

前言
相信我们很多同学都经常会使用到 Node(节点)和 Element(节点)的概念,那么这两者到底有何区别,不知道有多少人能够答得上来这个问题?
今天,我在这里尝试着解释一下 Node 和 Element 的区别。
准备工作
在正式开始介绍 Node 和 Element 区别之前,我们先准备以下代码:
<divid="parent">
This is parent content.
<divid="child1">This is child1.</div><divid="child2">This is child2.</div></div>
下面的绝大多数现象和结论都将借助这段代码的结构来进行展示说明。
getElementById 获取到的到底是什么?
document.getElementById()
方法应该是我们最常使用的接口之一,那么它的返回值到底是 Node 还是 Element?
我们使用以下代码验证一下:
let parentEle = document.getElementById('parent');
parentEle instanceofNode// true
parentEle instanceofElement// true
parentEle instanceofHTMLElement// true
可以看到,
document.getElementById()
获取到的结果既是 Node 也是 Element。
Node、ELement 和 HTMLElement 有什么关系?
上面的代码中为什么要用 Node、Element 和 HTMLElement 来做类型判断?它们之间到底有何关系?
看代码:
let parentEle = document.getElementById('parent');
parentEle.__proto__
// HTMLDivElement {…}
parentEle.__proto__.__proto__
// HTMLElement {…}
parentEle.__proto__.__proto__.__proto__
// Element {…}
parentEle.__proto__.__proto__.__proto__.__proto__
// Node {…}
parentEle.__proto__.__proto__.__proto__.__proto__.__proto__
// EventTarget {…}
parentEle.__proto__.__proto__.__proto__.__proto__.__proto__.__proto__
// {constructor: ƒ, …}
parentEle.__proto__.__proto__.__proto__.__proto__.__proto__.__proto__.__proto__
// null
对于以上输出结果,我们可以用一张图更直观地表示它们之间的关系:
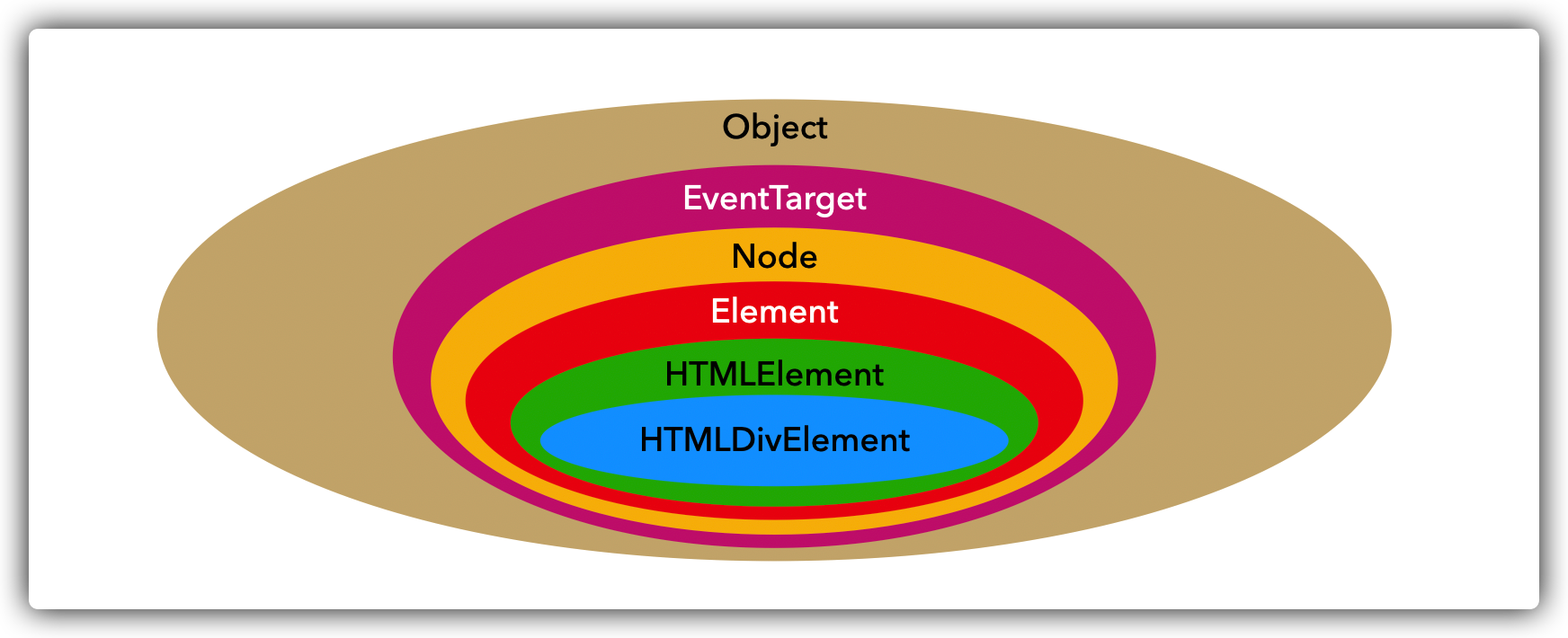
这也就解释了为什么 getElementById 获取到的既是 Node 也是 Element,因为 Element 继承于 Node。
从而也可以得出一个结论:Element 一定是 Node,但 Node 不一定是 Element。
所以:Element 可以使用 Node 的所有方法。
更直白地观察 Node 和 Element
虽然得出了上面的结论,也清楚了 Node 和 Element 的关系,但是那只是理论,我们还需要更直白的结果来强化对理论的认知。
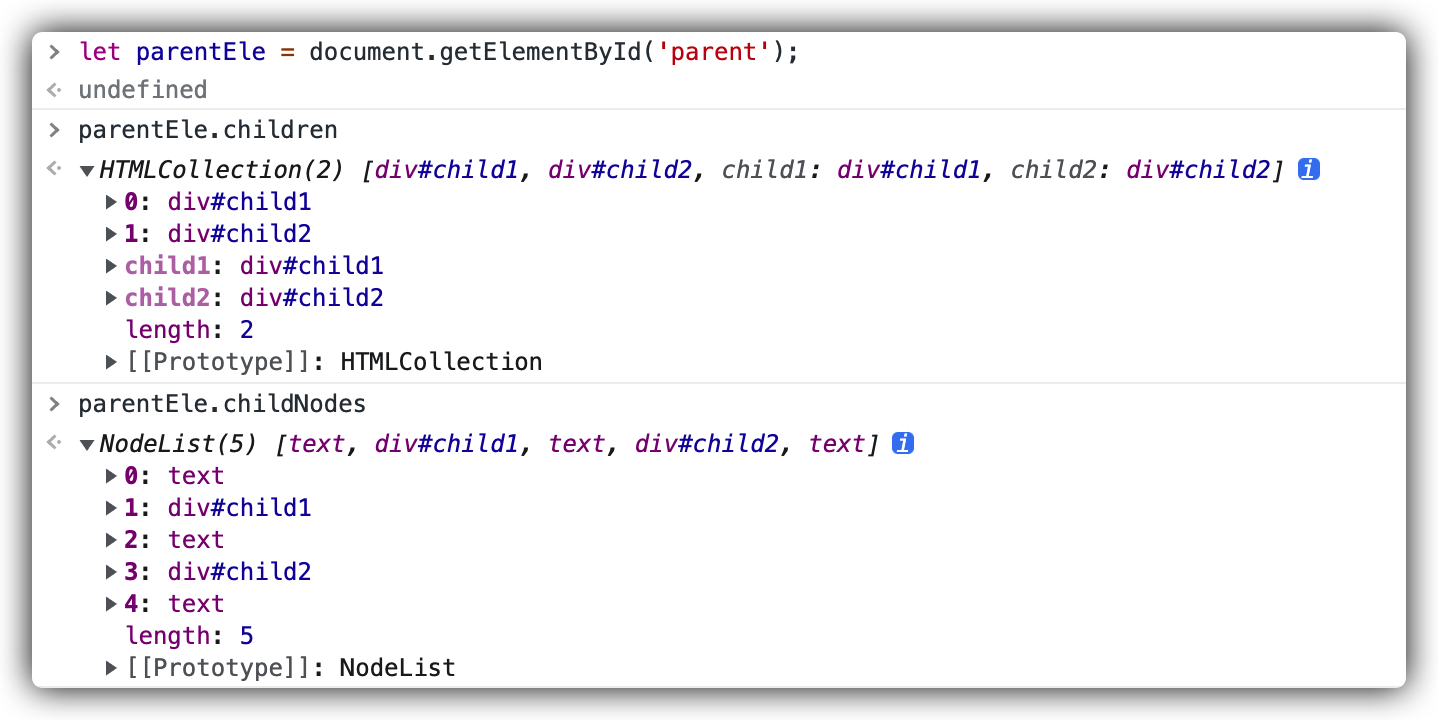
NodeList 内容:
- [0] “\n This is parent content.”
