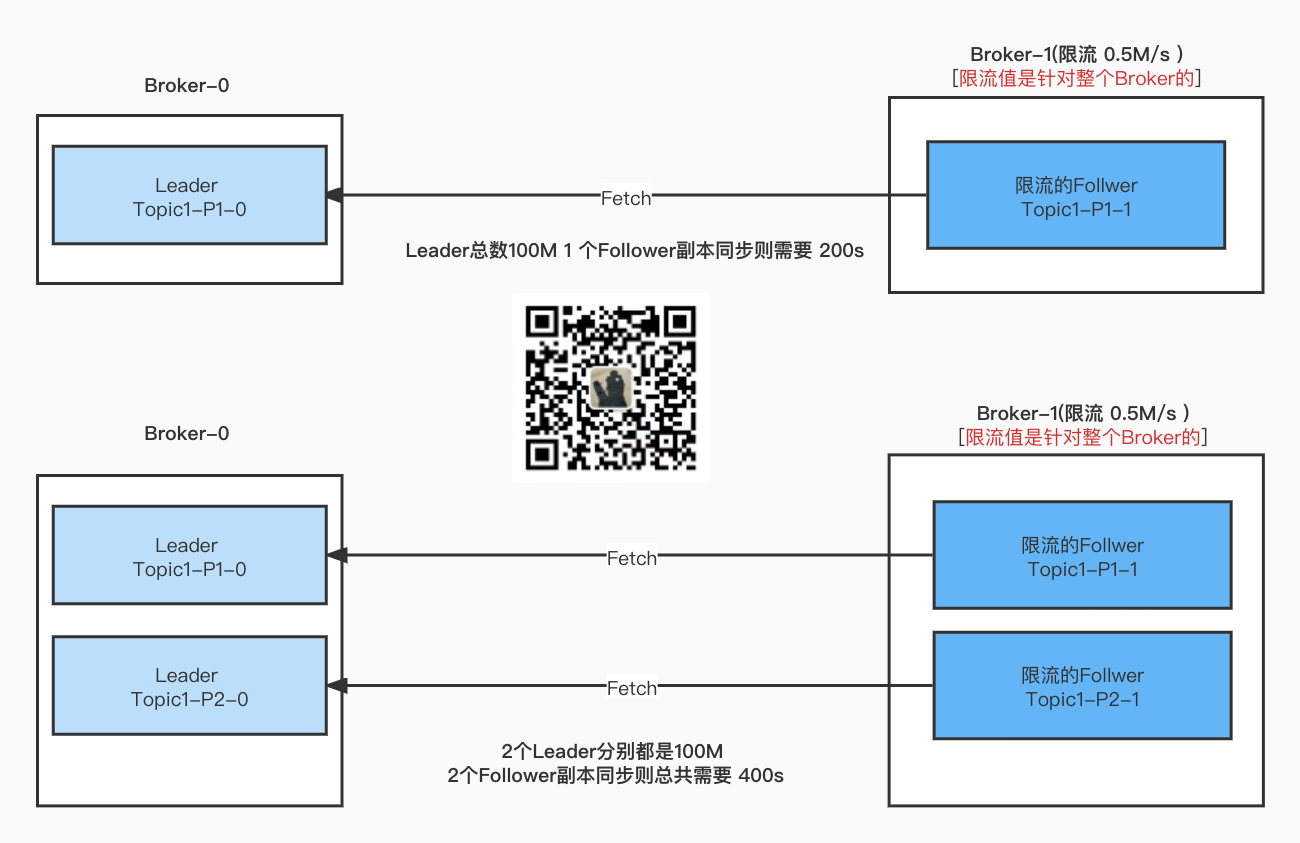
Topic1 多分区 多 副本
多个分区 多个副本 在不同的Broker上, 