
索引
0. 前言
同样是参考了学长的几篇博客,涛哥功德无量!在整合了各种信息之后,鄙人会尽量用更精炼、简单的说明来完成这个实验,当然不足一定是会有的,希望各位朋友可以斧正,同样也希望后来的朋友可以再次为这篇博客进行升级迭代!
博客是面向实验的,因此对完成实验无关的部分会优化掉。
带★的是可能遇到的问题可以看一下,以防后续操作出问题。
内容可能来自博主自己手搓、吸取同学的经验、网络上内容的整合等等,仅供参考,更多内容可以查看大三下指南专栏。
1. Docker
1.1 安装Docker
终端输入指令:
yum -y install docker
即可安装
通过输入指令:
docker version
查看版本(能看到就是安装成功了)
此时的
version
还略显青涩,只有
Client
短短的几行,只要启动了Docker它就会自动初始化了。
1.2 启动Docker
终端输入指令:
systemctl start docker.service
启动Docker服务(后续如果用不了Docker命令请先检查是否已经启动了服务)
再次输入指令:
docker version
查看版本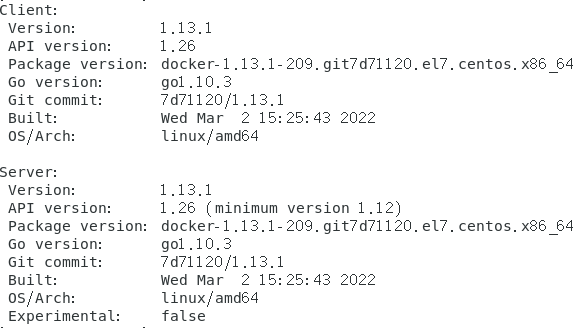
现在就同时拥有了Client和Server版本了,安装启动成功!
最后为了之后不用每次都手动开启,使用指令
systemctl enable docker
设置开机自启。
2. Dokcer部署Hadoop
因为Docker实际上是提供了一个虚拟环境(类似于虚拟机),因此我们其实相当于是在Master虚拟机上再创建三个小虚拟机,套娃……
所以下面的操作都是在Master一台虚拟机上进行的。
开始之前把Master虚拟机重新启动一次,另外两台虚拟机不需要开机。
2.1 设计Hadoop集群结构
主机:master(ip或主机名)
从机:slave1、slave2(ip或主机名)
2.2 拉取Hadoop镜像
确保Docker服务已经开启
终端输入指令:
docker images
查看镜像
很明显我的Docker非常的干净,啥也没有……
终端输入指令:
docker pull registry.cn-beijing.aliyuncs.com/jing-studio/centos7-hadoop
拉取Hadoop的镜像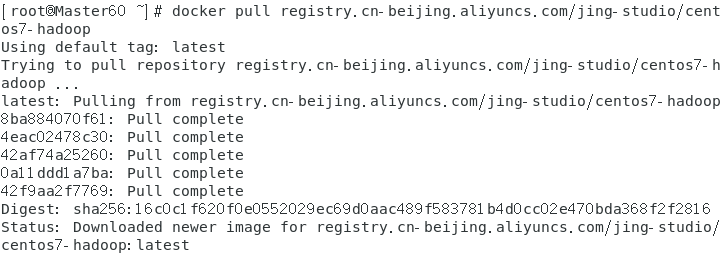
终端输入指令:
docker images
查看镜像,拉取成功了。
2.3 ★解决拉取镜像时 - no space left on device(磁盘不足)
我在拉取镜像时出现了以下的错误:
no space left on device

参考虚拟机扩容
2.4 创建Docker容器
**执行完命令之后可能会跳到登录界面,如果没进入GUI,可以
ctrl + alt + F2
切换,但是可能会没有鼠标。**
猜测是Docker的命令行抢占了GUI,而GUI被迫排到了原来CentOS命令行的位置(F1有鼠标,F2没有鼠标),如果有方法解决可以分享一下。
下面操作都是在Master一台虚拟机操作:
下面的
master60
、
slave1-60
、
slave2-60
只是容器的名字,可以起别的!
(1)终端输入指令:
docker run -d --name master60 -h master60 \
(注意修改主机名),在新出现的命令行依次输入:
-p 50070:50070 --privileged=true \registry.cn-beijing.aliyuncs.com/jing-studio/centos7-hadoop /usr/sbin/init
(2)终端输入指令:
docker run -d --name slave1-60 -h slave1-60 \
(注意修改主机名),在新出现的命令行依次输入:
--privileged=true \registry.cn-beijing.aliyuncs.com/jing-studio/centos7-hadoop /usr/sbin/init
(3)终端输入指令:
docker run -d --name slave2-60 -h slave2-60 \
(注意修改主机名),在新出现的命令行依次输入:
--privileged=true \registry.cn-beijing.aliyuncs.com/jing-studio/centos7-hadoop /usr/sbin/init
最后通过指令
docker ps
查看已经启动的容器
2.5 ★解决docker ps没有内容
docker ps
是查看已经启动的容器,如果没有找到可以通过
docker ps -a
查看容器的ID(最前面的),之后再通过
docker start 容器ID
打开。
2.6 通过终端进入容器
开头就提到过,每个容器就类似于一个小的虚拟机,我们可以直接连接到容器再对其进行操作。
下面的操作全都是在Master一台虚拟机上进行的!