- [2] "\n "
- [4] "\n "
Element.children
获取到的只是父元素点下的所有 div,而
Element.childNodes
获取到的却是父节点下的所有节点(包含文本内容、元素)。
单个 Node 的界限在哪里?
从上面例子的 NodeList 内容中,换行符
\n
被当成一个单独的 Node,由此产生了一个新的疑惑:单个 Node 产生的界限在哪里?
我们将用到的 HTML 代码去掉格式化、合并为一行,修改如下:
<divid="parent">This is parent content.<divid="child1">This is child1.</div><divid="child2">This is child2.</div></div>
输出结果:
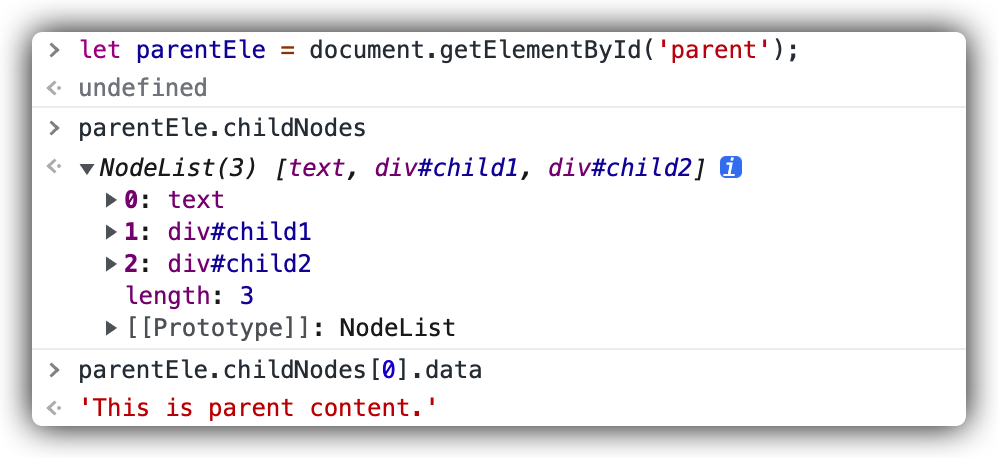
NodeList 中的没有换行符了,原来之前例子中 NodeList 里的换行符是因为原始代码中, HTML 标签与标签、内容与标签之间换行而产生的。
现在就可以回答单个 Node 的界限在哪里了,两个方面:
- 单个的 HTML 标签算是一个单独的 Node;
- 针对非 HTML标签(比如文本、空格等),从一个 HTML 标签的起始标签开始,到碰到的第一个 HTML 标签为止,如果中间有内容(文本、空格等),那这部分内容算是一个 Node。
再进一步
因为上面的例子中使用的都是块级元素,那如果使用行内元素会怎样?
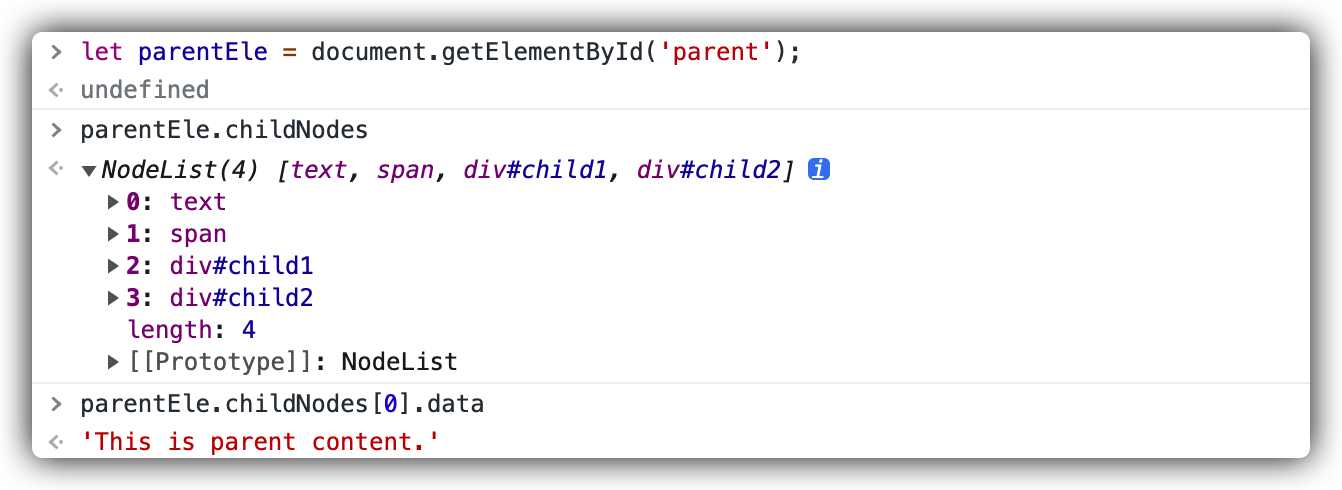
试验一:
<divid="parent">This is parent content.<span>This is a span.</span><divid="child1">This is child1.</div><divid="child2">This is child2.</div></div>
试验二:
<body><divid="parent">This is parent content\n.