不同的Broker的流量只会算在当台Broker。
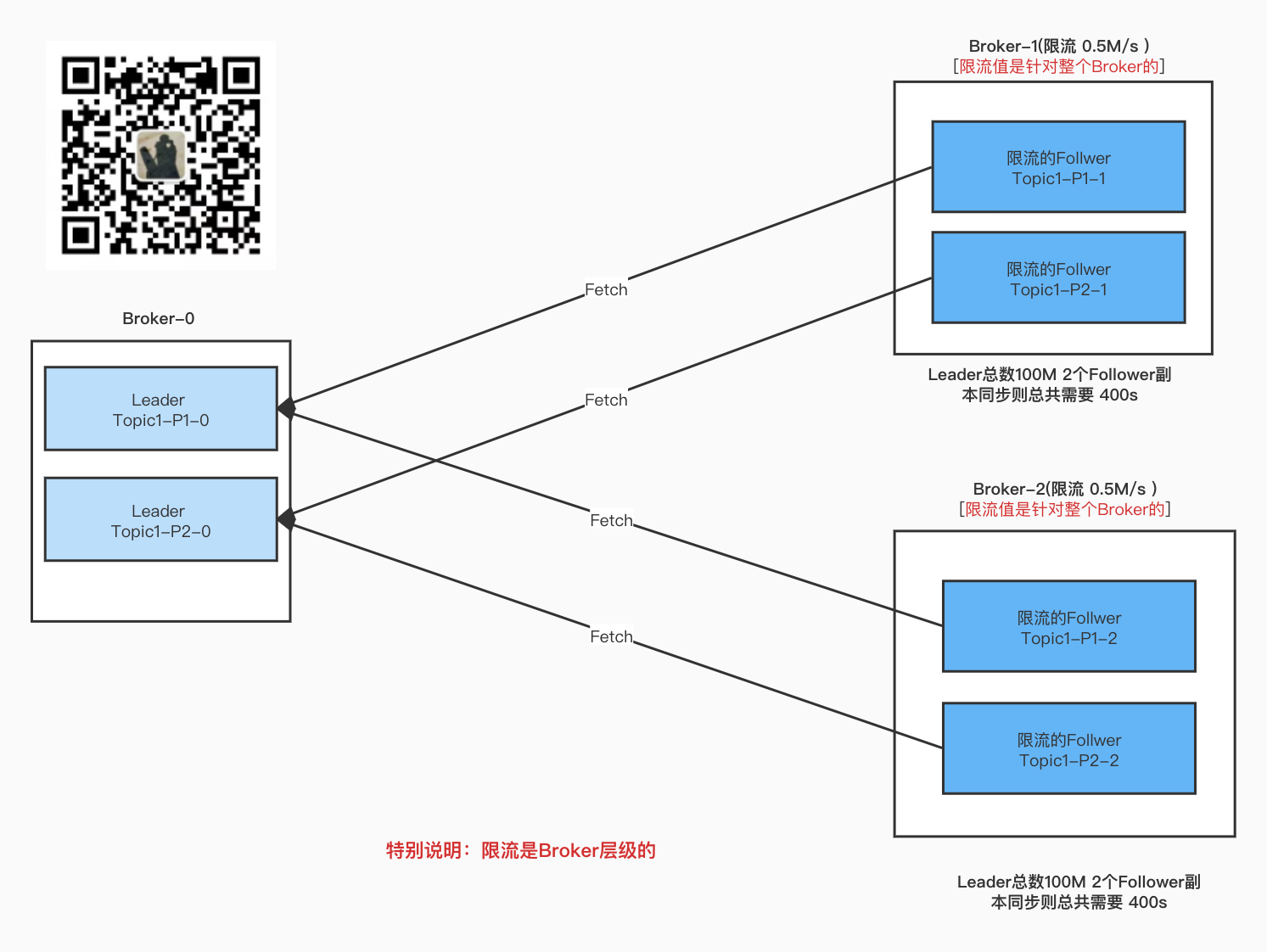