首先打开三个终端,分别通过以下指令进入三个容器。
docker exec -it master60 /bin/bash进入master容器docker exec -it slave1-60 /bin/bash进入slave1容器docker exec -it slave2-60 /bin/bash进入slave2容器
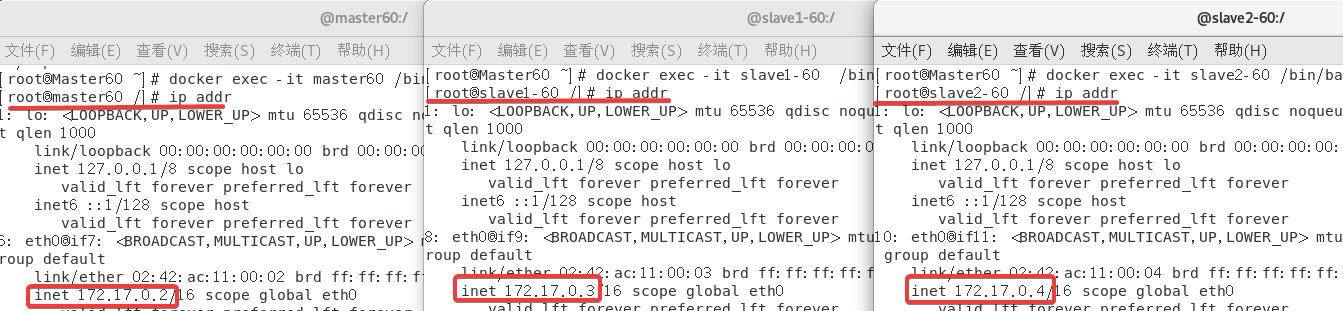
进来之后顺便看了一下IP:
172.17.0.2 master60
172.17.0.3 slave1-60
172.17.0.4 slave2-60
2.7 关闭防火墙
在三个终端都进行如下操作:
输入指令:
systemctl stop iptables.service
为了防止重启后防火墙重启,再进行如下操作:
输入指令:
vi ~/.bashrc
,之后再文件末尾添加上这段关闭指令
systemctl stop iptables.service
即可。
2.8 配置SSH
2.8.1 设置主机名
首先明确容器的主机名和容器名没有关系,和虚拟机的主机名也没有关系。
但是建议是不要和虚拟机的主机名相同,因为之后可能会产生冲突导致只能用IP来进行操作。
这句话是我后来加上的所以我这里没有修改,但是希望可以起类似于
Dmaster60
的主机名,当然要是害怕之后出问题,也可以不改。
在每一个终端都进行如下操作(共3次):
输入指令:
vi /etc/sysconfig/network
然后添加下面的内容,其中
HOSTNAME=XXX
是终端代表的虚拟机的主机名。
NETWORKING=yes
HOSTNAME=master60

直接中键复制可能会少几个字母!!!请确保完全一致,否则后续可能会出现问题!!!
2.8.2 添加映射关系
在每一个终端都进行如下操作(共3次):
输入指令:
vi /etc/hosts
然后把之前得到的容器IP添加到文件末尾:
172.17.0.2 master60
172.17.0.3 slave1-60
172.17.0.4 slave2-60

因为容器的
/etc/hosts
每次重启都会重置,这样我们再进行如下的操作:
输入指令:
vi ~/.bashrc
,然后在末尾添加如下内容(注意修改):
echo "172.17.0.2 master60" >> /etc/hosts
echo "172.17.0.3 slave1-60" >> /etc/hosts
echo "172.17.0.4 slave2-60" >> /etc/hosts
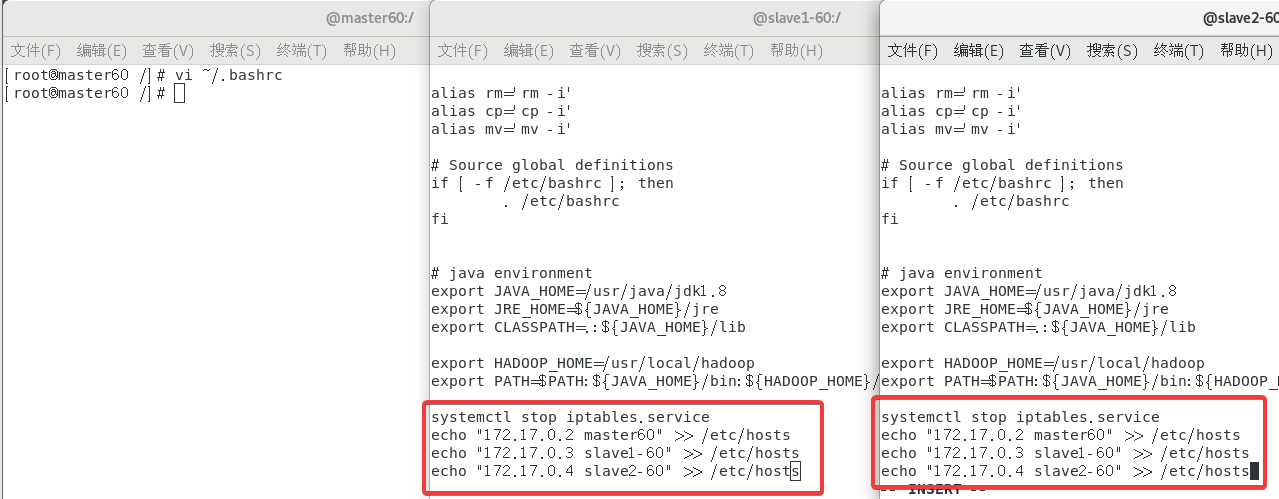
2.8.3 重置密码、生成秘钥
使用
passwd
指令重新设置密码(!!!之后可能会用),直接123456两次就可以。三个容器最好都重置密码。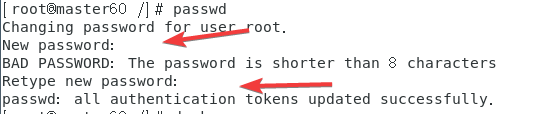
可能现在的版本创建的时候就已经自带秘钥了?没有设置就可以免密登录了。
分别在每个终端
ssh
其他的机器试试有没有免密,如果没有的话参考涛哥的博客step3 - 4。
2.9 配置分享Hadoop文件
在master60容器(终端)上完成配置,之后再分享给另外两个容器(终端)。
首先输入指令:
cd /usr/local/hadoop/etc/hadoop
这个和之前的实验一一样,写错了一点就几乎不可能成功运行,因此请认真核对自己的相关配置!