<span>This is a span.</span><divid="child1">This is child1.</div><divid="child2">This is child2.</div></div></body>
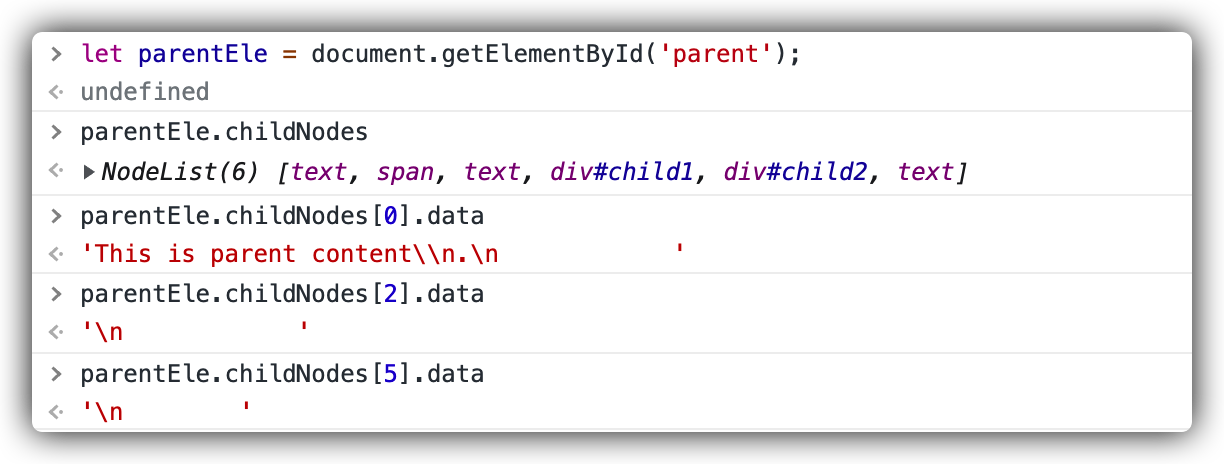
可以看到,即使使用了 span 元素,最后的结果也是符合上面得出的单个 Node 界限结论的。
扩展
从以上这么多例子中,我们可以再扩展总结一下:
- HTML 中的换行只能使用
</br>标签,\n会被直接解析成字符串; - HTML 代码中,标签与文本之间、标签和标签之间的换行都会被如实记录,反映到获取结果上就是
\n; - HTML 代码中,标签与标签、文本与文本、文本与标签之间的空格不被如实记录;
node.data内容中\n后面的空格字符数和实际代码中格式化空格配置数有关,其实也就是“空格会被如实记录”。
总结
以上通过几个例子说明了一下 Node 和 Element 之间的区别,主要结论总结起来就是:
document.getElementById()获取到的结果既是 Node 也是 Element。Element 一定是 Node,但 Node 不一定是 Element,也可能是文本、空格和换行符。
NodeList 里的换行符是因为原始代码中, HTML 标签与标签、内容与标签之间换行而产生的。
单个的 HTML 标签算是一个单独的 Node。
针对非 HTML标签(比如文本、空格等),从一个 HTML 标签的起始标签开始,到碰到的第一个 HTML 标签为止,如果中间由内容(文本、空格等),那这部分内容算是一个 Node。
~
本文完,感谢阅读!
~
学习有趣的知识,结识有趣的朋友,塑造有趣的灵魂!
大家好,我是〖编程三昧〗的作者 隐逸王,我的公众号是『编程三昧』,欢迎关注,希望大家多多指教!
版权归原作者 编程三昧 所有, 如有侵权,请联系我们删除。