上图中的2个Leader 都是100M。
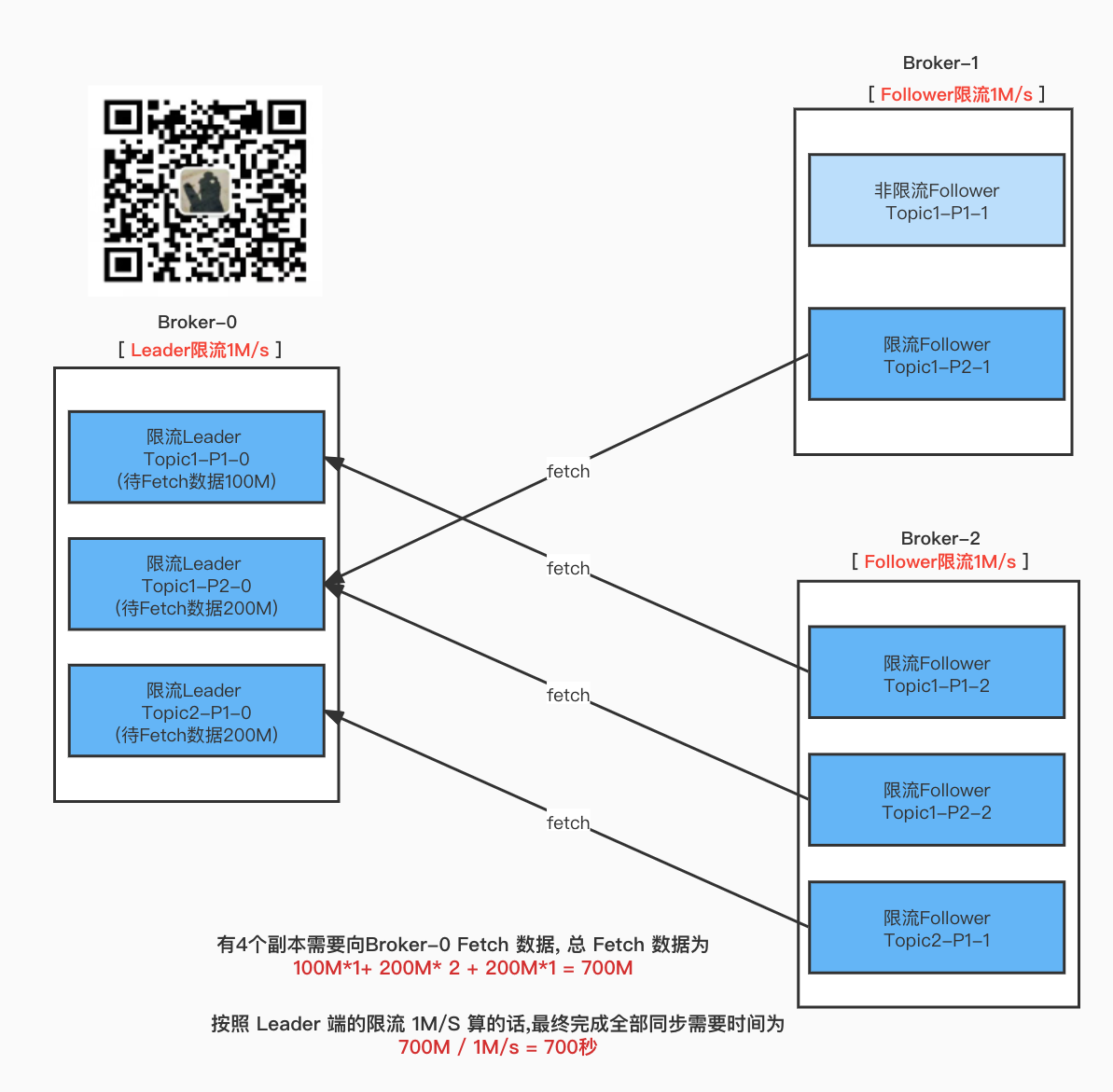
最终决定完成重分配任务关键点是什么?