2.9.1 core-site.xml
先进入到配置文件:
vi core-site.xml
在末尾追加以下内容:
<configuration><property><name>fs.defaultFS</name><value>hdfs://master60:9000</value></property><property><name>hadoop.tmp.dir</name><value>/home/data/hadoopdata</value></property></configuration>
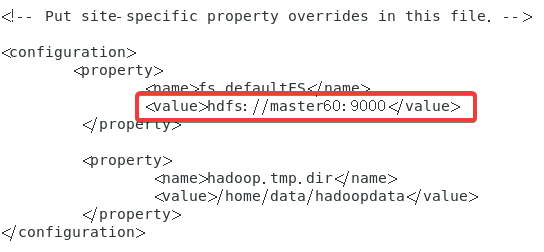
之后,返回到终端创建两个文件:
mkdir -p /home/data
mkdir -p /home/data/hadoopdata
2.9.2 hdfs-site.xml
先进入到配置文件:
vi hdfs-site.xml
在末尾追加以下内容:
<configuration><property><!--配置存储namenode数据的目录--><name>dfs.namenode.name.dir</name><value>/home/data/hadoopdata/name</value></property><property><!--配置存储datanode数据的目录--><name>dfs.datanode.data.dir</name><value>/home/data/hadoopdata/data</value></property><property><!--配置副本数量--><name>dfs.replication</name><value>1</value></property><property><!--配置第二名称节点--><name>dfs.secondary.http.address</name><value>master60:50090</value></property></configuration>
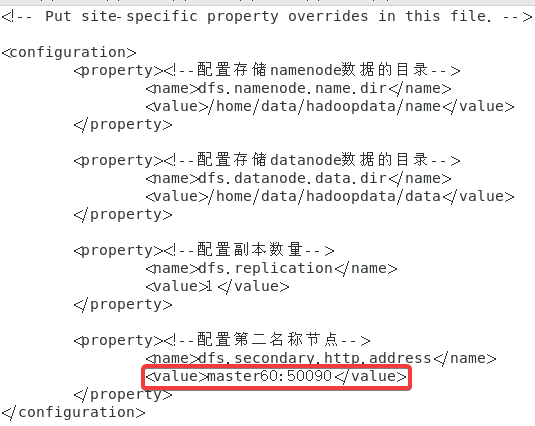
2.9.3 mapred-site.xml
输入指令:
cp mapred-site.xml.template mapred-site.xml
然后输入:
vi mapred-site.xml
在末尾追加以下内容:
<configuration><property><name>mapreduce.Framework.name</name><value>yarn</value></property></configuration>

2.9.4 yarn-site.xml
先进入到配置文件:
vi yarn-site.xml
在末尾追加以下内容:
<configuration><property><!--配置yarn主节点--><name>yarn.resourcemanager.hostname</name><value>master60</value></property><property><!--配置执行的计算框架--><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property></configuration>
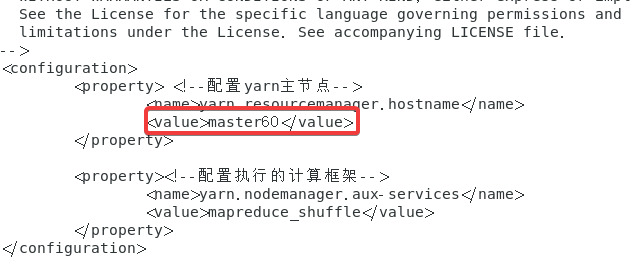
2.9.5 slaves
先进入到配置文件:
vi slaves
在末尾追加以下内容:
master60
slave1-60
slave2-60
不用localhost是因为之后要传给其他的容器,而localhost代表"本机"。
2.9.6 分享配置文件给其他容器
首先确保能互相ping通(一般有网就行),这里不多做演示。
确保主容器在hadoop目录下,
cd /usr/local/hadoop/etc/hadoop
。
①先传给slave1,记得改IP!!!
scp slaves root@slave1-60:/usr/local/hadoop/etc/hadoop/
scp mapred-site.xml root@slave1-60:/usr/local/hadoop/etc/hadoop
scp yarn-site.xml root@slave1-60:/usr/local/hadoop/etc/hadoop/
scp hdfs-site.xml root@slave1-60:/usr/local/hadoop/etc/hadoop
scp core-site.xml root@slave1-60:/usr/local/hadoop/etc/hadoop
scp -r /home/data/hadoopdata root@slave1-60:/home/
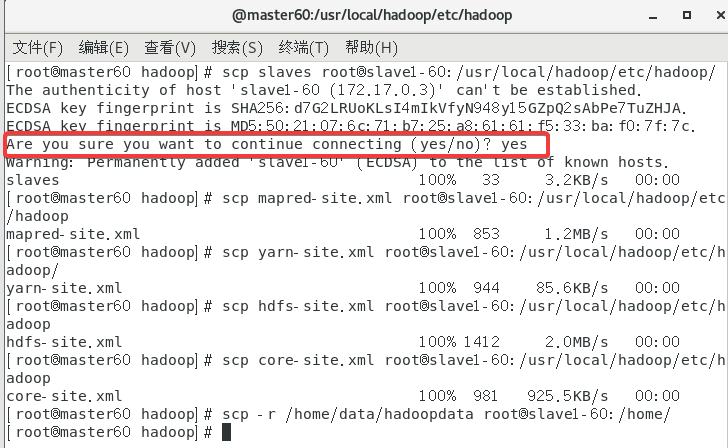
要是出现了这个就yes,好像是我的hosts配置的不是很好自动帮我修改了。
②再传给slave2,记得改IP!!!
scp slaves root@slave2-60:/usr/local/hadoop/etc/hadoop/
scp mapred-site.xml root@slave2-60:/usr/local/hadoop/etc/hadoop
scp yarn-site.xml root@slave2-60:/usr/local/hadoop/etc/hadoop/
scp hdfs-site.xml root@slave2-60:/usr/local/hadoop/etc/hadoop
scp core-site.xml root@slave2-60:/usr/local/hadoop/etc/hadoop
scp -r /home/data/hadoopdata root@slave2-60:/home/
2.10 格式化节点
在三个容器(终端)都使用指令:
hadoop namenode -format
,轻松拿下。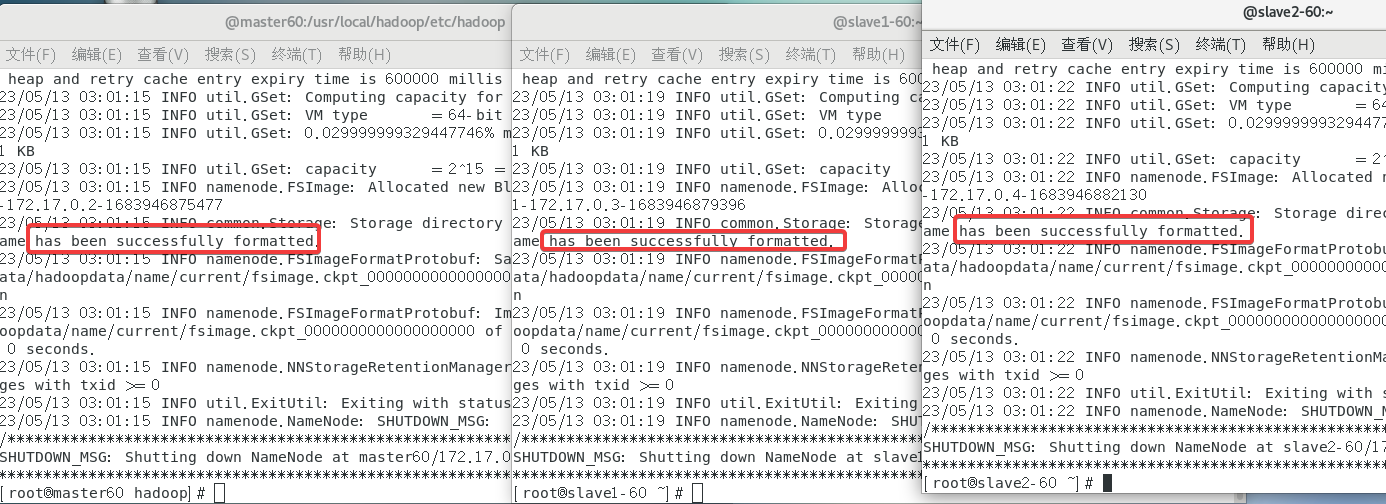
2.11 终极无敌启动Hadoop!!