那就是 Leader端的限流 和 Follower端限流 谁先达到阈值
Leader端先达到阈值
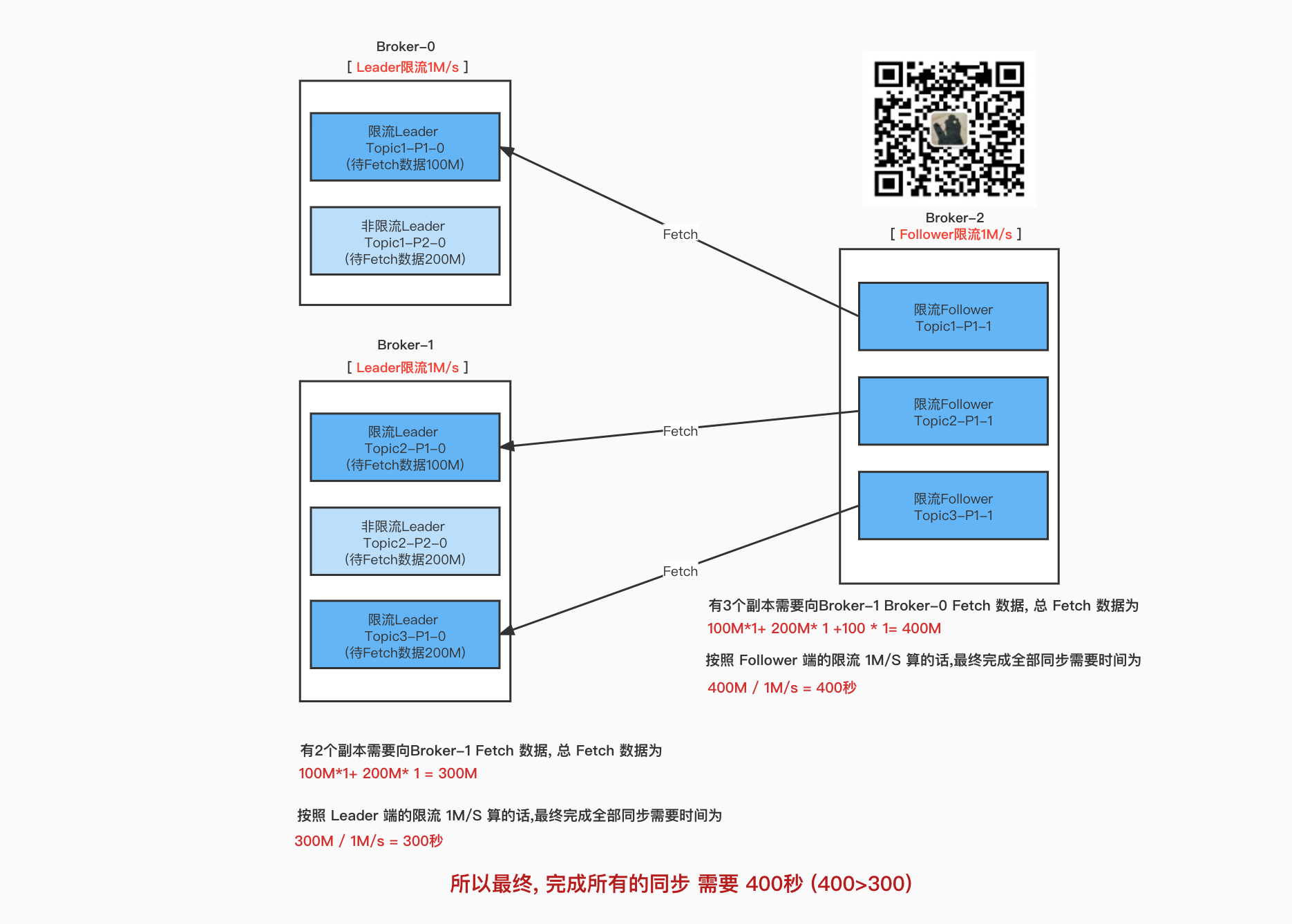
Follower 先达到阈值
同Broker跨目录同步限流
这个指的是 一个Broker可能有多个目录, 我们可能会针对不同目录做一些数据迁移。当然,这个过程也会限流
如何进行跨目录数据迁移,文章已经写好了,下周发,可以先关注我或者加我微信
szzdzhp001
获取最新推文,在这一篇就不详细展开了。
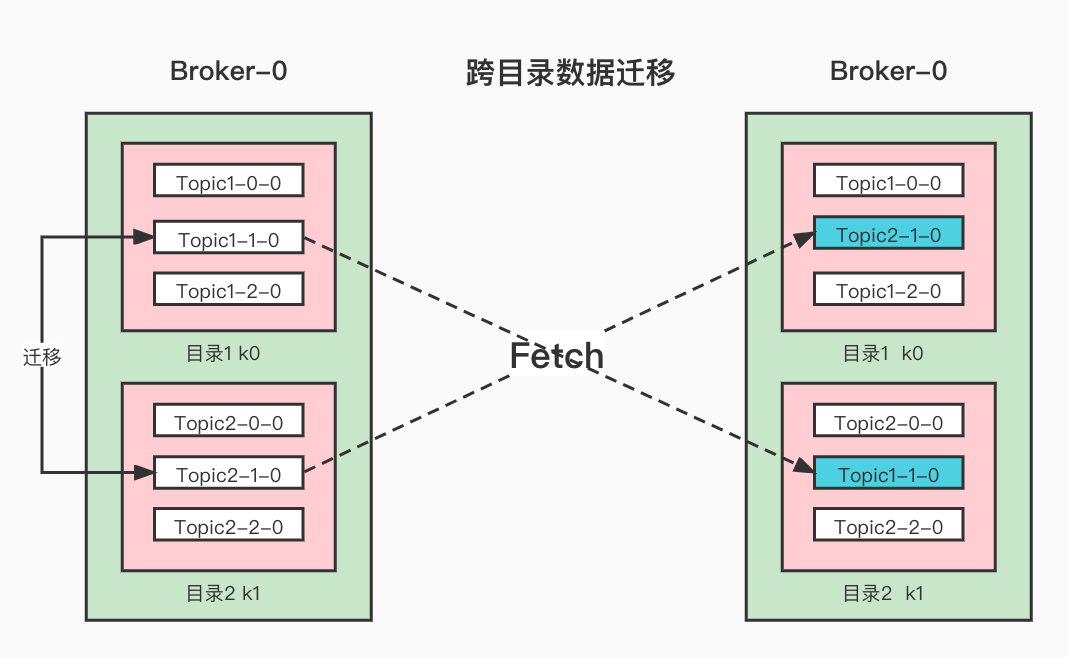
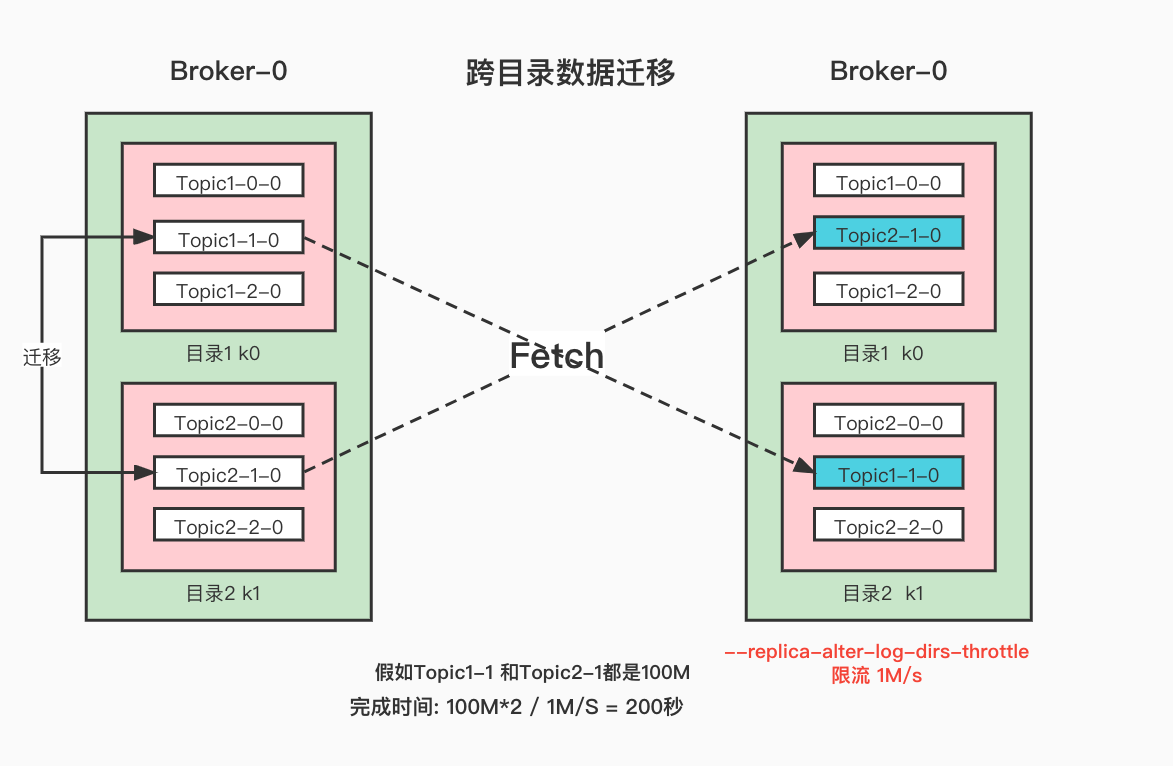
这个就是跨目录数据迁移, 在执行这个操作的时候 ,设置限流 1M/s
--replica-alter-log-dirs-throttle 1048576
那么会在Broker配置节点新增如下配置
/config/broker/0
{"version":1,"config":{"replica.alter.log.dirs.io.max.bytes.per.second":"1048576"}}
不用管,其他的分区的配置
leader.replication.throttled.replicas
和
follower.replication.throttled.replicas
什么的,不需要, 配置了也不会用,因为这里的限流会把这台里面的所有跨目录同步的数据流量给统计起来并进行限流。