在主机使用指令
/usr/local/hadoop/sbin/start-all.sh
然后经典
jps
查看状态,太健康了!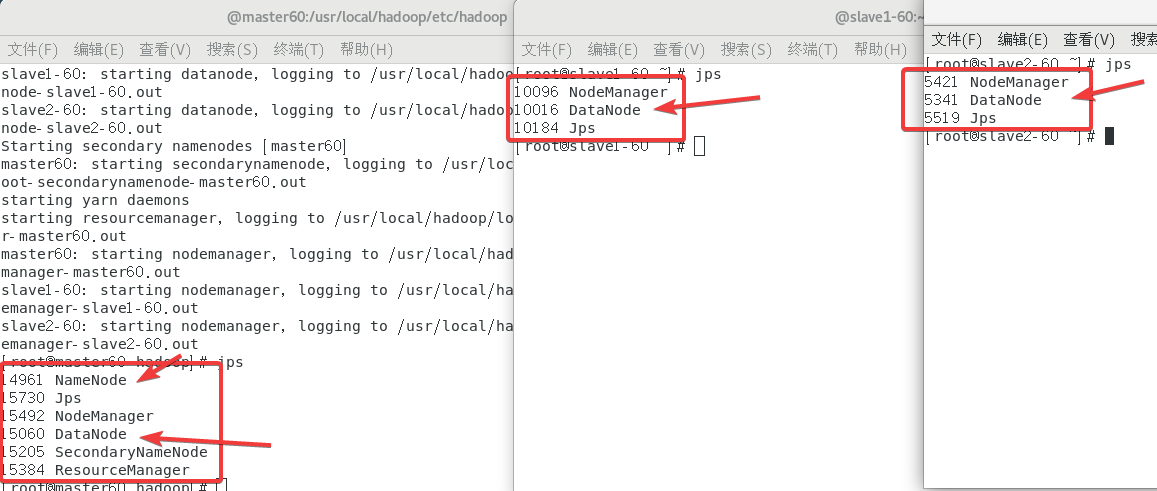
然后访问一下
172.17.0.2:50070
当然IP可以用主机名代替,但是我虚拟机主机名和容器主机名是冲突的(主机名不区分大小写),因此有时候我无法通过
master60:50070
来访问。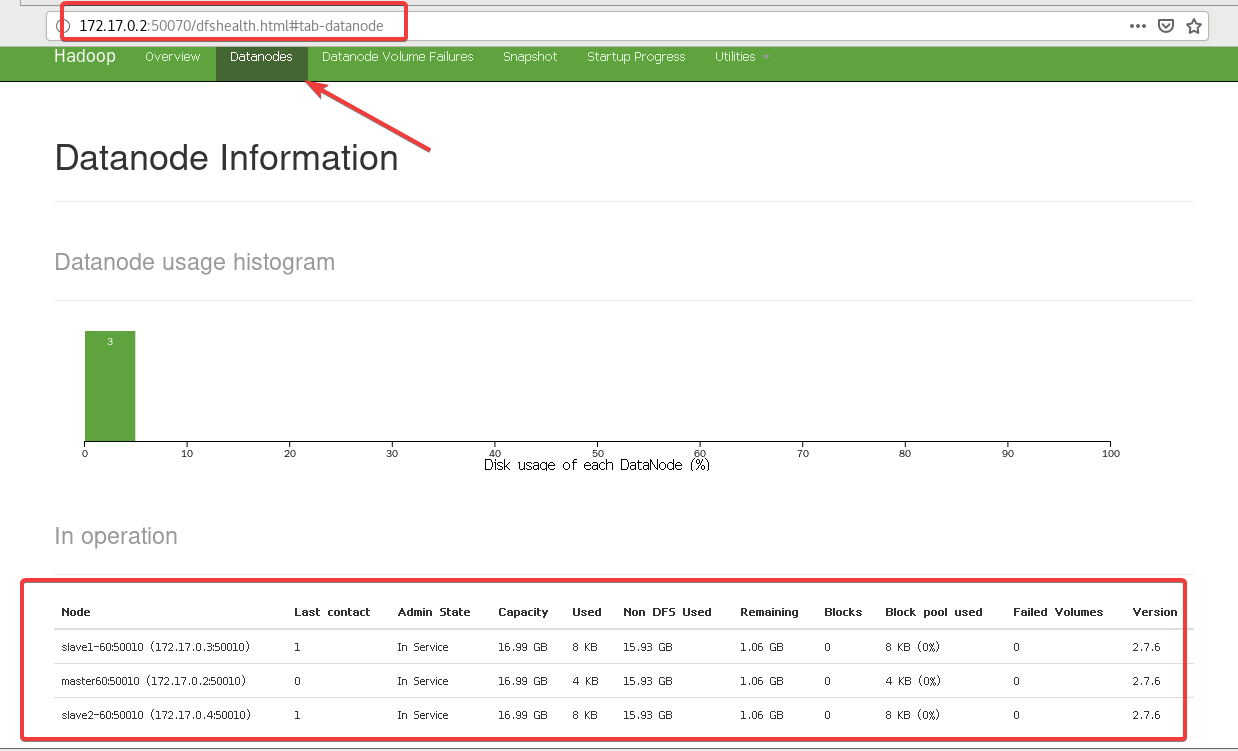
◆终端执行jps,证实虚拟器Hadoop集群没有启动Hadoop,需要截图[1]。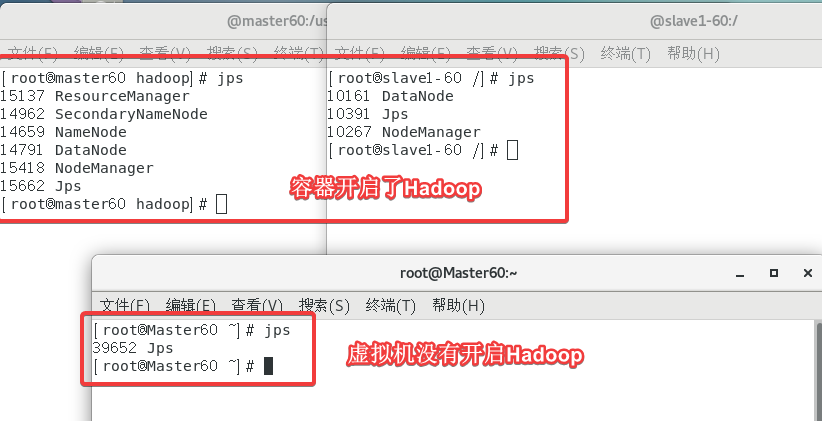
◆终端执行进入容器命令,用report命令显示Docker Hadoop集群状态,这个需要截屏[2]。
使用
hadoop dfsadmin -report
指令。
其实有三部分下面只截了
172.17.0.2
的信息。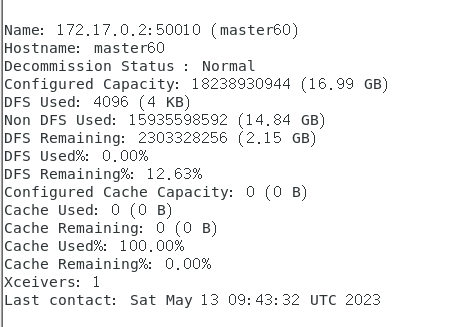
关闭终端不代表关闭容器,可以再次进入,Hadoop也不会断开。重开虚拟机会关闭容器,需要重新连接。
2.12 配置与运行Hadoop WordCount程序
直接按照步骤一步一步来:
hadoop fs -mkdir /input在HDFS中创建文件cd /usr/local/hadoop进入目录touch in.txt创建文件vi in.txt打开文件,添加信息(之后求出现次数)
hadoop fs -put in.txt /input/文件添加到HDFS的 /input/下cd share/hadoop/mapreduce切换目录hadoop jar hadoop-mapreduce-examples-2.7.6.jar \使用wordcount /input /output执行
hadoop fs -cat /output/part-r-00000查看结果
好像因为容器和虚拟机巴拉巴拉之间原因,用网页可能是无权操作的,因此这么做就行了。
如果要删除就使用
hadoop fs -rm -r /output
,不删除不能再次运行。
2.13 ★重启虚拟机后的操作
重启虚拟机后容器没有开启,
docker ps
是看不到容器的因为这个指令是看正在运行的容器的;
通过
docker ps -a
指令查看容器的ID,然后再通过
docker start ID
来启动。
直接一次开三个,跳转到GUI的概率大一点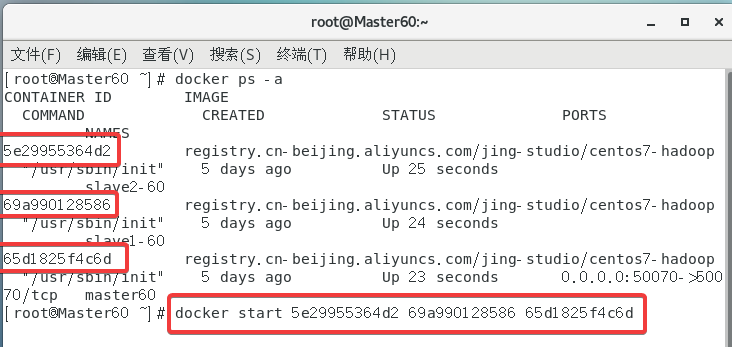
然后先打开三个终端,分别通过以下指令进入三个容器。
docker exec -it master60 /bin/bash进入master容器docker exec -it slave1-60 /bin/bash进入slave1容器docker exec -it slave2-60 /bin/bash进入slave2容器
最后再打开Docker的Hadoop就行了
/usr/local/hadoop/sbin/start-all.sh
。
3. Docker PLUS
终端关了就行了,现在是另外的内容了,之后是在虚拟机的终端上进行。
之后操作在虚拟机终端!!虚拟机终端!!虚拟机终端!!
3.1 制作自己的镜像
直接执行命令:
cd ~进入根目录mkdir -p dockerWorkspace创建目录cd dockerWorkspace进入目录touch hello.sh创建文件chmod 777 hello.sh给予权限vi hello.sh编辑文件,添加内容echo "hello docker!......
touch Dockerfile创建文件vi Dockerfile编辑文件,添加以下内容
FROM alpine:latest
ADD ./hello.sh /hello.sh
RUN chmod +x /hello.sh
CMD ["/bin/sh","-c","/hello.sh"]
docker build -t hello-docker .
不成功可以搞一个镜像加速
◆终端利用Docker build创建Hello-Docker镜像截屏,需要截屏[3]。 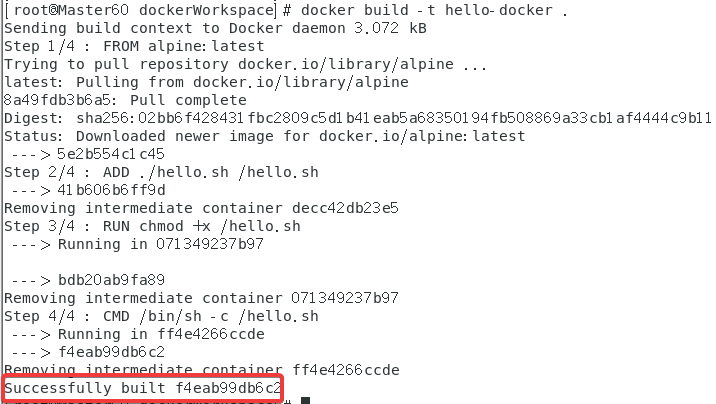
这个第一次失败了,又运行一遍就成功了……有点玄学。
用
docker images
查看镜像列表,创建成功了。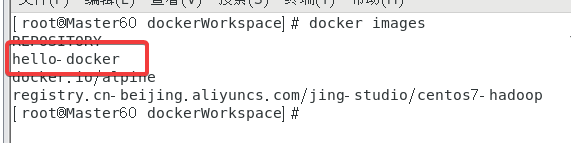
也可以用
docker run --name hello-docker hello-docker
来运行一下,当然实验中没有提到就不多说明了。
3.2 镜像注册,创建个人实例,关联GitHub
用阿里云是因为要有关联GitHub的过程?因为要完成实验,所以只进行到实验需要的部分。PS.为什么不用阿里云要用星星的Docker Hub!