如果上面的两个分区都是100M 那么完成迁移的最小时间是 100M*2 / 1M/s = 200秒。
留一个彩蛋(挖坑)
你知道跨目录迁移的时候,数据是从哪里获取的吗?是从本地呢?还是从Leader分区Fetch呢?
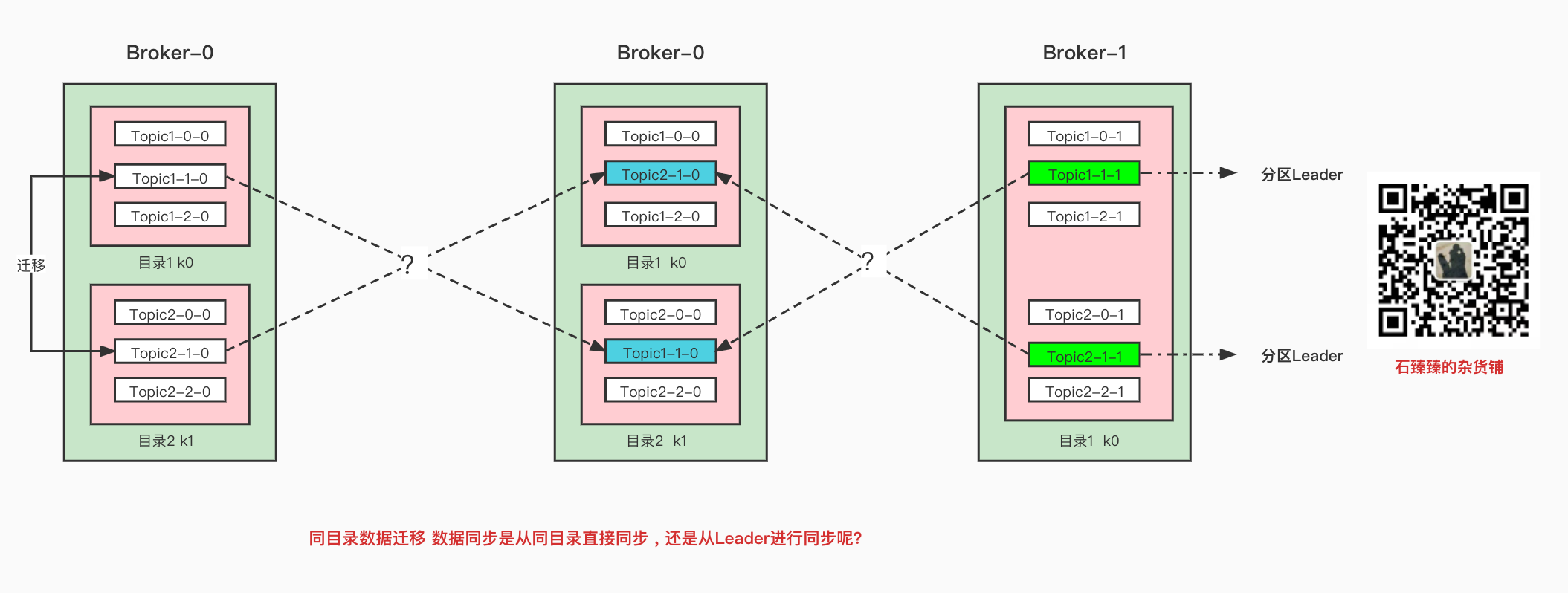
想知道答案, 可以关注石臻臻, 或者加微信
szzdzhp001
获取最新推送
我们下次专门来分析一下 跨目录迁移的运维操作和原理解析
如何手动设置限流
我们分析了分区副本同步过程中的所有情况, 也知道了里面的底层原理, 想要手动配置限流信息那岂不是随便拿捏。
虽然我这里在写如何设置副本同步限流的教程,但是我仍然不推荐我们主动来设置它, 因为很有可能会导致你的副本同步变慢, ISR 跟不上。
我们之前写过一篇关于kafka的 动态配置运维操作 和 动态配置的原理解析
如下所示, 可以访问我的个人网站 szzdzhp.com/kafka (石臻臻的杂货铺首字母) 查看kafka运维大全
这里的配置就是动态配置, 实时生效的动态配置。
设置相关配置属性
设置Broker-0的Leader和Follower限流速率
sh bin/kafka-configs.sh --bootstrap-server xxxxx:9092 --alter --entity-type brokers --entity-name 0 --add-config leader.replication.throttled.rate=1048576,follower.replication.throttled.rate=1048576