阿里云官网
3.2.1 阿里云关联GitHub
好像现在Docker Hub必须是高级VIP才能使用关联GitHub的功能,囊中羞涩只能用阿里云来表演一下关联GitHub这个操作了。
阿里云容器镜像服务
点击
代码源
,然后绑定GitHub就可以了。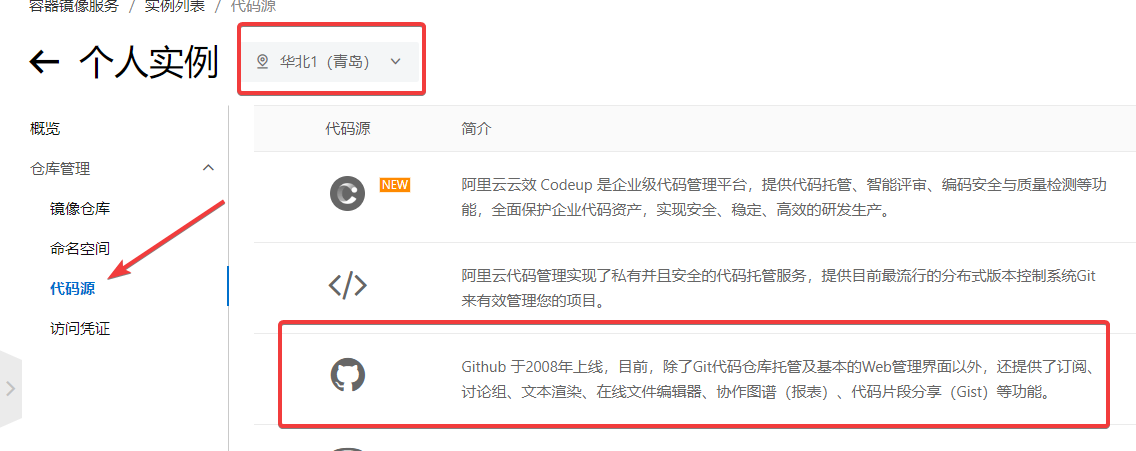
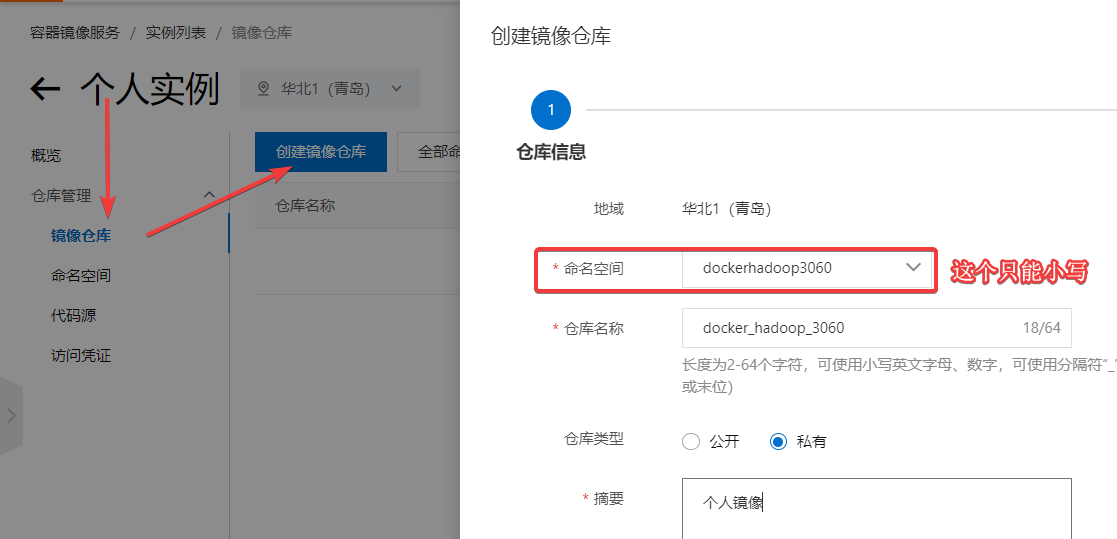
3.2.2 阿里云创建个人实例
点击
镜像仓库
->
创建镜像仓库
。
然后关联一下GitHub,之后退出刷新一下页面就出来了(提示仓库已存在)。
3.3 把自己的镜像发布到Docker Hub
上面的阿里云只是走个过场,这个才是要真提交的。
Docker Hub官网直接注册就行了……注册就不多说了Register。
3.3.1 Docker Hub创建仓库
点击上面的
Repositories
,然后新建一个仓库。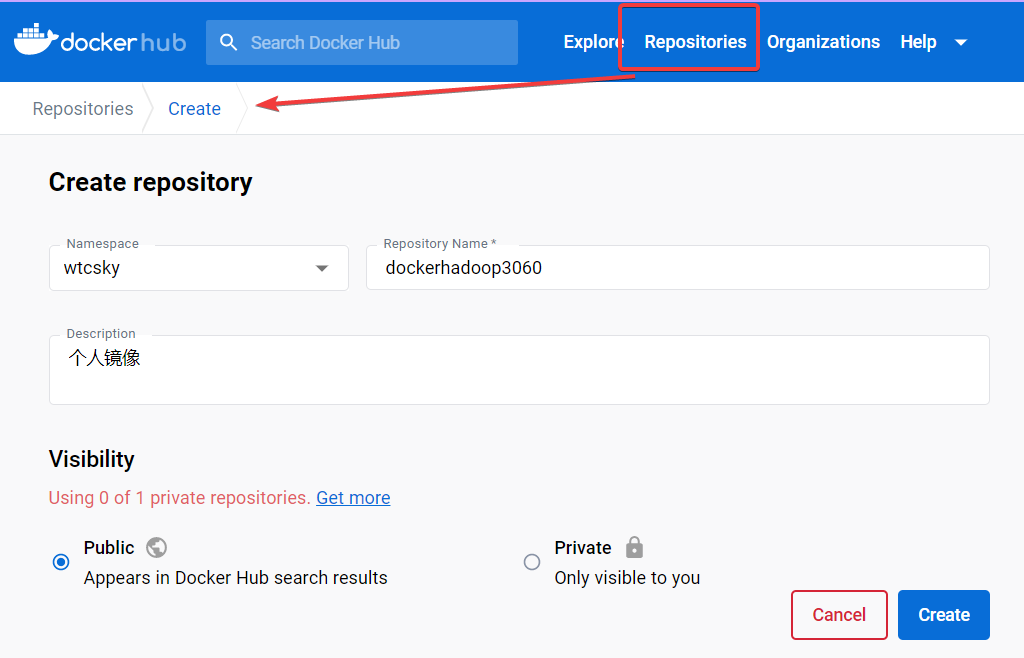
3.3.2 在Docker上登录Docker Hub
终端输入:
docker login -u 用户名 -p 密码
,账号密码自己知道。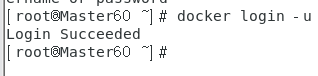
3.3.3 推送镜像
因为我虚拟机可能存在一些问题(大概率是网络问题)无法push到Docker Hub(用阿里云没问题),有的人可能没有这个问题。
由于我暂时没有使用Docker Hub因此之后的步骤用的是同学提供的截图!
十分感谢!
docker tag [镜像id] [网站上的位置]:[自定义Tag名字]
标准化一下,先打个标签