效果如下
{"version":1,"config":{"leader.replication.throttled.rate":"1048576","follower.replication.throttled.rate":"1048576"}}
当然如果设置
replica-alter-log-dirs-throttle
话 更改上面的配置就行了。
设置Topic1的某些分区需要进行限流
我们设置
Topic1-1 需要再Broker-0 上进行Leader限流
Topic1-2 需要再Broker-1 上进行Follower限流
sh bin/kafka-configs.sh --bootstrap-server xxxxx:9092 --alter --entity-type topic --entity-name Topic1 --add-config leader.replication.throttled.replicas=1:0,follower.replication.throttled.replicas=2:1
最终效果
/config/topics/Topic1
新增了以下几个配置
{"version":1,"config":{"leader.replication.throttled.replicas":"1:0","follower.replication.throttled.replicas":"2:1"}}
设置Topic1的所有分区在所有Broker上都需要进行限流
只需要把值设置为
*
就行了
sh bin/kafka-configs.sh --bootstrap-server xxxxx:9092 --alter --entity-type brokers --entity-name 0 --add-config leader.replication.throttled.replicas=*,follower.replication.throttled.replicas=*
最终效果
/config/topics/Topic1
新增了以下几个配置
{"version":1,"config":{"leader.replication.throttled.replicas":"*","follower.replication.throttled.replicas":"*"}}
再留一个彩蛋(挖坑)
**如果你执行分区副本重分配忘记执行
--verify
没有删除限流配置, 你应该知道如何做的吧?**
如何设置合理的限流值呢?
这是一个值得思考的问题, 我们在设置限流值的时候往往可能是根据以往的时候 Broker的网卡流量
还有预估这个Broker可能出现能够承载的最大流量, 然后设置一个合理的范围值, 但是这个合理的限流值应该是什么呢?
还要考虑哪些因素呢?
一台Broker上的网卡流量 除了副本同步的流量 还有哪些流量呢?
这值得我们专门写一篇文章来分析!
我是石臻臻, 下次见!
👇🏻 扫描 下方 关注公众号 参与每周福利👇🏻
版权归原作者 石臻臻的杂货铺 所有, 如有侵权,请联系我们删除。