docker tag hello-docker:latest fengjiahuan/fengjh032:version_1.0
。(tag自己起没有标准)
其中
fengjiahuan/fengjh032
是Docker Hub的
用户名/仓库名
。
docker push [网站上的位置]:[自定义Tag名字]
◆终端推送Hello-Docker到DockerHub的截屏,需要截屏[4]
直接执行
docker push fengjiahuan/fengjh032:version_1.0
如果不带tag就默认是
latest
。
3.3.4 验证是否成功
◆在网页进入DockerHub用户,查看推送的Hello-Docker镜像截屏,需要截屏[7]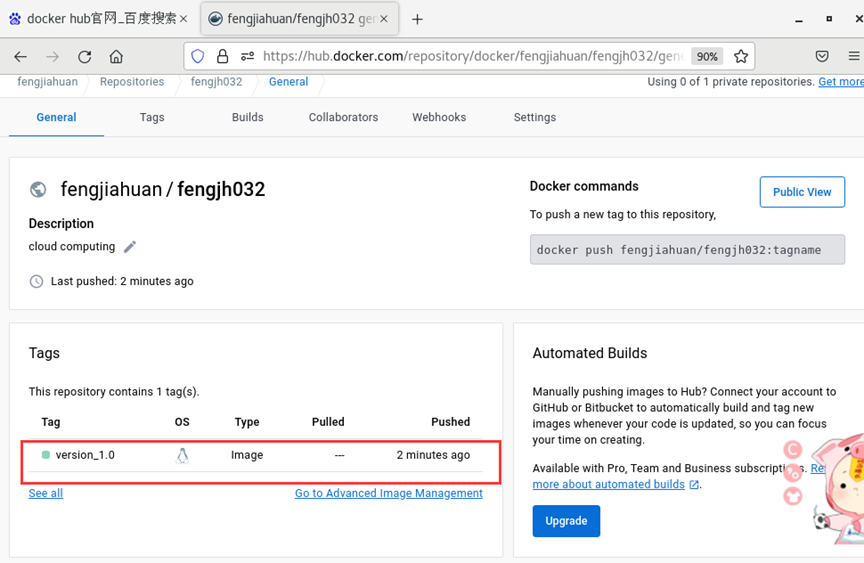
3.4 拉取验证自己的发布的镜像
最后一部分用阿里云代替了,应该差不多一样。
docker pull docker.io/[用户名]/[仓库名]:[镜像版本号]
◆终端执行pull从DockerHub拉取Hello-Docker镜像截屏,截屏[5]。
docker pull registry.cn-qingdao.aliyuncs.com/wtcsky/hello_docker:v1.0

最后查看一下
◆终端执行Docker Images截屏(红色框圈中刚刚拉取的镜像),截屏[6]。
4. 番外篇
博客按照任务的顺序编写,中间小节按照需要截图的来分配。
通过
Ctrl + F
开启搜索,搜索关键字符
◆
就可以找到七个截图的位置(当然会搜索到8个,因为这句话里也有一个)。
…写的挺水的,有问题随时修改吧。
版权归原作者 WtcSky 所有, 如有侵权,请联系我们删除。